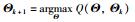江南大学轻工过程先进控制教育部重点实验室, 江苏 无锡 214122
收稿/录用/修回: 2016-10-08/2016-12-20/2017-02-10
基金项目: 国家自然科学基金资助项目(61134007, 61573169);江苏省六大人才高峰项目(2014-ZBZZ-010)
作者简介:
陈家益(1990-),男,硕士生.研究领域为工业过程建模与过程监控.
赵忠盖(1976-),男,博士,教授,博士生导师.研究领域为间歇过程建模与软测量,工业系统监控与诊断.
刘飞(1965-),男,博士,教授,博士生导师.研究领域为先进控制理论及应用,工业系统监控与诊断.
Semi-supervised Robust Probabilistic Partial Least Squares Model and Its Applications to Multi-rate Process Monitoring
Key Laboratory of Advanced Process Control for Light Industry, Ministry of Education, Jiangnan University, Wuxi 214122, China
1 引言
工业发展关系到国民经济命脉,而生产安全和产品质量一直是工业生产过程追求的两大目标.而对过程进行全面有效地监控是确保生产安全和提高产品质量的关键[1-2].多元统计监控方法是一种基于数据驱动的方法,通过对大量过程数据进行分析,判断过程正常运行程度或故障,从而指导实际生产,因此得到广泛应用[3-4].偏最小二乘(partial least squares,PLS)是常用的统计建模方法,将高维数据投影到低维独立的主元空间,并通过对主元空间和噪声空间中统计量的分析,实现对过程的监控[5],但PLS模型没有考虑到主元和残差的概率分布情况. Li等将概率分布引入PLS模型提出概率偏最小二乘(probabilistic partial least squares,PPLS)方法[6],在主元和误差都服从高斯分布的条件下,通过求解极大似然函数得到模型参数.考虑到工业过程中,环境恶劣,离群值遍布,而离群值会严重影响高斯分布的期望和方差,从而导致模型鲁棒性较差,陈等提出鲁棒概率偏最小二乘(robust probabilistic partial least squares,RPPLS)方法[7],采用T分布代替高斯分布,通过调整自由度参数,使模型对于离群数据的鲁棒性更好.
而在实际工业生产过程中,由于过程变量的采样率较高,而一些关键质量变量如产品浓度等,在线直接检测十分困难而且精度不高,需要通过实验室仪器离线分析得到,从而导致多采样率的问题,即输入输出采样时间间隔不一样.针对2采样率过程问题,降采样率方法是一种最简单的方法,即将所有变量的采样率都降低到系统的最低采样率,通过降采样把多采样数据转变成单采样率数据,这样就可以采用一般基于数据驱动的方法建立模型. Facco等[8]提出通过降采样办法建立多采样率过程的动态模型.但是经过降采样率处理后,高采样率的有用数据大量丢失,使得建立的模型准确性大大降低.针对降采样率方法的不足,本文引入半监督学习方法,将完整数据集合H分成少量标记数据H1和大量未标记数据H2,其中H1中一个过程数据对应一个质量数据,H2仅有过程数据而没有质量数据,经过处理后,H1和H2都是样本数一致的数据,然后分别用来建立模型,并通过充分提取大量未标记数据中的隐含信息来提高整个模型的准确性[9-10].
基于文[11],本文在鲁棒PPLS模型中,引入半监督方法,提出一种半监督鲁棒概率偏最小二乘方法,把完整数据集合分成标记数据和未标记数据,然后分别用这两组样本数一致的数据建立鲁棒PPLS模型,并通过充分挖掘未标记数据隐含的有用信息来提高模型的准确性.在建立半监督鲁棒PPLS模型时,考虑到模型参数包括主元分布的参数、自由度、均值和方差均未知,故引入最大期望(EM)算法进行参数估计.更进一步,基于半监督RPPLS模型,通过构建GT2和SPEx和SPEy三个监控指标,将半监督鲁棒PPLS引入到过程监控分别对主元空间、过程变量的噪声空间和质量变量的噪声空间进行监控,判断过程运行状况.最后将半监督鲁棒PPLS和降采样率鲁棒PPLS分别应用在TE过程监控,对比前11种故障监控结果表明,半监督鲁棒PPLS比降采样鲁棒PPLS监控效果更好.
2 RPPLS模型
2.1 T分布表达形式
假设变量x={xn|xn∈RDx}n=1N服从均值为μ,自由度为ν的T分布,其中Dx为数据维数,N为数据样本个数,则x的概率密度函数可以表示如下[12-13]:
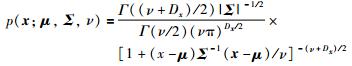
|
(1) |
式(1)中,矩阵Σ是正定矩阵,当ν>1,μ为均值向量,当ν>2时,协方差矩阵等于νΣ/(v-2). Γ(·)表示Gamma函数,其概率密度函数定义为: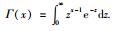 T分布通过调整自由度ν的大小,可以改变拖尾宽度,当ν→∞时,t(μ,Σ,ν)就是N(μ,Σ),所以正态分布可以看成是T分布的一种特殊形式.
T分布通过调整自由度ν的大小,可以改变拖尾宽度,当ν→∞时,t(μ,Σ,ν)就是N(μ,Σ),所以正态分布可以看成是T分布的一种特殊形式.
2.2 RPPLS模型
假设经过归一化后的数据过程变量和输出变量分别为X={xn|xn∈RDx}n=1N,Y={yn|yn∈RDy}n=1N,其中Dx、Dy分别为过程变量和输出变量个数,N为数据样本个数,RPPLS模型可以表示成如下形式:
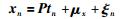
|
(2) |
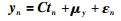
|
(3) |
其中:P∈RDx×K,C∈RDy×K,K<Dx为因子个数,μx,μy分别为X,Y的均值,而噪声满足ξn~t(0,σx2IDx,ν),εn~t(0,σy2IDy,ν),主元满足tn~t(0,IK,ν).
直接用T分布计算十分繁琐,考虑引入中间随机变量un,当un服从伽马分布,则服从T分布的变量x关于un的条件分布x|un服从正态分布.通过引入un可以把T分布转化成正态分布计算,具体转化过程如下:
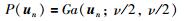
|
(4) |
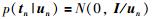
|
(5) |
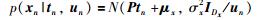
|
(6) |
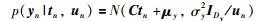
|
(7) |
在RPPLS模型中需要估计的参数有Θ=(P,C,μx,μy,σx2,σy2,ν). EM算法[14]是一种在数据缺失条件下比较有效的参数估计方法,将模型中主元tn和un当作缺失数据,符合EM算法应用条件,故采用EM算法对模型的未知参数进行估计. EM算法的收敛性证明可参考文[15].具体步骤如下:在给定样本X,Y的情况下,可以得到完整数据的似然函数如下:
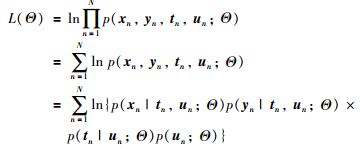
|
(8) |
根据p(tn,un|xn,yn)的期望值可以求出L(Θ)的期望值,然后对L(Θ)求偏导,求出更新值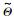 . E步和M步的具体迭代公式可参考文[7],EM算法的具体仿真过程参考算法1.
. E步和M步的具体迭代公式可参考文[7],EM算法的具体仿真过程参考算法1.
2.3 问题分析
考虑到在实际工业生产过程中,过程变量的采样率一般较高,而一些关键质量变量如产品浓度等,在线直接检测十分困难而且精度不高,需要通过实验室仪器离线分析得到,从而导致多采样率的问题.对于多采样率问题,最简单的方法是降采样率,但是经过降采样率处理后的高采样率的有用过程数据大量丢失,使得建立的模型准确性大大降低.而按输入输出数据可以将模型分为监督、半监督、无监督三类.其中数据只有输入{xi}而无输出的模型为无监督方法;对于既有输入{xi}又有输出{yi},并且一一对应的模型为监督方法;而既有输入{xi}又有输出{yj},但是{xi}采样率高、样本点多,{yj}的采样率低、样本点少则为半监督方法.针对多采样率问题,考虑到鲁棒PPLS方法的不足,本文引入半监督方法,提出一种半监督RPPLS算法,将多样率数据分成和采样率一样的标记数据和未标记数据,然后分别用这两组样本数一致的数据建立RPPLS模型,并通过充分挖掘未标记数据隐含的有用信息来提高模型的准确性.
3 半监督RPPLS模型
假设经过归一化后的数据输入变量和质量变量分别为:X={xn|xn∈RDx}n=1K,Y={yn|yn∈RDy}n=1N,其中Dx,Dy分别表示输入变量和质量变量个数,N<K为样本采样数,半监督RPPLS模型可以表示成:
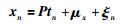
|
(9) |
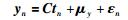
|
(10) |
基于文[11],按照图 1,把完整数据集合H分成标记数据H1和无标记数据H2,而处理后的H1和H2均为样本数一致的数据,可以用传统的方法计算,具体分类可表示如下:
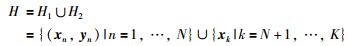
|
(11) |
完整的似然函数也可以分为两部分:
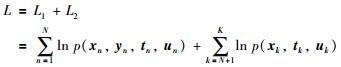
|
(12) |
在半监督RPPLS模型中,未知待估计的参数有Θ=(P,C,μx,μy,σx2,σy2,ν),由于模型中含有隐含变量tn、un,同样采用EM算法进行参数求解.由式(12),将完整似然函数分成两个部分进行求解,一部分类似于求解RPPLS模型参数,另一部分类似求解RPPCA模型参数.
对于L1部分,主元tn关于zn、un的后验分布以及un关于zn的后验分布计算公式为
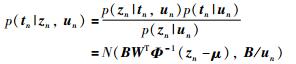
|
(13) |
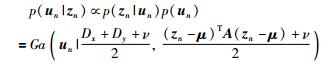
|
(14) |
其中,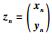 ,μx=(μxn,μxk),
,μx=(μxn,μxk),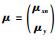 ,
,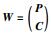 ,
,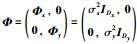 ,A=(WWT+Φ)-1,B=(I+WTΦ-1W)-1.
,A=(WWT+Φ)-1,B=(I+WTΦ-1W)-1.
同理,对于L2部分,主元tk关于xk,uk的后验分布以及uk关于xk的后验分布计算公式为
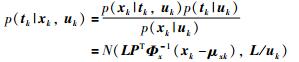
|
(15) |
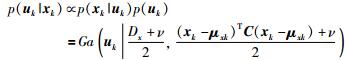
|
(16) |
其中,C=(PPT+Φx)-1,L=(I+PTΦx-1P)-1.
E步:对于L1部分,参考上文RPPLS参数求解过程可以直接得到:
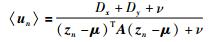
|
(17) |
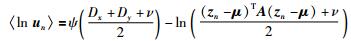
|
(18) |
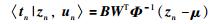
|
(19) |
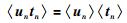
|
(20) |
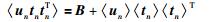
|
(21) |
对于L2部分,类似求解RPPCA模型,参考文[15],可以得到:
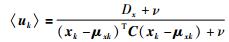
|
(22) |
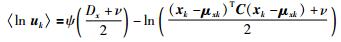
|
(23) |
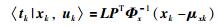
|
(24) |
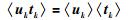
|
(25) |
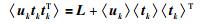
|
(26) |
M步:要求出使〈L(Θ)〉在取得极大值情况下的来更新旧值Θ,即对各需要更新的参数求偏导并使偏导数等于0,可得到的参数迭代公式:
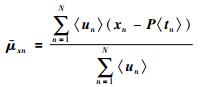
|
(27) |
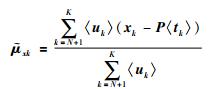
|
(28) |
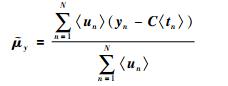
|
(29) |
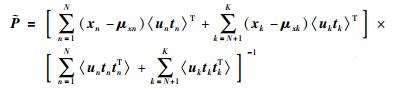
|
(30) |
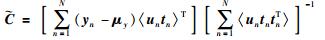
|
(31) |
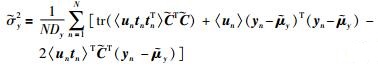
|
(32) |
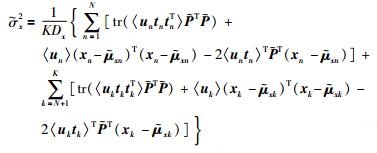
|
(33) |
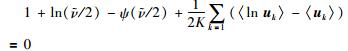
|
(34) |
反复进行E步和M步,直到算法收敛,得到更新值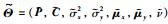 ,半监督RPPLS模型建立完成. EM算法的具体过程参考算法2.
,半监督RPPLS模型建立完成. EM算法的具体过程参考算法2.
4 基于半监督RPPLS模型的监控
下文将提出GT2、SPEx和SPEy三个监控指标分别对主元空间和残差空间进行监控,这3个指标是在主元和残差服从T分布的条件下构建的,不仅能对含离群值数据进行监控,而且可以对多采样率过程进行监控.本文对半监督鲁棒PPLS和降采样鲁棒PPLS的监控,都将采用这3个监控指标.
4.1 对主元空间的监控
主元反映了影响过程变化的主要因素,半监督RPPLS模型通过对主元空间的监控,来判断过程的运行状况.当采集到一个新的样本数据xnew时,可以得到主元期望:
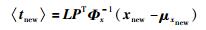
|
(35) |
参考文[17],则GT2定义为
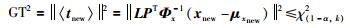
|
(36) |
上式中,χ(1-α,k)2表示自由度为k,显著性水平为α的卡方分布的值,即χ(1-α,k)2为GT2在显著性水平为α的控制线.
4.2 对噪声空间的监控
噪声反映了过程变量与模型的拟合程度,半监督RPPLS模型通过对噪声空间进行监控来判断过程是否出现故障.由于质量变量的采样率比较大,而过程变量采样率比较小,故本文提出SPEx和SPEy两个监控指标分别对过程变量的噪声空间和质量变量的噪声空间进行监控.
4.2.1 对过程变量噪声空间的监控
由于过程变量采样率比较小,故能对过程进行完整监控.当采集到新的输入数据xnew时,参考文[17],监控指标SPEx定义为
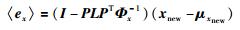
|
(37) |
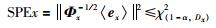
|
(38) |
4.2.2 对质量变量噪声空间的监控
由于质量变量的采样率比较大,故对于质量空间的噪声监控只能在有限的样本点处监控.参考文[18],监控指标SPEy定义为
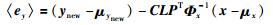
|
(39) |
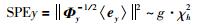
|
(40) |
其中,输入x为经过标记的输入数据,ynew为新的输出数据,而控制线参数的计算参考文[19],具体可由式(41)~式(42)得到:
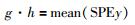
|
(41) |
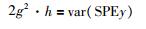
|
(42) |
5 实例验证分析
5.1 数值仿真
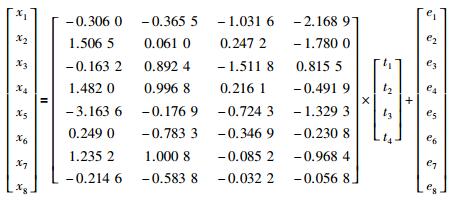
设计一个多采样过程,其中该过程有8个过程变量,3个输出变量,分别有4个隐含变量线性组合而成,关系式为
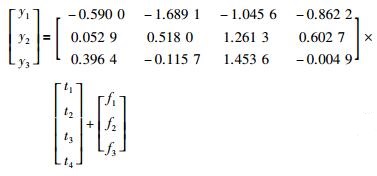
|
(43) |
|
(44) |
其中,隐含变量ti(i=1,…,4)服从标准正态分布;噪声变量ei(i=1,…,8)和fi(i=1,…,3)均服从均值为0,方差为10-4;x1~x8采样间隔为1,共生成1 500组数据,第1 000组数据在变量x3上引入一个幅值为2的阶跃故障;y1~y3采样间隔为10共生成150组数据,其中,前500组过程数据和50组输出数据用于建模,其余1 000组过程数据和100组输出数据用于测试.分别用半监督RPPLS和降采样RPPLS的监控结果如图 2、图 3所示.
由图 2、图 3可得:图 2(a)和图 3(a)均不能检测出故障;而图 2(b)也没能检测出故障,图 3(b)在500时刻超出控制限,所以半监督RPPLS通过SPEx指标能准确检测出故障;同样图 2(c)在680时刻超出控制限,图 3(c)在520时刻超出控制限,所以半监督RPPLS的SPEy指标对故障的产生更敏感.其次,图 2(b)漏报率将近1,而图 3(b)漏报率分别为0.413 2,故半监督RPPLS能有效降低漏报率.
5.2 TE过程仿真
田纳西—伊斯曼过程(TEP)是一个评价监控方法有效性的仿真平台.该过程每仿真一次,可以得到52个测量变量数据,并且可以通过预设定21种故障模式,得到用于监控的故障数据,关于TE过程的详细介绍参考文[20].本文对过程变量采样均为3 min一次,而对质量变量每30 min采样一次,即可以得到10%的标记数据和90%的未标记数据.其中,建模数据是通过每次仿真25 h,每次可以得到500组正常过程变量数据和50组质量变量数据;而监控数据通过是每次运行48 h,每一次运行可以得到960组过程数据和96组质量数据.本文取TE过程的故障1为例,来比较半监督RPPLS和降采样RPPLS的监控效果.
建立半监督RPPLS和降采样RPPLS模型时,参考文[21],选取A进料(流1)、D进料(流2)、E进料(流3)等16个容易检测的过程变量为输入变量,变量详情见表 1,取TE过程变量XMEAS(29)~XMEAS(36)共8个变量为质量变量.由交叉验证方法,本文的主元个数都选取为9个.然后分别将用完整数据建立的半监督RPPLS和仅用10%标记数据建立的降采样RPPLS应用于TE过程监控.本文取故障1为例,得到半监督RPPLS和降采样RPPLS模型的监控图分别如图 4、图 5所示.
表 1 TE过程16个过程变量
Table 1 16 monitoring variables in TE process
| 变量 |
描述 |
| 1 |
A进料(流1) |
| 2 |
D进料(流2) |
| 3 |
E进料(流3) |
| 4 |
总进料(流4) |
| 5 |
再循环流量(流8) |
| 6 |
反应器进料速度(流6) |
| 7 |
反应器温度 |
| 8 |
排放速度(流9) |
| 9 |
产品分离器温度 |
| 10 |
产品分离器压力 |
| 11 |
产品分离器塔底流量(流10) |
| 12 |
气提器压力 |
| 13 |
气提器温度 |
| 14 |
气提器塔底流量(流11) |
| 15 |
反应器冷却水出口温度 |
| 16 |
分离器冷却水出口温度 |
比较图 4、图 5,可得:图 4(a)的GT2值,图 4(b)的SPEx值和图 4(c)的SPEy值分别在采样时刻166、163、170时刻超出控制限,而图 5(a)的GT2值,图 5(b)的SPEx值和图 5(c)的SPEy值分别在采样时刻161、162、170时刻超出控制限,故障是在采样时刻160时引入,这就表明半监督RPPLS模型能更及时准确地判断故障的发生.其次,图 4(a)GT2的漏报率为0.227 2,图 4(b)SPEx的漏报率为0.003 7,图 4(c)SPEy的漏报率为0.864 2,而图 5(a)GT2的漏报率为0.058 7,图 5(b)SPEx的漏报率为0.002 5,图 5(c)SPEy的漏报率为0.839 5,半监督RPPLS漏报率明显低于降采样RPPLS.综上,半监督RPPLS通过提取大量未标记数据中的有用信息,提高了模型的准确性,不仅能更准确检测故障的产生,而且能更有效降低故障的漏报率.
最后分别用降采样RPPLS和半监督RPPLS对TE过程前11种故障模式进行监控,故障详细描述见表 2,故障均在采样时刻160处引入,监控效果如表 3、表 4,表中给出了3个监控指标对11种故障漏报率的监控情况.
表 2 TE过程故障描述
Table 2 Process fault description in TE process
| 故障 |
描述 |
故障类型 |
| 1 |
A/C进料比率,B成分不变(流4) |
阶跃 |
| 2 |
B成分,A/C进料比率不变(流4) |
阶跃 |
| 3 |
D的进料温度(流2) |
阶跃 |
| 4 |
反应器冷却水的入口温度 |
阶跃 |
| 5 |
冷凝器冷却水的入口温度 |
阶跃 |
| 6 |
A进料损失(流1) |
阶跃 |
| 7 |
C存在压力损失—可用性降低(流4) |
阶跃 |
| 8 |
A、B、C进料成分(流4) |
随机变量 |
| 9 |
D的进料温度(流2) |
随机变量 |
| 10 |
C的进料温度(流4) |
随机变量 |
| 11 |
反应器冷却水的入口温度 |
随机变量 |
表 3 基于降采样率RPPLS对11种故障模式的漏报率监控表
Table 3 Monitoring tables for 11 faults based on down-sampling RPPLS
| 故障 |
GT2 |
SPEx |
SPEy |
| 1 |
0.227 2 |
0.003 7 |
0.864 2 |
| 2 |
0.049 9 |
0.025 0 |
0.629 6 |
| 3 |
0.887 6 |
0.927 6 |
0.703 7 |
| 4 |
0.942 6 |
0.950 1 |
0.703 7 |
| 5 |
0.712 9 |
0.739 1 |
0.765 4 |
| 6 |
0.010 0 |
0.013 7 |
0.123 5 |
| 7 |
0.534 3 |
0.665 4 |
0.765 4 |
| 8 |
0.051 2 |
0.056 2 |
0.617 3 |
| 9 |
0.921 3 |
0.925 1 |
0.703 7 |
| 10 |
0.509 4 |
0.277 2 |
0.703 7 |
| 11 |
0.905 1 |
0.902 6 |
0.716 0 |
表 4 基于半监督RPPLS对11种故障模式的漏报率监控表
Table 4 Monitoring tables for 11 faults based on semi-supervised RPPLS
| 故障 |
GT2 |
SPEx |
SPEy |
| 1 |
0.058 7 |
0.002 5 |
0.839 5 |
| 2 |
0.033 7 |
0.017 5 |
0.469 1 |
| 3 |
0.717 9 |
0.957 6 |
0.716 0 |
| 4 |
0.815 2 |
0.953 8 |
0.679 0 |
| 5 |
0.596 8 |
0.786 5 |
0.790 1 |
| 6 |
0.007 5 |
0.012 5 |
0.135 8 |
| 7 |
0.407 0 |
0.732 8 |
0.765 4 |
| 8 |
0.036 2 |
0.054 9 |
0.617 3 |
| 9 |
0.767 8 |
0.958 8 |
0.716 0 |
| 10 |
0.339 6 |
0.253 4 |
0.617 3 |
| 11 |
0.742 8 |
0.930 1 |
0.654 3 |
对比表 3和表 4,半监督RPPLS模型GT2的漏报率在大多数情况低于降采样的GT2的漏报率,原因是通过提取大量未标记数据的有用信息使半监督RPPLS模型的GT2的监控效果得到提高.半监督RPPLS监控指标SPEx并没有比降采样监控指标SPEx监控效果更好.而对于监控指标SPEy,表 3和表 4的SPEy值都接近1,说明SPEy指标监控并不准确,对于降采样RPPLS模型,由于降采样使质量变量的有用数据大量丢失导致监控不准,而对于半监督RPPLS模型,虽然可以通过提取未标记数据的有用信息使半监督RPPLS模型的准确性更好,但大量未标记数据淹没了少量质量变量提供的有用信息导致监控不准确.
6 结论
考虑到多采样率对模型的影响,本文引入半监督方法,提出半监督RPPLS模型,能有效处理输入输出样本数不一致的问题,通过提取大量未标记数据的有用信息使模型的准确性得到了提高.通过降采样RPPLS和半监督RPPLS在TE过程中的监控应用表明:首先,将采样率不一致的完整数据用于建模使建立的模型准确性更高;其次,采用EM算法能够较准确地估计模型的未知参数;最后,本文提出GT2、SPEx、和SPEy三个监控指标,能够准确及时地反映出多采样率过程的故障变化情况.




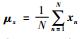 ,
,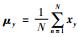 ,σx=1,σy=1
,σx=1,σy=1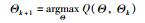

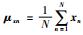 ,
,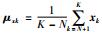 ,
,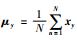 ,σx=1,σy=1,k=0,P=X(:,1:K),C=Y(:,1:K)
,σx=1,σy=1,k=0,P=X(:,1:K),C=Y(:,1:K)