



2. 中国科学院沈阳自动化研究所机器人学国家重点实验室, 辽宁 沈阳 110016;
3. 中国科学院机器人与智能制造创新研究院, 辽宁 沈阳 110169;
4. 中国科学院大学, 北京 100049
2. State Key Laboratory of Robotics, Shenyang Institute of Automation, Chinese Academy of Sciences, Shenyang 110016, China;
3. Institutes for Robotics and Intelligent Manufacturing, Chinese Academy of Sciences, Shenyang 110169, China;
4. University of Chinese Academy of Sciences, Beijing 100049, China
0 引言
自主水下机器人(autonomous underwater vehicle,AUV)在军事应用、海洋资源勘探、水文数据采集、水下智能作业等领域都发挥了重要作用,由于单个AUV难以满足日益增长的作业需求,AUV集群编队技术应运而生。
针对大规模资源探测等需求,AUV密集编队的概念被提出[1],随之而来要解决的是密集编队控制中邻近AUV的定位问题。然而由于水下环境的诸多限制,现有大多数陆上应用的视觉定位方法在水下应用具有一定的困难,在无法使用全球定位系统(GPS)定位以及视觉纹理特征有限的情况下,持续检测和跟踪AUV的位置姿态十分具有挑战性[2-4],针对AUV密集编队的应用背景,本文旨在解决水下集群中邻近AUV间的相对位置姿态估计问题。
由于红外光在水下的短距离衰减,RGB-D数据无法获取,本文专注于RGB信息的位姿估计方法。与空气中获取的图像数据不同的是,水下图像受光照强度以及折射率、能见度和周围水质环境的影响存在一定的弱纹理和低质量现象[5]。传统特征提取方法在弱纹理和无纹理环境下的表现很差,基于数据驱动的深度学习方法鲁棒性更好且泛化能力更强。但一些在LINEMOD[6]、Occluded-LINEMOD[7]、YCB-Video[8]等位姿估计基准数据集表现良好的卷积神经网络(convolutional neural networks,CNN)方法需要大量人工标注好的数据,目前没有一种容易适用的方法来收集大量精确的水下位姿数据。
在多机器人编队任务中,早期工作[9]使用基准标记来简化视觉定位任务,但平面标记很容易出现在视野外,而且很难在水下各个角度实现基准标记的检测与识别。采用图像拼接来扩大视野的方法[10]不能解决辅助平面标记增加水下航行阻力以及水下可视距离有限的问题,因此本文专注于对物体自然外观直接建模的位姿估计方法。
经典的6D位姿估计方法是从RGB图片中提取局部特征与目标3D模型匹配,建立对应关系基于Perspective-n-Point(PnP)[11]算法获取6D位姿,提取目标局部特征一般有传统方法和基于CNN的方法。此外,也有一些基于CNN的方法不预测关键点投影,直接回归6D位姿。本文专注关键点法,以下从传统方法和基于CNN的方法两个方面简要总结相关工作。
1) 传统方法
对于纹理丰富的物体,传统方法可以检测到物体的局部特征作为关键点,并且在遮挡和杂乱场景仍具有良好鲁棒性[6, 12-13],但是这些方法在弱纹理和低质量图像的情况下表现很差。与稀疏关键点预测相比,密集关键点预测意味着每个像素或图像块(patch)都会对位姿进行预测,然后通过投票得到最终结果[14]。一些方法采用随机森林算法预测物体3D坐标对应的像素,并利用几何约束生成2D-3D对应关系估计对象的位姿[15-16]。虽然密集关键点预测的精度高于稀疏关键点预测,但相应代价是运行速度非常慢。
2) 基于CNN的方法
为解决传统方法中基于关键点的目标姿态估计方法的不足,许多研究人员利用CNN作为关键点检测器,对RGB图像中目标的关键点进行检测。
PVNet[17]采用投票的方法密集预测关键点,虽然预测精度很好,但速度不够快。BB8[18]是一个多阶段方法,先对图像进行粗分割,然后在分割对象中检测关键点,该方法无法达到实时性要求。DPOD[19]估计输入图像和可用3D模型之间的密集对应关系,基于随机采样一致性(random sample consensus,RANSAC)的PnP算法求解初始位姿,并对初始位姿估计结果进行后处理优化,类似研究后处理优化的工作还有CullNet[20]和DeepIM[21]。基于CNN的关键点法中YOLO-6D[22]是无后处理的单阶段位姿估计方法,该方法的优点是速度快且不需要物体的三维模型,但它存在YOLO-V2[23]本身的缺点,在检测小物体和被遮挡物体时精度会降低。最近的工作MFPN-6D[24]通过增加垂直方向的残差结构改进了BiFPN[25]特征金字塔,结合CSPNet[26]预测关键点投影。DFPN-6D[27]也是一个类似的工作,它增加垂直方向的残差结构同时采用密集连接的方式改进了BiFPN特征金字塔,同样结合CSPNet预测关键点投影。
本文专注探索Mini水下机器人(图 1)在编队任务中(图 2)的定位,通过Unity3D使用虚拟相机对AUV的计算机辅助设计(CAD)模型进行投影获得已知姿态的渲染图像,通过循环生成对抗网络[28](cycle generative adversarial network,Cycle GAN)将各种不同距离姿态的渲染图像转换为类似真实水下图片,作为位姿估计网络的训练数据。所提出的位姿估计网络在Darknet-53[29]的基础上进行修改,分为目标检测、位姿回归和位姿优化三个部分。位姿估计网络通过关键点的局部投影预测和置信度的筛选,为每个3D关键点选择最可靠的2D关键点候选,产生2D-3D点对,基于RANSAC的PnP算法获得稳健的6D姿态估计。

|
| 图 1 探索Mini水下机器人 Fig.1 Explorer-Mini autonomous underwater vehicle |

|
| 图 2 探索Mini编队任务 Fig.2 Explorer-Mini vehicles for formation missions |
本文的主要创新点和贡献如下:
1) 论证了非配对图像转换可以有效消除仿真图像与真实水下图像之间的差距,解决了水下真实位姿难以获取的问题。
2) 基于Darknet-53提出了专注局部区域的6D位姿估计网络,并在水下合成位姿数据集上进行了指标评估,论证了所提出算法的有效性。
1 水下机器人视觉定位方法 1.1 视觉定位方法整体框架图 3展示了水下机器人视觉定位方法的整体设计,首先基于AUV的CAD模型通过Unity3D仿真环境搭建虚拟场景,由虚拟相机拍摄CAD模型得到AUV模型的RGB图片数据以及每张图片对应的位姿数据。通过Cycle GAN算法完成非配对图像转换工作,将真实采集的水下图片与仿真获取的渲染图片的特征空间进行对齐,结合仿真中的已知位姿,得到了已知位姿的近似真实水下场景的合成图片,如图 3(a)。以合成数据作为输入,专注于包含目标的局部区域预测,预测已知尺寸CAD模型的8个角点的2D投影。Darknet-53输出的特征图分别用于目标检测和位姿回归,通过2D检测框区域来筛选关键点投影坐标,选取最佳候选投影点,结合已知8个角点的3D坐标构成3D-2D点对,基于RANSAC的PnP算法求解出AUV间的相对位姿,如图 3(b)所示。

|
| 图 3 方法框架 Fig.3 Framework of approach |
本文基于探索Mini的CAD模型和Unity3D构建了一个虚拟的水下场景仿真环境,主要实现了虚拟环境下的仿真数据捕获,数据包括随机位置和姿态的RGB图片以及与图片相对应的8个角点的像素投影坐标。
依据探索Mini的CAD模型的物理尺寸(图 4),渲染了一个3D的包围框(图 5),以模型的几何中心为世界坐标系原点,其8个角点的世界坐标已知。本文使用分辨率为1 440×1 080且视角为60°的虚拟相机(主相机),在Unity3D中添加了实际的水池背景,对不同位置、姿态的CAD模型模拟拍摄,通过编写C#语言脚本实现了场景下的截屏、自动数据捕获以及手动数据捕获等功能,虚拟场景与UI界面如图 5所示。

|
| 图 4 探索Mini水下机器人的CAD模型 Fig.4 CAD model of Explorer-Mini vehicle |

|
| 图 5 虚拟场景与UI界面设计 Fig.5 Design of virtual scene and UI interface |
在自动数据捕获中,以附加包围框的AUV为一个整体(目标对象),其位置为世界坐标系的原点。为保证主相机拍摄有效,相机必须在目标对象后方。目标对象的位置坐标为世界坐标(x, y, 0),主相机的位置坐标为世界坐标(0, 0, d),其中d < 0,表示摄像机在目标对象后方,|d|表示摄像机与目标对象在z轴上的距离。为保证目标对象在主相机视野内,对目标对象位置坐标的x以及y值进行约束,视角60°时的x, y约束范围为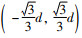
图像到图像的转换(image-to-image translation)是一类图像问题,其目标是通过成对图像训练来学习输入图像和输出图像之间的映射关系。但成对图像在许多任务中是不可用的,例如在本文的应用场景中,不存在仿真图像与真实水下图像的位姿保持一致的成对图像。
Cycle GAN[28]算法是一种基于非配对图像转换(unpaired image translation)的无监督学习方法,可以通过非配对图像完成域到域的风格迁移。本文应用该算法解决非配对图像之间图像到图像的转换工作,修补渲染图片与真实水下图片像素与像素之间的差距,输出与真实域相似的合成域图片数据,实现仿真环境到真实水下场景的风格迁移。
该方法通过双向对抗训练来学习渲染图像数据(A域)与真实水下图像数据(B域)之间的映射关系。网络由一组完全对称的生成器和判别器组成,记为{GAB、DB}和{GBA、DA},A域到B域的网络单向结构如图 6所示,反之亦然。

|
| 图 6 Cycle GAN单向结构 Fig.6 The single structure of Cycle GAN |
假设a~pdata(A),b~pdata(B)代表A,B两个域中的数据服从的概率分布,A域到B域的单向对抗损失函数为
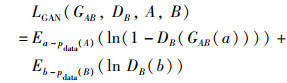
|
(1) |
其中,GAB会生成类似于B域中的样本GAB(a),DB用来区分GAB(a)和B域真实样本。同理,B域到A域的单向对抗损失函数为
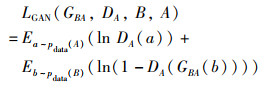
|
(2) |
在传统单向GAN网络损失的基础上,增加循环一致性损失,作为A域到B域的转换约束。生成器GAB生成的假样本作为输入通过GBA得到重建的A域图片,即a≈GBA(GAB(a)),B域到A域同理,总体循环一致性损失为
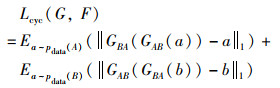
|
(3) |
综上所述,Cycle GAN总损失为
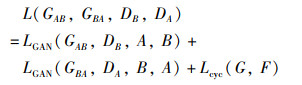
|
(4) |
采用渲染图片作为A域样本,通过分辨率1 440×1 080视角100°的工业相机实际采集了8 507帧真实水池图片,作为B域样本,使用Resblock9[30]作为生成器网络,PatchGAN[31]作为判别器网络,对抗训练过程如图 8(a)、图 8(b)所示。

|
| 图 8 Cycle GAN训练和测试过程 Fig.8 Training and testing process of Cycle GAN |
经过大量实验,基于Unity3D的渲染图片生成了与真实水下图片近似的合成图片,合成数据生成过程如图 8(c)、图 8(d)所示。生成的合成图片结合Unity3D中的已知位姿,最终得到了合成水下位姿数据,用于6D位姿估计网络的训练。
1.4 6D位姿估计6D位姿估计网络在Darknet-53[29]的基础上进行修改,包括Darknet-53编码器、目标检测解码器、位姿回归解码器以及局部区域的位姿优化。
Darknet-53预测3种大小的空间分辨率,通过上采样在多个空间分辨率中进行预测有助于在网络前期使用细粒度特征获得多尺度语义信息。两个解码器输出空间分辨率为S×S,维度分别为Ddet和Dreg的3D张量。
1) 目标检测解码器:回归2D检测框,通过上采样多尺度特征与最后一层深度特征连接得到维度Ddet=C+5,如图 7(a)所示。其中,C表示物体类别个数,{p1, …, pc}表示每个类别的概率,c表示检测框置信度,{(xmin,ymin),(xmax,ymax)}表示检测框左上角和右下角坐标。

|
| 图 7 解码器输出 Fig.7 Output of the decoder |
2) 位姿回归解码器:其结构与目标检测类似,但由于回归的是3D模型8个角点的2D投影,其维度为Dreg=C+3×8,如图 7(b)所示。其中,C表示物体类别个数,{p1, …, pc}表示每个类别的概率,{xi, yi, ci}表示第i个角点的2维投影坐标和置信度。
对于局部区域的位姿优化,本文采用目标检测框区域筛选全局投影点的方法,对全局预测投影点进行筛选,获得最佳候选投影点。
以下分别介绍目标检测、位姿回归和位姿优化三个方面,包括损失函数设计和最佳候选投影点选取方法以及一些超参数设定。
1.4.1 目标检测目标检测通过划分网格预测2维检测框,网格左上角相对图像左上角坐标偏移量为(cx, cy),网络预测4个坐标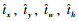
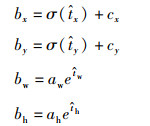
|
(5) |
σ为Sigmoid函数。通过式(5)可由检测框真值参数计算得到对应的t*,与预测值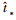
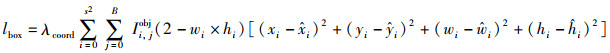
|
(6) |
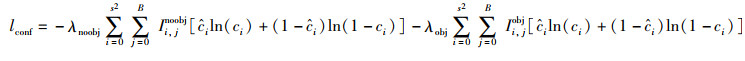
|
(7) |
置信度损失分别计算有物体的网格和无物体的网格,如式(7)。类别概率通过独立的logistic回归获得,使用二值交叉熵计算损失,如式(8):
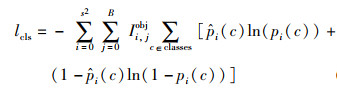
|
(8) |
以上式(6)~式(8)中,*i为真值,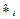
综上,目标检测总损失Ldet是坐标损失、置信度损失、类别概率损失之和,如式(9)。
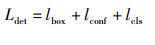
|
(9) |
位姿回归中主要设计了专注局部区域的损失函数,本文选择Unity3D中渲染的包围框的8个角点作为关键点,网络得到一个S×S×Dreg的3D张量,预测8个关键点投影坐标(x, y)、置信度c以及物体类别C,即Dreg=3×8+C。
网络不直接预测2D投影坐标,而是预测每一个关键点相对网格的位置偏移量。每一个网格左上角相对于图片左上角的位置为k,对于第i个关键点,网络预测相对于网格左上角的偏移量为fi(k),因此,图片中的关键点投影实际位置为k+fi(k),关键点投影位置的真值为gi,预测值与真值的差值为
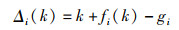
|
(10) |
则总投影位置坐标损失为
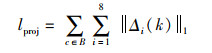
|
(11) |
其中,B表示在目标检测框内的网格,||·||1表示L1-norm损失函数。式(11)表示只计算目标检测框内的网格单元的投影损失,实现专注真正属于该目标的图像区域。
网络通过Sigmoid函数归一化了输出的预测置信度值,为vi(c)。由式(10)可知预测投影点与真值之间的距离为||Δi(k)||2,定义置信度函数为||Δi(k)||2的指数函数,则置信度损失计算如下:
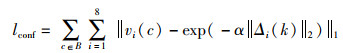
|
(12) |
其中,||·||2表示L2-norm损失函数或欧氏距离,α为指数函数的锐度,设为1。位姿回归的损失函数如式(13)所示,其中λ*为权重系数。
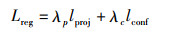
|
(13) |
为了平衡数值的稳定性,将λp设为1,对于不包含物体的网格,将λc设置为0.1,对于包含物体的网格,将λc设置为5。
综上,所提出的6D位姿估计网络总损失为
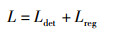
|
(14) |
位姿优化是网络推理时以检测框区域为局部区域,对网络预测的初始位姿回归结果,进行局部区域的关键点筛选,得到一组候选关键点,在候选关键点中通过基于RANSAC的PnP计算得到最终位姿,推理时的位姿优化流程图如图 9所示。

|
| 图 9 推理时的位姿优化流程框图 Fig.9 Flowchart of pose refinement during inference |
1) 网络初始预测结果
参照1.4节图 7所述,网络输出的初始预测结果分为目标检测和位姿回归,3张特征图有13×13+26×26+52×52个网格,每个网格均预测一个2D检测框和一个3D检测框(8个关键角点投影)。因此,初始目标检测结果即13×13+26×26+52×52×(C+5),初始位姿结果即13×13+26×26+52×52×(C+8×(x+y+c))。
2) 非极大值抑制获得目标检测框
首先处理目标检测获得包含目标的边界框,每个网格预测了目标检测框的位置坐标偏移量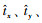
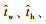
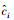
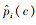
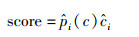
|
(15) |
使用非极大值抑制(non-max suppression)设定score阈值为0.25及IOU(intersection over union)阈值为0.35,获得了最优检测框。
3) 局部区域筛选全局投影点
由2)可得唯一的边界框,边界框区域内的值设为1,区域外的值为0,得到边界框的掩码mask。每个网络预测了8个关键点投影偏移量及置信度Δxi、Δyi、ci及类别概率。针对类别概率,在模型中虽然定义了类别概率,但在实际推理时未使用类别概率来做优化,且由于本文只有一类水下机器人,位姿回归的类别概率暂未使用到。
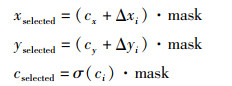
|
(16) |
如式(16)可得到局部投影点,其中,cx和cy为网格左上角相对图像左上角坐标偏移量,σ为sigmoid函数。
针对局部投影点,本文进行了像素距离和置信度的阈值筛选,得到最终过滤后的投影点,最后根据经验选取12个置信度最高的作为最佳候选投影点,用于RANSAC迭代。
图 10展示了推理过程中最佳候选投影点的选取方法。网络输出3张特征图直接预测(13×13+26×26+52×52)×8个点,如图 10(a)所示。同时获得目标检测框的掩码,如图 10(b)所示。网格预测的全局投影点通过掩码和像素距离阈值进行筛选,像素距离阈值为图片宽度的0.3倍,预测置信度小于0.5的关键点也被去除掉,如图 10(c)所示。为平衡计算量与准确度,根据经验使用了12个置信度最高的点作为最佳候选投影点,如图 10(d)所示。最后,采用12×8=96个2D-3D点对,基于RANSAC的PnP算法获得6D位姿估计结果(可视化结果见图 3(b)中)。

|
| 图 10 位姿优化可视化结果 Fig.10 Visualization results of pose refinement |
渲染数据集包含了由Unity3D渲染的CAD模型并覆盖了真实水池背景的图片。在主相机与目标对象的空间距离为1.5 m~6 m范围内拍摄了随机姿态的49 546张图片,其中有14 738张图片的姿态有角度限制,在XYZ轴上的旋转角范围分别为(270°,360°)、(240°,260°)、(0°,90°),具体参考1.2节。
合成数据集包含了基于Cycle GAN的非配对图像转换获得的类似真实水池图片,具体参考1.3节。其中,真值标签来自于Unity3D仿真环境,包括2D检测框{(xmin, ymin), (xmax, ymax)}以及9个参考点的投影坐标{(x1, y1), (x1, y2),…,(x8,y8),(xc,xc)}(8个角点和1个中心点)。为避免人工标注2D检测框,取投影点的极值作为2D检测框的标签,如式(17)所示。
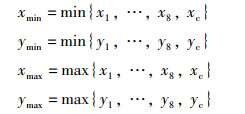
|
(17) |
室内水池数据集包括一些真实水下场景的图片和视频。通过AUV的板载相机拍摄图片和视频,如图 12中所示,真实水下场景1通过加负重让AUV下沉的方式采集,真实水下场景2在推进器有动力的情况下采集。
2.2 评价指标为验证网络的推理能力,本文从误差以及准确率两个方面来进行指标评价。
对于误差,本文计算了平均平移误差(mean translation error)、平均方向误差(mean orientation error)以及具体的俯仰(Pitch)、偏航(Yaw)、滚转(Roll)角度误差。(R,t)和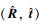
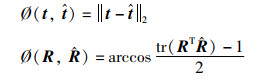
|
(18) |
其中,平移误差表示平移向量的真值与预测值之间的欧氏距离,方向误差计算中,tr(RT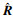
对于准确率,本文使用了标准指标:2D重投影误差和ADD指标[8, 22, 32-33]。结合相机内参,通过(R,t)和
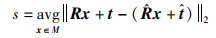
|
(19) |
对于合成数据的生成,采用仿真图片作为A域样本,其中包括AUV不全在画面内的情况,采用真实水下图片作为B域样本。由于AUV使用的广角相机在近距离下有较大的畸变,尝试标定去畸变以后进行Cycle GAN的训练,同时尝试过A域和B域的样本数据保持基本一致的情况,然而这两种情况的生成效果并不理想。最终,发现A域使用4 836个样本,B域使用8 507个样本,仿真样本与真实样本接近1∶ 2的比例,训练3个epoch的效果较好,可以生成完全对应的合成图片。
2.3.2 位姿估计网络实验发现对于图片中AUV不全在画面内的合成数据,其角点投影点坐标存在超过1 440、1 080和小于0的情况,负值限制为0以后,投影点产生偏移导致标签不准确。为了保证网络正确学习数据,对所有的49 546个合成数据做了过滤,保留了30 899张和2 240张AUV完整在画面内的图片,分别作为训练数据和验证/测试数据。
本文使用位姿估计网络训练了148个epoch,前3个epoch进行warm up处理,学习率从0增加到1×10-4,引入动量随机梯度下降(stochastic gradient descent,SGD)优化器且momentum参数为0.9,采用分段常数学习率衰减策略,在第20、60、100个epoch分别衰减到3×10-5、1×10-5、3×10-6,此后一直保持3×10-6。训练过程中的batch size为16,采用包括随机改变色调、饱和度、曝光以及图片随机缩放的数据增强方法来防止过拟合,训练过程中使用2 240张图片进行验证损失计算,衡量训练权重的泛化效果。
2.4 实验结果与分析 2.4.1 渲染与合成对比为了验证合成是否有效,采用相同的超参数设定,基于渲染数据集(30 899张)和合成数据集(30 899张)分别实验。计算它在由合成图像组成的验证集上的损失(图 11),横轴是迭代轮数,纵轴是平均损失,参考1.4.2节。随着迭代的进行,损失甚至出现不收敛的情况(图 11(a)),说明它在合成数据集上的泛化效果很差。而基于合成数据集进行训练,损失正常收敛(图 11(b)),这说明渲染图像与合成图像也是有一定差距的。

|
| 图 11 同一验证集上的损失对比 Fig.11 Comparison of losses on the same validation set |
同时使用两个训练权重分别在真实水下图像上定性测试,可以发现由渲染图像训练的网络出现很多基于RANSAC的PnP不收敛的情况和错误预测的情况,而由合成数据训练的网络与相对表现要好很多。
实验证明,基于渲染数据集进行训练,尽管网络在仅由渲染图像组成的验证集上表现良好,但无法泛化到合成图片,更无法泛化到真实水下场景下的图片。
由此可知渲染图像与合成图像、真实图像之间的纹理差距较大,仅使用渲染图像训练,网络在真实水下场景上的泛化效果非常差,也在一定程度上论证了非配对图像转换工作能有效消除渲染图像与真实图像之间的差距。
图 12(a)展示了一些合成数据的检测结果,图 12(b)、图 12(c)展示了一些室内水池数据的检测结果,其中绿色框表示预测的2D检测框,红色的3D检测框表示预测位姿。此外,水池图片只用于定性评估所提出的方法。

|
| 图 12 不同数据集上的检测结果 Fig.12 Detection results on different datasets |
本文在2 240个合成数据上对所提出的方法进行了指标评估,分别对比了位姿优化时所有网格初始位姿预测投影点(全局)以及局部区域筛选的投影点(区域)两种方法的评估结果,位姿优化具体参考1.4.3节。
本文将8个参考点的2D投影误差之和超过100像素、距离误差超过10 m、角度误差超过20°的预测认为是错误的检测,其中全局投影点方法和区域投影点方法分别共有102张和97张图片符合错误预测的情况。在2 138个和2 143个正确预测的情况中,分别计算了两种方法的4个指标(表 1),以及具体的滚转角、俯仰角、偏航角误差(表 2)。表 1、表 2中,↓表示该项值越小越好,↑表示该项值越大越好,加黑表示该项更优。
| 投影方法 | 平均平移误差/m↓ | 平均方向误差/(°)↓ | REP-10px准确率/%↑ | ADD-0.1d准确率/%↑ |
| 全局 | 0.13 | 4.81 | 81.88 | 73.13 |
| 区域 | 0.12 | 4.72 | 82.23 | 73.88 |
| 单位: (°) | |||||||||||||||||||||||||||||
| 投影方法 | 平均滚转角误差↓ | 平均偏航角误差↓ | 平均俯仰角误差↓ | ||||||||||||||||||||||||||
| 全局 | 7.28 | 5.45 | 2.71 | ||||||||||||||||||||||||||
| 区域 | 7.37 | 5.02 | 2.61 | ||||||||||||||||||||||||||
结果证明,所提出的专注于区域投影点的位姿优化是有效的,平均平移误差、平均方向误差以及两个标准指标均有提升,但是对于具体的旋转角误差,区域投影点方法的平均偏航角和平均俯仰角误差更小,平均滚转角误差则是全局投影点方法更小。
图 13分别展示了全局投影点方法(图 13(a))和区域投影点方法(图 13(b))在2 240个合成数据上平移及方向误差相对相机距离的统计情况。其中,横坐标中的相对相机距离的区间范围是左闭右开的区间,绿色上三角表示平均值。相对距离小于1.5 m的图片仅有一张,中位数、平均值以及最大值最小值都重合。

|
| 图 13 箱型图:相对相机距离的平移及方向误差统计 Fig.13 Boxplot: Statistics of translation and orientation errors relative to camera distance |
从统计情况来看,平移误差随AUV间相对距离的增大而增大,超过4.5 m以后误差比较明显的上升。而对于方向误差,在AUV间相对距离较大或较小时,都具有更高的方向误差。在1 m到6 m的距离范围内,对于全局投影点方法,最大的平移误差为3.17 m,最大的方向误差为19.74°,而对于区域投影点方法,最大平移误差为2.29 m,最大方向误差为19.96°。实验证明,区域投影点方法降低了最大平移误差,可以更有效地估计AUV间相对6D位姿。
2.4.3 本文方法与YOLO-6D对比为验证所提出方法的性能,本文与LINEMOD基准数据集上表现良好的YOLO-6D[22]算法进行了对比,采用2 021个合成数据同样训练148个epoch,并使用2 240张进行测试,对比结果见表 3,其中FPS基于RTX2080显卡测试。
实验结果表明,所提出的方法与YOLO-6D相比较,具有更高的准确率和更小的预测误差,但运行速度较慢一些。另外,在REP-10px指标相差2.45% 的情况下,两者的平均平移误差和平均方向误差相差一倍,这说明YOLO-6D预测结果有不稳定的异常值,经计算,YOLO-6D的平移误差标准差和方向误差标准差分别为2.49和49.10,而本文方法的平移误差标准差和方向误差标准差分别为1.32和22.26,由此说明本文方法相较YOLO-6D可以进行更准确和更稳定的位姿估计,但相应的代价是运行速度更慢一些。
相较YOLO-6D,提升的性能主要来自于两个因素:1) 使用了更好的检测网络;2) 在回归损失函数中引入的局部区域关键点损失计算(参考1.4.2节位姿回归损失函数)以及推理时采用局部区域位姿优化(参考1.4.3节局部区域位姿优化)。YOLO-6D使用最高置信度的关键点,而本文采用局部区域的关键点采样并基于RANSAC的PnP选择更合适的关键点,但RANSAC迭代会消耗更多的时间,导致运行速度下降。
2.4.4 合成数据泛化性能分析至于合成数据训练的网络在真实水下场景的泛化情况,本文在水池数据集上进行了定性评估。图 12(b)是1 440×1 080分辨率、视角100°的相机拍摄(场景1),图 12(c)是1 920×1 080分辨率、视角90°的相机拍摄(场景2)。由于非配对图像转换时采用的目标域是场景1,因此合成图片与场景1更相似,网络在场景1下的泛化性能也更好。
在两种真实场景下均有各种失败的检测案例,在距离超过6 m的情况或者基于Darknet-53的目标检测无法识别的情况,位姿预测可能错误。在渲染距离范围内位姿预测不准确的一部分原因可能是,真实场景下采集的图片位置角度相对固定,合成数据中某些位置角度的数据可能有缺失。此外,非配对图像转换也具有很重要的影响,生成具有不同背景纹理、亮度、相似度更高的合成图像可以更好地减少过拟合和提高泛化性能,适应更多的场景。
3 结论针对水下集群中邻近AUV的视觉定位问题,这项工作在没有AUV相对位姿真值的情况下,基于合成数据实现了AUV相对6D位姿的预测,解决了水下场景难以获取大量精确位姿的问题。
实验证明,基于合成图片训练的网络可以更好的泛化到真实水下场景,所提出的基于局部区域的位姿估计方法可以进行更稳定的6D位姿估计,所提出的基于合成数据的方法为水下场景的视觉定位问题提供了一种新思路。
| [1] |
杨翊, 周星群, 胡志强, 等. 基于视觉定位的水下机器人无通信高精度编队技术研究[J]. 数字海洋与水下攻防, 2022, 5(1): 50-58. YANG Y, ZHOU X Q, HU Z Q, et al. Research on high-precision unmanned underwater vehicles team formation without communication based on visual positioning technology[J]. Digital Ocean and Underwater Warfare, 2022, 5(1): 50-58. |
| [2] |
WU Y, TA X, XIAO R, et al. Survey of underwater robot positioning navigation[J/OL]. Applied Ocean Research, 2019[2021-03-16]. http://www.sciencedirect.com/science/article/abs/pii/s014118718305546. DOI: 10.1016/j.apor.2019.06.002.
|
| [3] |
GONZÁLEZ-GARCÍA J, GÓMEZ-ESPINOSA A, CUAN-URQUIZO E, et al. Autonomous underwater vehicles: Localization, navigation, and communication for collaborative missions[J/OL]. Applied Sciences, 2020[2021-07-04]. http://www.innovation4.cn/library/r56182. DOI: 10.3390/app10041256.
|
| [4] |
WATSON S, DUECKER D A, GROVES K. Localisation of unmanned underwater vehicles (UUVs) in complex and confined environments: A review[J/OL]. Sensors, 2020[2022-01-02]. https://www.mdpi.com/1424-8220/20/21/6203. DOI: 10.3390/s20216203.
|
| [5] |
王丹, 张子玉, 赵金宝, 等. 基于场景深度估计的自然光照水下图像增强方法[J]. 机器人, 2021, 43(3): 364-372. WANG D, ZHANG Z Y, ZHAO J B, et al. An enhancement method for undwerwater images under natural illumination based on scene depth estimation[J]. Robotics, 2021, 43(3): 364-372. |
| [6] |
HINTERSTOISSER S, LEPETIT V, ILIC S, et al. Model based training, detection and pose estimation of texture-less 3D objects in heavily cluttered scenes[C]//Asian Conference on Computer Vision. Berlin, Germnay: Springer: 548-562.
|
| [7] |
KRULL A, BRACHMANN E, MICHEL F, et al. Learning analysis-by-synthesis for 6D pose estimation in RGB-D images[C]//IEEE International Conference on Computer Vision. Piscataway, USA: IEEE, 2015: 954-962.
|
| [8] |
XIANG Y, SCHMIDT T, NARAYANAN V, et al. PoseCNN: A convolutional neural network for 6D object pose estimation in cluttered scenes[EB/OL]. (2018-05-26)[2021-02-21]. https://arxiv.org/abs/1711.00199.
|
| [9] |
SCHNEIDERMAN H, NASHMAN M, WAVERING A J, et al. Vision-based robotic convoy driving[J]. Machine Vision and Applications, 1995, 8(6): 359-364. DOI:10.1007/BF01213497 |
| [10] |
王然. 基于领航—跟随模型的水下机器人编队研究[D]. 哈尔滨: 哈尔滨工业大学, 2020. WANG R. Research on formation of underwater robot based on leader-follower model[D]. Harbin: Harbin Institute of Technology, 2020. |
| [11] |
LEPETIT V, MORENO-NOGUER F, FUA P. EPnP: An accurate o(n) solution to the PnP problem[J]. International Journal of Computer Vision, 2009, 81(2): 155-166. DOI:10.1007/s11263-008-0152-6 |
| [12] |
ZHANG H, CAO Q. Detect in RGB, optimize in edge: Accurate 6D pose estimation for texture-less industrial parts[C]//International Conference on Robotics and Automation. Piscataway, USA: IEEE, 2019: 3486-3492.
|
| [13] |
KEHL W, MILLETARI F, TOMBARI F, et al. Deep learning of local RGB-D patches for 3D object detection and 6D pose estimation[C]//European Conference on Computer Vision. Berlin, Germany: Springer, 2016: 205-220.
|
| [14] |
HU Y, HUGONOT J, FUA P, et al. Segmentation-driven 6D object pose estimation[C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, USA: IEEE, 2019: 3385-3394.
|
| [15] |
MUÑOZ E, KONISHI Y, BELTRAN C, et al. Fast 6D pose from a single RGB image using Cascaded Forests Templates[C]//2016 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway, USA: IEEE, 2016: 4062-4069.
|
| [16] |
TEJANI A, KOUSKOURIDAS R, DOUMANOGLOU A, et al. Latent-class hough forests for 6 DoF object pose estimation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 40(1): 119-132. |
| [17] |
PENG S, LIU Y, HUANG Q, et al. PVNet: Pixel-wise voting network for 6DoF pose estimation[C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, USA: IEEE, 2019: 4561-4570.
|
| [18] |
RAD M, LEPETIT V. BB8: A scalable, accurate, robust to partial occlusion method for predicting the 3D poses of challenging objects without using depth[C]//IEEE International Conference on Computer Vision. Piscataway, USA: IEEE, 2017: 3828-3836.
|
| [19] |
ZAKHAROV S, SHUGUROV I, ILIC S. DPOD: 6D pose object detector and refiner[C]//IEEE/CVF International Conference on Computer Vision. Piscataway, USA: IEEE, 2019: 1941-1950.
|
| [20] |
GUPTA K, PETERSSON L, HARTLEY R. CullNet: Calibrated and pose aware confidence scores for object pose estimation[C]//IEEE/CVF International Conference on Computer Vision Workshops. Piscataway, USA: IEEE, 2019: 2758-2766.
|
| [21] |
LI Y, WANG G, JI X, et al. DeepIM: Deep iterative matching for 6D pose estimation[C]//European Conference on Computer Vision Berlin, Germany: Springer, 2018: 683-698.
|
| [22] |
TEKIN B, SINHA S N, FUA P. Real-time seamless single shot 6D object pose prediction[C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, USA: 2018: 292-301.
|
| [23] |
REDMON J, FARHADI A. YOLO9000: Better, faster, stronger[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, USA: IEEE, 2017: 7263-7271.
|
| [24] |
LIU P, ZHANG Q, ZHANG J, et al. MFPN-6D: Real-time one-stage pose estimation of objects on RGB images[C]//2021 IEEE International Conference on Robotics and Automation. Piscataway, USA: IEEE: 2021: 12939-12945.
|
| [25] |
TAN M, PANG R, LE Q V. Efficientdet: Scalable and efficient object detection[C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, USA: IEEE, 2020: 10781-10790.
|
| [26] |
WANG C Y, LIAO H Y M, WU Y H, et al. CSPNet: A new backbone that can enhance learning capability of CNN[C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway, USA: IEEE, 2020: 390-391.
|
| [27] |
CHENG J, LIU P, ZHANG Q, et al. Real-time and efficient 6-D pose estimation from a single RGB image[J]. IEEE Transactions on Instrumentation and Measurement, 2021, 70(1): 1-14. |
| [28] |
ZHU J Y, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]//IEEE International Conference on Computer Vision. Piscataway, USA: IEEE, 2017: 2223-2232.
|
| [29] |
REDMON J, FARHADI A. YOLOv3: An incremental improvement[EB/OL]. (2018-04-08)[2021-05-23]. https://arxiv.org/abs/1804.02767.
|
| [30] |
HOHNSON J, ALAHI A, LI F F. Perceptual losses for real-time style transfer and super-resolution[C]//European Conference on Computer Vision. Berlin, Germany: Springer: 2016: 694-711.
|
| [31] |
ISOLA P, ZHU J Y, ZHOU T, et al. Image-to-image translation with conditional adversarial networks[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, USA: IEEE, 2017: 1125-1134.
|
| [32] |
BRACHMANN E, MICHEL F, KRULL A, et al. Uncertainty-driven 6D pose estimation of objects and scenes from a single RGB image[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, USA: IEEE, 2016: 3364-3372.
|
| [33] |
KEHL W, MANHARDT F, TOMBARI F, et al. SSD-6D: Making RGB-based 3D detection and 6D pose estimation great again[C]//IEEE International Conference on Computer Vision. Piscataway, USA: IEEE, 2017: 1521-1529.
|