



2. 国网阜新供电公司变电检修工区, 辽宁 阜新 123000;
3. 开滦集团有限责任公司, 河北 唐山 063018
2. Substation Maintenance Work Area, State Grid Fuxin Power Supply Company, Fuxin 123000, China;
3. Kailuan Group Co, Ltd., Tangshan 063018, China
0 引言
电力变压器在电力系统中处于核心枢纽地位,担负着电压转换、电能分配等重要功能,其出现故障会给人们的生命安全和供电网络带来巨大危害[1-2]。当变压器发生故障时,常采用油中溶解气体法(dissolved gas analysis,DGA),根据各种特征气体浓度的变化,对变压器故障进行诊断辨识[3]。
近年来,支持向量机(support vector machine,SVM)、多层前馈式(back propagation,BP)神经网络、模糊理论和极限学习机(extreme learning machine,ELM)等成为变压器故障检测的主流方法。文[4]针对ISSA-SVM(improved salp swarm algorithm- support vector machine)模型对变压器故障进行分析,引入信赖机制和突变,提高全局搜索能力和模型精度。文[5]提出残差BP神经网络,通过堆叠残差网络模块,提升模型精度。文[6]运用模糊聚类算法,构造故障测度隶属函数,解决了编码缺失和分类模糊问题。文[7]通过快速非支配排序遗传算法(NSGA2)优化正则化极限学习机,提高了变压器故障诊断模型的稳定性。虽然以上故障诊断模型在变压器故障诊断领域中取得了一定的研究成果,但是模型易受随机参数影响,故障诊断精度有限,容易误判故障类型,引发电力事故。
此外,变压器故障数据质量也直接影响故障辨识的精度。实际收集的变压器故障样本数据具有小样本特性,导致故障辨识精度低。在数据处理方法中,采用过采样、欠采样和混合采样等方式,削弱数据分布不均衡带来的影响;在分类算法改进上,引入代价敏感学习等。文[8]采用合成少数类过采样技术增加样本数据,增多训练集中的重复样本,导致模型过拟合。文[9]采用K近邻欠采样,削减多数类数据,使数据均衡化,但丢失大量数据特征,不适用于数据量不足的变压器故障诊断。文[10]采用混合采样对故障数据处理,扩充故障样本数量,减少不同类别的样本重叠,提高诊断精度。文[11]引入代价敏感学习到AdaBoost模型中,有效提升分类器处理不平衡数据的性能,但方法具有一定局限性。
鉴于此,提出基于ADASYN的IWOA-KELM变压器故障诊断模型。首先,利用ADASYN算法平衡训练集样本;然后,组合优化策略对鲸鱼算法改进。利用非线性收敛因子达到算法全局搜索能力和局部勘探能力的最佳平衡,自适应学习因子确保算法收敛性和多项式变异防止种群过度同化。利用IWOA对KELM模型的相关超参数进行寻优,构建IWOA-KELM故障诊断模型;最后,以实际变压器油色谱数据为故障特征信息,分别利用变压器故障原始训练集和平衡后训练集建立IWOA-KELM故障诊断模型,并与粒子群算法核极限学习机模型(PSO-KELM)、鲸鱼算法核极限学习机模型(WOA-KELM)、灰狼算法优化核极限学习机模型(GWO-KELM)等模型进行对比分析,验证本文所提方法的有效性。
1 ADASYN数据平衡化算法通常,电力变压器故障样本数量远小于正常样本数量,且各类型变压器故障数量分布不均衡,如高能放电和局部放电故障数据较少。故障诊断模型更加注重正常类多数样本正确分类,忽略故障少数类样本正确分类,导致分类器精度下降[12]。为使变压器故障数据均衡采用ADASYN将不同权重赋予不同的少数类变压器故障样本,减少原始数据不平衡分布导致的模型误差[13]。
ADASYN算法步骤:
1) 计算不平衡度:
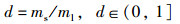
|
其中,ms为少数类样本的数量,ml为多数类样本数量。
2) 计算需要合成的样本数量:
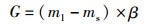
|
(1) |
其中,G为少数类样本和多数类样本的差值,β=1表示操作后形成完全平衡的数据集。
3) 计算比率ri。对xi(少数类样本)寻找出n维空间的K邻近:
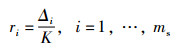
|
(2) |
其中,Δi为xi的K邻近中多数类占比。
4) 将ri标准化处理。用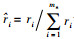
5) 计算合成样本的数目:
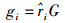
|
(3) |
6) 根据式(4)进行合成样本si:
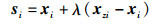
|
(4) |
其中,xzi-xi是n维空间中的差分向量,λ为(0,1] 间的随机数。
2 鲸鱼优化算法与其他智能优化算法相比,鲸鱼算法[14]具有步骤简单、需要的参数较少、求解精度高和收敛速度快的特点。鲸鱼优化算法根据座头鲸狩猎行为具象为3种策略追捕猎物。
2.1 包围策略在围捕猎物环节中,最佳鲸鱼发现猎物位置并对其包围,鲸鱼个体受到最佳鲸鱼个体的影响,向最佳鲸鱼靠近争夺猎物。更新公式:
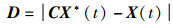
|
(5) |
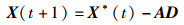
|
(6) |
式中,t为当前迭代;A为收敛因子;C为摆动因子;X*(t)和X(t)表示第t代中最优鲸鱼位置和第t代鲸鱼个体的位置,迭代过程中有更优解出现时,需要更新X*。计算收敛因子A和摆动因子C:
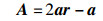
|
(7) |
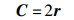
|
(8) |
其中,a由2到0线性变化;r为[0, 1]的随机向量。
2.2 螺旋气泡捕食策略气泡捕食策略分为摇摆包围捕食和螺旋气泡捕食,假设两种捕食行为概率各为50%。随机概率p为[0, 1]之间的常数。
当p < 0. 5,鲸鱼进行摇摆包围捕食,根据式(6) 更新自身位置。
当p≥0. 5,执行螺旋气泡捕食策略。鲸鱼个体位置更新公式:
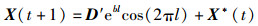
|
(9) |
其中,b为螺旋包围常数,l为(-1,1)间的随机数,D′为当前个体到最优个体的距离。
2.3 随机搜索捕猎鲸鱼在捕食过程中,不再根据最优鲸鱼位置更新自身位置,而是根据收敛因子A的变化进行大范围搜索,并更新自身位置。当|A| ≥1时,执行随机搜索捕猎。随机搜索的侦查范围较广,其数学模型为
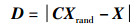
|
(10) |
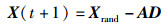
|
(11) |
其中,Xrand为当前种群中的一头随机鲸鱼。
3 鲸鱼优化算法改进策略 3.1 非线性收敛因子收敛因子是权衡鲸鱼算法局部勘探能力与全局搜索能力的关键因素。由式(7)可知,收敛因子A的变化由系数a决定,a从2线性迭代为0,导致收敛过程中A的变化不足。通过非线性收敛因子w[15],更新系数a。在算法早期增大种群移动幅度,算法后期降低种群移动幅度。数学模型:
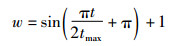
|
(12) |
其中,t为迭代次数。
图 1为非线性收敛因子w在迭代次数为500次的收敛趋势。搜索猎物阶段,种群有充足时间执行全局搜索,保持种群的多样化;气泡攻击阶段,局部搜索趋于精细化。随着收敛因子的动态变化,达到鲸鱼优化算法的全局搜索和局部探索能力的均衡。

|
| 图 1 非线性收敛因子迭代图 Fig.1 Iterative diagram of nonlinear convergence factor |
鲸鱼位置更新过程中,优化鲸鱼随机搜索策略。在有效迭代次数下,可提高算法收敛性。避免鲸鱼种群出现适应度远远高于当前鲸鱼种群平均的个体适应度造成多样性丧失。为此,引入了自适应学习因子[16]。
迭代中自适应学习因子公式为
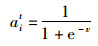
|
(13) |
其中,v∈(0,2]。
鲸鱼个体值的变化率公式:
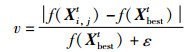
|
(14) |
式中,ε表示为避免零除法误差的最小常数,f(Xi,jt)为当前鲸鱼位置,f(Xbestt)为最优鲸鱼位置。
根据鲸鱼个体的适应度和其在种群中的整体相对位置来自适应更新自身位置,在有限的迭代次数下延缓了收敛趋势,提高分类精度,避免出现早熟现象。新的摇摆包围捕食、螺旋气泡捕食和随机搜索捕食鲸鱼位置更新公式分别为
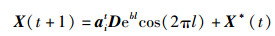
|
(15) |
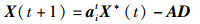
|
(16) |
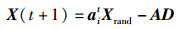
|
(17) |
在优化迭代过程中,会出现群体搜索停止,算法陷入局部桎梏。鉴于此,引入多项式变异算子[17],在维持解的多样性的同时提高算法后期对最优解的收敛能力,进一步提升算法局部极值的逃逸能力,如多项式变异算子公式:
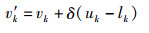
|
(18) |
其中,
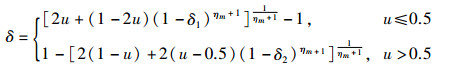
|
(19) |
其中,δ1=(vk-lk)/(uk-lk),δ2=(uk-vk)/(uk-lk);u为[0, 1]间的随机数;ηm为分布指数;lk为位置下限;uk为位置上限。
变异的概率按照Pm进行,其公式为
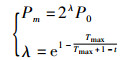
|
(20) |
其中,t表示迭代次数,Tmax表示最大迭代次数。式(20)的初始多项式变异频率较高(近似为2P0),但变异频率随迭代次数增多而降低。若频繁出现相同变异,会减慢算法的收敛速度。通过多项式变异,改变变异触发方式,不仅避免算法的不利变异,而且在算法停滞下引发变异。
3.4 IWOA算法性能测试选取多策略改进鲸鱼优化算法(IWOA)、粒子群算法(PSO)、鲸鱼优化算法(WOA)和灰狼优化算法(GWO)在4组基准测试函数上作寻优实验。测试函数见表 1。
| 测试函数 | 维度 | 搜索范围 | 最优解 |
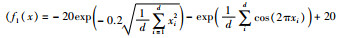 |
30 | [-20, 20] | 0 |
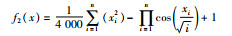 |
30 | [-500, 500] | 0 |
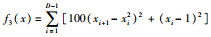 |
30 | [-30, 30] | 0 |
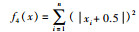 |
30 | [-100, 100] | 0 |
测试函数f1(x)是一个指数函数加上放大余弦函数构成的多峰函数,由于函数结构特殊性,存在多个局部最优值和一个全局最优值,用于检测算法的全局收敛速度。测试函数f2(x)为非线性多模态函数且数据分布存在多个局部极值,易使算法陷入局部最优,可以检验算法跳出局部极值能力。测试函数f3(x)的全局极小值位于抛物线形山谷内,此函数极难收敛到全局最小值。测试函数f4(x)为阶梯函数,会出现阶跃现象,从而产生大量局部极值。函数f3(x)和f4(x)被用来检验算法寻优性能。图 2~图 5为寻优过程曲线,表 2和表 3为寻优结果。可以看出,IWOA算法收敛速度快,跳出局部最优能力强,能收敛到全局极小点附近。

|
| 图 2 f1(x)寻优曲线 Fig.2 f1(x) optimization curves |

|
| 图 3 f2(x)寻优曲线 Fig.3 f2(x) optimization curves |

|
| 图 4 f3(x)寻优曲线 Fig.4 f3(x) optimization curves |

|
| 图 5 f4(x)寻优曲线 Fig.5 f4(x) optimization curves |
| 算法 | f1(x) | f2(x) | f3(x) | f4(x) |
| IWOA | 8.88×10-16 | 0 | 5.47×10-162 | 9.56×10-183 |
| WOA | 4.44×10-15 | 0 | 8.70×101 | 4.74×101 |
| GWO | 7.55×10-14 | 2.81×10-4 | 5.63×10-6 | 7.52×10-7 |
| PSO | 1.34 | 3.94×10-4 | 6.33 | 1.24 |
| 算法 | f1(x) | f2(x) | f3(x) | f4(x) |
| IWOA | 136 | 47 | 56 | 119 |
| WOA | 168 | 140 | 未收敛 | 未收敛 |
| GWO | 116 | 未收敛 | 401 | 434 |
| PSO | 未收敛 | 未收敛 | 未收敛 | 未收敛 |
在函数f1(x)的测试结果中,虽然GWO算法收敛速度最快,为116次,但收敛精度相比IWOA算法相差2. 95×10-12。与其他3个测试函数相比,IWOA算法在最少的迭代次数下收敛到了全局极小值,由此证明引入非线性收敛因子、自适应学习因子及多项式变异算子的组合优化策略的鲸鱼优化算法,具有更强的稳定性。
4 IWOA-KELM变压器故障诊断模型 4.1 核极限学习机核极限学习机相比ELM网络精度和泛化能力具有很大优势。引入核参数映射和正则化理论到ELM中,可以降低网络随机性和复杂程度,提高变压器故障分类精度[18],其数学模型为
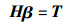
|
(21) |
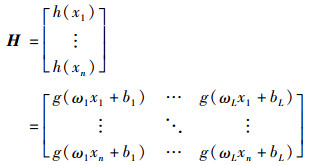
|
(22) |
其中,T为期望输出;β为隐层和输出层连接权重;H为隐层节点输出。
对式(23)求解得到β=HT(I/C+HHT)-1T。为提高模型鲁棒性引入对角矩阵I和正则化系数C:
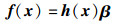
|
(23) |
其中,f(x)是网络分类输出;h(x)是隐层特征映射矩阵。
引入高斯核函数将原有的高维向量内积转换成了低纬向量的内积,能更迅速有效地衡量样本相似度,提高模型的稳定性。核函数的矩阵为ΩELM=HHT,其元素为ΩELM(i,j)=h(xi)h(xj)=K(xi,xj),改进后输出为
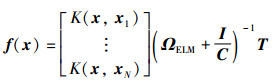
|
(24) |
引入高斯核函数[19]:
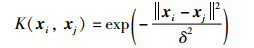
|
(25) |
核函数参数和正规化参数是影响变压器故障样本映射到高维特征空间分布的复杂性及模型稳定性的重要因素[20]。本文利用改进的鲸鱼搜索算法对核极限学习机参数寻优,解决了因参数随机选择造成的模型精度不足问题,提高了变压器故障样本分类精度。基于IWOA-KELM的相关超参数寻优流程如图 6所示,具体步骤为:

|
| 图 6 故障诊断算法流程图 Fig.6 Flowchart of fault diagnosis algorithm |
Step 1 数据预处理。对变压器故障原始数据集进行训练集与测试集的划分,训练集数据采用ADASYN均衡化。
Step 2 随机初始鲸鱼种群对KELM的两个超参数进行初始化。
Step 3 计算出当前迭代次数下的每一只鲸鱼的适应度值及其位置。首先,根据式(12)计算A。然后,产生随机数P。若P>0. 5,则采用式(15)更新鲸鱼种群;否则,判断|A|是否小于1,若|A|≥1,则采用式(16)更新鲸鱼种群;若|A| < 1,则采用式(17)更新鲸鱼种群。最后,对鲸鱼算法引入多项式变异。
Step 4 若未达到最大迭代次数,则继续执行;否则,将最佳的正则化系数和核函数参数赋予KELM,结束算法。
Step 5 确定IWOA优化后的最优超参数,构建最优IWOA-KELM诊断模型。
5 实例分析 5.1 数据集平衡化处理本文数据来源于文[21-22]和辽宁某电网提供的数据,通过对溶解气体分析判别变压器故障状态。通过IEC 60599分析,变压器油中H2、CH4、C2H2、C2H4、C2H6五类特征气体作为变压器故障特征[1]。因为特征气体浓度相差较大,直接输入模型会产生较大误差,所以采取式(26)对5种气体归一化处理[23]:
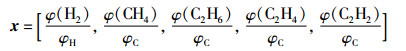
|
(26) |
600组数据按4∶ 1的比例划分为训练样本和测试样本。表 4中跟据变压器故障类型对其编号。比较第3列训练集样本数据量和第4列ADASYN处理后的各故障类型数据量。得出变压器故障数据经ADASYN处理后,故障样本数量分布更均衡。例如局部放电故障输入模型的样本量从40个提高到121个。
| 故障类型 | 编号 | 训练样本 | ADASYN训练数据 |
| 正常 | 0 | 121 | 119 |
| 高能放电 | 1 | 55 | 123 |
| 低能放电 | 2 | 104 | 125 |
| 高温过热 | 3 | 98 | 123 |
| 中低温过热 | 4 | 62 | 128 |
| 局部放电 | 5 | 40 | 121 |
120组测试样本数据用于测试训练后的模型分类准确率。为了说明数据平衡化前后对故障诊断结果的影响,每种故障诊断模型又分别进行了基于原始数据集和平衡数据集的故障诊断,故障分类准确率如图 7~图 14所示。计算模型故障综合准确率公式:
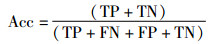
|
(27) |

|
| 图 7 基于原始数据集的PSO-KELM诊断结果 Fig.7 PSO-KELM diagnosis result based on original data set |

|
| 图 8 基于平衡化数据集的PSO-KELM诊断结果 Fig.8 PSO-KELM diagnosis result based on balanced data set |

|
| 图 9 基于原始数据集的GWO-KELM诊断结果 Fig.9 GWO-KELM diagnosis results based on the original data set |

|
| 图 10 基于平衡化数据集的GWO-KELM诊断结果 Fig.10 GWO-KELM diagnosis result based on balanced data set |

|
| 图 11 基于原始数据集的WOA-KELM诊断结果图 Fig.11 WOA-KELM diagnosis results based on the original data set |

|
| 图 12 基于平衡化数据集的WOA-KELM诊断结果 |

|
| 图 13 基于原始数据集的IWOA-KELM诊断结果 Fig.13 IWOA-KELM diagnosis results based on the original data set |

|
| 图 14 基于平衡化数据集的IWOA-KELM诊断结果图 Fig.14 IWOA-KELM diagnosis result based on balanced data set |
其中,Acc为准确率;TP,预测为正,真实为正;FP,预测为正,真实为负;TN,预测为负,真实为负;FN,预测为负,真实为正。当前类为正,其他统称负。
表 5、表 6分别列出了原始训练数据和平衡化数据,各个故障诊断模型对不同故障类型的准确率。图 15为4个故障诊断模型的综合故障准确率对比。
| 单位: % | |||||||||||||||||||||||||||||
| 故障类型 | PSO-KELM | GWO-KELM | WOA-KELM | IWOA-KELM | |||||||||||||||||||||||||
| 0 | 89.66 | 86.21 | 86.21 | 86.21 | |||||||||||||||||||||||||
| 1 | 73.33 | 66.67 | 73.33 | 80.00 | |||||||||||||||||||||||||
| 2 | 76.92 | 76.92 | 80.77 | 84.62 | |||||||||||||||||||||||||
| 3 | 73.91 | 82.61 | 86.96 | 91.30 | |||||||||||||||||||||||||
| 4 | 68.75 | 81.25 | 75.00 | 81.25 | |||||||||||||||||||||||||
| 5 | 72.73 | 72.73 | 63.64 | 63.64 | |||||||||||||||||||||||||
| 单位: % | |||||||||||||||||||||||||||||
| 故障类型 | PSO-KELM | GWO-KELM | WOA-KELM | IWOA-KELM | |||||||||||||||||||||||||
| 0 | 82.76 | 89.66 | 86.21 | 93.10 | |||||||||||||||||||||||||
| 1 | 73.33 | 73.33 | 73.33 | 93.33 | |||||||||||||||||||||||||
| 2 | 80.77 | 80.77 | 84.62 | 88.46 | |||||||||||||||||||||||||
| 3 | 73.91 | 78.26 | 86.96 | 91.30 | |||||||||||||||||||||||||
| 4 | 81.25 | 87.50 | 81.25 | 93.75 | |||||||||||||||||||||||||
| 5 | 81.82 | 72.73 | 90.91 | 90.91 | |||||||||||||||||||||||||

|
| 图 15 4个模型故障诊断综合准确率对比图 Fig.15 Comparison chart of comprehensive accuracy rate of fault diagnosis of four models |
由图 7~图 15、表 5和表 6可得,经ADASYN数据预处理后的IWOA-KELM模型,故障1、故障4和故障5的诊断精度分别提升13. 3%、12. 5%和27. 27%,其他模型诊断精度也有不同比例提升。这说明变压器故障样本不均衡会影响故障辨识结果,平衡化数据处理对少数类变压器样本故障辨识精度有所提升。
由表 5、表 6和图 15看出,基于IWOA优化的KELM变压器故障诊断模型,每种故障类型的分辨精度和综合准确度均优于其他模型。这说明利用多种策略改进的鲸鱼优化算法对KELM的相关参数优化后建立的变压器故障诊断模型故障辨识精度最高。
5.3 其他故障诊断模型对比分析选取BP、SVM、ELM、KNN和KELM五种变压器故障诊断模型在经验参数进行训练[24]。将其故障诊断结果与IWOA-KELM变压器故障诊断结果对比分析。每个模型重复训练30次,图 16为各模型故障诊断平均准确率的对比分析图。图中基于IWOA- KELM的变压器故障诊断平均准确率为91. 34%,显著高于其他模型的故障诊断准确率,验证了IWOA-KELM变压器故障诊断模型的优势。

|
| 图 16 故障诊断模型准确率对比图 Fig.16 Comparison of the accuracy of fault diagnosis models |
1) 本文利用ADASYN解决变压器各类别故障数据不平衡化问题。数据经过平衡化处理后,故障诊断的准确率有所提升。
2) 通过寻优实验对比,证明引入非线性收敛因子,自适应学习因子及多项式变异几种优化策略对鲸鱼优化算法进行改进,避免了算法陷入局部桎梏,提高了算法探索和开发能力,加快了算法向最优解收敛的速度。
3) 建立IWOA-KELM变压器故障诊断模型。仿真实验结果表明,与BP、SVM、ELM、KNN和KELM等主流模型对比,IWOA-KELM变压器故障诊断平均准确率最高。与PSO-KELM、GWO-KELM、WOA-KELM等其他算法建立的故障诊断模型相比,本文提出的IWOA-KELM诊断模型得到更准确诊断结果,具有理论研究及实际工程意义。
| [1] |
ZHENG H B, ZHANG Y Y, LIU J F, et al. A novel model based on wavelet LS-SVM integrated improved PSO algorithm for forecasting of dissolved gas contentin power transformers[J]. Electric Power Systems Research, 2018, 155: 196-205. DOI:10.1016/j.epsr.2017.10.010 |
| [2] |
周光宇, 马松玲. 基于机器学习与DGA的变压器故障诊断及定位研究[J]. 高压电器, 2020, 56(6): 262-268. ZHOU G Y, MA S L. Study of transformer fault diagnosis and location based on machine learning and DGA[J]. High Voltage Apparatus, 2020, 56(6): 262-268. |
| [3] |
李刚, 于长海, 刘云鹏, 等. 电力变压器故障预测与健康管理: 挑战与展望[J]. 电力系统自动化, 2017, 41(23): 156-167. LI G, YU C H, LIU Y P, et al. Fault prediction and health management of power transformers: Challenges and prospects[J]. Automation of Electric Power Systems, 2017, 41(23): 156-167. DOI:10.7500/AEPS20170213002 |
| [4] |
谢国民, 蔺晓雨. 基于改进SSA优化MDS-SVM的变压器故障诊断方法[J/OL]. 控制与决策[2022-02-03]. https://doi.org/10.13195/j.kzyjc.2021.1437. XIE G M, LIN X Y. Transformer fault diagnosis method based on improved SSA and optimized MDS-SVM[J/OL]. Control and Decision[2022-02-03]. https://doi.org/10.13195/j.kzyjc.2021.1437. |
| [5] |
赵文清, 严海, 周震东, 等. 基于残差BP神经网络的变压器故障诊断[J]. 电力自动化设备, 2020, 40(2): 143-148. ZHAO W Q, YAN H, ZHOU Z D, et al. Transformer fault diagnosis based on residual BP neural network[J]. Electric Power Automation Equipment, 2020, 40(2): 143-148. |
| [6] |
刘凯, 彭维捷, 杨学君. 特征优化和模糊理论在变压器故障诊断中的应用[J]. 电力系统保护与控制, 2016, 44(15): 54-60. LIU K, PENG W J, YANG X J. Application of feature optimization and fuzzy theory in transformer fault diagnosis[J]. Power System Protection and Control, 2016, 44(15): 54-60. DOI:10.7667/PSPC151515 |
| [7] |
王春明, 朱永利. 基于NSGA2优化正则极限学习机的变压器油色谱故障诊断[J]. 高压电器, 2020, 56(9): 210-215. WANG C M, ZHU Y L. Fault diagnosis of transformer oil chromatography based on NSGA2 optimized regular extreme learning machine[J]. High Voltage Electrical Apparatus, 2020, 56(9): 210-215. |
| [8] |
BEJ S, DAVTYAN N, WOLFIEN M, et al. LoRAS: An oversampling approach for imbalanced datasets[J]. Machine Learning, 2021, 110(2): 279-301. DOI:10.1007/s10994-020-05913-4 |
| [9] |
BECKMANN M, EBECKEN N F F, PIRES DE LIMA B S L, et al. A KNN undersampling approach for data balancing[J]. Journal of Intelligent Learning Systems and Applications, 2015, 7(4): 104-116. DOI:10.4236/jilsa.2015.74010 |
| [10] |
李亮, 范瑾, 闫林, 等. 基于混合采样和支持向量机的变压器故障诊断[J]. 中国电力, 2021, 54(12): 150-155. LI L, FAN J, YAN L, et al. Transformer fault diagnosis based on mixed sampling and support vector machine[J]. China Electric Power, 2021, 54(12): 150-155. |
| [11] |
刘云鹏, 和家慧, 许自强, 等. 结合AdaBoost和代价敏感的变压器故障诊断方法[J]. 华北电力大学学报(自然科学版), 2022, 49(5): 1-9. LIU Y P, HE J H, XU Z Q, et al. Transformer fault diagnosis method combining AdaBoost and cost-sensitive[J]. Journal of North China Electric Power University (Natural Science Edition), 2022, 49(5): 1-9. |
| [12] |
刘云鹏, 和家慧, 许自强, 等. 基于SVM SMOTE的电力变压器故障样本均衡化方法[J]. 高电压技术, 2020, 46(7): 2522-2529. LIU Y P, HE J H, XU Z Q, et al. Power transformer fault sample equalization method based on SVM SMOTE[J]. High Voltage Technology, 2020, 46(7): 2522-2529. |
| [13] |
HE H B, BAI Y, GARCIA E A, et al. ADASYN: Adaptive synthetic sampling approach for imbalanced learning[C]//2008 IEEE International Joint Conference on Neural Networks. Piscataway, USA: IEEE, 2008: 1322-1328.
|
| [14] |
MIRJALILI S, LEWIS A. The whale optimization algorithm[J]. Advances in Engineering Software, 2016, 95: 51-67. |
| [15] |
张珍珍, 贺兴时, 于青林, 等. 多阶段动态扰动和动态惯性权重的布谷鸟算法[J]. 计算机工程与应用, 2022, 58(1): 79-88. ZHANG Z Z, HE X S, YU Q L, et al. Cuckoo algorithm for multi-stage dynamic disturbance and dynamic inertia weight[J]. Computer Engineering and Applications, 2022, 58(1): 79-88. |
| [16] |
ZHU Y L, YOUSEFI N. Optimal parameter identification of PEMFC stacks using adaptive sparrow search algorithm[J]. International Journal of Hydrogen Energy, 2021, 46(14): 9541-9552. |
| [17] |
温泽宇, 谢珺, 谢刚, 等. 基于新型拥挤度距离的多目标麻雀搜索算法[J]. 计算机工程与应用, 2021, 57(22): 102-109. WEN Z Y, XIE J, XIE G, et al. Multi-objective sparrow search algorithm based on a new crowding degree distance[J]. Computer Engineering and Applications, 2021, 57(22): 102-109. |
| [18] |
寇英信, 奚之飞, 徐安, 等. 基于改进核极限学习机和集成学习理论的目标机动轨迹预测[J]. 国防科技大学学报, 2021, 43(5): 23-35. KOU Y X, XI Z F, XU A, et al. Target maneuver trajectory prediction based on improved nuclear extreme learning machine and integrated learning theory[J]. Journal of National University of Defense Technology, 2021, 43(5): 23-35. |
| [19] |
徐睿, 梁循, 齐金山, 等. 极限学习机前沿进展与趋势[J]. 计算机学报, 2019, 42(7): 1640-1670. XU R, LIANG X, QI J S, et al. Advances and trends in extreme learning machine[J]. Chinese Journal of Computers, 2019, 42(7): 1640-1670. |
| [20] |
范君, 王新, 徐慧. 粒子群优化混合核极限学习机的构造煤厚度预测方法[J]. 计算机应用, 2018, 38(6): 1820-1825, 1830. FAN J, WANG X, XU H. Tectonic coal thickness prediction method based on particle swarm optimization hybrid kernel extreme learning machine[J]. Journal of Computer Applications, 2018, 38(6): 1820-1825, 1830. |
| [21] |
田晓飞. 基于改进蝙蝠算法优化支持向量机的变压器故障诊断研究[D]. 成都: 西华大学, 2019. TIAN X F. Research on transformer fault diagnosis based on improved bat algorithm to optimize support vector machine[D]. Chengdu: Xihua University, 2019. |
| [22] |
尹金良. 基于相关向量机的油浸式电力变压器故障诊断方法研究[D]. 北京: 华北电力大学, 2013. YIN J L. Research on fault diagnosis method of oil-immersed power transformer based on correlation vector machine[D]. Beijing: North China Electric Power University, 2013. |
| [23] |
HUANG X Y, HUANG X L, WANG B R, et al. Fault diagnosis of transformer based on modified grey wolf optimization algorithm and support vector machine[J]. IEEJ Transactions on Electrical and Electronic Engineering, 2020, 15(3): 409-417. |
| [24] |
汪可, 李金忠, 张书琦, 等. 变压器故障诊断用油中溶解气体新特征参量[J]. 中国电机工程学报, 2016, 36(23): 6570-6578, 6625. WANG K, LI J Z, ZHANG S Q, et al. New characteristic parameters of dissolved gas in oil for transformer fault diagnosis[J]. Proceedings of the Chinese Society of Electrical Engineering, 2016, 36(23): 6570-6578, 6625. |