



0 引言
SLAM作为机器人学的一项关键技术,常被用于解决机器人在未知环境中的感知及定位问题[1]。根据传感器不同,SLAM主要分为激光SLAM[2]和视觉SLAM[3],其中视觉SLAM在环境感知方面优势明显,常常作为机器人环境感知的重要手段。动态环境是现实生活中最常见的情景,然而传统SLAM算法无法准确区分动态环境中的运动对象,从而影响环境感知的结果。因此,探索适用于动态环境的视觉SLAM算法对推进机器人的发展具有积极作用。
传统的视觉SLAM算法是在静态世界基本假设的前提下发展起来的,SLAM的概念最早是由Smith等[4]于20世纪80年代提出的。视觉SLAM表现出强大的环境感知能力。Klein等[5]首次将特征点法应用于SLAM系统并提出了PTAM(parallel tracking and mapping),开创性地提出跟踪线程和建图线程,该系统第一次将非线性优化代替传统的滤波器应用于系统优化后端,为非线性优化作为视觉SLAM后端开创先河。针对PTAM存在的跟踪易丢失问题,萨拉戈萨大学的Raul等[6]在PTAM的基础上于2015年提出了ORB-SLAM,之后作者于2017年推出ORB-SLAM的迭代版本ORB-SLAM2[7],支持单目、双目、RGB-D(color-depth)等多种相机并且增加了地图复用功能,在29个公开数据集上得到的结果在当时具有最高的准确性。Engel等[8]提出了一种基于稀疏直接结构和运动公式的视觉里程计DSO(direct sparse odometry)系统,以更整体、更优雅地方式处理了数据关联问题,但对场景光照变化敏感,适用于相机运动平缓、光照条件稳定的场景。
国内外针对动态环境下如何进行鲁棒定位与建图已经做了大量研究,目前的主流研究方案致力于消除动态对象的影响。中国人民解放军陆军工程大学的Ai等[9]提出了一种能够在高动态场景下鲁棒运行的DDL-SLAM(dynamic deep learning SLAM),得到仅包含静态区域的RGB图像及对应的深度图像,但实时性有待提高。萨拉戈萨大学的Bescos等在ORB-SLAM2的基础上提出DynaSLAM[10],算法具备较好的动态目标检测和背景修复能力,但是不能达到实时性要求。Rünz等[11]提出以RGB-D数据流作为输入的Co-Fusion系统,使得该系统能生成一个可与环境交互的环境地图,前提需要模型的先验知识。随后,Rünz等[12]提出一个基于语义场景理解来建模和跟踪多个目标的MaskFusion系统,实现实例级对象重建,但是该系统对于小物体的跟踪和建模不够理想,在分割分类阶段没有考虑分类错误的情况。北京大学Zhong等[13]提出Detect-SLAM系统,利用深度神经网络SSD(single shot detector)构建目标检测器判断动态对象并移除其特征,改善SLAM的准确性和鲁棒性并以在线的方式构建环境的实例级语义地图。Henein等[14]提出了一种Dynamic SLAM算法,该算法利用语义分割来估计场景中刚性物体的运动,无需估计物体姿态或者3D模型先验知识。Yu等[15]提出了一种面向动态环境的鲁棒语义可视化的DS-SLAM(dynamic semantic SLAM),将语义分割网络和运动一致性检查方法相结合,减小了动态对象的影响;Scona等[16]提出了一种RGB-D SLAM方法,在动态环境下检测运动目标的同时重构背景结构的鲁棒稠密建图方法。Rebecq等[17]提出了一个基于事件的视觉里程计(event-based visual odometry,EVO)算法,该方法利用了事件相机的突出特性来跟踪快速相机的运动,同时恢复半透明的三维环境地图;此外,还有EM-Fusion[18](expectation maximization fusion)、BaMVO[19](backgroundmodel-based VO)、RO-SLAM[20] (range-only SLAM)、FlowFusion[21]、ReFusion[22]方法。现有SLAM算法面临动态场景时,存在着实时性和鲁棒性不足的问题。
人类与周围环境相比具有明显不同的特性,即温度不同。基于此,面向以人类为主要动态对象的室内场景,本文提出了基于热像仪与深度相机的多传感协同方案,以解决动态场景中的定位与建图问题。算法采用热像仪与RGB-D深度相机构建多传感视觉系统。首先,进行多传感视觉系统联合标定与图像配准;然后,基于热像图实现人体分割提取人体掩模,深度图像经人体掩模图像处理后便可同RGB图像根据各帧对应的位姿生成点云;最后,对点云数据进行拼接、滤波、转换等处理,生成最终的地图形态。
1 多传感视觉系统标定与图像配准由于热像仪和RGB-D深度相机属于异源传感器,在用于动态场景中的定位与建图前,需要对两个传感器构成的多传感视觉系统进行严格的内参标定、外参标定与图像配准工作。
本文使用的RGB-D深度相机为Kinect V2深度相机,包括彩色摄像头、红外发射器和红外接收器,其中深度信息是通过投射的红外线返回时间来取得深度信息,即可认为深度图像来源于红外图像,两者显示的内容一致,但由于深度图像无法显示标定板角点,故在进行相机标定中使用红外图像进行标定。
1.1 标定方法多传感相机标定算法采用的标定工具为Matlab Camera Calibrator[23],其核心操作是需要对若干张棋盘格图像进行角点检测,计算出相机的内参矩阵和畸变系数。
热像仪根据周围环境的热辐射情况进行成像,选择“黑热”模式成像。由于普通棋盘格在热像仪镜头下看不到角点,故制作表面哑光喷漆的不锈钢镂空棋盘格标定板,格子尺寸为30 mm×30 mm,数量为7×4,如图 1所示,其中黑色格子为镂空区域。

|
| 图 1 标定图像 Fig.1 Calibration images |
将不锈钢标定板置于热源电暖气前方,其间加装一张黑色纸,由于不锈钢和黑纸的厚度和传热系数不同,短时间内标定板的格子区域与标定板之间产生较大的温差,因此可以在热像仪镜头下产生棋盘状的图像,如图 1(c)所示。固定标定板,多次改变传感器位置进行标定图像采集,同步采集了30张标定板图像,其中部分图像如图 1所示。
1.2 热像仪与RGB-D相机内参标定热像仪使用FLIR热像仪,成像过程符合针孔模型,相机内参矩阵为
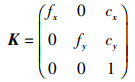
|
(1) |
式中,fx、fy为使用像素来描述x轴、y轴方向焦距的长度,cx、cy为主点的实际位置。
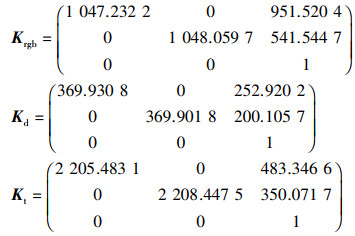
根据标定结果,得到RGB镜头、红外镜头和热镜头的内参矩阵Krgb、Kd、Kt为
|
(2) |
由标定结果得到各传感器的径向畸变系数k1、k2,具数值如表 1所示。
| 传感器 | k1 | k2 |
| RGB相机 | 0.013 5 | 0.839 9 |
| 深度/红外相机 | -0.061 9 | 1.140 7 |
| 热像仪 | -0.253 7 | 0.677 0 |
热像仪、RGB-D深度相机的相对位置如图 2所示,为了能够进行图像配准,需要将它们置于同一坐标系下进行表示。用Rd→rgb、td→rgb分别表示RGB镜头相对于红外镜头的空间旋转矩阵及中心点间的平移向量,Rd→t、td→t分别表示热镜头相对于红外镜头的空间旋转矩阵及中心点间的平移向量。

|
| 图 2 多传感视觉系统 Fig.2 Multi-sensor vision system |
假设在红外相机归一化坐标系的空间点Pd,它在红外相机像素平面上的投影点为ud,设该点在热像仪归一化坐标系下对应的空间点为Pt,经过投影得到热像仪像素平面上的投影点ut,根据内参矩阵Kt,通过空间位置变换关系,可得:
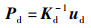
|
(3) |
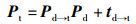
|
(4) |
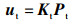
|
(5) |
假设世界坐标系下有空间点Pw,根据空间位置变换关系,可以得到该点在红外相机坐标系下的空间点Pd,在热像仪坐标系下的空间点Pt,即:
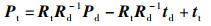
|
(6) |
式中,Rd、td表示红外相机的当前位姿;Rt、tt表示热像仪的当前位姿。
对比式(4)、式(6),可以得到:
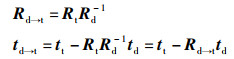
|
(7) |
根据式(7)可知,只要获取同一时刻下红外相机的位姿和热像仪的位姿,就可以得到两者之间的空间位置关系Rd→t、td→t。同理可获得红外相机和RGB相机之间的空间位置关系Rd→rgb、td→rgb:
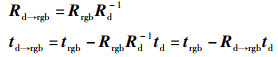
|
(8) |
现需要通过标定,获得同一场景下RGB图像、红外图像和热图像分别对于标定板的位姿,将得到的位姿通过式(7)、式(8)进行计算得到各传感器之间的相对位置。同一场景下各传感器获得的标定图像,如图 3所示。

|
| 图 3 同一场景的标定图像 Fig.3 Calibrated images of the same scene |
对每帧标定图像,Matlab Camera Calibrator可以给出其对应的相机位姿,计算得到结果为
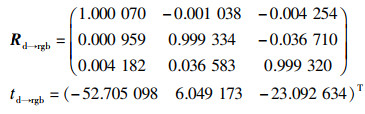
|
(9) |
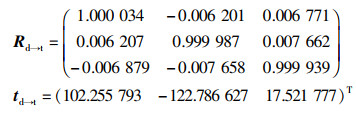
|
(10) |
为了保证多传感器可以获得完全一致的图像,找到3种模态图像之间的相同区域,需要对来自不同传感器的原始图像进行配准处理,得到像素级对应的具有相同图像内容的RGB灰度图像、红外图像和热图像。
假设深度图像中有一个像素点ud,其深度值为zd,可以得到该点在相机坐标系下的3维坐标Pd:
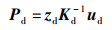
|
(11) |
已知红外镜头和RGB镜头的空间关系Rd→rgb、td→rgb,整理得到RGB图像与红外图像的像素点urgb、ud之间的空间位置关系:
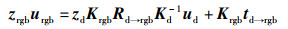
|
(12) |
同理得到热图像与红外图像的像素点之间的空间位置关系:
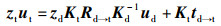
|
(13) |
根据式(13),可以找到深度图像中某一像素点ud对应的RGB图像像素点urgb和热图像像素点ut,遍历深度图像中每一个像素点,即可找到该深度图像对应的RGB图像像素群和热图像像素群,通过重组该像素群得到与深度图像内容一致的全新RGB灰度图像、深度图像和热图像,如图 4所示。

|
| 图 4 配准后的GDH三模图像 Fig.4 RDH three-mode images after registration |
针对室内主要的动态对象——人类,利用热图像来定位分割人类,获得人体掩模图像,从而确定场景中的静态区域,然后通过静态区域的信息开展室内动态场景下的鲁棒定位,完成视觉里程计的实现。
2.1 基于热图像获取人体掩模图像热像仪采用“黑热”模式成像,故通过确定人体区域内像素灰度值所在区间,就可以明确图像内任一像素点的归属域。在数据集[24]中,经过多组实验选择像素灰度值区间[22, 95]为人体区域,首先对热图像进行双边滤波处理,然后二值化分割得到初始人体分割图像,如图 5(b)所示,对其进行腐蚀与膨胀处理,去除伪人体区域,得到图 5(c)所示的图像,称为人体掩模图。

|
| 图 5 人体掩模图像 Fig.5 Human mask images |
ORB-SLAM2算法作为基本框架,是特征点法的集大成者,提取的特征点为ORB特征[25]。在2.1节中通过热图像得到的人体掩模图像,其作用是确定对应的RGB图像上的感兴趣区域(region of interest,ROI),即不含人类的区域,对ROI区域进行ORB特征提取,即可实现仅提取静态特征的目的,如图 6所示。

|
| 图 6 静态ORB特征提取结果 Fig.6 The features extraction result of ORB |
ORB特征的信息利用Steer BRIEF描述子进行表达,考虑到本系统面临的环境中特征点数不多,故采用暴力搜索方法来完成两幅图像之间的特征匹配,结果如图 7(a)所示。可以看到,由于室内物品相似度较高,不同地点的特征较为相似等一些原因会导致大量的误匹配,需要对误匹配进行剔除。采用的剔除策略为:匹配过程中计算出所有匹配特征的最小汉明距离,当某个匹配特征的汉明距离大于最小距离的2倍时,则认为是误匹配予以剔除,结果如图 7(b)所示。

|
| 图 7 特征匹配结果 Fig.7 The result of feature matchimg |
对匹配到的特征点选择PnP(perspective-n-point)算法进行建模,使用非线性优化算法对其求解,构建最小二乘问题并迭代求解,完成优化,从而计算出当前的相机运动。
3 静态环境稠密地图构建提出的基于RDH三模图像构建静态环境地图的方案。首先利用热图像分割生成人体掩模图像,然后用其进行深度图像更新,从源头上避免动态像素的建模。最后根据相机位姿将RGB-D数据转换为点云并完成拼接,再通过滤波、转换等后处理,实现动态场景下3维静态地图的构建。
3.1 系统框架基于ORB-SLAM2算法框架,增加一个稠密建图(dense mapping)线程,提出一种多传感视觉SLAM算法。算法同时运行着跟踪(tracking)、局部建图(local mapping)、闭环检测(loop closing)及稠密建图 4个线程,系统框架如图 8所示。其中,前3个线程实时运行,主要基于输入的RDH三模图像构建视觉里程计,得到局部优化的相机位姿、特征点地图以及相应的关键帧序列;所增加的稠密建图线程主要负责将关键帧序列中的深度图像进行人体滤除,并根据相应的位姿进行点云构建与拼接,再经过后处理得到最终的场景静态地图,由于其较大的计算量且不需要实时预览,故在后台运行。

|
| 图 8 系统框架 Fig.8 System framework |
已知某像素点的像素坐标和深度值,根据当前相机位姿和内参矩阵可以计算出该像素点的世界坐标;反之当其深度值z=0时,则无法得到其3维空间点。利用这一原理,依赖人体掩模图像,将每一帧深度图像人体区域的深度值修改为0。
具体过程如下:构造两个指针,分别指向人体掩模图像与深度图像的第一个像素,若该指针所指向的像素属于人体区域(即在人体掩模图中灰度值为0),则将深度图中指针所指向像素的深度值修改为0,否则不做任何修改;移动指针指向下一个像素,重复上述过程,直到处理完所有像素点,深度图像更新效果如图 9所示。

|
| 图 9 深度图像更新 Fig.9 Depth image update |
深度图像经人体掩模图像处理后便同RGB图像根据各帧对应的位姿生成点云(point cloud,PC),最后将点云数据进行拼接、滤波、转换处理,生成最终的地图形态。
本文采用RGB-D相机作为重要的图像采集传感器,可以同时获取同一场景的RGB图像和深度图像,即可以同时得到像素的坐标值p=(u,v)T和深度值z,根据相机成像模型和当前的相机位姿,得到深度值已知的像素点所对应的世界坐标为
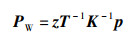
|
(14) |
式中,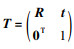
遍历深度图,对每一个像素点进行上述反投影过程,得到点云。再将RGB图像对应像素的颜色信息附着在点云上,依次处理关键帧序列中的其他帧,最终得到全局静态稠密点云。
点云的生成是不断向空间添加点的过程,对于经过深度滤除的某一帧,即便没有获得人体区域遮挡的场景,但随着人体移动,被遮挡的场景仍会被传感器视野捕捉,这些区域的数据仍会被投影到空间生成点云。
对于生成的点云中存在的离群异常点和冗余数据,首先采用统计滤波器[26]剔除离群异常点;然后采用体素滤波器[27],进一步剔除冗余数据。
对河北工业大学北辰智能装备研究院5号楼4单元1层进行3维重建验证滤波算法,选择参数k=50,n=1,统计滤波后的点云如图 10(b)所示。原始点云共包含3 402 359个数据点,经过统计滤波器处理后剩余2 261 548个数据点,数据量减少33.5%,占用空间从54.5 Mb减小至36.2 Mb。体素滤波将体素的体积设置为1.5 cm×1.5 cm×1.5 cm,滤波后的点云如图 10(c)所示,此时点云数据点数量降至1 108 887,相比原始点云减少67.4%。

|
| 图 10 滤波处理 Fig.10 Filtering processing |
为适用于避障和导航,将滤波后的点云格式转换为OctoMap[28]地图形式。首先以1.5 cm为最小分辨率创建一个八叉树模型,读取点云文件,遍历点云数据,将每一个点的位置和颜色信息插入到对应位置的OctoMap中,形成带颜色的“体数据”,最后由OctoMap中所有的体数据构成最终的八叉树地图模型,如图 11所示,此时文件占用存储空间仅为8.4 Mb,相比于原始点云减少84.6%。

|
| 图 11 八叉树地图模型 Fig.11 The model of OctoMap |
为验证本文提出的算法,搭建一套如图 12所示的多传感视觉SLAM系统实验平台,平台主体为HandsFree轮式移动机器人,底盘由1个万向轮和2个驱动轮构成;多传感系统由Kinect V2深度相机和FLIR T1040热像仪组成,其详细参数如表 2所示;计算平台为ThinkPad E470,其处理器为Inter Core i7-7500U,运行内存8 G,主频2.70 GHz,最高2.9 GHz,运行的软件系统为Windows 10+Ubuntu 16.04 LTS双系统组合。

|
| 图 12 实验平台 Fig.12 Experiment platform |
| 参数 | RGB-D相机 | 热像仪 |
| 型号 | Kinect V2 | FLIR T1040 |
| 分辨率 | RGB:1 920×1 080 Depth:512×414 | 1 024×768 |
| 视场角(FOV) | RGB:84.1×53.8 Depth:70×60 | 28×21 |
| 帧率 | 30帧/s | 30帧/s |
选择河北工业大学北辰智能装备研究院5号楼4单元1层车间作为实际场地进行数据采集,其中固定热成像传感器的测温范围为20 ℃~45 ℃,黑热模式。获得的图像序列分别包含RGB图像、深度图像和热图像,数据集部分序列如图 13(a)~图 13(c)所示,图像经处理后得到如图 13(d)所示的人体掩模图像。以一组图像为例,配准后得到如图 14所示的RGB图像、深度图像和热图像,根据热图像处理后得到如图 14(d)所示的人体掩模图像。

|
| 图 13 数据集序列(部分) Fig.13 Part of dataset sequence |

|
| 图 14 图像数据 Fig.14 The image data |
如图 14所示,根据第2节中提出的配准方法,基于RGB图像、热图像分别与深度图像的像素点之间的空间位置关系,找到和深度图像对应的RGB图像像素群和热图像像素群,通过重组像素群得到与深度图像内容一致的全新RGB图像和热图像如图 14(a)、图 14(c)所示。然后基于配准后的热图像,二值化分割获得的人体掩模图像如图 14(d)、图 14(e)所示,其中图 14(e)中红色线框为深度图像14(b)的人体区域轮廓,从图中可以看出掩模图像中人体轮廓与深度图像中人体轮廓吻合较好。进一步地,图 13所示序列中3帧RGB图像、深度图像、热图像及处理的到的人体掩模图像横向对比表明,所提出算法可稳定提取动态场景中动态对象人的人体掩模图像。
将图像送入多传感视觉SLAM系统,对其运行状况进行截图,如图 15(a)所示。作为对比,图 15(b)为将数据集中的RGB图像序列和深度图像序列送入常规的视觉SLAM系统,对其运行状况进行截图所示,经过对比,可以发现动态对象上的特征点明显变少。

|
| 图 15 算法运行截图 Fig.15 Screenshot of algorithm running |
在构建的动态数据集上运行多传感协同算法以及ORB-SLAM2算法,得到的轨迹如图 16所示。从图中可以发现,两种算法形成了差异较大的轨迹:两个算法在运行初期静态环境中地图轨迹基本相同;运行3 s后,由于动态对象的出现,传统算法的定位产生较大干扰,而多传感视觉算法具备一定的抗干扰能力。

|
| 图 16 轨迹对比实验结果 Fig.16 The experiment results of trajectory comparison |
从轨迹波动及整体形状来看,多传感视觉算法的运行轨迹更符合当时采集的路线,且对于动态特征具有抑制作用。多传感视觉算法运行轨迹与ORB-SLAM2算法得到的轨迹之间的差值最大为1.134 m,均方根差为0.560 m,多传感视觉算法的数据集对应的总距离为10.65 m。
多传感视觉算法得到的稠密点云如图 17(a)所示,作为对比,ORB-SLAM2算法得到的稠密点云如图 17(b)所示。从图 17可以看出,多传感视觉算法取得了良好的实验效果,动态对象几乎被剔除干净。

|
| 图 17 稠密3维点云 Fig.17 Dense 3D point clouds |
对多传感视觉算法生成的点云进行滤波处理,如4.2节内容所述,统计滤波参数取k=50,n=1,得到滤波后的效果如图 18(a)所示,对比图 17(a)滤波前图片可以得知,存在的离群异常点被滤除;而后设置体素空间为1.5 cm×1.5 cm×1.5 cm,经过体素滤波后的点云如图 18(b)所示,在剔除冗余数据的情况下,使得点云地图更加精确美观。

|
| 图 18 滤波后的点云数据 Fig.18 Filtered point cloud data |
对多传感视觉算法生成的点云滤波处理后进行格式转换,以1.5 cm为最小分辨率转换生成的OctoMap如图 19所示。

|
| 图 19 八叉树地图 Fig.19 OctoMap |
本文还可以从以下几方面不足进行改进:
1) 使用效果更好的RGB-D相机和热成像传感器。由于设备有限,采用的Kinect V2 RGB-D相机深度图像的质量不高,导致在图像配准时生成的RGB图像和热图像不够精确;热成像传感器视场角过小,间接导致图像配准完成之后图像分辨率仅有160×120。
2) 由于环境中可能存在与人体体温相近且体积较大的特殊物体,这部分物体在环境建模时会被过滤掉。在今后的研究中可以采用深度学习的方法处理热图像,更好地提取人体掩模图像。
5 结论针对传统视觉SLAM在面临室内动态场景时产生的实时性、鲁棒性不足及建模冗余问题,本文从“温度”的角度出发,提出基于热像仪与深度相机相结合的多传感SLAM协同方案。首先,实现深度相机与热成像组成的多传感视觉系统的联合标定与多模态图像配准,然后基于RDH三模图像构建视觉里程计,创建静态地图,最后对该视觉系统应用于SLAM系统,提出多传感视觉SLAM算法。经实验验证,在面临动态场景时,本文所提算法相比于传统视觉SLAM算法能够有效去除动态对象特征点干扰,提升了建图效果。在后续研究工作中,将针对不同动态场景种类、复杂度和稠密度等参数进行研究,探索其对算法的影响。
| [1] |
Durrant-Whyte H, Bailey T. Simultaneous localization and mapping: Part Ⅰ[J]. IEEE Robotics & Automation Magazine, 2006, 13(2): 99-110. |
| [2] |
危双丰, 庞帆, 刘振彬, 等. 基于激光雷达的同时定位与地图构建方法综述[J]. 计算机应用研究, 2020, 37(2): 327-332. Wei S F, Pang F, Liu Z B, et al. Survey of Li DAR-based SLAM algorithm[J]. Application Research of Computers, 2020, 37(2): 327-332. |
| [3] |
权美香, 朴松昊, 李国. 视觉SLAM综述[J]. 智能系统学报, 2016, 11(6): 768-776. Quan M X, Piao S H, Li G. An overview of visual SLAM[J]. CAAI Transactions on Intelligent Systems, 2016, 11(6): 768-776. |
| [4] |
Smith R C, Cheeseman P. On the representation and estimation of spatial uncertainty[J]. The International Journal of Robotics Research, 1986, 5(4): 56-68. DOI:10.1177/027836498600500404 |
| [5] |
Klein G, Murray D. Parallel tracking and mapping for small AR workspaces[C]//6th IEEE & ACM International Symposium on Mixed & Augmented Reality. Piscataway, USA: IEEE, 2007: 225-234.
|
| [6] |
Mur-Artal R, Montiel J M M, Tardos J D. ORB-SLAM: A versatile and accurate monocular SLAM system[J]. IEEE Transactions on Robotics, 2015, 31(5): 1147-1163. DOI:10.1109/TRO.2015.2463671 |
| [7] |
Mur-Artal R, Tardós J D. ORB-SLAM2: An open-source SLAM system for monocular, stereo and RGB-D cameras[J]. IEEE Transactions on Robotics, 2017, 33(5): 1255-1262. DOI:10.1109/TRO.2017.2705103 |
| [8] |
Engel J, Koltun V, Cremers D. Direct sparse odometry[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(3): 611-625. DOI:10.1109/TPAMI.2017.2658577 |
| [9] |
Ai Y, Rui T, Lu M, et al. DDL-SLAM: Arobust RGB-D SLAM in dynamic environments combined with deep learning[J]. IEEE Access, 2020, 8: 162335-162342. DOI:10.1109/ACCESS.2020.2991441 |
| [10] |
Bescos B, FácilJ M, Civera J, et al. DynaSLAM: Tracking, mapping and inpainting in dynamic scenes[J]. IEEE Robotics & Automation Letters, 2018, 3(4): 4076-4083. |
| [11] |
Rünz M, Agapito L. Co-Fusion: Real-time segmentation, tracking and fusion of multiple objects[C]//IEEE International Conference on Robotics and Automation. Piscataway, USA: IEEE, 2017: 4471-4478.
|
| [12] |
Rünz M, Buffier M, Agapito L. MaskFusion: Real-time recognition, tracking and reconstruction of multiple moving objects[C]//IEEE International Symposium on Mixed and Augmented Reality. Piscataway, USA: IEEE, 2018: 10-20.
|
| [13] |
Zhong F, Wang S, Zhang Z, et al. Detect-SLAM: Making object detection and SLAM mutually beneficial[C]//2018 IEEE Winter Conference on Applications of Computer Vision. Piscataway, USA: IEEE, 2018: 1001-1010.
|
| [14] |
Henein M, Zhang J, Mahony R, et al. Dynamic SLAM: The need for speed[C]//2020 IEEE International Conference on Robotics and Automation. Piscataway, USA: IEEE, 2020: 2123-2129.
|
| [15] |
Yu C, Liu Z, Liu X J, et al. DS-SLAM: Asemantic visual SLAM towards dynamic environments[C]//2018 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway, USA: IEEE, 2018: 1168-1174.
|
| [16] |
Scona R, Jaimez M, Petillot Y R, et al. StaticFusion: Background reconstruction for dense RGB-D SLAM in dynamic environments[C]//2018 IEEE International Conference on Robotics and Automation. Piscataway, USA: IEEE, 2018: 3849-3856.
|
| [17] |
Rebecq H, Horstschaefer T, Gallego G, et al. EVO: Ageometric approach to event-based 6-DOF parallel tracking and mapping in real time[J]. IEEE Robotics & Automation Letters, 2017, 2(2): 593-600. |
| [18] |
Strecke M, Stuckler J. EM-fusion: Dynamic object-level SLAM with probabilistic data association[C]//2019 IEEE/CVF International Conference on Computer Vision. Piscataway, USA: IEEE, 2019: 5864-5873.
|
| [19] |
Kim D H, Kim J H. Effective background model-based RGB-D dense visual odometry in a dynamic environment[J]. IEEE Transactions on Robotics, 2016, 32(6): 1565-1573. |
| [20] |
Kim J H, Kim D. Cooperative range-only SLAM based on sum of gaussian filter in dynamic environments[C]//2019 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway, USA: IEEE, 2019: 2139-2144.
|
| [21] |
Zhang T, Zhang H, Nakamura Y, et al. FlowFusion: Dynamic dense RGB-D SLAM based on optical flow[C]//2020 IEEE International Conference on Robotics and Automation. Piscataway, USA: IEEE, 2020: 7322-7328.
|
| [22] |
Palazzolo E, Behley J, Lottes P, et al. Refusion: 3D reconstruction in dynamic environments for RGB-D cameras exploiting residuals[C]//2019 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway, USA: IEEE, 2019: 7855-7862.
|
| [23] |
陈昕, 谢志宏, 宗艳桃. 基于Matlab Camera Calibrator的摄像机标定方法研究[J]. 电脑编程技巧与维护, 2015(16): 81-82, 92. Chen X, Xie Z H, Zong Y T. Camera calibration method based on Matlab camera calibrator[J]. Programming Skills & Maintenance, 2015(16): 81-82, 92. |
| [24] |
Palmero C, Clapés A, Bahnsen C, et al. Multi-modal RGB-depth-thermal human body segmentation[J]. International Journal of Computer Vision, 2016, 118(2): 217-239. |
| [25] |
Rublee E, Rabaud V, Konolige K, et al. ORB: An efficient alternative to SIFT or SURF[C]//IEEE International Conference on Computer Vision. Piscataway, USA: IEEE, 2011: 2564-2571.
|
| [26] |
李鹏飞, 吴海娥, 景军锋, 等. 点云模型的噪声分类去噪算法[J]. 计算机工程与应用, 2016, 52(20): 188-192. Li P F, Wu H E, Jing J F, et al. Noise classification denoising algorithm for point cloud model[J]. Computer Engineering and Applications, 2016, 52(20): 188-192. |
| [27] |
李瑞雪, 邹纪伟. 基于PCL库的点云滤波算法研究[J]. 卫星电视与宽带多媒体, 2020(13): 237-238. Li R X, Zou J W. Point cloud filtering algorithm based on PCL library[J]. Satellite TV & IP Multimedia, 2020(13): 237-238. |
| [28] |
Hornung A, Kai M W, Bennewitz M, et al. OctoMap: An efficient probabilistic 3D mapping framework based on octrees[J]. Autonomous Robots, 2013, 34(3): 189-206. |