



2. 陕西省教学信息技术工程实验室, 陕西 西安 710119
2. Engineering Labortory of Teaching Information Technology of Shaanxi Province, Xi'an 710119, China
1 引言
近年来,从运动图像中恢复非刚体的三维结构是计算机视觉研究的难点和热点[1-2].在没有任何先验知识的情况下,只能实现物体的射影重建[3-4],而不能实现物体的欧氏重建.但射影重建是欧氏重建的前提和基础,它将影响最终的重建效果[5].
由于刚体运动简单,因此早期的三维重建研究对象都是基于刚体运动[6-7].经过二十多年的发展,基于刚体的重建研究已经趋于成熟[8-9].然而现实生活中大部分运动具有柔性,属于非刚体运动.非刚体在运动过程中,结构会发生变化,其运动比刚体要复杂,因此重建的难度将更大.为了重建三维非刚体,Bregler等提出非刚体可以由若干个刚性形状基(shape basis)线性加权组成的假设[10],但是该方法求解过程非常繁琐,后来Gotardo证明该重建是病态不定问题[11].为了把病态不定问题变为良态可解问题,一方面需要减少求解的未知数,另一方面需要寻求更多的约束条件.为了减少求解的未知数,有些学者利用已标定的相机进行非刚体重建[12-14],但是标定后的相机不能调焦.为了增加约束条件,Garg和Isack等利用非刚体表面光滑性的约束,构造能量函数,但是运算量大,设置参数较多,并且该方法没有考虑到物体运动的关联性[15-16].现实生活中,非刚体的运动在时间上具有连续性,即前后时刻非刚体的运动具有相似性.Akhtert等利用这一特点,提出基于轨迹基的重建方法[17],并认为所有特征点在一个低维子空间中运动,但Akhtert方法基于正投影模型,当物体景深与相机到物体距离相比不能忽略时,正投影模型误差较大.
本文假设相机为透视投影模型,其成像过程更加符合实际情况,因此,重建的精度将更高.本文利用非刚体的轨迹生成一个低维子空间且该低维子空间的基底能够事先定义的特点,提出了基于轨迹基的3维非刚体射影重建方法,由于基底能够事先定义,因此减少了求解的未知数的数量,提高了算法的鲁棒性.同时,利用图像矩阵的行向量和列向量生成一个低维子空间的性质,对深度因子求解,实现射影重建.由于在求解深度因子时,同时利用了图像矩阵的行向量和列向量的约束,提高了重建精度.
2 成像模型假设摄像机为透视投影模型,有F帧图像,P个空间点,则第i帧图像第j个空间点的成像过程可表示为
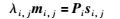
|
(1) |
式中,mi,j=[hi,j,gi,j,1]T和si,j=[Xi,j,Yi,j,Zi,j,1]T分别为已知图像点及三维空间点的齐次坐标,λi,j为深度因子,Pi为3×4的投影矩阵,i=1,…,F,j=1,…,P.
若将所有的图像点表示成一个大矩阵M3F×P,则式(1)可表示为
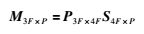
|
(2) |
式中,
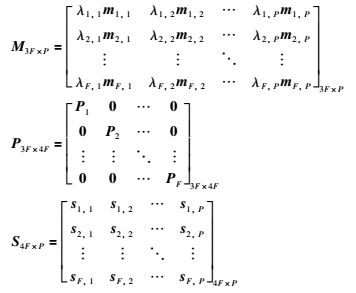
|
由于非刚体的运动具有连续性,因此物体上每点的运动不是任意的,其前后时刻运动具有相关性,可以认为非刚体上各点的运动轨迹生成一个低维子空间.假设该低维子空间的基元数为r,{σ1 σ2 … σr}为该子空间的一个标准正交基,那么第j个空间点的轨迹可表示为
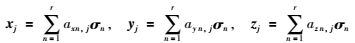
|
(3) |
式中,σn=[σ1,n σ2,n … σF,n]T为迹基向量,xj、yj和zj分别是空间点j的运动轨迹在x、y和z轴上的分量,axn,j、ayn,j、azn,j为系数.
若将所有的空间点放在一起,由式(3)可得
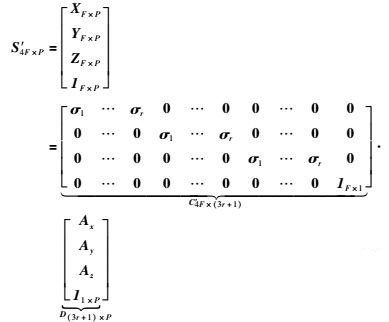
|
(4) |
式中,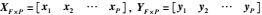
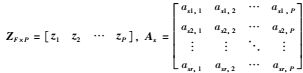

若对矩阵S4F×P′的行进行调整,只需对C4F×(3r+1)′相应的行进行调整,而D(3r+1)×P保持不变.将S4F×P′按行进行调整,调整后与式(2)中的S4F×P相同,则有:
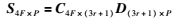
|
(5) |
式中

|
其元素为C4F×(3r+1)′按行进行了调整.
三维重建的目的是为了恢复S4F×P,从S4F×P的定义可以看出,它有3F×P个未知数.由于轨迹基{σ1 … σr}可以事先定义,即C4F×(3r+1)已知,因此对S4F×P的求解可以转化为对D(3r+1)×P的求解.D(3r+1)×P有(3r+1)×P(3F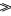
将式(5)代入式(2),有:
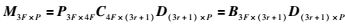
|
(6) |
式中B3F×(3r+1)=P3F×4FC4F×(3r+1).
从式(6)可以看出,存在一个非奇异矩阵H(3r+1)×(3r+1)满足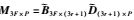
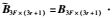
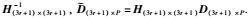
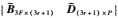
同时,还可以看出,矩阵M3F×P的秩为3r+1,若深度因子λi,j已知,对M3F×P进行SVD分解,则有:
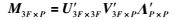
|
(7) |
式中,U3F×3F′和ΛP×P′为正交阵,V3F×P′=diag(v1 v2 … vb)(b=min(3F,P))为对角阵.
在没有噪声的情况下,V3F×P′中的对角线元素ve(e=1,2,…,b)只有前3r+1个元素为非零值,其它的值应全为0.因此式(7)还可写为
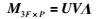
|
(8) |
式中U为U3F×3F′的前3r+1列,V为V3F×P′左上角(3r+1)×(3r+1)的子矩阵,Λ为ΛP×P′的前3r+1行.
因此,若深度因子λi,j已知,很容易实现射影重建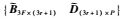
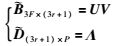
|
(9) |
任一向量投影到U列向量生成的正交补空间的投影矩阵T3F×3Fc为
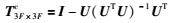
|
(10) |
由式(8)可知,U的列向量相互正交,因此有UTU=I,I为单位矩阵,即式(10)可简化为
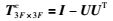
|
(11) |
从式(8)可以看出,M3F×P的列向量和U的列向量生成同一线性子空间.由于M3F×P中的任一列向量在U生成的子空间的正交补空间上的投影都为0[19],取M3F×P的第j列列向量
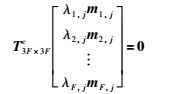
|
(12) |
假设将T3F×3Fc表示为
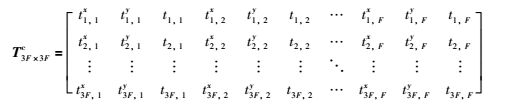
|
(13) |
将式(12)展开并整理得:
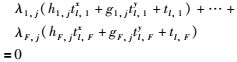
|
(14) |
式中,l=1,…,3F.即对于M3F×P中的第j列,只有F个未知数(即λ1,j,λ2j,…,λF,j),可以列3F个方程,因此可以求解出λ1,j,λ2j,…,λF,j.
同理,利用任一行向量到Λ行向量生成的正交补空间的投影矩阵TP×Pr为
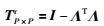
|
(15) |
同理,M3F×P中的任一行向量在Λ生成子空间的正交补空间上的投影为0[12],取M3F×P的第3i-2行行向量[λi,1hi,1 λi,2hi,2 … λi,Phi,P],可以得到
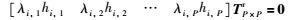
|
(16) |
假设把TP×Pr表示为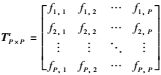
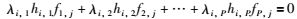
|
(17) |
式中j=1,2,…,P,对于M3F×P的第3i-2行,有P个未知数(即λi,1,λi,2,…,λi,P),可以列出P个方程,所以可以求解出深度因子λi,1,λi,2,…,λi,P.
在上述式(14)和式(17)求解深度因子λi,j过程中,要求T3F×3Fc和TP×Pr已知,但从T3F×3Fc和TP×Pr的定义可以看出,T3F×3Fc和TP×Pr分别来自于U和Λ,而U和Λ是通过对M3F×P进行SVD分解得到,M3F×P中又含有深度因子λi,j.因此,可以构造一个迭代算法,实现对深度因子λi,j的求解.
5 算法总结从上面分析,可以构造一个迭代射影重建方法,总结如下:
(1) 令所有的深度因子λi,j=1,k=1,ε=10-4.
(2) 利用式(7)和式(8)对M3F×P进行SVD分解得到U和Λ、v3r+2(k).
(3) 利用式(11)求到T3F×3Fc.
(4) 利用式(14)求到深度因子λ1,j,λ2j,…,λF,j.
(5) 利用式(15)求到TP×Pr.
(6) 利用式(17)求到深度因子λi,1,λi,2,…,λi,P.
(7) 若|v3r+2(k)-v3r+2(k-1)|≤ε,转(8); 否则k=k+1,转(2).
(8) 利用式(9)实现射影重建.
在本文算法中,ε的取值与迭代次数有关.ε越小,迭代次数就越多.本文每次迭代的运算量主要来自于对M3F×P进行奇异值分解,其运算复杂度为min(O(F2P),O(FP2)).
6 实验 6.1 仿真实验为了验证本文方法的收敛性,模拟产生由80帧图像构成的非刚体运动图像序列,该非刚体的运动由100个空间点的轨迹构成且这些轨迹生成的子空间基元数r=3,ε=10-4.同时,在图像序列中加入零均值方差为0.5、1.0、1.5个像素的高斯噪声,用本文方法进行射影重建.迭代收敛图如图 1所示.从图 1中可以看出,本文方法迭代10次以内就能够达到收敛,因此,具有较好的收敛性能.

|
| 图 1 v3r+2随迭代次数变化图 Figure 1 Variation of v3r+2 with the number of iteration |
同时,为了验证本文方法的有效性,和上述方法一样,但轨迹生成的子空间基元数r分别是4、6、8、10,产生非刚体运动图像序列.同时,在图像中加入方差由0变化至2个像素的高斯噪声,在每种情况下分别重复运行60次,然后求其平均值,实验结果如图 2所示.

|
| 图 2 v3r+2随噪声变化图 Figure 2 Variation of v3r+2 with image noise 中文注解 |
从图 2可以看出,v3r+2的值随图像噪声线性增长,说明该方法鲁棒性较好; 同时还可以看出,基元数r越大,v3r+2值越小,原因是由于矩阵在奇异值分解时,V3F×P的对角线元素ve是从大到小排列的,因此基元数r越大其对应的v3r+2值就越小.
为了研究v3r+2随基元数r的变化情况,基元数r由1变化至15,和上述方法一样产生图像序列中加入均值为0,方差分别为0.5、1.0、1.5和2.0个像素的高斯噪声,在每种情况下分别运行60次,然后求其平均值,实验结果如图 3所示.

|
| 图 3 v3r+2随基元数r变化图 Figure 3 Variation of v3r+2 with the number of base r |
从图 3可以看出,随着基元数目的增加,v3r+2的值减小,这个结论和图 2是一致的.
为了研究空间点数和图像数对v3r+2的影响,首先保持50帧图像不变,将空间点数由50个变化至350个.然后反过来,保持50个空间点数不变,图像数由50帧变化至350帧.同时,在图像序列中均加入零均值,方差为0.5个像素的高斯噪声,重复运行60次,然后求其平均值,实验结果如图 4和图 5所示.

|
| 图 4 v3r+2随空间点数变化图 Figure 4 Variation of v3r+2 with the number of space point |

|
| 图 5 v3r+2随图像数变化图 Figure 5 Variation of v3r+2 with the number of image |
从图 4和图 5可以看出,随着空间点数和图像数的增加,v3r+2值增加.原因在于,当空间点数和图像数增加时,图像矩阵M3F×P变大.从能量的角度来讲,即矩阵M3F×P的能量越大,而V3F×P对角线元素ve是图像矩阵M3F×P能量的反映,因此,v3r+2会随着图像矩阵M3F×P的增加而增加,即随着空间点数和图像数的增加而增加.
为了比较本文方法和Lladó方法[20]的重建效果,本文在基元数r分别为3、4和5时,产生一个含有20帧40个空间点的非刚体运动图像序列,并加入零均值方差为0到2的高斯噪声,分别用本文方法和Lladó方法进行射影重建.在每种情况下分别运行60次,然后求v3r+2的平均值,实验结果如图 6所示.

|
| 图 6 本文方法和Lladó方法比较 Figure 6 Comparisons of our method with Lladó′s method |
从图 6可以看出,本文方法在各种基元数r下与Lladó方法相比,v3r+2值更小,说明本文方法要比Lladó方法重建精度要高.原因是由于本文方法求解深度因子时既利用了图像矩阵行约束,又利用了图像矩阵列约束,而Lladó方法仅利用了图像矩阵的列约束.
6.2 真实实验本文获取了一个含有30帧的跳舞图像序列,其中的两帧如图 7所示.从图中可以看出,该人体的运动不能当作刚体运动,只能当作非刚体运动.提取并跟踪了48个特征点(见图 7中的“+”),取基元个数为9,利用这些特征点,本文方法和Lladó方法分别进行射影重建.为了反映重建效果,将重建的特征点分别进行重投影(见图 7中的“Ο”),其中第1行为本文方法的重投影,第2行为Lladó方法的重投影,第1列为图像序列的第7帧,第2列为第19帧.

|
| 图 7 跳舞图像序列 Figure 7 Image sequence of dance |
从图 7中可以看出,本文方法的重投影点(Ο)和特征点(+)基本重合,而Lladó方法的误差比较大,说明本文方法能够更加有效地实现非刚体的射影重建.
7 结束语本文在相机为透视投影模型下,基于非刚体可由若干个特征点的轨迹组成且由轨迹生成的低维子空间的基底可以事先定义的特点,使求解的未知数大大减少,提高了算法的鲁棒性.利用图像矩阵的行向量和列向量生成一个低维子空间的性质,对深度因子进行迭代求解,最终实现射影重建.求解深度因子时,同时利用了图像矩阵的行向量和列向量的约束,提高了重建精度.模拟和真实实验结果表明,本文方法具有收敛速度快、误差小等优点.
| [1] | Jo J, Choi H, Kim I, Kim J. Single-view-based 3D facial reconstruction method robust against pose variations[J]. Pattern Recognition, 2015, 48(1): 73–85. DOI:10.1016/j.patcog.2014.07.013 |
| [2] | Bartoli A, Collins T, Pizarro D. Metric corrections of the affine camera[J]. Computer Vision and Image Understanding, 2015, 135: 141–156. DOI:10.1016/j.cviu.2015.03.001 |
| [3] | Park H, Shiratori T, Matthews I, et al. 3D trajectory reconstruction under perspective projection[J]. International Journal of Computer Vision, 2015, 115(2): 115–135. DOI:10.1007/s11263-015-0804-2 |
| [4] | Raviv D, Kimmel R. Affine invariant geometry for non-rigid shapes[J]. International Journal of Computer Vision, 2015, 111(1): 1–11. DOI:10.1007/s11263-014-0728-2 |
| [5] | Nasihatkon B, Hartley R, Trumpf J. A generalized projective reconstruction theorem[J]. International Journal of Computer Vision, 2015: 1–28. |
| [6] | Kiriakos N, Steven M. A theory of shape by space carving[J]. International Journal of Computer Vision, 2000, 38(3): 199–218. DOI:10.1023/A:1008191222954 |
| [7] | Tomasi C, Kanade T. Shape and motion from image streams under orthography:A factorization method[J]. International Journal of Computer Vision, 1992, 9(2): 137–154. DOI:10.1007/BF00129684 |
| [8] | Pollefeys M, Gool L, Vergauwen M, et al. Visual modeling with a hand-held camera[J]. International Journal of Computer Vision, 2004, 59(3): 207–232. DOI:10.1023/B:VISI.0000025798.50602.3a |
| [9] | Sung C, Kim P. 3D terrain reconstruction of construction sites using a stereo camera[J]. Automation in Construction, 2016, 64: 65–77. DOI:10.1016/j.autcon.2015.12.022 |
| [10] | Bregler C, Hertzmann A, Biermann H. Recovering non-rigid 3D shape from image streams[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA:IEEE, 2000:690-696. |
| [11] | Gotardo P, Martinez A. Kernel non-rigid structure from motion[C]//IEEE International Conference on Computer Vision. Piscataway, NJ, USA:IEEE, 2011:6-13. |
| [12] | Simon T, Valmadre J, Matthews I, et al. Separable spatiotemporal priors for convex reconstruction of time-varying 3D point clouds[C]//European Conference on Computer Vision. Piscataway, NJ, USA:IEEE, 2014:204-219. |
| [13] | Dhou S, Motai Y. Dynamic 3D surface reconstruction and motion modeling from a pan-tilt-zoom camera[J]. Computers in Industry, 2015, 70(6): 183–193. |
| [14] | Valmadre J, Lucey S. General trajectory prior for non-rigid reconstruction[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA:IEEE, 2012:1394-1401. |
| [15] | Garg R, Roussos A, Agapito L. A variational approach to video registration with subspace constraints[J]. International journal of computer vision, 2013, 104(3): 286–314. DOI:10.1007/s11263-012-0607-7 |
| [16] | Isack H, Boykov Y. Energy based multi-model fitting & matching for 3D reconstruction[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA:IEEE, 2014:1146-1153. |
| [17] | Akhter I, Sheikh Y, Khan S, et al. Trajectory space:A dual representation for nonrigid structure from motion[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 33(7): 1442–1456. |
| [18] | Snavely N, Seitz S, Szeliski R. Modeling the world from internet photo collections[J]. International Journal of Computer Vision, 2008, 80(2): 189–210. DOI:10.1007/s11263-007-0107-3 |
| [19] | Golub G, Loan C. Matrix computations[M]. Baltimore, MD: Johns Hopkins University Press, 2012: 141-187. |
| [20] | Lladó X, Bue A D, Agapito L D. Non-rigid 3D factorization for projective reconstruction[C]//Proceedings of the British Machine Vision Conference. Durham, UK:BMVA Press, 2005:844-849. |