



1 引言
复杂网络在现实世界中广泛存在,网络中的个体成员之间按照某种自然规则形成关联.复杂网络中的节点具有模块性,即同类型节点之间联系紧密,不同类型的节点间联系稀疏,呈现一定的社区结构[1].大量实证研究表明,很多网络的社区之间并不是完全彼此分离的,通常会存在某些归属于多个社区的节点,如社会网络上参与不同群组的用户、生命系统中具有多种功能的蛋白质分子、计算机网络中的路由节点、电力系统中的变电站等等.重叠网络社区发现[2]旨在挖掘网络中的“重叠”社区结构,解释重叠节点在网络和社区中发挥的作用.
重叠社区发掘自提出以后,相关研究得到广泛的关注,取得了大量成果.目前的重叠社区发现算法大致可分为智能优化算法、凝聚方法和分裂方法等三类.智能优化方法主要包括聚类方法和优化方法.边图划分[3-5]将社区视为关系密切边的集合,定义边的相似度函数,对边集进行聚类,再将边划分结果转化为相应的节点社区.由于一个点的不同边可能被划分到不同社区,因此实现了节点的复制;Zhang等[6]用模糊集对节点进行聚类,并用改进的模块度函数对重叠社区进行评价;文[7]通过2阶段聚类实现重叠社区的发现.聚类算法的缺陷在于容易出现过度重叠和社区冗余问题,相似性指标的设计也是一个困扰研究者的问题.优化方法预先定义全局目标函数,以达到或接近目标函数最大值来获得重叠社区. Shen等[8]则基于最大覆盖思想计算节点在社区中的隶属度,定义了的重叠
社区模块度函数Qov;Nicosia[9]在模块度Q函数的基础上,引入节点和社区的归属系数,定义了有向图中重叠社区评价的扩展模块度函数并研究了用遗传算法求解重叠社区方案;文[10]结合谱图理论和粗糙集理论,通过优化重叠社区模块度函数来发掘网络中的重叠社区;Ball等[11]用统计学模型模拟网络构成,并运用期望最大化 (EM) 算法对其进行优化求解.优化方法的主要问题在于容易产生局部最优解.
凝聚方法从网络的局部结构入手,不断扩充社区结构,社区间形成自然的重叠.文[12]通过谱划分找到社区种子集合,再采用随机行走的技术对社区进行扩展,且在每步中加入Q函数进行评价;Lancichinetti等[13]认为社区最多只包括社区节点和邻居节点,通过建立评价邻居节点的适应度函数,逐步扩张社区;文[14]以极大度节点的团作为种子社区,采用粗糙集对社区邻域进行描述,用社区稳定性函数作为邻居节点扩张与否的度量;Lee等[15]基于k派系扩张提出了一种重叠社区挖掘算法,由于节点可能属于多个k派系,从而能够找到重叠社区;文[16]基于传统标签传播思想,提出基于边标签传播的重叠社区识别方法;文[17]提出了基于重要节点扩展的重叠社区识别算法,根据网络拓扑信息选择重要节点,计算其它节点归属于重要节点的节点归属度,并以Q函数对重要节点进行调整,迭代实现网络的重叠社区识别.凝聚方法的计算过程无需加载整个网络,计算效率有所提高,但结果受初始社区的影响很大.
分裂方法通过节点复制来挖掘重叠社区.文[18]迭代选择具有最大边介数的链接,根据一定评价标准对边进行切割或对边的关联点复制;文[19]用结构相似度取代边介数,社区间链接的结构相似度应小于社区内链接的结构相似度,在算法的每次迭代中具有最小结构相似度的边被删除;CONGA (cluster-overlap Newman Girvan algorithm)[20]引入局部介数的概念,通过分裂有最高节点介数的节点,对传统的边介数分裂GN算法 (Girvan and Newman′s algorithm) 算法进行扩展,支持重叠社区的发现;Peacock算法[21]利用非重叠社区发现算法划分重叠社区,算法分为2个阶段:通过分裂节点介数将网络转化为一个新的网络,再将任意一种非重叠社区发现算法用于新网络.目前分裂算法的主要问题是复杂度高,需要逐步计算边介数/局部介数/结构相似度来确定待分割的边或复制节点.
从实用性角度出发,理想的重叠社区发现方法应具备低时间复杂度且无需领域 (专家) 知识的特征.本文提出一种基于节点最优复制的重叠社区发现算法OCDNOD (Overlapping Community Detection algorithm based on Node Optimized Duplication).首先根据局部网络信息计算链接的关联度,对网络节点进行最优复制,并计算节点复制关联度;逐步分割最低关联度链接直到获得需要的社区数.本文的主要贡献在于:
(1) 定义了一种反映网络链接疏密及节点内部凝聚程度的度量方法.
(2) 基于节点最优复制,提出分割策略的重叠社区发现算法OCDNOD.算法无需领域知识,避免了分割算法中常见的必须逐步计算相关度量并确定分割链接的问题,极大地提高了算法效率.
2 基于最优节点复制的重叠社区发现算法 2.1 基本概念与特征复杂网络都可以抽象成图来描述,图中的节点表示复杂网络中的个体,而边 (或链接) 表示个体之间的关系,本文研究的是无权无向简单图.图由二元组G=〈V,E〉表示,其中vi∈V表示网络中的节点,|V|=N是网络的节点总数;边eij=〈vi,vj〉∈E表示节点vi、vj之间存在链接〈vi,vj〉,|E|=M是网络的链接总数,通常M≫N.令矩阵A表示图G的邻接矩阵,记为A=(aij)N×N.如果存在eij∈E,则aij=1;否则aij=0.
定义1链接关联度[22] 关联度反映直接链接的网络节点之间,通过多边形加强彼此关联的程度,是网络节点之间的直接链接与多边形链接数之和与度较小节点的度之比:
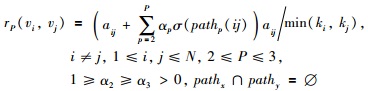
|
(1) |
其中,vi,vj∈V是网络节点,aij是它们的邻接项,kvi、kvj分别是它们的度;αp是多边形环路对关联度的效果参数,σ(pathp(ij)) 是vi、vj之间距离为p的路径数,这些路径之间没有任何相同的链接和节点;显然0≤rp(vi,vj)≤1,如果rP(vi,vj)=0,两个节点之间没有直接链接.对于网络节点vi∈V,如果rP(vi,vj)=1(∀j,aij=1),则称节点vi是网络中的一个完全子图节点.
定义2节点关联度 对给定的节点vi,节点vi的关联度定义为
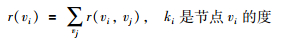
|
(2) |
从信息流的角度来说,链接关联度反映了两端节点的互通程度,具有较高关联度值的两个节点之间的信息流通更为通畅 (从度小的节点流向度大的节点);从网络结构的角度来看,链接关联度反映的是两个相邻节点的支持/依赖程度,具有较高关联度的两个节点之间结构更为紧密 (度小的节点依赖于度大的节点).节点关联度则反映所有邻居节点对特定节点的支持/依赖联系.
与链接关联度和节点关联度类似,边聚集系数和点聚集系数同样使用附近的三边形或多边形来反映链接和节点的局部微结构.但边聚集系数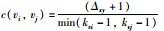
定义3节点复制 对于网络节点vi∈V,vi′、vi″(vi′∉V,vi″∉V) 称为vi的复制节点. ei′i″=〈vi′,vi″〉是复制节点之间的连接,如果ai′i″=1,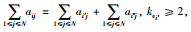
性质1 对于网络节点vi∈V,vi′、vi″是vi的复制节点,则ki+2=ki′+ki″.
证明 性质1是显然的.
定义4有效的节点复制 对于网络节点vi∈V,vi′、vi″是vi的复制节点. 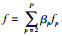
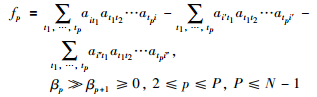
|
(3) |
如果f≥0则称节点复制是有效的.
定义5节点复制关联度 复制节点关联度是网络中的原节点复制后,两个复制节点间链接的关联度:
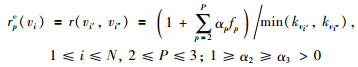
|
(4) |
定义6最优复制 对于网络节点vi∈V,vi′、vi″是vi的有效复制节点,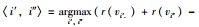
直观上而言,
图 1是网络中节点的几种复制情况. 图 1(a)是原始网络,图 1(b)对节点1进行复制,由于复制后节点1″的度不满足节点复制要求,因此被视为非节点复制;图 1(c)对节点1进行复制,复制后以节点1′、1″为顶点的三角形减少一个,以节点1′、1″为顶点的四边形增加一个,复制后r(v1′.)+r(v1″)-2r(v1′,v1″)=4.833;图 1(d)对节点1进行复制,复制后以节点1′、1″为顶点的三角形减少一个,以节点1′、1″为顶点的四边形增加一个,但r(v1′.)+r(v1″)-2r(v1′,v1″)=5.因此图 1(c)是有效但非最优复制,图 1(d)是最优复制.

|
| 图 1 网络节点的各种复制 Figure 1 Duplication of the network node |
从信息流的角度来说,节点关联度反映被复制节点内部信息流动混杂情况.对于具有较高节点复制关联度值的节点,其内部信息的流通更为混杂,难以明确区分;具有低节点复制关联度值的节点,内部信息流动泾渭分明,更易于分割;从结构力学的角度来看,节点复制关联度反映了被复制节点的内部凝聚程度,具有较高节点复制关联度值的节点内部结构更为紧凑和混杂.
在含有比较大的比例的三角形的复杂网络中 (平均聚集系数>0.1),可以只考虑直接链接和三角形链接对链接关联度和节点复制关联度的影响,用r2(vi,vj) 和r2c(vi) 足以描述链接关联度和节点复制关联度;在更稀疏的网络中,需要考虑直接链接、三角形链接、四边形链接对关联度影响,用r3(vi,vj) 和r3c(vi) 来描述链接关联度和节点复制关联度.为简化起见,通常当P=2时,取α2=1;P=3时,取α2=α3=1.
定义7孤立结构 对于网络G=〈V,E〉,C={c1,…,ct}(ci∩cj=∅,ci是连通的,1≤i,j≤t,i≠j) 是网络的一个划分,如果1 < |Ci| < n0(n0称为社区节点数阈值),则称Ci是孤立结构.如果|Ci|=1,则称Ci是孤立点.
按照关联度对网络进行重叠社区划分,社区之间的链接关联度值和复制节点的节点关联度值均较低,否则无法保证社区内部连接密集、社区之间连接稀疏.
性质2 关联度具有以下特征:(1) r2(vi,vj)≤r3(vi,vj);(2) 对于节点vi∈V,如果kvi={1,2,3},最优重叠社区划分方案下,vi必定不是复制节点.
证明 从链接关联度定义和最优节点复制定义直接得证.
性质3 连通网络在最优节点复制下的重叠社区划分,社区间链接eij的关联度
证明 不失一般性,假设划分为2个不含任何孤立点的社区.对社区之间的任意链接eij,考虑度小的节点vi.
(1) 如果kvi=1,必然分割出含孤立节点vi的社区,与假设矛盾.
(2) 如果kvi=2,则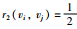
(3) 如果kvi≥3,假设两个社区是ca和cb,vi、vj分别位于ca和cb;x类型的节点 (节点位于社区ca并与vi、vj构成三角形) 为s1个,y类型的节点 (节点位于社区cb并与vi,vj构成三角形) 为s2个,社区情况见图 2(a).

|
| 图 2 社区边缘节点 Figure 2 Fringe node of the community |
● 如果s1=0且s2=0,则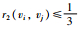
● 如果s1≥1,复制vj,则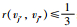
综合 (1)、(2)、(3),得证.
2.2 最优节点复制的重叠社区发现算法重叠社区发现算法首先计算所有链接的关联度,根据性质2对部分节点最优复制并计算节点复制关联度.将所有关联度逆序排列,逐步删除关联度最低的链接或复制节点之间的链接,直到找到需要的社区数和社区节点集.
算法1 初始社区的生成
1) 输入网络图链接数组L,期望的社区数k0,社区节点数阈值n0,链接集合E1,初始社区k=0.
2) 计算网络的节点数n和链接数m.
3) 计算各个节点的度.
4) 计算每个链接的关联度.
5) 对节点进行最优复制,计算节点复制关联度.
6) 对所有关联度值,按照高低排序.
7) 如果k=k0,转11),否则转8).
8) 选择关联度最低的链接或复制链接,从L中删除,将被删除的链接置入E1.
9) 计算各个连通结构的节点数,如果节点数 < n0,连通结构为孤立结构或孤立点,否则视为社区.
10) 计算网络中的社区数,转7).
11) 输出链接数组L,点集合V1,链接集合E1,初始社区集{Ci}和孤立结构/孤立点集{Sj}.
算法2 孤立结构/孤立点的合并
1) 输入链接数组L,链接集合E1,初始社区集{Ci}和孤立结构/孤立点集{Sj}.
2) 如果{Sj}为空,转6);否则从E1找出关联度值最大的链接,将该链接从E1中删除并置入L.
3) 如果该链接是孤立结构或初始社区内部链接,转2);否则转4).
4) 如果该链接联系的是两个孤立结构/孤立点,对它们进行合并,转2);否则转5).
5) 如果该链接联系的是一个孤立结构/孤立点和一个初始社区,将孤立结构/孤立点从{Sj}删除,并将它合并到初始社区中.
6) 如果该链接是初始社区之间链接,将该链接从L中删除,转2).
7) 合并每个社区内部的复制节点.
8) 输出所有的社区节点结构.
在本算法中,以邻接表存储网络,以数组存储链接、链接/节点关联度和各个节点的度.在算法1中,步骤2)、3)、7)、8)、9) 的时间复杂度为O(m),如果以r2计算关联度,步骤4) 的时间复杂度为O(k2m)(如果以r3计算关联度,则时间复杂度为O(k3m)),步骤5) 的时间复杂度为O(k2m),步骤6) 的时间复杂度为O(mln m),k是节点平均度.在算法2中,步骤2)、3)、4)、5)、6) 的时间复杂度为O(m),步骤7) 的时间复杂度为O(n).所以整个算法的时间复杂度为O(mln m+k2m)(最差为O(mln m+k3m)).此外,性质1~性质3可用于有效提高算法效率. 表 1是本文算法与几种代表性的重叠社区挖掘算法的时间复杂度比较.从表 1可以看到,本文算法效率相对其它重叠社区发现算法有极大的提高.
本文采用几个真实网络和基准网络对算法进行社区挖掘正确性评估和运行性能评价.不同算法的结果用文[13]定义的重叠社区NMI (normalized mutual information) 进行比较.本文算法在Win 7平台上采用Matlab R2012a进行开发,运行环境为Intel 2.1 GHz Processor,4 GB RAM.为简化起见,本文所有实验用r2(vi,vj) 和r2c(vi) 以描述链接关联度和节点复制关联度.
3.1 正确性评估Karate网络[23]是复杂网络社区挖掘研究中的典型分析对象,网络节点代表了俱乐部成员,边代表了俱乐部成员之间的朋友关系.由于争执,整个俱乐部分裂为两个各有16和18个成员的小社区.整个网络包含34个节点、76条边,聚集系数为0.588. 图 3(a)是本文算法的重叠社区划分结果,参数k0=2(期望的社区数),n0=6(社区节点数阈值);图 3(b)是含节点{2}社区的进一步重叠社区最优划分.从图 3(a)中可以看到,对节点{3,9,34}进行最优复制后,重叠社区划分下两社区之间的链接是5条,NMI=0.783 1.从图 3(b)中可以看到,在对节点1进行复制后,含节点{2}的社区可以进一步分离.

|
| 图 3 Karate网络的重叠社区划分 Figure 3 Overlapping community detection of the Karate network |
Dolphins网络[24]是一个宽吻海豚群体的社会关系网,网络中每个节点代表一个海豚,边表示两个海豚之间有频繁的接触.网络中共有62个节点、159条边,聚集系数为0.303.整个网络包括一个含20个海豚的较小社区和一个含42只海豚的较大社区. 图 4(a)是本文算法的重叠社区划分结果,参数k0=2(期望的社区数),n0=6(社区节点数阈值);图 4(b)是含节点{2}社区的进一步重叠社区划分结果,参数k0=2(期望的社区数),n0=6(社区节点数阈值).从图 4(a)可以看到,重叠社区划分下两个社区之间有4条链接,NMI=0.887 5;从图 4(b)可以看到,对于含节点{58}的社区,如果对节点{18,42,55,58}进行最优复制,社区可以进一步进行重叠划分,此时两个社区间有4条链接.

|
| 图 4 Dolphins网络的重叠社区最优划分 Figure 4 Overlapping community detection of the Dolphins network |
Yeast网络[25]是一个有2 361个节点、7 182条边的蛋白质交互网络,平均聚集系数为0.2,网络包括13个真实社区.本文将其视为无向无权网络,当用本文算法对网络进行重叠社区划分时,有37个重叠节点,NMI=0.753 8. 表 2是3种真实网络本文算法与其它算法的重叠社区划分效果比较.
从表 2的结果可以看到,本文算法在3种网络的重叠社区评价结果最好,这是因为本文算法的重叠节点数最少;CONGA算法和SSNCA算法次之,这是因为这两种算法都尽量减少节点的复制;GCE算法和LFM算法最低,这是由于这两类算法都会导致较大数量的节点复制.
本文利用Lancichinetti和Fortunato提出的LFR基准网络[26],生成人工网络来进一步测试不同网络节点平均度下本文算法与其它重叠社区挖掘算法的划分精度.设置节点个数为128,社区最小最大规模分别为20、50,网络节点最大度为30,网络节点平均度分别为15,社区间重叠参数μ分别为{0.10,0.175,0.25,0.325,0.40,0.475,0.55,0.625},网络节点度分布指数为2,网络社区规模分布指数为1.重复生成10个网络,共80个网络.
图 5是本文算法与几种典型重叠社区发现算法的精度比较.从图 5可以看到,各种算法的社区发现精度都随重叠参数μ的增大而降低,这是因为随着μ的增加,社区之间的边界越来越模糊,可能的重叠节点越来越多.当μ≤0.40时,除LFM算法外,其它几种算法的精确度都很高,NMI值均在0.8以上;当μ≥0.4时,各种算法的精确度开始迅速下降;当μ>0.475时,几种算法的NMI值差异开始显得非常明显.从图 5可以看到,LFM算法精度最低,GCE算法、LFM算法精度有所提高,这是因为这两类算法在重叠社区的发掘过程中会导致较大量的节点复制;CONGA算法和SSNCA算法精度较好,这是因为这两种算法都尽量减少节点的复制;本文算法的在几种算法中精度最高,这是因为重叠社区最优节点复制,重叠节点数最少.由于有大量的重叠节点,导致不同的参数下的社区挖掘结果NMI精度远比独立社区挖掘结果低.

|
| 图 5 算法运行时间比较 Figure 5 Running time comparison among the algorithms |
本文采用PGP网络[27]对算法在实际网络上的运行效率进行评估,网络具有10 680个节点,24 340条边,网络平均度为4.554,聚集系数为0.44,平均路径长度为7.48. 图 6的直方图是网络在几种算法下的不同运行时间.

|
| 图 6 PGP网络上的算法运行效率比较 Figure 6 Efficiency comparison among the algorithms on PGP network |
从图 6中可以看到,当网络有较大规模时,几种算法的运行效率差异极大,OCDNDO的运算时间约为1 316 s,CONGA、SSNCA和LFM的运行时间分别为OCDNDO算法运算时间的11.5、10.6和5.7倍,GCE算法由于运算规模过于庞大,在本文实验机器上未能完成,无法给出所需的运算时间.
为进一步评估算法的运行效率,本文利用LFR基准网络[23]作为数据生成器,生成无权无向图数据.设置节点个数为分别为500、1 000、2 000、3 000、4 000、5 000,社区最小最大规模分别为20、50,网络节点最大度为30,网络节点平均度分别为15,社区间重叠参数μ=0.10,网络节点度分布指数为2,网络社区规模分布指数为1.重复生成10个网络,共60个网络.
图 7是本文算法与几种典型重叠社区发现算法的运行效率比较.从图 7可以看到,几种算法的运行时间均随节点数增长而急剧增长;在各种节点数情况下,本文算法均远低于其它算法,具有最好的运行效率.这是因为关联度的计算只需处理网络的局部信息,远比社区迭代扩张、网络中派系的搜索、(局部) 介数的计算简单.在不同节点数情况下,LFM、SSNCA、CONGA三种算法中,LFM算法最好,SSNCA次之,CONGA算法最低;GCE算法的运行时间随节点数增长最快,当节点数为500时,其运行时高于本文算法,但低于LFM、SSNCA、CONGA,但当节点数为1 000时,GCE算法的运行时间已经与LFM算法基本持平,节点数为3 000点时,GCE算法的运行时间高于LFM、SSNCA,当节点数为5 000时,GCE算法的运行时间已经远高于其它4种算法.

|
| 图 7 算法运行效率比较 Figure 7 Efficiency comparison among the algorithms |
本文基于节点的局部邻居信息,提出衡量节点之间的依赖/支持程度和信息流通程度的链接关联度,并提出最优节点复制以分割凝聚程度低的节点,提出了重叠社区发现算法——OCDNOD.算法只对社区边缘的节点进行最优复制,具有低时间复杂度、支持重叠社区发现、无需领域或专家知识的特点,实验结果验证了算法的有效性和可行性.未来的重点是研究基于关联度的社区挖掘评价标准和社区挖掘并行算法.
| [1] | Girvan M, Newman M E J. Community structure in social and biological networks[J]. Proceedings of the National Academy of Sciences, 2002, 99(12): 7821–7826. DOI:10.1073/pnas.122653799 |
| [2] | Palla G, Derenyi I, Farkas I, et al. Uncovering the overlapping community structures of complex networks in nature and society[J]. Nature, 2005, 435(7043): 814–818. DOI:10.1038/nature03607 |
| [3] | Shen H W, Chen X Q, Cai K, et al. Detect overlapping and hierarchical community structure in networks[J]. Physical A:Statistical Mechanics and Its Applications, 2009, 388(8): 1706–1712. DOI:10.1016/j.physa.2008.12.021 |
| [4] | Ahn E, Bagrow J P, Lehmann S. Link communities reveal multi-scale complexity in networks[J]. Nature, 2010, 466(7307): 761–764. DOI:10.1038/nature09182 |
| [5] | 朱牧, 孟凡荣, 周勇. 基于链接密度聚类的重叠社区发现[J]. 计算机研究与发展, 2013, 50(12): 2520–2530. Zhu M, Meng F R, Zhou Y. Density-based link clustering algorithm for overlapping community detection[J]. Journal of Computer Research and Development, 2013, 50(12): 2520–2530. DOI:10.7544/issn1000-1239.2013.20130944 |
| [6] | Zhang S H, Wang R S, Zhang X S. Identification of overlapping community structure in complex networks using fuzzy C-means clustering[J]. Physical A:Staticstical Mechanics and Its Applications, 2007, 374(1): 483–490. DOI:10.1016/j.physa.2006.07.023 |
| [7] | 蒋盛益, 杨博泓, 李敏敏, 等. 基于二阶段聚类的重叠社区发现算法[J]. 模式识别与人工智能, 2015, 28(11): 983–991. Jiang S Y, Yang B H, Li M M, et al. Overlapping community detection algorithm based on two-stage clustering[J]. Pattern Recognition and Artificial Intelligence, 2015, 28(11): 983–991. |
| [8] | Shen H W, Cheng X Q, Guo J F. Quantifying and identifying the overlapping community structure in networks[J]. Journal of Statistical Mechanics:Theory and Experiment, 2009(7): 07042. |
| [9] | Nicosia V, Mangioni G, Carchiolo V, et al. Extending the definition of modularity to directed graphs with overlapping communities[J]. Journal of Statistical Mechanics, 2009(3): 3166–3168. |
| [10] | 黄发良, 肖南峰. 用于网络重叠社区发现的粗糙谱聚类算法[J]. 小型微型计算机系统, 2012, 33(2): 263–266. Huang F L, Xiao N F. Rough spectral clustering algorithm applied to overlapping network communities discovery[J]. Journal of Chinese Computer Systems, 2012, 33(2): 263–266. |
| [11] | Ball B, Karrer B, Newman M E J. An efficient and principled method for detecting communities in networks[J]. Physical Review E:Statistical Nonlinear & Soft Matter Physics, 2011, 84(32): 109–134. |
| [12] | Wei F, Qian W N, Wang C, et al. Detecting overlapping community structures in networks[J]. World Wide Web, 2009, 12(2): 235–261. DOI:10.1007/s11280-009-0060-x |
| [13] | Lancichinetti A, Fortunato S, Kertesz J. Detecting the overlapping and hierarchical community structures in complex networks[J]. New Journal of Physics, 2008, 11(15): 19–44. |
| [14] | 张泽华, 苗夺谦, 钱进. 邻域粗糙化的启发式重叠社区扩张方法[J]. 计算机学报, 2013, 36(10): 2078–2086. Zhang Z H, Miao D Q, Qian J. Detecting overlapping communities with heuristic expansion method based on rough neighborhood[J]. Chinese Journal of Computers, 2013, 36(10): 2078–2086. |
| [15] | Lee C, Reld F, McDald A, et al. Detecting highly overlapping community structure by greedy clique expansion[C]//Proceedings of the 4th International Workshop on Social Network Mining and Analysis (SNN-KDD'10). New York, NJ, USA:ACM, 2010:33-42. |
| [16] | 张健沛, 邓琨, 杨静, 等. 基于边标签传播的复杂网络社区识别方法[J]. 电子学报, 2015, 43(6): 1113–1118. Zhang J P, Deng K, Yang J, et al. Community detection in complex networks based on link label propagation[J]. Acta Electronica Sinica, 2015, 43(6): 1113–1118. |
| [17] | Zhang H Y, Chen X W, Li J, et al. Fuzzy community detection via modularity guided membership-degree propagation[J]. Pattern Recognition Letters, 2016, 70(15): 66–72. |
| [18] | John W P, David R W. Betweenness-based decomposition methods for social and biological networks[M]. Leeds, UK: Leeds University Press, 2007. |
| [19] | 金弟, 刘杰, 贾正雪, 等. 基于k最近邻网络的数据聚类算法[J]. 模式识别与人工智能, 2010, 23(4): 546–551. Jin D, Liu J, Jia J X, et al. Study on k-nearest-neighbor network for data clustering algorithm[J]. Pattern Recognition and Artificial Intelligence, 2010, 23(4): 546–551. |
| [20] | Gregory S. An algorithm to find overlapping community structure in networks[C]//Proceedings of the 11th European Conference on Principles and Practice of Knowledge Discovery in Databases. Berlin, Germany:Springer, 2007:91-102. |
| [21] | Gregory S. Finding overlapping communities using disjoint community detection algorithms[C]//Proceedings of the International Workshop on Complex Networks. Berlin, Germany:Springer-Verlag, 2009:47-61. |
| [22] | 龙浩, 汪浩. 复杂社会网络的两阶段社区发现算法[J]. 小型微型计算机系统, 2016, 37(4): 694–698. Long H, Wang H. A two-stage community detection algorithm in social network[J]. Journal of Chinese Mini-Micro Computer Systems, 2016, 37(4): 694–698. |
| [23] | Zachary W W. An information flow model for conflict and fission in small groups[J]. Journal of Anthropological Research, 1977, 33(4): 452–473. DOI:10.1086/jar.33.4.3629752 |
| [24] | Lusseau D, Schneider K, Biosseau O J, et al. The bottlenose dolphin community of doubtful sound features a large proportion of long-lasting associations[J]. Behavioral Ecology and Sociabiology, 2003, 54(4): 396–405. DOI:10.1007/s00265-003-0651-y |
| [25] | Vladimir B, Andrej M. Pajek datasets[DB/OL]. (2003-06-25)[2016-02-21]. http://vlado.fmf.uni-lj.si/pub/networks/data/bio/Yeast/Yeast.htm. |
| [26] | Boguñá M, Pastor-Satorras R, Díaz-Guilera A, et al. Models of social networks based on social distance attachment[J]. Physical Review E:Statistical Nonlinear & Soft Matter Physics, 2004, 70(52): 148–168. |
| [27] | Lancichinetti A, Fortunato S. Benchmarks for testing community detection algorithms on directed and weighted graphs with overlapping communities[J]. Physical Review E:Statistical Nonlinear & Soft Matter Physics, 2009, 80(12): 145–148. |