



2. 重庆邮电大学自动化学院, 重庆 400065;
3. 重庆邮电大学光电工程学院, 重庆 400065
2. College of Automation, Chongqing University of Posts and Telecommunications, Chongqing 400065, China;
3. College of Photoelectric Engineering, Chongqing University of Posts and Telecommunications, Chongqing 400065, China
目前国内外对移动机器人的研究越来越热衷,工业机器人、服务机器人等已经渗透到人们生产和生活的方方面面. 人机交互是实现人与计算机对话的技术,它也是实现移动机器人为人类服务的关键技术. 其中语音人机交互[1-2]作为最自然最直接的人机交互技术,对更好地实现人机对话具有很大的优势和研究意义.
随着语音人机交互技术发展的越来越成熟,人们对噪声环境下语音识别率的要求也越来越高,因此提高噪声环境下语音识别的鲁棒性和识别率就成为了当前研究的热点和难点. 一个比较完整的语音识别控制系统大体分为3个部分: 语音信号特征提取、 声学模型和模式匹配、 语义理解[3]. 语音特征提取是从原始语音信号中提取出具有代表性的参数来表示语音信号,作为语音识别技术中最基础最重要的环节,特征提取对后端语音识别起到至关重要的作用. 因此特征提取的鲁棒性[4-5]研究对于提高语音识别系统的鲁棒性和识别率具有重要的理论意义和使用价值.
在语音识别中经典的谱估计技术包括美尔频率倒谱系数(MFCC)特征提取中用到的快速傅立叶(FFT)变换谱和线性预测(LPC)谱估计. 由文[6]可知,MFCC特征提取具有很好的鲁棒性,但该特征提取技术采用FFT获得的谱估计信息分辨率不高,鲁棒性存在进一步提高的空间. 针对此问题,曾经有人采用希尔伯特(Hilbert)谱估计[7-8]、 最小方差无失真响应(MVDR)谱估计[5]和多信号分类法(MUSIC)谱估计[9]等谱估计技术来代替FFT谱,都取得了较好的分辨率,提高了特征提取的鲁棒性和语音识别系统的识别率. 特别是基于MUSIC谱估计的特征提取,由于MUSIC谱估计具有很高的分辨率,使得特征提取具有很高的鲁棒性,但在信噪比(SNR)稍大时该谱估计分辨率会有所下降,特征提取的鲁棒性也随之下降. 通过研究最小模法(MNM)谱估计发现,随着信噪比的增大该谱估计分辨率越高[10-11],因此本文提出将二者结合进行谱估计,以达到在不同信噪比的情况下都能提高特征提取鲁棒性和语音识别系统识别率的目的.
本文提出的算法是在基于MUSIC谱估计特征提取的基础上进行的改进,通过分析MUSIC谱估计和MNM谱估计在不同信噪比时的分辨率,找出两者谱估计分辨率相当时临界信噪比的值,再根据临界信噪比判断本文特征提取算法具体运行时采用何种谱估计. 当信噪比低于临界值时采用MUSIC谱估计; 等于临界值时两者皆采用,结果选择分辨率高的输出; 高于临界值时采用MNM谱估计. 在移动机器人平台上对本文算法和传统的MFCC特征提取、 基于MUSIC谱估计的特征提取方法进行实验验证,通过分析比较实验结果表明,本文提出的算法能够有效地提高特征提取的鲁棒性和语音识别率.
2 传统的MFCC特征提取方法美尔频率倒谱系数(MFCC)特征是着眼于人耳听觉感知特性提出的. MFCC特征提取过程主要包括预处理、 谱估计、 滤波器组和降维过程,其中预处理部分包含预加重、 加窗和分帧. 具体原理框图[12]如图 1所示.

|
| 图 1 MFCC特征提取 Fig. 1 MFCC feature extraction |
预加重处理是将语音信号通过高通滤波器来滤除低频信号,从而使语音信号的高频特性更加突现. 针对语音信号只在较短的时间内呈现出平稳性,将其划分为一个个的短时段即分帧; 与此同时,为了避免语音信号动态信息的丢失,两两相邻的帧之间会有一段重叠区域,这些重叠区域一段的长度是帧长的1/2或1/3. 加窗是将每个语音帧乘上窗函数,来增加每帧左右端的连续性. 对分帧和加窗后的各帧语音信号进行FFT变换得到其频谱,接着对其频谱取模平方从而得到语音信号的功率谱. 将所得的功率谱通过Mel滤波器组得到滤波系数,再将每个滤波器的输出取对数,得到相应频带的对数功率谱; 并进行反离散余弦变换(DCT),得到MFCC系数[13-14].
在Matlab上仿真语音信号功率谱[15],通过多次重复仿真可知,当信噪比不同时,MFCC特征提取中FFT谱估计的分辨率没有太大变化,因此本文用图 2作为代表.

|
| 图 2 MFCC特征提取中的谱估计图 Fig. 2 The map of spectrum estimation in MFCC feature extraction |
从图 2可以看出,MFCC特征提取中谱估计的特点是: 在语音信号能量较大时即谱峰处谱估计的准确率不高,在信号能量较低即频谱谷值处分辨率稍好. 但总的来说,MFCC特征提取中谱估计的分辨率不高,有待进一步提升.
3 基于MUSIC谱估计的特征提取基于MUSIC谱估计的特征提取原理与MFCC特征提取类似,其基本结构原理图如图 3所示.

|
| 图 3 MUSIC-MFCC特征提取 Fig. 3 MUSIC-MFCC feature extraction |
从图 3可以看出,基于MUSIC算法流程与MFCC相比,唯一不同的是其计算功率谱的方法. 基于MUSIC谱估计的特征提取方法既保留了MFCC特征提取的优点,同时也改进了MFCC的不足之处,其谱估计信息具有更高的分辨率,对语音信号的估计也更为准确.
MUSIC算法是先计算多个信号的自相关矩阵R,对矩阵R进行特征分解求出其特征值和特征向量,然后依据信号子空间(由信号特征向量组成)和噪声子空间(由噪声向量组成)的相互正交关系来确定信号的谱估计[16].
对于由p个正弦分量构成的信号,设其复振幅和频率分别为gk、 ωk(k=1,2,…,p),信号表示为

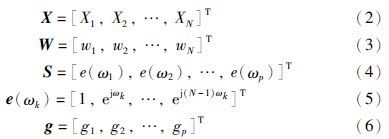
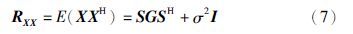

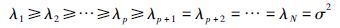
由于这种分解可保留有用信号的信息,舍弃噪声信息,因此可能通过信号子空间获得信号频率的良好估计. 同时这种估计将不反映噪声的变换,受噪声影响很小,因而在信号成分提取和噪声有效抑制的意义下,这种估计可认为是最优的[17]. 功率谱函数为
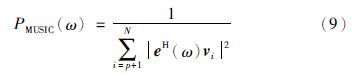
当ω=ωi(i=1,2,…,p)时,PMUSIC(w)将有很大的峰值,谱峰具有很好的尖锐性,从而MUSIC算法具有非常高的分辨率和稳定性.
当信噪比为0 dB、 5 dB、 10 dB时,MUSIC谱估计图如图 4所示.

|
| 图 4 MUSIC谱估计图 Fig. 4 The spectral estimation map of MUSIC |
从图 4可以看出,当信噪比为0 dB时MUSIC谱估计的准确性最好,为5 dB时稍差,为10 dB时最差. 当信噪比较小时,也就是环境噪声较大时,MUSIC谱估计的分辨率较好,在较大噪声环境下用这种谱估计将很大程度提高特征提取的鲁棒性.
4 基于MUSIC/MNM谱估计的特征提取由上文可知,基于MUSIC谱估计的特征提取具有很高的鲁棒性,但是在信噪比较大时谱估计的准确性有所下降,特征提取的鲁棒性也随着下降. 通过研究MNM谱估计发现,随着信噪比的增大,该算法谱估计分辨率越好. 因此本文将MUSIC和MNM两种算法结合提出了基于MUSIC/MNM谱估计的特征提取,其原理与MFCC特征提取类似,其基本结构原理图如图 5所示.

|
| 图 5 MUSIC/MNM-MFCC特征提取 Fig. 5 MUSIC/MNM-MFCC feature extraction |
从图 5可以看出,MUSIC/MNM算法流程与MFCC相比也是在计算功率谱时不同. 基于MUSIC/MNM谱估计的特征提取方法采用MUSIC/MNM进行谱估计,同样保留了MFCC的优势,也改进了MFCC的不足之处. 而且,与MUSIC相比,MUSIC/MNM在信噪比大小不同时都提高了谱估计的分辨率,使得各种噪声环境下的语音识别率都有很大提高.
第3节已经讲述了MUSIC谱估计的原理,本节将主要描述MNM谱估计原理及MNM与MUSIC结合进行谱估计的方法.
4.1 MNM谱估计最小模法(MNM)是Kumarensan和Tufts提出的,其实质仍然是利用信号子空间与噪声子空间正交补空间的垂直关系来确定谱估计[18, 19]. 首先需要在噪声子空间中寻找一个矢量vi(i=p+1,…,N),该矢量在第1个元素为1的约束条件下具有最小模特性. 然后利用vi的最小模特性,并考虑到它位于噪声子空间ΩN-p且第1个元素值为1,可推导出:
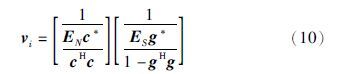
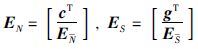 ,cT、 gT分别表示EN和ES的第1行矢量,E、 E分别表示EN和ES除第1行之外的其它行所组成的矩阵. 由此同MUSIC方法一样,最小模法也是考虑ω的变化来进行谱估计[20],功率谱函数为
,cT、 gT分别表示EN和ES的第1行矢量,E、 E分别表示EN和ES除第1行之外的其它行所组成的矩阵. 由此同MUSIC方法一样,最小模法也是考虑ω的变化来进行谱估计[20],功率谱函数为
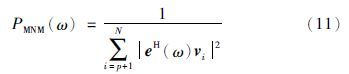
当信噪比为0 dB、 5 dB、 10 dB时,MNM谱估计图如图 6所示.

|
| 图 6 MNM谱估计图 Fig. 6 The spectral estimation map of MNM |
从图 6可以看出,当信噪比为0 dB时MNM谱估计的分辨率较差,5 dB时稍好,10 dB时最好,即当环境噪声较小时MNM算法能大大提高谱估计的分辨率,提高特征提取的鲁棒性.
4.2 MUSIC/MNM谱估计MUSIC/MNM谱估计算法的重点是找到临界信噪比,这需要进行多次对比实验,由于篇幅有限本文只选取具有代表性的实验对比图,如图 7所示. 图 7中(a)、 (b)和(c)分别是信噪比为0 dB、 5 dB和10 dB时的两种谱估计对比图. 由图 7可知,当信噪比为0 dB时MUSIC谱估计的分辨率较好,当信噪比为5 dB时二者的分辨率差别不大,当信噪比为10 dB时MNM谱估计的分辨率较好. 因此可以确定SNR=5 dB为临界信噪比. 当SNR<5 dB时,采用MUSIC谱估计; 当SNR>5 dB时,采用MNM谱估计.

|
| 图 7 两种谱估计效果对比图 Fig. 7 The Comparison map of two kinds of spectral estimation |
结合MUSIC和MNM谱估计后,通过一系列实验验证其谱估计的分辨率. 实验结果表明,当信噪比大小不同时其谱估计的分辨率差别不大,准确率都非常高. 以图 8作为代表,从图 8可以看出谱估计的分辨率已达到很高的水平.

|
| 图 8 MUSIC/MNM谱估计 Fig. 8 The spectral estimation map of MUSICMNM |
为了验证本文算法的有效性,通过多次修改代码最终得到合适的程序,用Cool Edit Pro录制语音建立语音库,并从中选取多对语音控制指令. 用Matlab实现Babble噪声与纯净指令合成不同信噪比的语音指令. 在移动机器人
平台上进行语音抗噪实验,从而对本文算法和MFCC特征提取算法、 MUSIC特征提取算法的语音识别性能进行对比.
本实验分别在信噪比为0 dB、 5 dB、 10 dB的环境下进行上千次语音指令重复测试实验. 不同SNR的语音识别结果对比如表 1所示.
| 算法信噪比 | 0 dB | 5 dB | 10 dB |
| MFCC | 20.782 | 34.949 | 55.379 |
| MUSIC | 80.283 | 75.836 | 65.192 |
| MUSIC/MNM | 81.721 | 82.043 | 84.163 |
由表 1可以看出,本文提出的算法在信噪比不同时识别率都高出传统MFCC特征提取识算法很多; 相对于MUSIC特征提取算法,本文算法的识别率也有一定的提高且随着信噪比的增大这种效果越来越明显.
选取10人的不同语音重复实验,对本文算法和MFCC特征提取算法、 MUSIC特征提取算法的语音识别系统的识别率和鲁棒性进行比较. 经过统计可得每个人在Babble噪声下不同信噪比的语音识别结果如表 2所示.
| 人员编号信噪比/算法 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
| MFCC | 18.659 | 20.221 | 23.524 | 19.667 | 16.000 | 29.325 | 20.000 | 19.333 | 25.000 | 16.100 | |
| 0 dB | MUSIC | 75.110 | 88.000 | 75.422 | 85.000 | 69.833 | 87.681 | 81.222 | 77.900 | 83.000 | 79.666 |
| MUSIC/MNM | 82.134 | 79.110 | 80.347 | 76.891 | 85.068 | 83.885 | 86.125 | 83.000 | 82.433 | 78.222 | |
| MFCC | 30.233 | 29.555 | 34.000 | 35.736 | 38.416 | 36.000 | 37.333 | 32.666 | 38.000 | 37.555 | |
| 5 dB | MUSIC | 75.235 | 77.000 | 74.110 | 80.222 | 69.900 | 76.555 | 81.111 | 75.333 | 71.000 | 77.900 |
| MUSIC/MNM | 78.100 | 80.990 | 85.222 | 84.000 | 78.990 | 86.888 | 79.455 | 84.222 | 79.900 | 82.666 | |
| MFCC | 58.245 | 60.361 | 49.867 | 55.752 | 50.211 | 59.880 | 53.621 | 49.666 | 58.770 | 57.420 | |
| 10 dB | MUSIC | 64.233 | 69.000 | 59.200 | 65.777 | 79.000 | 60.400 | 63.333 | 55.660 | 69.000 | 66.320 |
| MUSIC/MNM | 82.333 | 85.011 | 79.661 | 88.455 | 84.222 | 79.633 | 87.666 | 85.333 | 80.550 | 88.770 | |
由表 2可知,当信噪比为0 dB时本文特征提取算法与MFCC特征提取算法和MUSIC特征提取算法相比,平均识别率分别高了74.56%和1.76%. 由于当信噪比较小时,本文算法中主要用到的是MUSIC谱估计,所以与MUSIC特征提取相比识别率没有太大变动; 当信噪比为5 dB时,本文特征提取算法与MFCC特征提取算法和MUSIC特征提取算法相比平均识别率分别高了57.40%和8.94%,由于此时MUSIC和MNM谱估计的分辨率相当,本文算法会自动选取较好的识别效果,所以平均识别率较MUSIC特征提取有所提高; 当信噪比为10 dB时,本文特征提取算法与MFCC特征提取算法和MUSIC特征提取算法相比平均识别率分别提高了34.44%和22.81%,此时信噪比较大,本文算法会选择信噪比较大时分辨率较高的MNM谱估计,所以较MUSIC特征提取平均识别率提升较大. 综上所述,当信噪比大小不同时,本文算法的平均识别率都维持在较高值即噪声大小对其鲁棒性几乎没有影响,且信噪比越大本文算法的优越性越能得到体现.
通过计算表 2中的实验数据的标准差可以看出本文算法对提高语音识别鲁棒性在3种算法中是最高的,图 9是3种算法在不同信噪比时标准差的直观对比图.

|
| 图 9 不同信噪比的标准差示意图 Fig. 9 The standard deviation map of different SNR |
本文提出的基于MUSIC/MNM谱估计的鲁棒语音特征提取算法在信噪比大小不同时都具有较高的语音识别率且鲁棒性较好,特别是当信噪比较小时,较传统的MFCC鲁棒特征提取算法的语音识别率和鲁棒性效果更显著. 针对基于MUSIC谱估计的鲁棒语音特征提取算法,本文算法着重在信噪比较大时提高识别率,这就提高了本文算法在各种信噪比条件下的平均识别率. 随着将来进一步的深入研究,基于MUSIC/MNM谱估计的鲁棒语音特征提取在语音识别方面会具有更广泛的应用前景.
| [1] | Evans R E, Kortum P. The impact of voice characteristics on user response in an interactive voice response system[J]. Interacting with Computers, 2010, 22(6): 606-614. |
| [2] | García V M Á. Voice interactive classroom, a service-oriented software architecture for speech-enabled learning[J]. Journal of Network & Computer Applications, 2010, 33(5): 603-610. |
| [3] | 蔡莲红, 黄德智, 蔡锐. 现代语音技术基础与应用[M]. 北京: 清华大学出版社, 2003: 233-237. Cai L H, Huang D Z, Cai R. The foundation and Application of modern speech technology[M]. Beijing: Tsinghua University Press, 2003: 233-237. |
| [4] | 魏勋, 耿志辉, 王晓攀. 语音识别的鲁棒性特征提取方法研究[J]. 无线电工程, 2010, 40(8): 59-61. Wei X, Geng Z H, Wang X P. Research on method of robust feature extraction for speech recognition[J]. Radio Engineering, 2010, 40(8): 59-61. |
| [5] | 韩志艳. 语音信号鲁棒特征提取及可视化技术研究[D]. 沈阳: 东北大学, 2009. Han Z Y. Research on robust feature extracting and visualization of speech signal[D]. Shenyang: Northeastern University, 2009. |
| [6] | Dev A, Poonam B. Robust features for noisy speech recognition using MFCC computation from magnitude spectrum of higher order autocorrelation coefficients[J]. International Journal of Computer Applications, 2010, 10(8): 36-38. |
| [7] | 余耀, 赵鹤鸣. 一种改进的最小统计噪声功率谱估计算法[J]. 计算机工程与应用, 2013, 49(4): 134-137. Yu Y, Zhao H M. Improved of noise estimation algorithm based on minimum statistic[J]. Computer Engineering and Applications, 2013, 49(4): 134-137. |
| [8] | Seyedin S, Ahadi M. Feature extraction based on DCT and MVDR spectral estimation for robust speech recognition[C]//Proceedings of 9th International Conference on Signal Processing. Piscataway, NJ, USA: IEEE, 2008: 605-608. |
| [9] | 梁国龙, 张锴, 范展, 等. 单矢量传感器MUSIC算法的DOA估计及性能评价[J]. 哈尔滨工程大学学报, 2012, 1(1): 30-36. Liang G L, Zhang K, Fan Z, et al. Performance evaluation of DOA estimation using a single acoustic vector-sensor based on an improved MUSIC algorithm[J]. Journal of Harbin Engineering University, 2012, 1(1): 30-36. |
| [10] | 朱凯, 王可人, 薛磊. MUSIC法与最小模法的性能比较[J]. 航天电子对抗, 2003(2): 36-39. Zhu K, Wang K R, Xue L. The performance comparison between MUSIC method and minimum norm method[J]. Aerospace Electronic Warfare, 2003(2): 36-39. |
| [11] | 卢海杰, 章新华, 熊鑫. MUSIC与MNM在均匀圆阵的方位估计性能比较[J]. 声学技术, 2010, 29(6): 642-646. Lu H J, Zhang X H, Xiong X. Research on the DOA performances of MUSIC and MNM with uniform circular array[J]. Technical Acoustics, 2010, 29(6): 642-646. |
| [12] | Zhao H, Zhao K, Liu H, et al. Improved MFCC feature extraction combining symmetric ICA algorithm for robust speech recognition[J]. Journal of multimedia, 2012, 7(1): 74-81. |
| [13] | Xie C, Cao X L, He L L. Algorithm of abnormal audio recognition based on improved MFCC[J]. Procedia Engineering, 2012, 29(4): 731-737. |
| [14] | 邹大勇, 李玲. 有色噪声环境中鲁棒语音特征提取研究[J]. 计算机仿真, 2011, 28(5): 395-398. Zou D Y, Li L. Research on robust speech feature parameter extraction in colored noise environment[J]. Computer Simulation, 2011, 28(5): 395-398. |
| [15] | 王福杰, 潘宏侠. MATLAB中几种功率谱估计函数的比较分析与选择[J]. 电子产品可靠性与环境试验, 2009, 27(6): 28-31. Wang F J, Pan H X. Comparative analysis and selection of several MATLAB power spectrum estimation[J]. Electronic Product Reliability and Environmental Testing, 2009, 27(6): 28-31. |
| [16] | 邵英, 李晓明, 张晓明. 基于插值FFT和多信号分类法的间谐波参数检测[J]. 海军工程大学学报, 2011; 23(4): 53-59. Shao Y, Li X M, Zhang X M. Interharmonics parameter detection based on interpolation FFT and multiple signal classification algorithms[J]. Journal of Naval University of Engineering, 2011, 23(4): 53-59. |
| [17] | Yan F G, Jin M, Qiao X L. Source localization based on symmetrical MUSIC and its statistical performance analysis[J]. Science China: Information Sciences, 2013, 56(6): 1-13. |
| [18] | 朱丽芹. 最小模原理的证明[J]. 济南大学学报: 自然科学版, 2009, 23(3): 315-316. Zhu L Q. Proof of minimum modulus principle[J]. Journal of University of Jinan: Science and Technology, 2009, 23(3): 315-316. |
| [19] | Nenonen J T, Hämäläinen M S, Iimoniemi R J. Minimum-norm estimation in a boundary-element torso model[J]. Medical and Biological Engineering and Computing, 1994, 32(1): 43-48. |
| [20] | Hui W. On minimum norm control for an elastic robot system[J]. Systems Science and Systems Engineering, 2002, 11(2): 158-163. |