



0 引言
局部特征检测是图像处理的第一步,在许多计算机视觉应用中有着至关重要的作用,例如图像匹配[1]、三维重建[2]、图像检索[3]等. 在过去二十年里,局部特征检测一直是热门研究课题,许多经典的局部特征检测器在这期间被提出. 在早期,手工制作的局部特征检测器占据主导地位,开发了多种局部特征检测器用来检测不同规模、不同视角下的图像特征[4-5]. 以Harris[6]、FAST(features from accelerated segment test)[7]为代表的角点检测器在平移和旋转方面具有不变性,能够有效检测图像间经旋转或平移的局部特征. 而像SIFT(scale invariant feature transform)[8]这样的斑点检测器通过在高斯尺度空间中寻找DoG(difference of Gaussian)响应的局部最大值,以获得尺度不变的局部特征. 这些手工制作的检测器往往只有在处理特定条件下的图像才能表现得很好,泛化性较差. 面对光照或视角剧烈变化的图像,手工制作的检测器经常会检测到许多不同的局部特征,在特征可重复性上检测效果差强人意.
随着深度学习在解决图像分类和目标检测等问题上取得的成功,基于学习的局部特征检测器也逐渐被提出. Verdie等[9]提出的TILDE(Temporally Invariant Learned DEtector)是通过学习同一场景下不同时间和季节所拍摄的图像中的时不变特征的检测器,以应对不同天气和光照条件下剧烈的成像变化. Kwang等[10]提出将特征检测、方向估计和描述符计算3个独立的神经网络融合成一个新的网络,以实现图像的预处理,但在实践中并不适用. Lenc和Vedaldi[11]首次提出将局部特征检测作为一个回归问题,使用卷积神经网络来学习训练一个变换回归器CovDet(Covariant feature Detectors),以检测图像中协变的局部特征. Savinov等[12]提出一种无监督的方法来学习特征检测器,通过将特征映射为实值,并进行高低排位来对稳定的局部特征进行筛选. 但由于自然图像内容的复杂多样,基于学习的检测器想要提取稳定可靠的局部特征,需要设计较深的网络结构来学习尽可能多的特征信息,且检测时间消耗较长.
针对上述问题,本文提出一种基于VGG16改进的局部特征检测器VGG-Det,以实现网络结构的简化和检测器性能的提升. VGG-Det通过对传统VGG16网络的层间结构进行调整压缩,使用Mish函数替换其卷积层中的ReLU(Rectified Linear Unit)激活函数,并将随机变换的图像块送入改进后的紧凑型网络进行训练,以使其更充分地学习特征信息,同时缩短检测时间. VGG-Det与现有的基于学习的检测器相比,不仅提升了检测特征可重复性的性能,还大大缩短了检测时间.
1 相关理论 1.1 协变约束给定一个图像块x,局部特征用f表示,t表示对图像块x所做的几何变换. 特征检测器定义为φ:x→f. 若特征检测器φ满足:
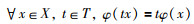
|
(1) |
则称特征检测器φ为协变检测器. 其中,X、T分别表示图像块的集合和几何变换的集合. 协变检测器φ的协变约束定义为
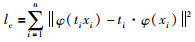
|
(2) |
Lenc等指出,学习这样的检测器计算复杂,过程繁琐,可以将所有的局部特征f用唯一的标准特征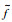
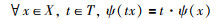
|
(3) |
其中,·表示组合变换. 那么变换回归器ψ的目标学习函数定义为
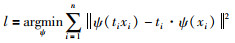
|
(4) |
理论上,变换回归器ψ将遍历所有的图像及其变换进行训练. 而Zhang等[13]指出式(4)的解不唯一,仅仅只学习协变约束会导致检测器不稳定. 文[13]通过定义“基准图像块”和“标准特征”两个概念来改进式(4)的学习函数,从而简化训练过程,增加检测器的鲁棒性. 对于任意的基准图像块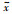
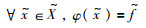
|
(5) |
其中,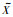
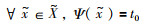
|
(6) |
于是,变换约束定义为
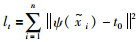
|
(7) |
目标学习函数(4)被改写为
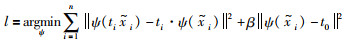
|
(8) |
其中,β为超参数,用于权衡协变约束和变换约束.
1.2 传统VGG16网络模型VGG16网络[14]由牛津大学Visual Geometry Group提出,是常见的卷积神经网络(convolutional neural network,CNN)模型之一,广泛应用于图像分类和目标检测任务中. 它由13个卷积层(convolution layer)、5个最大池化层(max pooling layer,MP)、3个全连接层(fully connected layer,FC)和1个softmax层构成,其网络结构如图 1所示. 在该结构中,所有卷积层都采用相同的3×3卷积核,步长大小为1;其池化层的核大小为2×2,步长为2;3个全连接层的前两层共有4 096个输出通道,第3层输出1 000个类别标签;最后一层为softmax层,输出图像为每个类别的概率. 所有卷积层和全连接层都带有ReLU非线性激活函数. VGG16网络使用小卷积核来替代较大的卷积核,不仅减少了网络的参数量,且增加了网络中的非线性单元,使得网络学习特征信息的能力增强,解决了大卷积核带来的参数爆炸问题. 输入图像通过连续叠加的卷积层和池化层,以获得图像中的主要特征信息并对其进行压缩[15]. 最后通过全连接层和输出层对学习到的图像信息整合并进行分类处理.

|
| 图 1 VGG16网络结构 Fig.1 Structure of VGG16 network |
激活函数引入的非线性特性对卷积神经网络模型的学习起着至关重要的作用. 在传统VGG16网络模型中(图 1),使用ReLU作为激活函数,其数学定义为
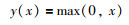
|
(9) |
图像数据在网络中经过大量卷积计算后,输出会产生大量的负值,而这些负值在经过ReLU激活单元后都将直接被置为零值,这样网络就会丢失大量的特征信息,对检测器的特征提取产生很大的影响[16].
2019年,Misra[17]提出了一个非单调激活函数(图 2),称为Mish,其数学定义为
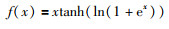
|
(10) |

|
| 图 2 Mish激活函数 Fig.2 Mish activation function |
它很好地消除了使用ReLU激活函数可能会面临的“神经元死亡”现象[18]. 这一问题的解决有助于卷积神经网络获取图像更多的有效信息. 同时,Mish与ReLU一样没有上边界,从而避免了训练网络中接近于零的梯度致使网络训练速度减慢. 但与ReLU不同的是,Mish是连续可微的,这很好地避免了梯度优化时梯度爆炸或梯度消失的现象发生.
2 本文方法本文提出的VGG-Det所用方法如图 3所示. 首先使用32×32大小的滑动窗口将整个图像分成多个图像块xi,然后将图像块xi分别送入预测变换网络来预测变换ti(图 3(a)). 预测变换ti应用于标准特征

|
| 图 3 变换预测网络与特征检测器 Fig.3 Predictive transformation network and feature detector |
基准图像块具有足够的可判别性和变换多样性,用于学习变换回归器. 本文选择TILDE-P24特征检测器的输出结果作为基准图像块. 因为基准图像块进行变换后可能会使用邻域的像素,所以选取以特征为中心向外扩散51×51像素的图像块作为一个候选基准图像块.
基准图像块
| 变换类型 | 变换形式 |
| 平移 | x轴、y轴从[-5, 5]中均匀采样 |
| 旋转 | [0,360°]内均匀采样 |
| 裁剪 | x轴、y轴在[-0.10,0.10]范围内均匀采样 |
| 缩放 | x轴、y轴在[-0.15,0.15]比例上均匀采样 |
本文提出的VGG-Det为了能够从图像中学习到更多的特征信息,将32×32像素的基准图像块送入网络进行训练. 因此,不需要过深的网络结构,过多的卷积层不仅消耗内存,还影响训练速率. 于是,通过对传统VGG16网络模型结构进行删减和卷积层添加,最终设计成为VGG-Det的网络结构,加快了图像特征信息的提取,缩短了网络的训练时间.
VGG-Det的网络结构如图 4所示. 相较于传统VGG16网络,VGG-Det的网络中卷积层的卷积核大小、池化层大小、步长都与传统VGG16网络保持一致. 其改进在于由2-2-3-3-3结构的13层卷积层改为2-2-1-1-1结构的7层卷积层,池化层由5个减少到2个,全连接层由3个减少到1个. 前6个卷积层中所有的卷积核大小均为3×3,步长为1;最大池化层的核大小为2×2,步长为2;全连接层输出通道数改为256;在全连接层后添加了1个1×1的卷积层,通道数为2. 所有卷积层中都引入Mish激活函数来替代ReLU激活函数以实现网络的加速收敛和特征的有效学习.

|
| 图 4 VGG-Det的网络结构 Fig.4 VGG-Det network structure |
本文实验使用的环境配置为:Intel Core i7-9750H CPU. 操作系统为Ubuntu16.04,基于tensorflow深度学习框架,python 3.5实现网络,实验预处理部分使用Matlab 2016b对图像进行裁剪变换.
3.2 数据集为了合理地评估本文VGG-Det检测特征可重复性的性能,将其在3个经典的特征检测数据集上进行测试,分别为Webcam数据集、EF[19]数据集、VGG-Affine[20]数据集. Webcam数据集包含6个图像组,每个组均是来自同一场景的图像,它包含一个场景的时间和天气的剧烈变化,这对特征检测器的检测是一个很大的挑战. VGG-Affine数据集中的图像具有不同视点、光照条件和压缩率的特点,是传统评估检测器数据集之一. EF数据集包含5个剧烈光照和背景变化的图像组. 同时本文还从光照变化、视角变化以及两者都变化三个方面,制作了自己的数据集,分别为Low-light、Sub-Oxford和Sub-Paris,进一步评估VGG-Det的性能. Low-light选取自Fu等[21]研究中使用的Campus Image Dataset(CID)中的部分图像组,每个组包含6张图像,是同一场景下相机使用不同曝光度所拍摄的图像,代表了光照变化. Sub-Oxford和Sub-Paris选自Philbin等[22-23]所使用的Oxford 5K dataset和The Paris dataset中的部分图像,分别代表了不同光照、视角变化和不同视角变化. 图 5展示了这些数据集中的一些场景.

|
| 图 5 数据集中部分场景展示 Fig.5 Part of the scene display in the datasets |
本文提出的VGG-Det将与FAST[24]、SFOP[25]、CovDet、TILDE-CNN和TILDE-P24进行比较. TILDE检测器和CovDet检测器均使用作者提供的模型.
本文实验中网络训练参数设置如下:初始学习率设为0.01,使用指数衰减算法对学习率进行动态调整;batch size为128,超参数β设为1,训练轮次为20,并选择Momentum优化器优化网络,Momentum设为0.9. VGG-Det首先在TILDE-P24检测器输出的Mexico子集图像上随机选取约4 500个图像块,随机变换生成约120 000个基准图像块进行训练. 然后分别在Webcam(除Mexico子集)、EF、VGG-Affine、Low-light、Sub-Oxford和Sub-Paris数据集上进行测试评估.
3.4 超参数β的确定β是式(8)中平衡协变约束和变换约束的重要超参数,选择一个合适的值可以使检测器得到更好的检测效果,本文分别取β值为0,0.1,1,10进行训练,得到如图 6的结果. 从图中可以看出,在EF和VGG-Affine数据集上当β=0.1时得到的可重复性要略微好于β=1. 但从平均来看,β=1的效果要优于β=0.1,且β=0.1时训练所耗时间比β=1时要长近一倍,所以本文将β的值设为1.

|
| 图 6 不同β值训练得到的重复率 Fig.6 Repeatability obtained by training with different β values |
本文提出的VGG-Det分别在Webcam(除Mexico子集)、EF、VGG-Affine、Low-light、Sub-Oxford和Sub-Paris六个数据集上,使用与Mikolajczyk等相同的可重复性度量进行评估. 可重复性指在两幅图像相对应的区域中检测到一致特征的数量与其中检测特征数量较小者的比值,用百分比来表示. 本文分别计算每幅图像提取500个特征和1 000个特征时的可重复性来避免特征可能的随机“匹配”.
表 2展示了6种检测方法在3个经典数据集上的平均可重复性,可以看出,VGG-Det的表现均优于其他5种检测方法. 这说明本文改进的网络模型学习到了更多有效的图像信息,以使VGG-Det提取到了更多稳定的局部特征,提升了基于学习的检测器检测特征可重复性的能力.
| 单位: % | |||||||||||||||||||||||||||||
| 方法 | 数据集 | ||||||||||||||||||||||||||||
| Webcam | VGG | EF | |||||||||||||||||||||||||||
| 500 | 1 000 | 500 | 1 000 | 500 | 1 000 | ||||||||||||||||||||||||
| SFOP | 34.2 | 43.8 | 46.9 | 51.2 | 28.0 | 36.1 | |||||||||||||||||||||||
| FAST | 49.8 | 56.3 | 50.0 | 50.7 | 25.9 | 32.0 | |||||||||||||||||||||||
| CovDet | 41.5 | 49.9 | 52.1 | 62.1 | 30.4 | 42.7 | |||||||||||||||||||||||
| TILDE-CNN | 45.0 | 51.4 | 46.2 | 50.7 | 29.6 | 38.0 | |||||||||||||||||||||||
| TILDE-P24 | 53.9 | 61.7 | 61.3 | 64.4 | 38.3 | 45.4 | |||||||||||||||||||||||
| VGG-Det | 65.3 | 70.4 | 64.4 | 69.5 | 45.9 | 48.2 | |||||||||||||||||||||||
为了评估VGG-Det在检测具有挑战性的图像时的性能,又分别从图像的光照变化、视角变化以及两者都变化3个方面进行了测试评估,实验结果如表 3所示. 从表 3数据可以看到,在仅有光照变化的Low-light数据集上,VGG-Det检测器的可重复性均达到80%以上,这说明仅在光照的影响下,VGG-Det可以检测提取到80%以上的重复性特征. 在只有视角变化的Sub-Paris数据集和两者都发生变化的Sub-Oxford数据集上,VGG-Det的表现也优于其他的检测器. 这表明VGG-Det能够在剧烈变化的图像下提取到更多稳定的局部特征,改善了手工制作的检测器在极端图像条件下检测特征可重复性的不佳效果.
| 单位: % | |||||||||||||||||||||||||||||
| 方法 | 数据集 | ||||||||||||||||||||||||||||
| Low-light | Sub-Oxford | Sub-Paris | |||||||||||||||||||||||||||
| 500 | 1 000 | 500 | 1 000 | 500 | 1 000 | ||||||||||||||||||||||||
| SFOP | 70.1 | 74.1 | 23.3 | 28.6 | 20.1 | 25.9 | |||||||||||||||||||||||
| FAST | 74.6 | 77.9 | 29.6 | 37.3 | 22.8 | 29.8 | |||||||||||||||||||||||
| CovDet | 75.9 | 77.3 | 22.5 | 34.8 | 21.8 | 33.3 | |||||||||||||||||||||||
| TILDE-CNN | 71.1 | 74.2 | 24.5 | 32.3 | 19.9 | 25.2 | |||||||||||||||||||||||
| TILDE-P24 | 77.5 | 79.9 | 26.3 | 35.5 | 22.3 | 32.8 | |||||||||||||||||||||||
| VGG-Det | 81.6 | 85.6 | 32.3 | 37.6 | 29.5 | 34.2 | |||||||||||||||||||||||
特征检测器的性能评估不仅在于它是否能够提取较多稳定的局部特征,且检测时间对它来说也很重要. 图 7给出不同的检测器在Webcam数据集的StLouis子集上提取500个特征所需的时间以及可重复性10次实验的平均值. 从图 7(a)可以看出,基于学习的检测器的检测时间都比手工制作的检测器长,这是由于它们采用深度学习的方法来学习图像中的特征,网络结构比较复杂. 手工制作的检测器SFOP、FAST所耗时间较短,但其可重复性检测效果没有优势. 而在基于学习的检测器中,TILDE-CNN、CovDet和本文提出的VGG-Det检测时间相当,但VGG-Det的可重复性分别高于它们15.66%和8.28%. 与可重复性相当的TILDE-P24检测器相比,VGG-Det在检测时间上缩短约21.5%. 这说明,本文提出的VGG-Det在保证可重复性的条件下,同步提升了检测速度.

|
| 图 7 不同检测器提取500个特征所需的平均时间以及平均重复率 Fig.7 The average time and repeatability required for different detectors to extract 500 features |
本文提出的基于VGG16网络改进的特征检测器VGG-Det,通过一个紧凑的网络模型,实现了对图像信息的更有效学习,简化了网络结构,缩短了检测时间. 本文提出的VGG-Det无论是在3个经典数据集上,还是在针对光照和视角变化建立的数据集上进行性能评估,可重复性均优于其他的检测器. 此外,与基于学习的检测器相比,VGG-Det在检测速度上也具有优势. 今后的工作将集中在进一步研究如何提升基于学习的检测器在检测可重复性特征上的性能.
| [1] | Zanfir A, Sminchisescu C. Deep learning of graph matching[C]//31st Meeting of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, USA: IEEE, 2018: 2684-2693. |
| [2] | Fan B, Kong Q, Wang X, et al. A performance evaluation of local features for image-based 3D reconstruction[J]. IEEE Transactions on Image Processing, 2019, 28(10): 4774–4789. DOI:10.1109/TIP.2019.2909640 |
| [3] | Duan Y, Lu J, Wang Z, et al. Learning deep binary descriptor with multi-quantization[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(8): 1924–1938. |
| [4] | Bay H, Tuytelaars T, Gool L V. SURF: Speeded up robust features[C]//The 9th European conference on Computer Vision-Volume Part I. Berlin, Germany: Springer-Verlag, 2006: 404-417. |
| [5] | Mikolajczyk K, Tuytelaars T, Schmid C, et al. A comparison of affine region detectors[J]. International Journal of Computer Vision, 2005, 65(1/2): 43–72. |
| [6] | Harris C G, Stephens M J. A combined corner and edge detector[C]//The 4th Alvey Vision Conference. Manchester, UK: University of Manchester, 1988: 147-151. |
| [7] | Rosten E, Porter R, Drummond T. Faster and better: A machine learning approach to corner detection[J]. IEEE Transaction on Pattern Analysis and Machine Intelligence, 2010, 32(1): 102–119. |
| [8] | Lowe D G. Distinctive image feature from scale-invariant keypoints[J]. International Journal of Computer Vision, 2004, 60(2): 91–110. DOI:10.1023/B:VISI.0000029664.99615.94 |
| [9] | Verdie Y, Yi K M, Fua P, et al. TILDE: A temporally invariant learned DEtector[C]//Conference on Computer Vision and Pattern Recognition. Piscataway, USA: IEEE, 2015: 5279-5288. |
| [10] | Kwang M, Eduard T, Vincent L, et al. LIFT: Learned invariant feature transform[C]//European Conference on Computer Vision. Berlin, Germany: Springer, 2016: 467-483. |
| [11] | Lenc K, Vedaldi A. Learning covariant feature detectors[C]//European Conference on Computer Vision. Berlin, Germany: Springer, 2016: 100-117. |
| [12] | Savinov N, Seki A, Ladicky L, et al. Quad-networks: Unsupervised learning to rank for interest point detection[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, USA: IEEE, 2017: 3929-3937. |
| [13] | Zhang X, Yu F X, Karaman S, et al. Learning discriminative and transformation covariant local feature detectors[C]//IEEE Conference on Computer Vision & Pattern Recognition. Piscataway, USA: IEEE, 2017: 6818-6826. |
| [14] | Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[C/OL]//International Conference on Learning Representations. (2015-4-10)[2020-10-14]. http://arxiv.org/abs/1409.1556. |
| [15] |
沈瑜, 陈小朋. 基于DLatLRR与VGG Net的红外与可见光图像融合[J/OL]. 北京航空航天大学学报(2020-07-20)[2020-12-24]. https://doi.org/10.13700/j.bh.1001-5965.2020.0178. Shen Y, Chen X P. Infrared and visible light image fusion based on DLatLRR and VGG Net[J/OL]. Journal of Beijing University of Aeronautics and Astronautics. (2020-07-20)[2020-12-24]. https://doi.org/10.13700/j.bh.1001-5965.2020.0178. |
| [16] |
姚明海, 隆学斌.
基于改进的卷积神经网络的道路井盖缺陷检测研究[J]. 计算机测量与控制, 2020, 28(1): 66–70,75.
Yao M H, Long X B. Research on road manhole cover defect detection based on improved convolutional neural network[J]. Computer measurement and Control, 2020, 28(1): 66–70,75. |
| [17] | Misra D. Mish: A self regularized non-monotonic neural activation function[J/OL]. arxiv: 1908.08681(2019-08-26)[2020-10-14]. https://arxiv.org/abs/1908.08681. |
| [18] |
张琦. 基于深度学习的视觉显著性算法研究及应用[D]. 西安: 西安电子科技大学, 2019. Zhang Q. Research and application of visual saliency algorithm based on deep learning[D]. Xi'an: Xidian University, 2019. |
| [19] | Zitnick C L, Ramnath K. Edge foci interest points[C]//2011 International Conference on Computer Vision. Piscataway, USA: IEEE, 2011: 359-366. |
| [20] | Mikolajczyk K, Schmid C. A performance evaluation of local descriptors[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27(10): 1615–1630. DOI:10.1109/TPAMI.2005.188 |
| [21] | Fu Q X, Di X G, Zhang Y. Learning an adaptive model for extreme low-light raw image processing[J]. IET Image Processing, 2020, 14(4): 3433–3443. |
| [22] | Philbin J, Chum O, Isard M, et al. Object retrieval with large vocabularies and fast spatial matching[C]//2007 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, USA: IEEE, 2007: 1-8. |
| [23] | Philbin J, Chum O, Isard M, et al. Lost in quantization: Improving particular object retrieval in large scale image databases[C]//2008 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, USA: IEEE, 2008: 1-8. |
| [24] | Rosten E, Drummond T. Machine learning for high-speed corner detection[C]//9th European Conference on Computer Vision. Berlin, Germany: Springer, 2006: 430-443. |
| [25] | Förstner W, Dickscheid T, Schindler F. Detecting interpretable and accurate scale-invariant keypoints[C]//12th International Conference on Computer Vision. Piscataway, USA: IEEE, 2009: 2256-2263. |