



2. 河南理工大学电气工程与自动化学院, 河南 焦作 454000;
3. 中国科学院大学, 北京 100049
2. School of Electrical Engineering and Automation, Henan Polytechnic University, Jiaozuo 454000, China;
3. University of Chinese Academy of Sciences, Beijing 100049, China
1 引言
随着信息获取技术的飞速发展,人们在日常生活中所接触到的数据的维数越来越高;直接在高维空间对数据进行处理不仅耗时而且易受噪声等因素的干扰.因此,设计一种合适的降维算法对数据进行表达已成为数据处理领域的一个关键问题[1-3].作为一种常见的降维方法,非负矩阵分解(non-negative matrix factorization,NMF)[4]理论在文本分析[5]、图像处理[6]和视频表达[7]等领域均有应用且取得了不错的成绩.这是因为现实中的许多数据均为非负数据,非负性约束使得NMF算法可以学习到一个稀疏的、局部的数据表达方法[8].有研究结果表明[9],人类大脑对事物的感知过程也具有基于局部表达的特性;因此与主成分分析(principal component analysis,PCA) 等基于整体的数据表达方法相比,NMF算法是一种更加贴近大脑感知过程的数据表达方法.
基于Lee等人[4]的工作,近年来涌现了许多不同的NMF的变形算法.例如,Liu和Ding等人[10-12]提出了基于稀疏约束的NMF算法,以显式的形式对系数矩阵的稀疏性进行控制. Liu等人[13]将部分样本的标签信息作为约束项添加到了NMF的框架中,并提出了一种半监督的NMF算法. Zafeiriou等人[14]提出基于Fisher判据NMF算法,以提高算法的判别力.
尽管上述算法均取得了不错的结果,但其本质上仍属线性降维方法,当输入样本的分布具有非线性特征时,例如,当输入数据是嵌入高维空间的低维流形时,线性的降维处理将会引入较大的计算误差.流形学习是一种有效的获取高维数据分布中隐藏的非线性几何结构的降维方法.常见的流形学习算法包括:等距特征映射算法(ISOMAP)[15],局部线性嵌入算法(LLE)[16],拉普拉斯特征图算法(LE)[17]和局部切空间对齐算法(LTSA)[18]等.为了合理利用流形学习和NMF技术各自的优点,Cai等人[19]首次将流形学习思想引入NMF框架,并提出了一种图正则化的NMF算法(GNMF).其试验结果表明,GNMF算法在文本和图像聚类上的性能均有大幅的提高.为了充分利用样本的流形信息,Wang等人[20]随后又提出了一种多图正则化的NMF算法(MultiGNMF).尽管GNMF和MultiGNMF算法可将样本流形结构的先验知识包含进NMF框架,但两者过分强调了局部结构不变性假设在矩阵分解过程中的作用.局部结构不变性假设本质上仅刻画了降维前后近邻样本间的紧凑性关系,但并未考虑非近邻样本间的可分离性关系对降维结果的影响;另外,过分强调样本间的紧凑性关系,必然会导致降维后样本间的可分离性关系发生畸变,从而对最终的降维结果产生不利的影响.
鉴于此,我们提出了一种新的基于几何结构保持的非负矩阵分解算法(SPNMF).不同于GNMF,SPNMF可以在矩阵分解过程中同时保持局部近邻样本间的相似性关系和非近邻样本点的互斥性关系不发生改变,从而能够进一步提高算法的降维性能.
在已存在的文献中,Li[21]等人的方法和本文的工作最为相似,两者均在非负矩阵分解的过程中实现了样本间的结构保持.但两者描述远距离样本点间互斥关系的方法并不相同,由此造成了求解过程及算法复杂度的不同.相对于Li等人[21]的方法,本文提出的算法在矩阵分解过程中,可以更加稳定地保持样本间的非近邻点的互斥关系,求解方法更为简单,算法复杂度也大为降低.
2 相关工作假定存在非负矩阵X=[x1,…,xN],其中,xi∈R+M表示样本集中的第i个样本,NMF的目的是找到两个非负低维子矩阵U∈R+M×K和V∈R+N×K,使它们的乘积能够最佳地逼近原始矩阵X,NMF可公式化的表示为
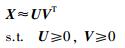
|
(1) |
式中,U表示新形成的子空间的基矩阵,V表示相应的系数矩阵.为了实现对原始矩阵的紧凑性分解,一般要求基矩阵的维数K要远远小于原始样本的维度M和原始样本的个数N.
常见的用于度量NMF近似程度的数据重构函数如式(2) 所示.
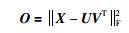
|
(2) |
这里,||·||F为矩阵的Frobenius范数.
由于式(2) 中所示的目标函数对因子矩阵U和V均为非凸的,因此无法得到其全局最优解. Lee等人[15]提出了一种乘式迭代优化算法用于其局部最小值求解,其迭代规则如式(3) 所示.
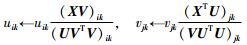
|
(3) |
由式(3),NMF的求解过程中仅包括不同基之间的加法运算;因此,其求解结果必将是一种稀疏的、基于局部的数据表达方式.
3 几何结构保持的非负矩阵分解 3.1 算法提出假设G={X,E}是一个无向图,X表示图中顶点构成的矩阵;E表示相似性矩阵,其元素描述了图G中成对的顶点间的相似性关系.为了刻画样本点间的局部结构信息,我们构建了一个k-近邻图,并定义其权重矩阵W如式(4) 所示.
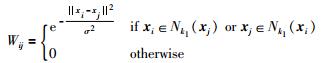
|
(4) |
其中,σ是带宽参数,Nk1(xi) 表示样本xi的k1个近邻集.
根据式(4) 中所定义的权重矩阵,可用式(5) 来度量算法在降维过程中的平滑性.

|
(5) |
式(5) 的取值越小,在原始高维空间中相近的样本点在低维的嵌入子空间的距离也越近.因此,通过最小化ΔL,可以保证在原始高维空间中相邻的样本点在低维的嵌入子空间依然相邻.
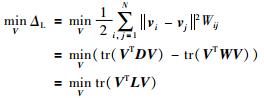
|
(6) |
式中,tr (·) 表示矩阵的迹运算. D和L分别为图G的对角线矩阵和拉普拉斯矩阵,其定义如式(7) 所示:
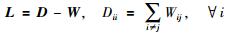
|
(7) |
若假定在原始高维空间中近邻的样本点具有相同的语
义标签,而非近邻的样本具有不同的语义标签.则式(6) 本质上仅反映了无监督条件下数据降维前后同类样本间的紧凑性关系.为了确保降维前后非同类样本间的互斥性关系保持不变,Li等人[21]提出了如式(8) 所示的正则化方法:
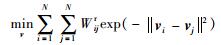
|
(8) |
其中,Wijr=||xi-xj||2,表示非相邻样本xi和xj间的连接权重.对比式(6) 和式(8) 可以发现:两者虽均为取最小值形式,但式(8) 无法转化成矩阵迹的形式,且待求解变量vi以指数的形式存在,这会导致求解过程的复杂化;其次,相对于式(4) 中定义的Wij,Wijr取值范围过大,这使得降维过程的平滑性难以控制.
受Fisher准则的启发,我们重新构造了一个非k近邻图GC={X,EC},并期望其能够反映出不同语义标签样本间的结构化信息;图GC的权重矩阵WC的定义如式(9) 所示.
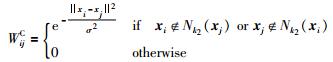
|
(9) |
其中,Nk2(xi) 代表xi的k2个最近邻样本点的集.由式(9) 可见,图GC描述了远距离样本点间的互斥性信息.若假定在原始高维空间中非近邻的数据点在低维的子空间也非近邻,即降维前后,样本点间的互斥性关系保持不变,则可用式(10) 来限定远距离样本点间的这种相互约束关系.
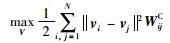
|
(10) |
假定DC和LC分别代表图GC的对角线矩阵和拉普拉斯矩阵,则式(10) 可以重新被写成:
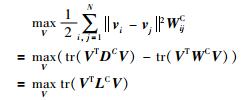
|
(11) |
虽然式(6) 和式(11) 共同完成了样本间的结构化信息的描述,且两者的形式完全统一,但两者的求解目标并不一致.为此,我们引入了互补子空间的概念.
假定存在两个子矩阵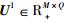
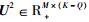
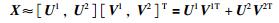
|
(12) |
为使式(6) 和式(11) 的取值方向保持一致,我们用系数矩阵V1来保留式(6) 所示的近邻样本的相似性关系,并用系数矩阵V2来保留式(11) 所示的非近邻样本的互斥关系.因为,基矩阵U1与U的特性相同,则式(6) 可表示为
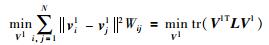
|
(13) |
而基矩阵U2与U的特性互补,则可将式(11) 所示的求最大值的运算转化为式(14) 所示的求最小值的运算.即,
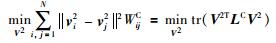
|
(14) |
若把式(13) 和式(14) 引入式(2) 所示的NMF框架,则可确保在进行非负矩阵分解的同时保持数据分布的流形信息,即结构保持的非负矩阵分解(SPNMF). SPNMF算法的目标函数可表示为
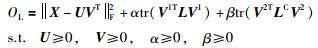
|
(15) |
由式(15) 可见,SPNMF的目标函数分为两个部分,一部分用于流形结构的保持;另一部分则用于计算数据重构的误差,且输入矩阵X可用(U1,V1) 和(U2,V2) 以加运算的方式进行重构.式中α和β为协调参数,用于控制不同的正则项的权重.当β=0时,SPNMF退化成GNMF[19].当α=0并且β=0时,SPNMF退化成NMF[4].
由于式(15) 所示的目标函数对于因子矩阵U和V均为非凸的,直接对式(15) 求全局最优解是不可能的,下面我们将通过迭代算法来求取其局部最小值.
3.2 算法求解假设ψik和ϕik分别为uik≥0和vjk≥0的拉普拉斯乘子,且Ψ=[ψik]和Φ=[ϕik]是相应的拉普拉斯矩阵.则目标函数OL拉普拉斯扩展式L可表示为
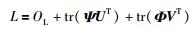
|
(16) |
L关于U以及V1和V2的偏导数如式(17) 所示:
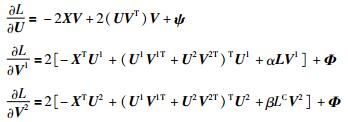
|
(17) |
利用KKT条件ψikuik=0、ϕikvjk1=0和ϕikvjk2=0,可得如下等式:
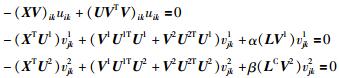
|
(18) |
根据式(18),可得如下关于SPNMF的迭代规则:
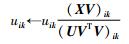
|
(19) |
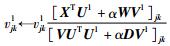
|
(20) |
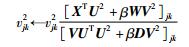
|
(21) |
则,
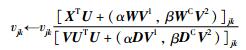
|
(22) |
为了避免尺度迁移问题,我们对U和V进行如下的归一化处理:
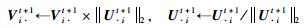
|
(23) |
其中,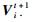
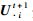
SPNMF完整的求解过程如算法1所示.

|
式(15) 所示的目标函数中,仅第一项与U相关;因此,SPNMF求解算法关于U的收敛性证明与NMF的证明过程相同,更多细节请参考Lee等人[15]的工作.本文中,我们只需给出SPNMF的目标函数在式(22) 所示的迭代规则下是非增的即可.为此,首先证明式(15) 所示的目标函数关于变量V1是非增的.
引理1 如果函数F(v) 存在一个辅助函数G(v,vt),并且满足G(v,vt)≥F(v) 和G(v,v)=F(v),则F(v) 在如下求解规则下是非增的.
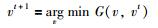
|
(24) |
证明 F(vt+1)≤G(vt+1,vt)≤G(vt,vt)=F(vt).证毕
为了证明目标函数OL在式(24) 所示的迭代规则下是非增的,我们只需构建一个合适的辅助函数Gab(V1,V1t),使其满足Gab(V1,V1t)≥Fab(V1) 和Gab(V1,V1)=Fab(V1) 即可,其中F(V1) 表示OL中仅与V1相关的部分,Fab(V1) 表示F(V1) 的第(a,b) 个元素.
Fab(V1) 的泰勒展开式可表示为
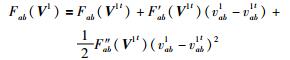
|
(25) |
其中,V1t表示第t次迭代时,矩阵V1的值;F′ab(V1t) 和Fab″(V1t) 为OL关于V1t的一阶和二阶偏导数中的第(a,b) 个元素,分别表示如下:
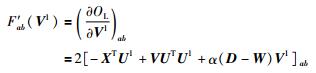
|
(26) |
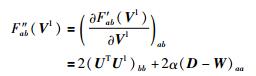
|
(27) |
引理2 函数
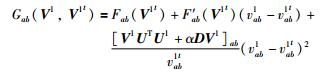
|
(28) |
是函数Fab(V1) 的辅助函数,且其满足Gab(V1,V1t)≥Fab(V1) 和ab.
证明 明显地ab成立,我们只需证明Gab(V1,V1t)≥Fab(V1) 成立即可.为此,我们把函数Gab(V1,V1t) 和Fab(V1) 的泰勒展开式进行了比较.
因为,
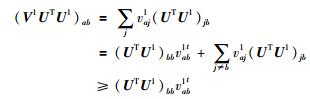
|
(29) |
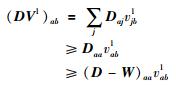
|
(30) |
所以可以推出Gab(V1,V1t)≥Fab(V1).证毕
目标函数关于变量V2的收敛性证明与V1相似,因此忽略此过程.
3.4 计算复杂度分析基于式(20) 和(23) 的迭代规则,我们在表 1中给出了SPNMF计算复杂度的估算结果.由于本文中采用k1近邻和非k2近邻取构建局部近邻图G和非局部近邻图GC,所以,权重矩阵W和WC均为稀疏矩阵,且W和WC中每一行中平均的非零元素的个数为k1和N-k2.因此,我们只需Nk1Q和N(N-k2)Q次浮点的乘加运算来计算WV1和WCV2.
由于SPNMF还需要O(MN2) 次乘加运算去构建局部近邻图G和非局部近邻图GC,因此,以算法进行了t次迭代为例,SPNMF、GNMF和NMF的计算代价分别为O(tMNK+2MN2)、O(tMNK+MN2) 和O(tMNK).可见,SPNMF的计算复杂度基本与GNMF算法相当.
| 浮点加 | 浮点乘 | 浮点除 | 总计 | |
| 更新U(Eq (19)) | 3MNK-M(N+2K) | 3MNK | MK | O(MNK) |
| 更新V(Eq (22)) | 2NK(M-1)+MN(K-1)+NQ(N+k1-k2-2) | 3MNK+NQ(N+k1-k2+2)+K(2mN+M+N) | NK | O(MNK) |
| 归一化U和V | (M-1)N | MN | MK | O(MN) |
| 总计 | O(MNK) | O(MNK) | O((M+N)K) |
本节中,我们在ORL、PIE和FERET三个数据集上进行了聚类试验,以验证所提算法. 3个数据集的统计特性总结如表 2所示.对于算法聚类性能的评估,我们采用精确性(AC) 和归一化互信息(NMI) 指标[19].
| 数据集名称 | #样本数 | #特征维度 | #种类数 |
| ORL | 400 | 1 024 | 40 |
| PIE | 680 | 1 024 | 68 |
| FERET | 420 | 1 024 | 70 |
为了验证SPNMF的性能,我们将其与如下算法的聚类结果进行了比较:
·典型的K均值聚类算法,简记为K-means.
·基于主成分分析的K均值聚类算法,简写为PCA.
·基于非负矩阵分解的K均值聚类算法,简写为NMF.
·基于图正则化的非负矩阵分解的K均值聚类算法,简写为GNMF.
·基于结构不变非负矩阵分解的K均值聚类算法,简写为SPNMF_s[21].
除K-means,其它算法首先通过降维处理建立一个低维的子空间,然后在新的低维空间中进行K均值聚类.
4.1 参数敏感性为了公平地比较本文所涉及算法对参数的敏感性.对每一组参数都进行了20次试验,并记录下其均值和方差.在每次试验中,为避免U和V的初始值对聚类结果的影响,我们均进行了20次K-means聚类试验,并记录下最佳结果.
本文中,我们设所有经过降维处理后的数据的维度r与样本集自身所包含的类数一致.对于SPNMF,补空间和原始空间的维度d均设为r/2.对所有基于图的算法,其k近邻包含的样本的数目分别设为{2,3,…,10}.对于SPNMF和SPNMF_s,非k近邻点所包含的样本的个数设为{10,20,…,50}.对于GNMF,正则项系数α设为{10-3,10-2,…,103}.对于SPNMF和SPNMF_s,α和β的值分别设为{10-3,10-2,…,103},对于SPNMF_s,γ的值设为0.
参数敏感性试验结果如图 1所示.为简化比较流程,本试验中,我们假设α=β.由图 1可见,SPNMF和SPNMF_s的聚类性能和稳定性都要优于GNMF,这显示出非k近邻点的结构不变性假设在反映数据本质的分布形式中具有重要作用.随着正则项系数的增大,GNMF性能开始明显地下降,这说明过分地强调局部结构不变性会导致降维后的数据间结构发生畸变,从而无法准确反映出样本间本质的分布形式;这将导致矩阵分解误差的增大,并影响最终的聚类结果.

|
| 图 1 聚类性能与参数α的关系(ORL) Figure 1 Relationship between clustering performance and parameter α on ORL |
为了比较维度信息对算法性能的影响,在图 2中给出了不同维度下算法的聚类结果的比较.由图 2可见,在各个维度下SPNMF的结果要优于其它算法,这再次证明了几何结构保持对于矩阵分解的重要性.

|
| 图 2 聚类性能与目标维度的关系(ORL) Figure 2 Relationship between clustering performance and target dimension on ORL |
所有算法在不同测试集上的最佳聚类结果如表 3和表 4所示.由表中结果可见,SPNMF和SPNMF_s算法的结果大致相同,但SPNMF算法的性能要略优于SPNMF_s,这一方面是因为SPNMF_s算法中的权重取值范围偏大,造成降维结果的不平滑;另一方面是因为本实验中放松了对基矩阵正则化的约束.另外,SPNMF算法的结果要优于其它算法.其原因是SPNMF为NMF框架引入了更多的样本分布的先验信息,即,除了邻近样本间的紧凑性关系外还考虑了非近邻样本点的互斥关系.由表中结果可见,NMF及其变形算法的性能要优于K-means和PCA算法,这说明了基于局部表达的降维方法要优于基于整体的降维方法.
| 数据集 | accuracy/(%) | |||||
| K-means | PCA | NMF | GNMF | SPNMF_s | SPNMF | |
| FERET | 32.6±1.9 | 32.9±1.6 | 32.6±1.5 | 23.0±0.6 | 34.3±2.1 | 36.1±1.3 |
| ORL | 50.8±2.4 | 54.4±3.1 | 57.4±3.0 | 45.2±2.1 | 62.3±2.4 | 63.1±2.5 |
| PIE | 20.1±1.6 | 19.9±1.7 | 58.3±2.0 | 51.7±1.4 | 69.3±2.3 | 69.3±1.7 |
| 数据集 | normalized mutual information/(%) | |||||
| K-means | PCA | NMF | GNMF | SPNMF_s | SPNMF | |
| FERET | 64.1±1.4 | 64.7±1.4 | 64.3±1.3 | 58.4±0.6 | 65.3±1.4 | 69.3±1.1 |
| ORL | 70.5±1.2 | 73.1±1.9 | 74.9±1.6 | 65.7±1.4 | 78.5±2.0 | 80.3±1.5 |
| PIE | 46.9±1.9 | 47.0±1.8 | 79.3±1.9 | 73.3±1.3 | 86.9±1.8 | 89.1±1.7 |
本节我们主要分析SPNMF的执行效率,即目标函数在式(20) 和式(23) 所示的迭代规则下的收敛速度. 图 3描述了GNMF、SPNMF_s、SPNMF算法在3个数据集上的收敛曲线.对于每个图,y轴表示目标函数的值,x轴表示迭代次数.由收敛曲线可见,SPNMF_s、SPNMF和GNMF算法的收敛速度基本相当,均能在进行500次迭代运算后收敛到一个稳定值. 表 5给出了所有算法在各个数据集上具体的运行时间.其运行环境为:i5-3320M CPU,4 G内存,Windows 7操作系统,Maltab 2012a.由表 5的运行时间结果可以看出,各个算法在不同测试集上的运行时间均在一个可接受的范围内,但SPNMF算法的运行速度要快于SPNMF_s算法.这是因为,在SPNMF_s算法中,式(8) 所描述的非近邻点的互斥性关系无法用矩阵迹的形式进行表示,需借助文[22]的方法才能进行算法的求解,且求解过程中,需要一直迭代更新权重矩阵及图的拉普拉斯矩阵,从而造成运行时间的增加.

|
| 图 3 收敛曲线比较 Figure 3 Convergence curve comparison |
| 数据集 | 运行时间/s | |||||
| K-means | PCA | NMF | GNMF | SPNMF_s | SPNMF | |
| FERET | 1.445 9 | 1.086 10 | 13.647 2 | 6.373 7 | 18.935 6 | 15.233 3 |
| ORL | 0.917 2 | 0.413 18 | 2.210 5 | 3.240 7 | 7.346 2 | 5.452 2 |
| PIE | 2.104 9 | 0.997 89 | 13.427 3 | 15.047 9 | 26.235 1 | 21.090 4 |
本文提出一种新的结构保持的非负矩阵分解算法(SPNMF),此算法在进行子空间学习的同时能够保持数据分布的流形结构.相对于NMF算法,SPNMF算法将近邻样本点间的紧凑性信息和非近邻样本点的互斥性信息引入到了NMF框架.借助数据分布的先验知识,SPNMF使得矩阵的分解过程在指定的流形空间而不是传统的欧氏空间上进行,这将有助于算法聚类性能的提高.最后,SPNMF算法在人脸图像上进行了聚类验证.
| [1] | Song M, Tao D, Chen C, et al. Color-to-gray based on chance of happening preservation[J]. Neurocomputing, 2013, 119 (7): 222–231. |
| [2] | Deng X, Liu X, Song M, et al. LF-EME:Local features with elastic manifold embedding for human action recognition[J]. Neurocomputing, 2013, 99 (1): 144–153. |
| [3] | Cai D, He X, Wu X, et al. Non-negative matrix factorization on manifold[C]//Proceedings of the 8th IEEE International Conference on Data Mining. Piscataway, NJ, USA:IEEE, 2008:63-72. |
| [4] | Lee D D, Seung H S. Algorithms for non-negative matrix factorization[M]//Advances in Neural Information Processing Systems. Breckenridge, USA:MIT, 2001:556-562. |
| [5] | Lee J H, Park S, Ahn C M, et al. Automatic generic document summarization based on non-negative matrix factorization[J]. Information Processing & Management, 2009, 45 (1): 20–34. |
| [6] | Monga V, Mihçak M K. Robust and secure image hashing via non-negative matrix factorizations[J]. IEEE Transactions on Information Forensics and Security, 2007, 2 (3): 376–390. DOI:10.1109/TIFS.2007.902670 |
| [7] | Bucak S S, Gunsel B. Online video scene clustering by competitive incremental NMF[J]. Signal, Image and Video Processing, 2013, 7 (4): 723–739. DOI:10.1007/s11760-011-0264-2 |
| [8] | Lee D D, Seung H S. Learning the parts of objects by nonnegative matrix factorization[J]. Nature, 1999, 401 (1): 788–791. |
| [9] | Palmer S E. Hierarchical structure in perceptual representation[J]. Cognitive Psychology, 1977, 9 (4): 441–474. DOI:10.1016/0010-0285(77)90016-0 |
| [10] | Liu H, Wu Z, Li X, et al. Constrained nonnegative matrix factorization for image representation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34 (7): 1299–1311. DOI:10.1109/TPAMI.2011.217 |
| [11] | Ding C, Li T, Jordan M. Convex and semi-nonnegative matrix factorizations[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32 (1): 45–55. DOI:10.1109/TPAMI.2008.277 |
| [12] | 贾旭, 崔建江, 孙福明, 等. 基于改进非负矩阵分解的手背静脉识别算法[J]. 信息与控制, 2016, 45 (2): 193–198. Jia X, Cui J J, Sun F M, et al. Porsal hand vein recognition algorithm based on improved nonnegative matrix factorization[J]. Information and Control, 2016, 45 (2): 193–198. |
| [13] | Liu H, Wu Z, Li X, et al. Constrained nonnegative matrix factorization for image representation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34 (7): 1299–1311. DOI:10.1109/TPAMI.2011.217 |
| [14] | Zafeiriou S, Tefas A, Buciu I, et al. Exploiting discriminate information in nonnegative matrix factorization with application to frontal face verification[J]. IEEE Transactions on Neural Networks, 2006, 17 (3): 683–695. DOI:10.1109/TNN.2006.873291 |
| [15] | Tenenbaum J B, De Silva V, Langford J C. A global geometric framework for nonlinear dimensionality reduction[J]. Science, 2000, 290 (5500): 2319–2323. DOI:10.1126/science.290.5500.2319 |
| [16] | Roweis S T, Saul L K. Nonlinear dimensionality reduction by locally linear embedding[J]. Science, 2000, 290 (5500): 2323–2326. DOI:10.1126/science.290.5500.2323 |
| [17] | Belkin M, Niyogi P. Laplacian eigenmaps for dimensionality reduction and data representation[J]. Neural computation, 2003, 15 (6): 1373–1396. DOI:10.1162/089976603321780317 |
| [18] | Zhang Z, Zha H. Principal manifolds and nonlinear dimensionality reduction via tangent space alignment[J]. Journal of Shanghai University:English Edition, 2004, 8 (4): 406–424. DOI:10.1007/s11741-004-0051-1 |
| [19] | Cai D, He X, Han J, et al. Graph regularized nonnegative matrix factorization for data representation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33 (8): 1548–1560. DOI:10.1109/TPAMI.2010.231 |
| [20] | Wang J J Y, Bensmail H, Gao X. Multiple graph regularized nonnegative matrix factorization[J]. Pattern Recognition, 2013, 46 (10): 2840–2847. DOI:10.1016/j.patcog.2013.03.007 |
| [21] | Li Z, Liu J, Lu H. Structure preserving non-negative matrix factorization for dimensionality reduction[J]. Computer Vision & Image Understanding, 2013, 117 (9): 1175–1189. |
| [22] | Carreira-Perpinan M A. The elastic embedding algorithm for dimensionality reduction[C]//Proceedings of the 27th International Conference on Machine Learning. Piscataway, NJ, USA:IEEE, 2010:167-174. |