



2. 重庆川仪自动化股份有限公司, 重庆 400000
2. Chongqing ChuanYi Automation Co., Ltd, Chongqing 400000, China
1 引言
现实生活中许多问题都是由相互冲突、相互影响的多个目标组成,使多个给定目标在给定区域内尽可能最佳的优化问题就是多目标优化问题(multi objective optimization).多目标优化是要找出一个能同时满足所有优化目标的解,而这个解通常是以一个不确定的点集形式出现,所以其目标就是找出这个解集的分布情况,并根据具体情况找出合适问题的解.将粒子群优化算法(particle swarm optimization,PSO)运用于多目标优化,对多个目标相互协调,形成多目标粒子群优化算法(multi-objective particle swarm optimization algorithm,MOPSO).它在实际工程中得到了广泛的应用[1-5].
目前多目标粒子群优化算法主要是通过建立外部档案[6-7]来保存Pareto解.为了提高种群的多样性,Lei[8]采用小生境选择策略,在外部种群中选择最佳粒子作为领导粒子,用于领导进化种群中粒子的进化. Yang等[9]将多精英学习策略和惯性权重自适应调整策略引入标准粒子群优化算法中,利用前者维持种群的多样性以避免算法陷入局部最优,利用后者提高算法的搜索效率和收敛速度. Li等[10]改进密度估计策略,减少远离Pareto前沿的非被占优解数量,提高算法的收敛性能. Ding等[11]提出了一种基于自适应网络和动态拥挤距离的多目标粒子群优化算法. Jiao等[12]通过一组均匀分布的方向向量将目标空间区域进行均匀划分,种群中的个体被划分到各个子区域进行协同进化,以提升种群的多样性. Wang等[13]引入基于拥挤距离的Pareto最优解分布性动态维护策略,改进Pareto前沿的分布性.还有其他一些方法用于提高种群的多样性,比如Ye[14]建立了粒子数动态变化的函数,利用函数中的周期振荡项增加种群的多样性. Qiao[15]引入混沌变异机制,增加种群的多样性.
这些小生境、拥挤距离、K邻近等方法往往比较复杂,相比而言,网格策略是在对Pareto解进行多样性判断时较简单的方法,但由于网格划分的盲目性,它的分辨率往往不高,为了减少其盲目性,出现了一些改进的网格划分策略,它们能自适应目标空间[16],对目标空间进行更合理的划分,但无论如何划分目标空间,都不可避免地出现超体内所含粒子数量相同的情况,传统方法此时失去了判断其多样性的能力,一旦需要对这些超体进行如档案删减,领导粒子选择时,就存在一定盲目性,所选的超体不一定是最优的.
于是本文在MOPSO算法的基础上提出了一种新的算法——带基因交换和动态网格的多目标粒子群优化算法(Multi-objective Particle swarm Optimization with Gene exchange and Dynamic mesh,MPOGD),利用动态网格策略,合理划分目标空间,并对含有相同粒子的超体进行二次划分,对这些多样性相同的超体进行排序,便于对档案的管理和领导粒子的选择;同时利用以往被忽略的档案解,交换其优秀基因,提高算法的收敛速度,仿真[17]表明了算法具有良好的多样性和更快的收敛速度.
2 带基因交换和动态网格的多目标粒子群优化算法(MPOGD)多目标粒子群优化算法与粒子群优化算法的区别在于多目标粒子群优化算法得到的解是多维的,由于它的多维特性,使得在比较解的支配等级上出现了无法比较的情况,那些无法被其它解支配的解所形成的集合就是多目标粒子群优化的解集.本文的主要工作就是对这个解集进行利用和管理,提高算法的收敛速度和解的多样性.
多目标粒子群优化算法的粒子更新公式为
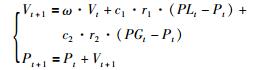
|
(1) |
Vt表示速度,Pt表示位置,PLt表示局部最优,PGt表示全局最优,t为迭代次数,ω表示惯性权重,c1和c2为加速系数,r1和r2为[0, 1]均匀分布的随机数.
ω·Vt为惯性部分,表示粒子保持之前的速度;较大的ω值便于全局搜索,而较小的ω值便于局部搜索,通常在粒子更新过程中ω值在[0.9,0.4]内线性递减;c1·r1·(PLt-Pt)是认知部分,表示粒子对自身的思考;c2·r2·(PGt-Pt)是社会部分,表示粒子间的信息共享和相互协作.
根据多目标粒子群优化算法的粒子更新公式,我们将每一代计算得到的解集存入档案,并完成基因交换及网格的动态划分,提高算法的收敛速度和解的多样性.
2.1 档案基因交换档案中存储的都是精英解,而传统的粒子群优化算法,仅仅是从这部分解中求得领导粒子,以引导后续粒子的进化,其余绝大部分粒子并没有参与到后续进化中,为了充分利用档案解,在其中进行随机的基因交换,提高算法性能.
在算法中后期,档案中聚集了大量的解,这些解都是精英解,它们是目前计算出来距离最优解最近的粒子,而构成这些粒子的是每一个维度的基因,这就说明,这些粒子内包含有部分优秀基因,甚至可能存在某部分基因就是最优解的基因,但同时由于它并不是最优解,粒子内同样包含了部分劣基因,如果能将某粒子内的优秀基因与其他粒子对应位的劣基因进行基因交换,则新生粒子较父代更优.如图 1所示.

|
| 图 1 基因交换示意图 Figure 1 Schematic diagram of gene exchange |
由于对优秀基因的判断较为复杂,且在某种程度上并不可行,这里的基因交换如同自然界的基因交换,是一种盲目的、随机的交换,为了保证基因交换的有效性,我们采用大规模基因交换的方式,提高基因交换的成功率.基因交换可以看成是一种局部搜索,在优化前期,由于档案解距离最优解较远,这时的搜索以全局搜索为主,基因交换的效率较低,此时并不使用.我们将基因交换的触发机制设为:一是档案解的数量是否超过阈值;二是当前代数是否超过阈值.只有当两者满足条件时才触发基因交换.
针对不同的问题,有不同的基因交换策略,可以借鉴遗传算法;可以随机选取若干粒子,在这些粒子间交换基因等.基因交换完成之后与原档案解一起,选出新的档案解.
2.2 动态网格网格策略是将目标空间分为若干超体,以每个超体内粒子的数量为基础,得出粒子分布的密度,引导粒子向密度小的方向飞行,提高种群的多样性,同时通过对高密度分布的粒子进行删减,完成对档案的管理.
以往的网格划分策略只是对目标空间进行一次划分,通过划分份数的调整,尽量使粒子在每个划分的空间内均匀分布,但对于具有相同粒子数量的空间,目前还没有措施对其进行多样性判断.于是本文提出了动态调整的概率,对目标空间进行二次划分,判断其多样性.
2.2.1 目标空间动态划分以往的网格划分是在每个子目标上,将目标空间划为n份,这样m维目标空间就有nm个超体.
假设di表示在第i维空间上每份空间的长度,di,min表示第i维空间上相邻粒子目标函数值的最小间隔;di,max表示第i维空间上,相邻粒子目标函数值的最大间隔.当满足:
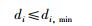
|
(2) |
划分的每份空间内,粒子的数量不会超过1,显然这对我们寻求粒子密度是不利的,而且过多的空间会导致算法计算时间的延长.
当满足
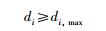
|
(3) |
划分的空间数量过少,这样又会降低分辨率.
对此提出了如下划分公式:
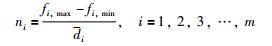
|
(4) |
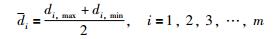
|
(5) |
m是目标空间的维度,ni是在第i维目标空间上划分的份数,fi,max表示略大于现有粒子在第i维空间上目标函数最大值的数值,fi,min是略小于现有粒子在第i维空间上目标函数最小值的数值. di是相邻粒子在第i维空间上目标函数值间隔的最小值di,min与最大值di,max的平均值.
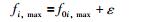
|
(6) |
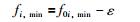
|
(7) |
f0i,max,f0i,min表示现有粒子在第i维空间上目标函数的最大值和最小值,ε是一个很小的正数.这样做的目的是稍微加大目标空间划分的边界,使得最小值和最大值的粒子落到空间内.
通过该公式更合理地划分目标空间,使得每个超体包含的粒子数量出现较明显的差异,方便引导飞行和档案管理.
2.2.2 超体的动态调整无论对网格如何划分,难免会出现若干个含有相同数量粒子的超体,如果在选取领导粒子或需要对档案解进行管理时出现这种情况,就需要对含有相同数量粒子的超体进行密度排序,以往的网格策略是在这些超体中随机选择,不能保证选取的超体是最优的,于是我们提出了超体动态调整的方法,对网格进行二次划分,选取最合适的网格.
网格策略反映的仅仅是超体内的粒子密度,当出现含有相同数量粒子的超体时,认为这些超体内的粒子密度相同,但对于超体周围的粒子密度其并不能反映出来,如果出现超体内密度高,而超体周围粒子密度低,则总密度也可能低,对此,我们对超体周围的粒子数量进行统计,以此为依据对具有相同粒子密度的超体进行密度排序.
如果需要对其进行密度排序,我们就将该超体在每个维度上向外扩展,集合与其相邻的若干个超体,形成一个稍大的新超体,然后对新立方体统计所含粒子数量,数量少的说明原超体周围的粒子密度较低,而数量多的说明原超体周围的粒子密度较高.
这里将每个超体的密度优先级表示为
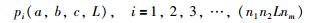
|
(8) |
a为超体i中的粒子数量,a越小,优先级pi越高,相同的粒子数量有着相同的优先级.当出现超体优先级相同时,即pj(a)=pk(a),j≠k.临时扩大超体至其相邻的超体,即与邻近超体组合成新的超体,统计含有粒子数量为b,优先级变为pj(a,b),pk(a,b),这时b决定了超体j和k的优先级,b越小,优先级pi越高.如果pj(a,b)=pk(a,b),则进一步扩大至c,比较pj(a,b,c),pk(a,b,c),以此类推.
如图 2所示,超体A和B的优先级为pA,pB,且pA(1)=pB(1),此时扩大A和B的区域至相邻阴影部分,超体A和B的优先级为pA(1,5),pB(1,14) 有pA(1,5)>pB(1,14).

|
| 图 2 超立方A和B的示意图 Figure 2 Hypercube A and B |
超体动态调整的触发机制为:一是出现粒子分布密度相同的超体;二是需要对这些超体进行密度排序时,比如需要在这些超体中选取领导粒子时,或者需要删除高密度超体内的粒子时.当同时满足这两个条件时,才进行超体的动态调整.
2.2.3 选择领导粒子和档案管理领导粒子的选取遵循的是低密度粒子优先的原则,当出现若干个最低密度超体时,对其动态调整、二次划分,有利于选取比实际密度更低的粒子做领导粒子,引导整个种群的进化.
当档案解的数量过大时,需要对其进行删减,而档案解删减的原则是高密度粒子优先,当出现有若干个最高密度超体时,对其动态调整、二次划分,从周围密度最高的超体开始删减其中粒子.
2.3 算法流程Step 1 初始化,包括种群的位置、速度和档案等.
Step 2 进行粒子飞行,并计算适应度,更新档案.
Step 3 更新个体最优,利用动态网格策略选取领导粒子.
Step 4 当档案解大于阈值时,进行档案基因交换.
Step 5 如基因交换出现了更优解则对档案进行更新,重新选择领导粒子,否则进入下一步.
Step 6 如果满足退出条件,退出运算,否则返回Step 2.
2.4 复杂度分析由于MPOGD算法并没有对多目标粒子群优化算法的结构进行大的改动,而且本文所提的基因交换策略和超体动态调整策略并不会在每一代计算中出现,所以算法总时间复杂度较多目标粒子群优化算法不会有明显提高,下面讨论下两种策略的时间复杂度.
基因交换的时间复杂度根据选择交换方式的不同而不同,本文中选择的是依次轮换的方式,即将第一个粒子的某基因段赋给第二个粒子的对应位,第二个例子的该基因段赋给第三个粒子的对应位,以此类推,最后一个粒子的该基因段赋给第一个粒子的对应位.如此,只要一次循环就能完成基因交换的工作,所以其时间复杂度为o(n).
传统网格策略的时间复杂度为o(n),而将传统网格策略的网格划分策略改为超体动态划分只是对划分超体的数量进行动态确定,并不会增加网格策略的总体时间复杂度,其仍为o(n);而超体动态调整策略的时间复杂度也为o(n),所以它的引入会在极限情况下将网格策略的时间复杂度变为o(n2),但实际中,由于动态调整触发机制的限制,其触发的次数有限,对实际计算时间的影响很小.
为了比较两种策略对算法的实际影响,我们选取相同的参数:种群大小和档案大小同为100,测试函数为ZDT1,函数决策空间的大小为30,用传统多目标粒子群优化算法与MPOGD算法进行的计算时间的统计,各种情况分布运行10次,统计平均时间.
| 迭代次数 | 平均运行时间(s) | |
| MOPSO | MPOGD | |
| 100 | 33.998 | 34.213 |
| 500 | 302.589 | 315.682 |
| 1 000 | 798.985 | 850.549 |
由此可见,随着迭代次数的增加,MPOGD算法较MOPSO算法的运行时间会有小幅增长,这主要是因为迭代次数的增加,伴随着基因交换和动态网格机制触发次数的增加,但由于基因交换和动态网格策略本身的时间复杂度并不高,所以运行时间的增加值也不会太高,对算法总体时间运行影响不大.
3 性能测试 3.1 测试函数和指标选择DTLZ作为测试函数,函数解的维度为12.对比算法选择MOPSO[18],MOEA/D[19]和SPEA2[20]三种算法.
指标选择超体积Ih和解集覆盖.超体积(hyper volume,HV)定义为被所得解集支配的、但不被参考点集支配的空间的体积.它同时度量了收敛性和多样性.当有3个目标函数时,DTLZ1选择的参考点为[0.5 0.5 0.5],其余函数的参考点选择[1 1 1];当有6个目标函数时,DTLZ1选择的参考点为[0.5 0.5 0.5 0.5 0.5 0.5],其余函数的参考点选择[1 1 1 1 1 1];当有9个目标函数时,DTLZ1选择的参考点为[0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5],其余函数的参考点选择[1 1 1 1 1 1 1 1 1].本文中为了计算近似解集所支配的区域,采用蒙特卡洛随机采样的模拟方法来计算支配区域的面积,即在整个参考点范围之内随机取点n个,然后计算位于解集支配的区域内的点的个数,该个数占总的采样点个数的比例可以近似看为是解集在目标空间所支配的空间相对于参考点的比例.显然Ih越大,收敛性越好.
解集覆盖(set coverage,SC)提供了两个对比算法性能的直观比较.基于Pareto支配的定义,通过比较两种对比算法得到的解集A和B,可以同时获得算法收敛性和多样性的度量.用SC(A,B)来表示,即B中的解被A中的解支配或者相等的比例.
4种算法的种群大小与输出解集大小相同,都是100. MOPSO和PMOPSO算法的ω为[0.9,0.4]的线性变化,c1=c2=2. MOEA/D算法和SPEA2算法所用的参数按照对应文献所推荐的参数设置.各个算法在具有相同目标函数时选取相同运算时间进行比较,在3维目标函数时选取的运算时间为1 min,6维目标函数选取2 min,9维目标函数选取3 min.
3.2 结果分析当3维目标函数时,每个算法独立运行10次,得到表 2、表 3(表中的D1-D6分别表示为函数DTLZ1-DTLZ6).
| 3 d | max | min | mean | square | |
| MPOGD | D1 | 0.770 8 | 0.752 8 | 0.762 5 | 3.99E-05 |
| D2 | 0.386 1 | 0.365 8 | 0.377 4 | 4.01E-05 | |
| D3 | 0.404 | 0.351 5 | 0.388 7 | 0.000 298 | |
| D4 | 0.398 | 0.379 9 | 0.389 8 | 3.3E-05 | |
| D5 | 0.221 | 0.218 1 | 0.219 6 | 8.98E-07 | |
| D6 | 0.218 4 | 0.212 | 0.214 7 | 4.56E-06 | |
| MOPSO | D1 | 0 | 0 | 0 | 0 |
| D2 | 0.316 4 | 0.281 5 | 0.305 8 | 0.000 147 | |
| D3 | 0 | 0 | 0 | 0 | |
| D4 | 0.301 9 | 0.220 8 | 0.271 7 | 0.000 962 | |
| D5 | 0.214 3 | 0.198 5 | 0.204 6 | 3.65E-05 | |
| D6 | 0 | 0 | 0 | 0 | |
| MOEA/D | D1 | 0 | 0 | 0 | 0 |
| D2 | 0.369 1 | 0.325 9 | 0.350 4 | 0.000 241 | |
| D3 | 0 | 0 | 0 | 0 | |
| D4 | 0.365 7 | 0.319 8 | 0.342 4 | 0.000 394 | |
| D5 | 0.218 5 | 0.199 8 | 0.209 2 | 4.64E-05 | |
| D6 | 0.222 3 | 0.199 6 | 0.213 2 | 6.74E-05 | |
| SPEA2 | D1 | 0 | 0 | 0 | 0 |
| D2 | 0.405 | 0.359 2 | 0.380 3 | 0.000 29 | |
| D3 | 0 | 0 | 0 | 0 | |
| D4 | 0.401 2 | 0.378 5 | 0.387 5 | 5.53E-05 | |
| D5 | 0.220 1 | 0.208 5 | 0.214 3 | 2.31E-05 | |
| D6 | 0 | 0 | 0 | 0 | |
| (a)DTLZ1 | (b)DTLZ2 | (c)DTLZ3 | ||||||||||||||
| D1 | A1 | A2 | A3 | A4 | D2 | A1 | A2 | A3 | A4 | D3 | A1 | A2 | A3 | A4 | ||
| A1 | 0 | 0.99 | 0.92 | 0.84 | A1 | 0 | 0.49 | 0.07 | 0.03 | A1 | 0 | 1 | 1 | 1 | ||
| A2 | 0 | 0 | 0 | 0 | A2 | 0.01 | 0 | 0 | 0 | A2 | 0 | 0 | 0 | 0 | ||
| A3 | 0 | 1 | 0.17 | 1 | A3 | 0.08 | 0.48 | 0.08 | 0.03 | A3 | 0 | 1 | 0.15 | 0.99 | ||
| A4 | 0 | 0.76 | 0 | 0 | A4 | 0.07 | 0.57 | 0.08 | 0 | A4 | 0 | 0.67 | 0 | 0.26 | ||
| (d)DTLZ4 | (e)DTLZ5 | (f)DTLZ6 | ||||||||||||||
| D4 | A1 | A2 | A3 | A4 | D5 | A1 | A2 | A3 | A4 | D6 | A1 | A2 | A3 | A4 | ||
| A1 | 0 | 0.64 | 0.18 | 0.1 | A1 | 0 | 0.71 | 0.17 | 0.08 | A1 | 0 | 1 | 0 | 1 | ||
| A2 | 0 | 0 | 0 | 0.02 | A2 | 0 | 0 | 0 | 0 | A2 | 0 | 0 | 0 | 0 | ||
| A3 | 0 | 0.27 | 0.1 | 0.05 | A3 | 0 | 0.64 | 0.03 | 0.03 | A3 | 0 | 1 | 0 | 1 | ||
| A4 | 0 | 0.31 | 0 | 0 | A4 | 0 | 0.7 | 0.14 | 0 | A4 | 0 | 0.98 | 0 | 0 | ||
从表 2分析,在DTLZ系列函数中,MPOGD算法在指标Ih上得到了DTLZ1、DTLZ3、DTLZ5三个函数的最优值,SPEA2算法在指标Ih上取得了DTLZ2、DTLZ4三个函数的最优值,而函数DTLZ6在指标Ih上的最优值由MOEA/D算法取得.在平均值上,MPOGD算法取得了除DTLZ2外的其它函数的最优值.可见在指标Ih上,MPOGD算法最优.
选取4种算法10次独立运算的解集中超体积Ih指标最好的解集,得到关于解集覆盖的指标值,如图 3所示(图中的A1-A4分别表示为MPOGD,MOPSO,MOEA/D和SPEA2四种算法).

|
| 图 3 4种算法在DTLZ系列函数的解集 Figure 3 The solution set of four algorithms in DTLZ |
在DZTL1函数上,MPOGD算法的解集能支配其余3种算法解集中的大部分.在DZTL2上,SPEA2算法优于MPOGD算法,这也与其在该函数的指标Ih上的结果相同.在DZTL3上,MPOGD的解集支配其余所有算法的解集.在DZTL4上,MPOGD的性能也是最优的,由于该函数在指标Ih上的最优值出现在SPEA2算法上,其性能也紧随MPOGD算法.在DZTL5上,MPOGD的算法也是最优的,其次是SPEA2算法.在DZTL6上,MPOGD算法与MOEA/D算法得到的解集不能相互支配,且能完全支配其它两种算法的解集.
由此可见,在这4种算法中,MPOGD算法最优,其次是SPEA2算法,然后是MOEA/D算法,最后是MOPSO.
为了进一步对比测试几种算法的性能,我们将问题的维度由3维扩展到6维.
当有6维目标函数时,得到表 4.
| 6 d | max | min | mean | square | |
| MPOGD | D1 | 0.503 4 | 0.489 8 | 0.498 5 | 3.06E-05 |
| D2 | 0.394 7 | 0.361 5 | 0.382 3 | 4.11E-05 | |
| D3 | 0.483 2 | 0.475 | 0.479 4 | 9.14E-06 | |
| D4 | 0.155 7 | 0.149 8 | 0.152 8 | 5.72E-06 | |
| D5 | 0.118 4 | 0.109 4 | 0.114 8 | 1.51E-05 | |
| D6 | 0.125 9 | 0.119 2 | 0.124 1 | 6.83E-06 | |
| MOPSO | D1 | 0.002 1 | 0 | 0.000 8 | 5.63E-07 |
| D2 | 0.041 | 0 | 0.020 5 | 0.000 283 | |
| D3 | 0 | 0 | 0 | 0 | |
| D4 | 0.098 7 | 0 | 0.048 2 | 0.001 449 | |
| D5 | 0.050 8 | 0 | 0.016 2 | 0.000 463 | |
| D6 | 0.001 2 | 0 | 0.000 4 | 2.7E-07 | |
| MOEA/D | D1 | 0.457 | 0.401 9 | 0.432 8 | 0.000 162 |
| D2 | 0.408 6 | 0.382 5 | 0.394 4 | 6.06E-05 | |
| D3 | 0.035 | 0 | 0.009 2 | 0.000 204 | |
| D4 | 0.139 4 | 0.107 2 | 0.124 7 | 0.000 156 | |
| D5 | 0.060 8 | 0.045 6 | 0.054 8 | 2.31E-05 | |
| D6 | 0.059 1 | 0.036 | 0.045 5 | 6.12E-05 | |
| SPEA2 | D1 | 0 | 0 | 0 | 0 |
| D2 | 0 | 0 | 0 | 0 | |
| D3 | 0 | 0 | 0 | 0 | |
| D4 | 0 | 0 | 0 | 0 | |
| D5 | 0 | 0 | 0 | 0 | |
| D6 | 0 | 0 | 0 | 0 | |
| (a)DTLZ1 | (b)DTLZ2 | (c)DTLZ3 | ||||||||||||||
| D1 | A1 | A2 | A3 | A4 | D2 | A1 | A2 | A3 | A4 | D3 | A1 | A2 | A3 | A4 | ||
| A1 | 0 | 1 | 0 | 1 | A1 | 0 | 0.65 | 0 | 0.95 | A1 | 0 | 0.97 | 0.69 | 1 | ||
| A2 | 0 | 0 | 0 | 0.2 | A2 | 0 | 0 | 0 | 0.49 | A2 | 0 | 0 | 0 | 0.24 | ||
| A3 | 0 | 0.91 | 0.01 | 0.99 | A3 | 0 | 0.64 | 0 | 0.96 | A3 | 0 | 0.57 | 0.02 | 1 | ||
| A4 | 0 | 0 | 0 | 0 | A4 | 0 | 0 | 0 | 0 | A4 | 0 | 0.05 | 0 | 0 | ||
| (d)DTLZ4 | (e)DTLZ5 | (f)DTLZ6 | ||||||||||||||
| D4 | A1 | A2 | A3 | A4 | D5 | A1 | A2 | A3 | A4 | D6 | A1 | A2 | A3 | A4 | ||
| A1 | 0 | 0.85 | 0.02 | 0.96 | A1 | 0 | 0.24 | 0 | 0.99 | A1 | 0 | 0.99 | 0 | 1 | ||
| A2 | 0 | 0 | 0 | 0.73 | A2 | 0 | 0 | 0 | 0.72 | A2 | 0 | 0 | 0 | 0.06 | ||
| A3 | 0 | 0 | 0 | 0.47 | A3 | 0 | 0 | 0 | 0.77 | A3 | 0 | 0.88 | 0 | 0.74 | ||
| A4 | 0 | 0 | 0 | 0 | A4 | 0 | 0 | 0 | 0 | A4 | 0 | 0 | 0 | 0 | ||
从该表可以看出,随着目标维度的扩展,几种算法的精度都有不同程度的下降,特别是SPEA2算法,在6维目标下,规定时间内几个测试函数都未成功收敛,说明了其对于高维目标优化能力的不足.
在函数DTLZ1、DTLZ3、DTLZ4、DTLZ5、DTLZ6上,MPOGD算法取得了明显的优势,但在函数DTLZ2上,MPOGD较弱于MOEA/D算法.而SPEA2在规定时间内无法收敛到参考点内.
从该表可以看出,在函数DTLZ1、DTLZ2、DTLZ3、DTLZ4、DTLZ6上,MPOGD算法得到的解集,能覆盖大部分MOPSO算法在其函数上得到的解集.在函数DTLZ3上,MPOGD得到的解集能覆盖大部分MOEA/D算法得到的解集.而对于SPEA2算法,MPOGD几乎能全覆盖.
综合统计4种算法在几个函数上,由3维目标扩展到4维目标的性能,如表 6.
| 3/6维目标函数 | 算法 | |||
| MPOGD | MOPSO | MOEA/D | SPEA2 | |
| DTLZ1 | 优/优 | 差/中 | 良/良 | 中/差 |
| DTLZ2 | 良/良 | 差/中 | 中/优 | 优/差 |
| DTLZ3 | 优/优 | 差/差 | 良/良 | 中/中 |
| DTLZ4 | 良/优 | 差/中 | 中/良 | 优/差 |
| DTLZ5 | 优/优 | 差/中 | 中/良 | 良/差 |
| DTLZ6 | 良/优 | 差/中 | 优/良 | 中/差 |
从该表可以看出,在3维目标下,本文所提的算法取得了三优三良的成绩,同时,当目标空间扩展到6维,本文的算法取得了五优一良的成绩,说明较其余3种算法,MPOGD在高维目标空间下性能衰减明显较低.其中的SPEA2算法,在3维和6维空间下出现了两级分化,说明其不适应高维空间. MOEA/D为公认解决多目标优化问题较好的算法,其在6维目标空间下取得了一优五良的成绩,验证了其在多目标优化问题中的有效性.
同时我们对各种算法达到相同精度的运行时间做出了统计.
由于目标空间的维度为3维,所以建立一个标准,如果两项测试指标落入该标准内,就认为其达到了一定精度,这个标准是根据历史数据进行统计分析所得.由于在3维目标的定时测试中,只有DTLZ2、DTLZ4、DTLZ5三个目标函数均有结果,所以此轮测试只用这三个目标函数,统计目标函数Ih的最低值做为标准一,由于MOPSO算法在各次计算中的结果最差,所以选取的Ih标准均为MOPSO算法所得.选取各个函数在各个算法中最差的解集与此轮计算结果进行解集覆盖计算,将能对该解集进行覆盖度做为标准二,由于MOPSO算法在各次计算中均最差,所以将MOPSO算法的解集与本次测试的解集做解集覆盖测试.
| 测试函数 | Ih标准值 | SC标准值 |
| DTLZ2 | 0.281 5 | 0.48 |
| DTLZ4 | 0.220 8 | 0.27 |
| DTLZ5 | 0.198 5 | 0.64 |
由于SC标准中,计算解集覆盖的集合较大,这里不一一列出.
由于性能指标的计算比较费时,它们都需要两两比较,故我们对每代计算结果和计算时间进行存储,完成整个运算后,再对每代计算结果进行分析,统计计算时间.当两个标准都达到时,其时间见表 8(10次独立运行的平均时间).
| 测试函数 | 平均运行时间/s | ||
| MPOGD | MOEA/D | SPEA2 | |
| DTLZ2 | 39.245 | 45.259 | 42.768 |
| DTLZ4 | 44.091 | 50.956 | 44.387 |
| DTLZ5 | 52.907 | 55.567 | 53.631 |
由于采用的标准均来源于MOPSO算法的性能指标,故未统计该算法的运行时间.
从表 8可以看出,在达到相同精度的情况下,本文所提的算法运行时间最短.
综上所述,MPOGD算法虽然在部分函数上微落后,但在总体性能上比较其余3种算法有较明显优势,特别是对于MOPSO算法而言,MPOGD算法取得全面优势.
4 结论网格策略在对含有相同粒子的网格进行多样性判断时失去了辨别能力,为此,本文通过二次划分的方式,动态调节超体的大小,用超体周围的粒子密度对含有相同数量粒子的超体进行多样性判断,据此选择领导粒子和管理档案解.同时,由于以往的多目标粒子群优化算法中,未对档案解进行利用,而档案解中包含有大量优秀基因,于是本文利用基因交换的策略,让粒子中的劣基因可以被优秀基因替代,从而加快算法的收敛速度.通过DTLZ系列函数的验证,表明了MPOGD算法具有良好的多样性和更快的收敛速度,并能有效解决高维多目标问题.
| [1] |
周悦, 岳林蓓, 张力心, 等.
基于粒子群变异的克隆选择算法的结构故障检测与分类[J]. 信息与控制, 2015, 44(4): 436–441.
Zhou Y, Yue L B, Zhang L X, et al. Structural damage detection and classification based on clone selection algorithm of particle swarm mutation[J]. Information and Control, 2015, 44(4): 436–441. |
| [2] |
宋晓宇, 王建国, 常春光.
基于需求紧迫度的非线性连续消耗应急调度模型与算法[J]. 信息与控制, 2014, 43(6): 735–743.
Song X Y, Wang J G, Chang C G. Nonlinear continuous consumption emergency material dispatching models based on demand urgency degrees and its algroithm[J]. Information and Control, 2014, 43(6): 735–743. |
| [3] |
石欣, 印爱民, 陈曦.
基于RSSI的多维标度室内定位算法[J]. 仪器仪表学报, 2014, 35(2): 261–268.
Shi X, Yin A M, Chen X. RSSI and multidimensional scaling based indoor localization algorithm[J]. Chinese Journal of Scientific Instrument, 2014, 35(2): 261–268. |
| [4] |
高学金, 崔宁, 张亚潮, 等.
基于粒子群优化MICA的间歇过程故障监测[J]. 仪器仪表学报, 2015, 36(1): 152–159.
Gao X J, Cui N, Zhang Y C, et al. Fault detection of batch processes based on MICA optimized with PSO[J]. Chinese Journal of Scientific Instrument, 2015, 36(1): 152–159. |
| [5] |
乔宗良, 张蕾, 周建新, 等.
一种改进的CPSO-LSSVM软测量模型及其应用[J]. 仪器仪表学报, 2014, 35(1): 234–240.
Qiao Z L, Zhang L, Zhou J X, et al. Soft sensor modeling method based on improved CPSO-LSSVM and its applications[J]. Chinese Journal of Scientific Instrument, 2014, 35(1): 234–240. |
| [6] | Pasandideh S H R, Niaki S T A, Sharafzadeh S. Optimizing a bi-objective multi-product EPQ model with defective items, rework and limited orders:NSGA-Ⅱand MOPSO algorithms[J]. Journal of Manufacturing Systems, 2013, 32(4): 764–770. DOI:10.1016/j.jmsy.2013.08.001 |
| [7] | Turky A M, Abdullah S. A multi-population harmony search algorithm with external archive for dynamic optimization problems[J]. Information Sciences, 2014, 272(10): 84–95. |
| [8] |
雷瑞龙, 侯立刚, 曹江涛.
基于多策略的多目标粒子群优化算法[J]. 计算机工程与应用, 2016, 52(8): 19–24.
Ley R L, Hou L G, Cao J T. Multi-objective particle swarm optimization algorithm based on multistrategy[J]. Computer Engineering and Applications, 2016, 52(8): 19–24. |
| [9] |
杨强大, 张卫军, 牛大鹏.
基于改进PSO的发酵过程同步串联混合建模[J]. 自动化学报, 2015, 41(3): 620–630.
Yang Q D, Zhang W J, Niu D P. Simultaneous series hybrid modeling for fermentation process based on improved particle swarm optimization[J]. Acta Automatica Sinica, 2015, 41(3): 620–630. |
| [10] | Li M Q, Yang S X, Liu X H. Shift-based density estimation for Pareto-based algorithms in many-objective optimization[J]. IEEE Transactions on Evolutionary Computation, 2014, 18(3): 348–365. DOI:10.1109/TEVC.2013.2262178 |
| [11] |
丁晓霖, 侍洪波.
基于自适应网络与动态拥挤距离的多目标粒子群算法及应用[J]. 华东理工大学学报:自然科学版, 2015, 41(2): 173–184.
Ding X L, Shi H B. Multi-objective particle swarm optimization algorithm based on adaptive network and dynamic crowding distance and its application[J]. Journal of East China University of Science and Technology:Nature Science Edition, 2015, 41(2): 173–184. |
| [12] | Jiao L C, Wang H D, Shang R H, et al. A co-evolutionary multi-objective optimization algorithm based on direction vectors[J]. Information Sciences, 2013, 228(7): 90–112. |
| [13] |
王建林, 吴佳欢, 张超然, 等.
基于自适应进化多目标约束的青霉素发酵过程优化[J]. 仪器仪表学报, 2013, 34(12): 2709–2714.
Wang J L, Wu J H, Zhang C R, et al. Optimization of penicillin fermentation process based on self-adaptive evolutionary constrained multi-objective approach[J]. Chinese Journal of Scientific Instrument, 2013, 34(12): 2709–2714. |
| [14] |
耶刚强, 孙世宇, 梁彦, 等.
基于动态粒子数的微粒群优化算法[J]. 信息与控制, 2008, 37(1): 18–27.
Ye G Q, Sun S Y, Liang Y, et al. Particle swarm optimization based on dynamic population size[J]. Information and Control, 2008, 37(1): 18–27. |
| [15] |
乔俊飞, 王超, 魏静.
一种具有局部搜索的自适应粒子群算法[J]. 信息与控制, 2015, 44(4): 385–392.
Qiao J F, Wang C, Wei J. An adaptive particle swarm optimization algorithm with local serach[J]. Information and Control, 2015, 44(4): 385–392. |
| [16] |
杨俊杰, 周建中, 方仍存, 等.
基于自适应网格的多目标粒子群优化算法[J]. 系统仿真学报, 2008, 20(21): 5843–5847.
Yang J J, Zhou J Z, Fang R C, et al. Multi-objective particle swarm optimization based on adaptive grids algorithms[J]. Journal of System Simulation, 2008, 20(21): 5843–5847. |
| [17] | Yang S X, Li M Q, Liu X H, et al. A grid-based evolutionary algorithm for many-objective optimization[J]. IEEE Transactions on Evolutionary Computation, 2013, 17(5): 721–736. DOI:10.1109/TEVC.2012.2227145 |
| [18] | Coello C A C, Pulido G T, Lechuga M S. Handling multiple objectives with particle swarm optimization[J]. IEEE Transactions on Evolutionary Computation, 2004, 8(3): 256–279. DOI:10.1109/TEVC.2004.826067 |
| [19] | Zhang Q, Li H. MOEA/D:A multiobjective evolutionary algorithm based on decomposition[J]. IEEE Transactions on Evolutionary Computation, 2007, 11(6): 712–731. DOI:10.1109/TEVC.2007.892759 |
| [20] | Chen M R, Lu Y Z. A novel elitist multiobjective optimization algorithm:Multiobjective extremal optimization[J]. European Journal of Operational Research, 2008, 188(3): 637–651. DOI:10.1016/j.ejor.2007.05.008 |