



2. 同济人工智能(苏州)研究院, 江苏 苏州 215131;
3. 同济大学电子与信息工程学院, 上海 201804
2. Tongji Artifical Intelligence Research Institute, Suzhou 215131, China;
3. School of Electronics and Information Engineering, Tongji University, Shanghai 201804, China
0 引言
移动机器人的工作场景逐渐从静态环境转向人群密集的复杂动态环境,例如机场、商场等。传统的避障算法利用当前时刻周围障碍物的信息,依靠几何构型[1-3]或采样[4-6]等方法得到最终的避障策略,其未考虑周围行人未来状态的变化,在行人密集的环境中,由于行人运动的随机性,该算法容易产生震荡等不自然的行为[7],使得机器人的控制信号频繁跳动,不能满足人群密集环境中安全性与舒适性的要求。因此,为了在人群密集的复杂环境中高效地完成避障任务,移动机器人的避障算法需要对行人的行为进行分析。同时,随着人机交互理念的发展[8],机器人的避障任务不仅仅需要满足高效与实时性,更加需要在与人交互的过程中考虑行人的舒适度要求[9-13]。
针对行人行为,可以通过隐马尔科夫模型(hidden Markov model,HMM)、高斯混合模型(Gaussian mixture model,GMM)[14-15]等数学模型对行人的历史轨迹进行拟合,进而分析其运动轨迹,但是该类方法适应性差,未考虑物理环境约束、周围智能体的影响以及社会规范等智能体行进时的具体因素,不能很好地拟合以及预测行人轨迹。因而许多学者通过研究行人运动行为及其特征,建立行人流模型[16-18]来对行人行为做更好的分析。其中,Helbing与Molnar提出的社会力模型(social force model,SFM)[17]是传统行人运动模型中应用最为广泛的模型之一,该模型将行人与周围障碍物以及自身目标点之间的关系用力的形式进行描述,假定行人之间的潜在斥力是关于两者距离以及行人占有半径的单调递减函数,具有一定的实际意义。缺点是该类方法较为粗糙,且需要根据环境进行参数调整,存在一定的局限性。随着时序网络的发展,基于大规模行人运动数据集训练得到的时序网络模型可以更加精确地预测行人运动的轨迹[19-21]。其中,Social-LSTM(Social Long Short Term Memory)[19]与Social-GAN(Social Generative Adversarial Network)[20]首先对周围环境进行栅格化处理,得到行人局部地图信息,利用网络对行人之间的潜在规则进行学习,预测得到了精确的轨迹信息,但栅格化的离散处理损失了一定的环境信息,且由于预测模型自身计算量大以及预测误差的存在导致的重规划问题,基于行人轨迹预测的避障算法难以满足实时性的要求。除此之外,基于轨迹预测的避障算法在人群密集的情况下容易导致机器人的冻结现象,从而找不到机器人的可行路径。
Google在2015年提出了深度强化学习算法[22],将深度学习的感知能力和强化学习的决策能力相结合,可以更好地解决复杂系统的感知决策问题,因此许多学者将其应用在机器人避障策略的学习中[23-26]。在人群密集环境中,基于深度强化学习的避障算法将行人行为预测与机器人运动规划进行了整合,直接通过环境状态得到机器人的控制输出信号,保证了避障算法的实时性与可靠性,成为了新的研究热点。Everett等[27-29]使用多层感知机拟合值函数,通过智能体与环境的不断交互,值函数网络可以在一定程度上学习到行人运动的不确定性,提升了机器人在行人密集环境中的避障效率。但由于行人行为具有较强的随机性以及值函数网络学习能力有限,基于深度强化学习算法的避障算法依旧存在不自然的避障行为。
舒适度要求主要考虑到机器人需要与人保持一定的距离,该距离不仅可以避免碰撞,而且还可以防止行人由于与机器人距离太近而引发的情绪不适[30-33]。其中,Hall[30]提出的个人空间理论(human spatial behavior)被广泛应用于人机交互中,该理论将人与人之间的距离分为亲密距离(intimate distance)、私人距离(personal distance)、社会距离(social distance)与公共距离(public distance)四种,为了满足人机交互舒适度的要求,机器人应该避免出现在亲密或者私人距离内。Pandey[31]依据行人舒适度等社会要求对路径规划算法进行了修改,虽然使避障策略具备了舒适性,但是引入了大量的参数以及复杂的场景设计,在环境发生变化后需要调整参数,并有可能针对新的环境需要重新设计避障算法,因而适应性较差。
为了更加准确地对行人行为进行学习,并且在不引入额外计算参数的情况下使避障算法满足舒适度的要求,本文提出了人群环境中基于深度强化学习的移动机器人避障算法。该算法受行人轨迹预测方法的启发,通过分析环境中行人的行为,提高了深度强化学习算法中值函数的学习能力;通过奖励函数对智能体进行合适的引导,在不进行精确建模的情况下,便可以得到符合人机交互要求的避障策略,达到机器人避障效率与行人舒适度的平衡。本文主要的创新点在于:
1) 使用角度行人网格对行人周围动态障碍物进行编码,并利用注意力机制对行人的时序特征进行了提取,得到了更加丰富的行人动态信息,提高了值函数网络的学习能力。
2) 依据行人空间行为,通过对进入行人私人距离内以及角速度变化过大的状态进行惩罚,重新设计了强化学习的奖励函数,使得机器人在避障的过程中可以实现行人舒适度要求与避障效率的平衡,从而更好地与人进行交互。
1 基于深度强化学习的避障算法利用强化学习算法解决避障问题的目标为得到机器人联合状态stjn到控制输出at的最优策略π*[24],如图 1所示,在基于强化学习的避障算法中,智能体通过与环境的交互得到当前时刻机器人以及周围所有行人的状态stjn;然后将机器人的控制信号离散化为一定大小的动作空间,通过一步预测模型(one-step look ahead)对动作空间中每个控制信号执行之后的状态进行预测,得到预测后的状态st+Δtjn;之后将预测状态st+Δtjn输入到值函数网络中,结合奖励函数得到该状态的价值,选取最大价值所对应动作空间中的动作即最优动作(optimal action)作为机器人最终的输出动作at,如式(1)所示。在智能体与环境的交互过程中,值函数网络V*不断进行优化直至收敛。
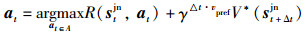
|
(1) |

|
| 图 1 基于深度强化学习的避障算法 Fig.1 Obstacle avoidance algorithm based on deep reinforcement learning |
其中,st+Δtjn=prop(stjn,Δt,at),表示预测模型通过简单的线性模型对Δt时刻后机器人及其周围行人的运动进行预测,近似得到Δt时刻后机器人的联合状态。以下为强化学习各个元素的具体选择方法:
状态空间:考虑机器人自身的状态和环境中其他行人的状态都将对最终的决策造成影响,使用联合状态stjn=[st,sto]作为t时刻强化学习的输入状态。其中,st=[px,py,vx,vy,r,gx,gy,vpref,φ]为机器人的状态,具体包括机器人的位置、运动速度、大小、目标点、最佳运行速度与转向角度;sto=[st1o,st2o,…,stno]为环境中所有行人的状态,不同于st,由于在人群环境中,机器人无法获取行人的目标点,最佳运行速度与转向角度的信息,所以第i个行人的状态stio仅包括行人的位置、运动速度、大小以及周围行人的编码信息,即stio=[px,py,vx,vy,r,ri]。
动作空间:动作空间取为一系列可行的机器人速度控制信号,即t时刻机器人的动作at=[v,w],其中,v,ω分别代表机器人的线速度与角速度。
值函数:强化学习算法的目标是获取最优值函数V*,且最优策略π*可以通过值函数网络获取,使机器人在与环境的交互中得到最佳的期望奖励:
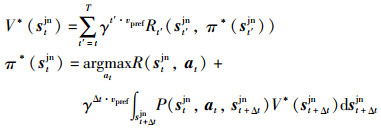
|
(2) |
其中,R(stjn,at)是t时刻的奖励值;γ∈(0,1)是衰减系数;P(stjn,at,st+Δtjn)为状态转移概率;vpref表示机器人在无障碍物时运行的速度,在之后的衰减系数中作为归一化项。
值函数通过机器人与环境的不断交互可以学习到一定的环境信息,但是仅仅使用浅层的多层感知机不能很好地对复杂的行人交互规则进行学习,本文对值函数进行修改,以提高值函数在人群密集的复杂环境下的学习能力,并针对行人舒适度的要求对奖励函数做了进一步的修改。除此之外,本文针对行人数量可变的情况,使用一个LSTM网络[25]进行处理。
2 具体算法本节通过在值函数网络中引入行人交互信息以及修改强化学习的奖励函数,基于深度强化学习得到了符合人机交互要求的避障算法。
2.1 基于行人交互的值函数网络改进如图 2所示,改进的值函数网络μ由行人交互信息模块(crowd interaction module)、LSTM网络ΦLSTM(·)、多层感知机(MLP)三个部分组成:行人交互模块先对原始智能体状态stjn进行行人特征的提取;再通过LSTM网络ΦLSTM(·)进行不定数量行人特征的组合,得到所有行人的联合隐藏状态ho;最后将ho与机器人自身状态联合输入到多层感知机网络ψM(·)中,得到对应的价值。本节主要介绍改进的值函数网络中的行人交互行为分析的具体方法。

|
| 图 2 改进的值函数网络结构 Fig.2 Improved network structure of value function |
行人之间的决策是互相影响的,如果将每对行人之间的关系进行准确的描述,将导致O(N2)的时间复杂度,随着环境中行人数量的增加,计算负担将会变得非常繁重。除此之外,一些距离较远的行人之间几乎不会对彼此的运动产生影响,将两者之间的关系进行描述不仅会加大计算复杂度,也会加重网络的学习负担。据此,本文采取一个特殊的混合网格—角度行人网格(APG)[32]对行人的局部环境进行编码,以剔除对避障策略无用的信息。
为了更好地捕获行人的动态特征,角度行人网格(APG)引入一个高分辨率的网格,增加了信息的广泛性。图 3表示了对第i个行人PHi进行编码的过程。设行人的总数为N,角度行人网格(APG)仅考虑以行人PHi为中心、以rmax为半径的圆内的行人。将该圆均分为K个扇形区域,选择每一个扇形区域内与行人PHi最近的距离作为该扇形区域的编码值。行人PHi经过角度行人网格(APG)编码后输出为一维向量ri=[ri,1,…,ri,k,…,ri,K],其中ri,k(第k个扇形的编码值)的数学表示方法如式(3)所示:
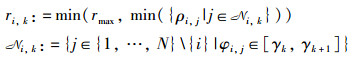
|
(3) |

|
| 图 3 角度行人网格 Fig.3 Angular pedestrian grid |
其中,k∈{1,…,K},每个网格所对应的扇形角度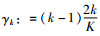
与标准2D网格相比,APG仅仅线性地影响输入的维数,而仍然能够以连续的分辨率而不是离散的网格单元捕获径向距离的变化。此外,行人PHj距离行人PHi的距离越近,行人PHj角度位置变化的观察性变得越精确。对于给定参数的APG网格,可以得到行人PHi在t时刻的状态stoi=[pxi,pyi,vxi,vyi,r,ri],该状态变量将作为改进的值函数网络的输入。
机器人的运动不仅仅受到当前时刻行人信息的影响,与之前时刻行人的信息也有很大的关系,而且依据多个时刻的共同影响,可以克服避障策略的短时性(short-sighted),减少了由于仅仅依据当前时刻的即时环境信息带来的控制信号跳变的问题,可以利用历史数据进行避障,达到更好的避障效果。
在时序预测中,注意力机制取得了较好的应用效果。本文通过自注意力机制(self-attention)[33]提取单个行人的时序特征,学习得到包括当前时刻在内的T个时刻数据的相对重要性以及对机器人避障策略的联合影响。
T时刻内行人PHi的连续轨迹序列[st-Toi,…,st-koi…,stoi]已知。如图 4所示,首先对每一个时刻的行人特征进行编码,通过多层感知机ψe(·)(MLP)得到定长的输出em:
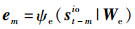
|
(4) |

|
| 图 4 注意力机制模型 Fig.4 Attention mechanism model |
然后,将向量em输入感知机ψh(·)中,从中提取得到行人PHi不同时刻状态之间的交互特性向量hm:
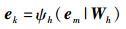
|
(5) |
接着通过多层感知机ψα(·)计算不同时刻行人状态的相对重要性,得到每个交互特征向量的注意力得分αm。
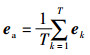
|
(6) |
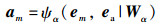
|
(7) |
ea为所有时刻的平均池化向量,ψe(·),ψh(·),ψα(·)为全连接网络,其非线性激活函数均为ReLU,We,Wh,Wα分别为全连接网络的权重值,具体的网络参数将在实验部分给出。
利用每一个时刻的交互特性向量em与相应的注意力得分αm,可以通过所有时刻交互特性向量的线性组合求出行人PHj最终的状态输出eo:
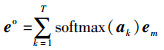
|
(8) |
最后,通过LSTM网络处理环境中不定数量的障碍物,最后得到定长的输出向量ho。
2.2 舒适奖励函数机器人在与人交互的场景中,如果行人没有向机器人发起服务需求,为了保证行人舒适度的要求,机器人应该尽量避免出现在行人的舒适范围内,即机器人不应该进入行人的私人距离内。除此之外,由文[13]可知,机器人从后向前超越行人的横向舒适距离是0.7 m,如果小于该距离同样会引发行人的不舒适感。因此,本文依据上述行人舒适度的要求修改了奖励函数,对机器人进入行人舒适范围内的状态进行了惩罚。
依据行人舒适度的知识,定义行人舒适区域Ω:以行人为坐标原点,前进方向为x轴,建立行人坐标系。行人舒适区域通过以行人为原点,私人距离最大值dperson为长轴,侧边舒适距离dside为短轴的半椭圆Ω表示(只考虑出现在行人视野范围内的情况,dside为0.7 m,dperson为1.2 m)。
假设机器人在行人坐标系中的坐标为(x0,y0),通过指示函数I(x0,y0)即可判断机器人是否行驶到了行人的舒适区域Ω内,I(x0,y0)为1表示机器人进入了行人舒适区域,I(x0,y0)为0表示机器人未进入行人舒适区域。
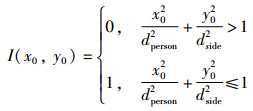
|
(9) |
如果机器人到达了行人的行人舒适区域内,即I(x0,y0)=1,会引发行人的不舒适感,需要给予机器人相应的惩罚,惩罚的大小取决于机器人在行人舒适区域内的位置,距离行人越近惩罚越大。如图 5所示,机器人为黄色标志,如果机器人(黄色圆圈)到达了行人舒适区域内,可以假设在行人舒适区域Ω内机器人坐标所在的与行人舒适区域具有相同长短轴比的椭圆上具有相同的惩罚,即图 5所示蓝色椭圆上的所有点具有相同的惩罚项,所以(x0,y0)与(w,0)处具有相同的惩罚。由于与人的距离越近越容易引发人的不适,且不适感会越来越大,因而采用指数函数表征该惩罚值,惩罚的最大值为rp,所以得到的与w有关的惩罚函数如下:
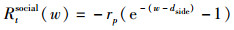
|
(10) |

|
| 图 5 行人私人距离区域 Fig.5 Personal distance zones for people |
其中,w为蓝色椭圆的短轴:
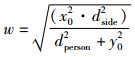
|
(11) |
原始的奖励函数Rto(stjn,at)为文[17]中所使用的奖励函数,其中去除了当机器人与障碍物相距较近时的惩罚项:
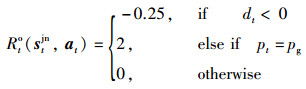
|
(12) |
同时,为了避免机器人角速度变化过大的情况,对角速度变化过大的情况进行了惩罚:
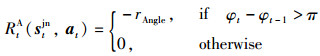
|
(13) |
最终的奖励函数为
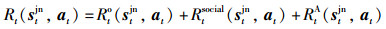
|
(14) |
通过该奖励函数,可以使得机器人的避障策略更加符合人的舒适度准则。
2.3 网络训练整个强化学习算法的训练方法采取了时序差分法,为了增加样本的利用率,将每次强化学习与环境交互的信息存储在缓存回放区(replay buffer)中,在训练网络时通过均匀采样的方法从缓存回放区中进行采样,得到训练数据,并通过固定目标网络的方法来加速算法的收敛并减小算法的方差。同时,为了进一步加快收敛,训练前利用传统方法ORCA[3]生成的数据集进行网络的预训练,详细的训练算法如算法1所示。
算法1:网络训练
1:使用传统算法ORCA生成预训练数据D
2:使用预训练数据D进行模仿学习,初始化表现模型(behaviour network)μ(·),μ(·)=[ψe(·),ψh(·),ψα(·),ΦLSTM(·),ψM(·)]
3:初始化目标网络(target network)的参数:
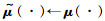
4:初始化经验回放池:E←D
5:for episode=1,M do
6: 随机初始化动态障碍物的状态s0jn
7: repeat:
8: at←plan(st+Δtjn)
9: 将样本数据(stjn,at,rt,st+Δtjn)存入经验回放池
10: 从经验回放池中随机选取batch个样本
11: 通过目标网络(target network)计算样本输出:
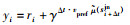
12: 通过梯度下降法更新表现模型
13: until终止状态或者t≥tmax
14: 更新目标网络(target network)
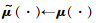
15:end for
16:return μ(·)

|
| 图 6 网络训练 Fig.6 Network training |
本章将通过比较不同编码方式的避障算法的性能,以及修改奖励函数前后避障算法的性能,分别验证改进的值函数网络的有效性与泛化性以及舒适奖励函数的可行性。
硬件平台:实验的硬件平台为Intel Core i7-7700 3.60 GHz,NVIDIA Geforce GTX 1050 Ti的台式机。
仿真环境:所有的实验均在基于Gym搭建的仿真环境中进行,在仿真环境中,使用半径为0.3 m的圆形代替行人与机器人,行人与机器人的任务为从起始点运行到目标点。其中,行人的运动使用传统避障算法ORCA[3]策略进行控制。起始点与目标点的选取采用了交叉相遇的方式,即行人和机器人的初始位置随机定位在同一个半径为4 m的圆圈上,目标点为其初始位置关于圆心中心对称的点。
机器人动作空间设置:仿真中的作为机器人的角速度与线速度,实验中选取机器人离散的动作空间为机器人线速度空间与角速度空间的组合,大小为80,其中线速度空间在[0,vpref]中均匀采样,角速度空间在[0,2π]中均匀采样,采样大小分别为5和16。
网络设置:本文首先通过ORCA[3]这一传统方法收集得到了3 000个训练回合的数据完成了网络权重的初始化。预训练结束后,为了平衡对未知状态的探索与已有结果的利用,采用e-greedy的方法进行训练。在训练开始时,为了能够更佳有效地探索环境中到的未知状态,设置探索率为0.5,之后随着训练次数的增加,不断减小探索率,在5 000回合时减小为0.1,之后的训练将不再改变探索率。其余的超参数和实验过程中值函数的网络参数分别如表 1、表 2所示。
| 参数 | 预训练 | 训练 |
| N | 6 | 6 |
| vpref | 1 | 1 |
| K | 12 | 12 |
| rmax | 3 | 3 |
| T | 5 | 5 |
| 学习率 | 0.01 | 0.001 |
| batch-size | 100 | 100 |
| Δt | 0.25 | 0.25 |
| γ | 0.9 | 0.9 |
| 网络 | 网络参数设置 |
| ψe(·) | [150, 100] |
| ψh(·) | [150, 50] |
| ψα(·) | [100, 100, 1] |
| ΦLSTM(·) | [50, 50] |
| ψM(·) | [150, 100, 100, 1] |
本小节通过与ORCA[3],CADRL[27]以及基于社会力(social force)与局部地图(local map)两种不同编码方法的避障算法进行比较,验证了本文改进的值函数网络的有效性。为了避免舒适奖励函数对该模块的影响,此处的奖励函数采取论文[24]中的奖励函数,因此,基于强化学习的避障算法的不同之处仅仅在于对行人交互信息的处理方式。为了表述方便,将基于社会力编码的算法称为SF_RL,基于局部地图编码的方式称为LM_RL,本文提出的基于APG编码的算法称为APG_RL。
图 7为CADRL、SF_RL、LM_RL以及APG_RL四种基于强化学习的避障算法在行人数量为6的仿真环境中,经过10 000个回合的训练,累积回报函数的变化曲线。其中,CADRL、LM_RL以及APG_RL三种算法的收敛性能明显高于SF_RL,这是由于使用社会力模型对行人之间的交互信息的描述可能存在误差,因而降低了网络的收敛性。

|
| 图 7 不同算法的学习回报曲线 Fig.7 Learning return curve of different algorithms |
训练结束后,在行人数量为6的仿真环境中对上述5种算法分别进行了500次测试,测试的结果如表 3所示。其中,基于强化学习的算法使用多层感知机拟合值函数,并通过机器人与环境的不断交互,在一定程度上学习得到了行人之间的交互特性,提升了机器人在行人密集环境中的避障性能,在测试过程中的成功率高于传统的ORCA算法。但由于提取行人交互信息方式的不同,其算法的性能也存在差别。CADRL由于未对行人交互特征进行处理,在测试过程中的避障成功率较低,表明仅仅使用一个浅层的网络不能很好地提取复杂动态环境中的信息。而SF_RL、LM_RL以及APG_RL由于增加了对行人交互特征的提取以及行人的时序特征,具备了一定的先验知识,大大提升了避障的成功率。相较于SF_RL,使用局部信息编码的避障算法LM_RL与APG_RL在网络训练过程中具有更好的收敛性,且避障用时更短,效率更高。
| 算法 | 成功率 | 失败率 | 平均时间/s | 回报 |
| ORCA | 0.33 | 0.66 | 11.04 | -0.065 2 |
| CADRL | 0.59 | 0.40 | 10.69 | 0.073 8 |
| SF_CADRL | 0.96 | 0.03 | 11.86 | 0.260 8 |
| LM_RL | 0.99 | 0.01 | 10.97 | 0.319 0 |
| APG_RL | 0.99 | 0.01 | 10.82 | 0.319 6 |
图 8为不同的避障算法在同一测试场景的避障结果,其中黄色的实心圆形代表机器人,其余颜色的圆圈代表不同行人,圆内数字表示机器人当前的运行时间。图 8(a)中机器人控制算法采用ORCA,机器人在3.5 s时与行人发生了碰撞,导致导航失败,其余方法分别在9.8 s、10.2 s、9.2 s、9.0 s到达了目标点。其中,APG_RL在最短的时间内到达了目标点,结合表 3可知,APG_RL经过500次测试的平均导航时间仅为10.82 s,极大地提升了避障的效率,很好地验证了本文改进的值函数网络的有效性。

|
| 图 8 不同算法同一仿真条件机器人轨迹比较 Fig.8 Comparison of robot trajectories with different algorithms under the same simulation condition |
除了更高的导航效率,经过实验发现,APG_RL可以适应某些更加复杂的环境,在LM_RL避障失败的情况下仍然可以完成导航任务,具体的轨迹图如图 9所示。如图 9(a)所示,6个行人从不同的方向圆心行驶,在第4 s的时候,LM_RL算法控制的机器人由于行驶到了行人中间,与行人发生了碰撞。而APG_RL由于采取了角度行人网格对周围的行人进行编码,获取得到的是周围行人连续的值,相比于局部地图的栅格化处理,可以更加精确地捕获行人的变化,因而在图 9所示复杂环境中,机器人在距离行人较近时便改变了运动方向,避免了进入人群的情况,如图 9(b)所示,机器人在4 s时向右转弯,最终成功地到达了目标点。

|
| 图 9 LM_RL与APG_RL同一仿真条件机器人轨迹比较 Fig.9 Trajectory comparison in a test case between LM_RL and APG_RL |
APG_RL算法在训练时仿真环境中行人的数量为6,为了进一步测试模型的泛化性能,在不重新训练网络的基础上,改变仿真环境行人的数量N,表 4给出了在不同行人个数时进行500次避障测试的结果。实验结果显示,在行人数量发生变化的情况下,机器人的避障成功率均保持在0.91以上。该实验充分证明了APG_RL算法可以很好地应对环境中行人变化的情况,尤其在行人数量为8的仿真环境中依旧可以取得较高的成功率,因而可以更好地应对复杂的行人环境。
| 行人个数 | 3 | 4 | 5 | 6 | 7 | 8 |
| 成功率 | 1.00 | 1.00 | 0.99 | 0.99 | 0.98 | 0.91 |
| 平均时间 | 10.20 | 10.18 | 10.81 | 10.82 | 12.30 | 12.75 |
本实验对本文提出的奖励函数的可行性进行了实验验证,rp与rAngle的取值均为0.02。在不改变APG_RL避障算法的基础上,依照式(13)设计的舒适奖励函数进行训练,分别得到了舒适避障策略APG_CRL与APG_CARL,其中APG_CRL的奖励函数仅添加了Rtsocial(w)项,APG_CARL的奖励函数添加了Rtsocial(w)与RtA(stjn,at)两项内容。表 5为上述3种算法在行人数量为6的仿真环境中测试500次得到的结果。
| 算法 | 成功率 | 失败率 | 平均时间/s | 距离/m |
| APG_RL | 0.99 | 0.01 | 10.82 | 0.14 |
| APG_CRL | 0.99 | 0.01 | 10.96 | 0.64 |
| APG_CARL | 0.99 | 0.01 | 10.77 | 0.50 |
通过表 5可知,APG_RL与APG_CRL均拥有较高的导航成功率,而机器人在平均到达目标点的时间仅仅增加了0.14 s的情况下,距离行人的最近距离从0.14 m增大到0.64 m,很好地平衡了导航效率与行人舒适度的要求。
除此之外,行人舒适度奖励函数不仅提高了导航时与行人的最大距离,与APG_RL避障算法相比,APG_CRL由于惩罚进入行人私人距离内的状态,可以很好地适用于某些环境更加复杂的情况。在图 10(a)所示的动态复杂环境下,APG_RL由于仅仅在机器人距离行人较近的情况下才对机器人进行惩罚,机器人会向人群聚集的地方行驶,而APG-CRL通过对机器人进入行人舒适范围的状态进行惩罚,使得机器人倾向于选择与人保持较远距离的行为,如图 10(b)所示,机器人会在原地等待行人离开后,再向目标点行驶。

|
| 图 10 不同奖励函数同一仿真条件测试轨迹比较 Fig.10 Trajectory comparison in a test case among different reward functions |
角度变化太过剧烈不仅不利于实际机器人的控制、传感器数据的获取等,而且对于周围环境中的行人也会产生影响,因而APG_CARL对机器人角度变化过大的情况进行惩罚。由表 5可知,与APG_CRL相比,在对角度进行惩罚后,其平均到达目标点的时间减少了0.19 s,APG_CARL由于避免了大幅度的角度变化,可以减少机器人得震荡行为,一定程度上提升了避障得效率。其某次避障任务中机器人的动作选择如图 11所示,图 11(a)、11(b)分别表示了APG_CRL与APG_CARL所处的仿真环境,其中红色箭头代表了机器人的运动方向。图 11(c)、11(d)分别表示机器人在执行动作空间中的动作后所获得的价值,颜色越浅代表执行该动作后获得的价值越高。APG_RL由于仅仅考虑了行人的舒适距离,因而在图 11所示的情况下,机器人倾向于选择角度变化更大但距离行人更远的角速度,而APG_CARL对角速度变化较大的情况进行了惩罚,在相同情况下,角速度的最优选择范围集中在当前角速度附近,不会造成控制信号大幅度的跳变,更加便于今后实体机器人的控制。

|
| 图 11 机器人执行每一个可行动作的值函数结果 Fig.11 The value function result of each feasible action performed by the robot |
本文提出的移动机器人舒适避障算法首先针对浅层的值函数网络难以拟合复杂行人环境的不足,对值函数进行了改进,设计了行人交互信息模块,通过角度行人网格提取行人之间的交互信息,并且利用注意力机制提取行人行走轨迹的时序特征。其次,通过修改奖励函数的方法将行人舒适度要求引入了避障策略中,使得机器人的避障策略更加符合人机交互的需求。通过仿真实验比较分析,本文提出的算法在人群密集的复杂动态环境中不仅拥有良好的避障成功率与适应性,而且可以满足行人舒适度的要求。
本文今后将继续研究不同行人舒适区域及动态障碍物提取方法对算法性能的影响。除此之外,本文提出的算法仅仅在仿真取得了较好的效果,后续研究将准备将该理论方法应用到实际的移动机器人,如NAO、Pepper机器人上,通过实际应用进一步改进算法,使其可以适应真实环境中传感器信息不准确等环境因素。
| [1] | Mellinger D, Kushleyev A, Kumar V. Mixed-integer quadratic program trajectory generation for heterogeneous quadrotor teams[C]//IEEE International Conference on Robotics and Automation. Piscataway, USA: IEEE, 2012: 477-483. |
| [2] | Fiorini P, Shiller Z. Motion planning in dynamic environments using velocity obstacles[J]. The International Journal of Robotics Research, 1998, 17(7): 760–772. DOI:10.1177/027836499801700706 |
| [3] | Peng H, Zhen L. Crowd simulation research based on reciprocal velocity obstacle collision avoidance[J]. Computer Simulation, 2012. |
| [4] |
王洪斌, 尹鹏衡, 郑维, 等.
基于改进的A*算法与动态窗口法的移动机器人路径规划[J]. 机器人, 2020, 42(3): 346–353.
Wang H B, Yin P H, Zheng W, et al. Mobile robot path planning based on improved A* algorithm and dynamic window method[J]. Robot, 2020, 42(3): 346–353. |
| [5] | Fox D, Burgard W, Thrun S. The dynamic window approach to collision avoidance[J]. IEEE Robotics & Automation Magazine, 1997, 4(1): 23–33. |
| [6] | Burgard W. Controlling synchrodrive robots with the dynamic window approach to collision avoidance[C]//IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway, USA: IEEE, 1996: 1280-1287. |
| [7] | Trautman P, Krause A. Unfreezing the robot: Navigation in dense, interacting crowds[C]// IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway, USA: IEEE, 2010: 797-803. |
| [8] | Ferrer G, Garrell A, Sanfeliu A. Social-aware robot navigation in urban environments[C]//European Conference on Mobile Robots. Piscataway, USA: IEEE, 2013: 331-336. |
| [9] | Kruse T, Pandey A K, Alami R, et al. Human-aware robot navigation: A Survey[J]. Robotics and Autonomous Systems, 2013, 61(12): 1726–1743. DOI:10.1016/j.robot.2013.05.007 |
| [10] | Pacchierotti E, Christensen H I, Jensfelt P. Human-robot embodied interaction in hallway settings: A pilot user study[C]//International Workshop on Robot and Human Interactive Communication. Piscataway, USA: IEEE, 2005: 164-171. |
| [11] |
张大鹏, 肖峰.
基于个人空间理论的人群疏散机理研究[J]. 交通运输工程与信息学报, 2016, 14(2): 144–152.
Zhang D P, Xiao F. Research on the mechanism of crowd evacuation based on the theory of personal space[J]. Journal of Transportation Engineering and Information, 2016, 14(2): 144–152. DOI:10.3969/j.issn.1672-4747.2016.02.020 |
| [12] |
孙月, 刘景泰.
基于RGB-D传感器的室内服务机器人舒适跟随方法[J]. 机器人, 2019, 41(6): 823–833.
Sun Y, Liu J T. Comfortable follow method of indoor service robot based on RGB-D sensor[J]. Robot, 2019, 41(6): 823–833. |
| [13] | Pacchierotti E, Christensen H I, Jensfelt P. Evaluation of passing distance for social robots[C]//International Symposium on Robot and Human Interactive Communication. Piscataway, USA: IEEE, 2006: 315-320. |
| [14] | Zhao Y, Tian G H, Yin J Q, et al. Human trajectory analysis method based on hidden markov model in home intelligent space[J]. Pattern Recognition and Artificial Intelligence, 2015, 28(6): 542–549. |
| [15] | Wiest J, Hoffken M, Kresel U, et al. Probabilistic trajectory prediction with Gaussian mixture models[C]//Intelligent Vehicles Symposium. Piscataway, USA: IEEE, 2012: 141-146. |
| [16] | Burstedde C, Klauck K, Schadschneider A, et al. Simulation of pedestrian dynamics using a two-dimensional cellular automaton[J]. Physica A, 2001, 295(3/4): 507–525. |
| [17] | Helbing D, Molnar P. Social force model for pedestrian dynamics[J]. Physical Review E: Statistical Physics, Plasmas, Fluids, and Related Interdisciplinary Topics, 1998, 51(5): 4282–4286. |
| [18] | Hoogendoorn S, Bovy P. Gas-kinetic modeling and simulation of pedestrian flows[J]. Transportation Research Record: Journal of the Transportation Research Board, 2000, 1710: 28–36. DOI:10.3141/1710-04 |
| [19] | Alahi A, Goel K, Ramanathan V, et al. Social LSTM: Human trajectory prediction in crowded spaces[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, USA: IEEE, 2016: 961-971. |
| [20] | Gupta A, Johnson J, Li F F, et al. Social GAN: Socially acceptable trajectories with generative adversarial networks[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, USA: IEEE, 2018: 2255-2264. |
| [21] | Vemula A, Muelling K, Oh J. Social attention: Modeling attention in human crowds[C]//IEEE International Conference on Robotics and Automation. Piscataway, USA: IEEE, 2018: 1-7. |
| [22] | Mnih V, Kavukcuoglu K, Silver D, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518(7540): 529–533. DOI:10.1038/nature14236 |
| [23] | Faust A, Oslund K, Ramirez O, et al. PRM-RL: Long-range robotic navigation tasks by combining reinforcement learning and sampling-based planning[C]//IEEE International Conference on Robotics and Automation. Piscataway, USA: IEEE, 2018: 5113-5120. |
| [24] | Chiang H T L, Hsu J, Fiser M, et al. RL-RRT: Kinodynamic motion planning via learning reachability estimators from RL policies[J]. IEEE Robotics and Automation Letters, 2019, 4(4): 4298–4305. DOI:10.1109/LRA.2019.2931199 |
| [25] | Tai L, Li S, Liu M. A deep-network solution towards model-less obstacle avoidance[C]//IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway, USA: IEEE, 2016: 2759-2764. |
| [26] | Chiang H T L, Faust A, Fiser M, et al. Learning navigation behaviors end-to-end with AutoRL[J]. IEEE Robotics and Automation Letters, 2019, 4(2): 2007–2014. DOI:10.1109/LRA.2019.2899918 |
| [27] | Chen Y F, Liu M, Everett M, et al. Decentralized non-communicating multiagent collision avoidance with deep reinforcement learning[C]//IEEE International Conference on Robotics and Automation. Piscataway, USA: IEEE, 2017: 285-292. |
| [28] | Everett M, Chen Y F, How J P. Motion planning among dynamic, decision-making agents with deep reinforcement learning[C]//IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway, USA: IEEE, 2018: 3052-3059. |
| [29] | Chen Y F, Everett M, Liu M, et al. Socially aware motion planning with deep reinforcement learning[C]//IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway, USA: IEEE, 2017: 1343-1350. |
| [30] | Hall E T. The hidden dimension[M]. 1st ed. New York, USA: Anchor Books-Doubleday, 1966. |
| [31] | Pandey A K, Alami R. A framework for adapting social conventions in a mobile robot motion in human-centered environment[C]//IEEE International Conference on Advanced Robotics. Piscataway, USA: IEEE, 2009: 1-8. |
| [32] | Pfeiffer M, Paolo G, Sommer H, et al. A data-driven model for interaction-aware pedestrian motion prediction in object cluttered environments[C]//IEEE International Conference on Robotics and Automation. Piscataway, USA: IEEE, 2018: 5921-5928. |
| [33] | Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[M]. La Jolla, USA: Neural Information Processing Systems Foundation, 2017: 5998-6008. |