



2. 康考迪亚大学机械、工业与航空工程系, 蒙特利尔 H3G 1M8, 加拿大
2. Department of Mechanical, Industrial and Aerospace Engineering, Concordia University, Montreal H3G 1M8, Canada
0 引言
近年来,随着科技的进步与发展,人们对智慧、健康生活的要求也不断提高.另一方面,人口老龄化情况的逐渐加剧,也使得适合老年人的各类护理服务需求极大地增加.在这些需求的驱动和科技发展的双重促进下,服务机器人市场正在快速增长.目前,服务机器人已经广泛地应用在家庭作业、助老助残、安保、物流等各个领域[1-4],相关的研究也成为了机器人领域的热点问题.与工业机器人的一个本质区别在于,工业机器人的工作环境往往是结构化的,而服务机器人所面临的工作环境绝大多数都是复杂的半结构化或者非结构化的,并且需要协助或与人类共同执行特定任务.因此,具有良好的环境感知能力和自主运动能力是提高服务机器人智能化水平和执行服务任务效率的关键因素.
机器人视觉控制是利用视觉传感器采集到图像信息设计控制律以控制机器人的运动,实现机器人的定位或跟踪.与传统的机器人控制系统相比较,基于视觉的机器人控制系统对于环境变化具有更高的灵活性、更高的精度、更强的鲁棒性等优点.因此,机器人视觉控制技术已广泛地应用在服务机器人研究领域以提高服务机器人对环境的感知能力和自主运动能力.
机器人视觉控制系统的性能依赖于控制回路中所用的图像特征. Mahony等人从理论上分析了图像特征的选取对于整个机器人视觉控制系统动态性能的影响[5].结果表明图像特征的选择尤其是对于基于图像的机器人视觉控制结构,它不仅直接决定控制律和最终系统的稳定性和鲁棒性等性能,而且也是机器人视觉控制系统在复杂环境下能够成功应用的关键因素之一.目前机器人视觉控制研究在结构化的环境中已取得了较好的成果,但所涉及的目标物体模型信息需要事先获取,如需要附加的人工标记[6]或是特殊设计的物体等(如具有明显的孔[7]、明显的角点[8]、特殊的形状[9])且在伺服过程中对光线变化,图像噪声等都有一定的限制条件.为了提高机器人视觉控制系统在自然场景下的定位性能,文[10]提出了一种基于随机树分类器的自然场景下机器人视觉控制方法,有效地提高了遮挡、光照变化等复杂自然场景下机器人的视觉定位性能,但该方法也需要预先学习以获取物体的模型信息.文[11]提出了一种基于轮廓特征的自适应性视觉伺服方法,是一种无需预先学习来获取物体模型信息的视觉定位方法.但该视觉伺服方法针对不同的未知视觉定位目标物体时,需要提前获取目标轮廓图像特征信息的先验知识.然而,在很多实际家庭服务场景,存在着机器人拟操作的目标种类繁多、环境复杂多变或目标很难事先训练等“未知”情况.这里的“未知”一方面指被操作物体信息未知,即事先对操作台上所有物体的种类和位置信息未知,而且对操作物体的形状、大小等这样的几何模型先验信息也未知;另一方面也指被操作未知物体所处的场景未知且环境复杂多变.在这种复杂的自然场景下,上述机器人视觉控制方法性能会下降甚至无法工作.因此,选择并提取出具有更好泛化能力的图像特征以鲁棒准确地在复杂自然场景下检测出目标,可以提高整个机器人视觉控制系统的性能.
2006年,Hinton等在Science杂志上首次提出了深度学习的概念[12].深度学习指的是多层的深度神经网络通过模拟人脑的运行机制来对事物的内在信息进行自主的感知与学习,从而实现对输入的高维数据进行有效的特征提取与表达.与传统的人工标记的特征提取方法相比而言,深度学习通过大数据的有效使用可以快速自动地学习到具有更好泛化能力的物体内在特征,这些特征能够在新的训练集中去适应未曾出现的新物体.近年来,深度学习作为一种强有力的自动特征获取方法已广泛应用在图像检索[13]、语音识别[14]、自然语言处理[15]、目标检测[16-19]、机械手抓取[20-22]等领域.文[23]提出了一种基于深度学习的工业分拣机器人快速视觉识别与定位算法,有效地实现了对目标物体鲁棒准确的识别和定位任务.文[24]利用深度学习算法判定最佳的抓取目标,从而依据基于图像的视觉伺服方法,完成对选定目标物体的视觉伺服任务.以上两种视觉伺服方法均可利用深度学习获取泛化性能良好的图像特征,从而提高视觉控制性能,但以上视觉伺服方法仅考虑了单个类别的未知物体或未考虑遮挡、光照变化等复杂情况.
基于此,本文提出了一种基于卷积神经网络(CNN)的机器人对未知物体视觉定位控制策略,实现了机器人对未知物体的自主视觉定位.所提出的视觉定位控制策略的创新点如下:
1) 所提出的定位控制方法无需提前获取操作物体及其所在场景的任何先验知识,且在机器人定位过程中空间始终存在多个物体,仅根据当前采集到的图像信息以控制机器人的运动使之定位到用户在初始帧任意指定的不同类别、不同规则形状的刚体或非刚体目标,是一种有效的机器人对未知物体视觉定位方法.
2) 所提出的定位控制方法对光照变化具有较好的鲁棒性.在MOTOMAN-SV3X六自由度工业机器人上完成的多组光照变化情况下机器人对未知物体定位实验结果表明所提出的方法在光照亮度发生较大变化的情况下仍能准确鲁棒地定位到目标.
1 系统整体框图机器人视觉控制结构一般有两种,即基于位置的视觉控制结构和基于图像的视觉控制结构,其中基于图像的视觉控制结构是最常用的一种视觉控制结构,本文即采用这种视觉控制结构.摄像机安装在机器人末端执行器上,与机器人手爪一起运动.机器人对未知物体的视觉控制任务是指机器人控制系统无需事先获得操作目标的任何模型信息,仅根据当前图像信息就能完成机器人对未知目标的智能感知与定位或跟踪.因此如何在未知的场景中确定和检测出机器人拟操作的目标以及如何设计视觉控制器是实现上述任务的两个关键问题.
为此,本文提出了基于卷积神经网络的机器人对未知物体的视觉定位控制策略,该策略整体框图如图 1所示.算法基本思路是:首先,利用基于卷积神经网络的多目标识别与检测算法对机器人操作台上所有物体进行识别与检测,以获取机器人操作台上所有未知物体的类别属性信息;其次,用户根据多目标识别与检测结果在线随机地选择机器人拟操作的目标物体,此后在整个机器人视觉控制过程中,机器人视觉控制系统利用该识别与检测网络从多个物体中检测出用户所选定的目标物体并计算出当前图像特征,从而实现机器人对未知目标的智能感知;最后,根据图像特征误差,采用滑模控制思想设计视觉控制律以驱动机器人手爪运动,从而完成机器人对未知物体的视觉定位.图 1中,图像特征定义为目标的质心点在图像平面中的坐标,fd表示期望的图像特征,可取为图像平面的中心(如图 1中红色十字交叉点所示);f表示当前的图像特征,即当前图像中用户随机选定的定位目标物体的质心(如图 1中矩形框里面的青色点所示),u表示视觉控制量,即机器人位姿变化量(或称运动速度、包括线速度和角速度).

|
| 图 1 基于卷积神经网络的机器人对未知物体视觉定位控制策略整体框图 Figure 1 Overall diagram of vision-based robot positioning control strategy for unknown objects based on convolutional neural network |
本节将详细介绍整个控制策略的具体实现,主要包括基于卷积神经网络的未知目标检测和视觉控制器的设计两个部分.
2.1 基于卷积神经网络的未知目标检测该模块的主要作用是在机器人视觉控制过程中识别并检测出用户随机选定的定位目标并计算出当前图像特征,整个检测过程如图 2所示.首先,在视觉定位初始帧,机器人控制系统利用已训练好的基于CNN的多目标识别与检测网络模型获取机器人操作台上所有未知物体的类别信息和位置信息;其次,用户根据多目标识别与检测结果随机地选择定位目标.在随后的定位过程中,机器人视觉控制系统利用该网络,从多个物体中检测出用户在定位初始帧任意选定的机器人拟定位目标并计算出当前图像特征,为实现下一步机器人定位到该目标物体做准备.其中,当前图像特征定义为当前图像中目标物体的质心,如图 2中名为“当前图像特征”对应的图像中矩形框里面的青色点所示.

|
| 图 2 基于卷积神经网络的未知目标检测流程 Figure 2 Schematic diagram of unknown object recognition and detection network based on CNN |
其中,基于CNN的多目标识别与检测网络模型采用文[19]提出的Darknet19模型,如图 2中所示.该网络利用WordNet结构将ImageNet分类数据集的前9 000类和COCO检测数据集的80类进行整合,建立了训练样本集——Wordtree,并在该样本集(分类—检测数据集)上联合训练该模型.所采用的联合训练方法的基本思想为:当网络遇到检测图像就进行正常的反向传播,其中对于分类损失只在当前及其路径以上对应的节点类别上进行反向传播;当网络遇到分类图像仅反向传播分类损失.最终,利用联合训练方法得到的网络可以实现9 000多种物体的实时检测,例如,涉及动物,如狗类、海豚类等;交通工具,如汽车类、船类等;食物,如汉堡类等;衣服,领带类等;书,图书类、杂志类等.其用于目标检测的基本思想是:首先,对输入的图像进行卷积和池化得到13×13的卷积特征图;然后,利用区域建议网络(RPN)[17]去预测目标的类别信息和坐标信息,使得目标定位更加精确.由于该网络是基于深度学习的端到端的实时目标检测系统,将目标区域预测和目标类别预测整合于单个神经网络模型中,实现在准确率较高的情况下快速目标检测与识别,更加适合复杂的实际应用环境.因此将该网络应用于机器人视觉控制系统中,可以实现在场景未知且复杂多变,以及在未知物体种类未知且事先未被训练的情况下,对随机指定的目标进行快速、准确的识别与检测.
2.2 视觉控制器的设计滑模控制作为一种非线性控制方法,因其具有设计简单、对系统参数变化和外界扰动不敏感等优点而广泛地应用在机器人、航空航天和伺服系统领域[25].为此本文根据滑模控制器的设计思想,在基于图像的视觉控制框架下,利用2.1节获得的当前图像特征,设计了机器人视觉定位控制器.整个设计过程由两部分组成,即滑模面切换函数设计和滑动模态控制律设计.首先设计滑模面切换函数,目的是使它所确定的滑动模态渐近稳定且具有良好的动态品质;接着设计滑动模态控制律,目的是使系统状态(即图像特征误差)快速到达滑模面并沿着滑模面稳定的趋于期望图像特征,即当前图像特征f与期望图像特征fd重合或小于某个给定的阈值.
为此,可将滑模面切换函数s设计为
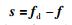
|
(1) |
在机器人视觉控制中,常用式(2)所示的图像雅可比矩阵Jim描述机器人手爪在机器人运动空间中的运动速度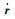
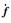
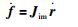
|
(2) |
其中,
据此,可设计出如式(3)所示的机器人视觉滑模定位控制律:
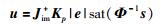
|
(3) |
式中,Jim+是图像雅可比矩阵Jim的伪逆;Φ-1=diag(φi),φi是机器人第i个运动方向的滑模面si边界层厚度,φi>0. sat(·)是饱和函数,定义如下:
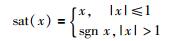
|
(4) |
取李亚普诺夫函数为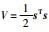
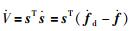
|
(5) |
本文采用眼在手构型,即摄像头固定安装在机器人手爪上,随着机器人的运动而运动.在这种机器人—摄像机构型下,机器人视觉定位和跟踪都被转化为图像特征空间中的定位问题.所以,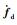
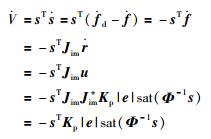
|
(6) |
对于机器人任意第i个运动方向的控制律ui而言,对应的李亚普诺夫函数的导数为
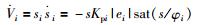
|
(7) |
当|si/φi|≤1,即当|si|≤φi时:
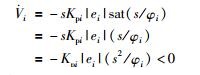
|
当|si/φi|>1, 即当|si|>φi时:
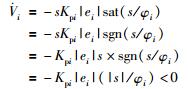
|
所以,对于任意方向上的机器人视觉滑模定位控制律ui,其对应的李亚普诺夫函数的导数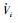
整个实验平台如图 3所示,由MOTOMAN-SV3X六自由度工业机器人、机器人控制柜、CCD摄像头和计算机组成.其中,CCD摄像头安装在机器人手爪上,随着机器人的运动而运动,其内外参数未知.

|
| 图 3 实验平台 Figure 3 Experimental platform |
相关参数设置为:摄像头拍摄的图像分辨率为1024×768像素,图像平面中心点坐标为(512, 384)T.图像平面特征误差定义为e=fd-f,其中,图像特征定义为目标的质心点在图像平面中的坐标,即f=(u, v)T,期望的图像特征坐标fd为图像平面中心点的坐标(512, 384) T.
采用式(3)所示的视觉滑模控制律,相关参数取值为:Kp=diag(0.04, 0.04), Φ=diag(3, 3).
3.2 实验结果及分析为了验证所提出的基于卷积神经网络的机器人对未知目标视觉控制策略的有效性,本文在自然场景下分别针对刚体和非刚体两类目标进行了5组机器人对未知物体的视觉定位实验,其中刚体4组、非刚体1组.实验中,选择了生活中五类较常见的目标物体,即图书、手机(电子设备类)、水瓶(生活用品类)、香蕉(水果类)、teddy bear(玩偶类)作为机器人拟定位的未知物体.所选择物体在定位前均未进行过预训练或其它获取目标物体形状、大小等几何模型信息的工作.定位结果如下:
实验1 无光照变化时机器人对未知刚体目标视觉定位
该实验的目的是为了验证所提方法对未知刚体目标定位的有效性.本次实验分别选择书和手机作为定位目标,完成了2组无光照变化情况下机器人视觉定位实验,其定位过程及结果如图 4所示.首先,利用2.2节所提及的基于卷积神经网络的多目标识别与检测网络对CCD摄像机捕获的初始图像如图 4(a)所示进行识别与检测,获得机器人操作台上所有物体的类别信息(包括图书、手机、水瓶、香蕉、teddy bear,如图 4(b)所示);接着用户根据检测结果人机交互式地选择定位目标(第1组定位实验选择的目标为书,第2组定位实验选择的目标为手机);最后,利用目标检测算法在包含机器人所要操作目标的当前图像中检测出定位目标的图像位置信息,即获得定位目标的当前图像特征(如图 4(c1)和图 4(c2));在此基础上,利用滑模控制器设计定位控制律驱动机器人手爪运动来完成视觉定位任务(如图 4(c1~f1)和图 4(c2~f2)所示,其中图 4(c1)和图 4(c2)分别表示2组定位实验的定位初始帧,图 4(f1)和图 4(f2)分别表示定位结束帧).图中红色十字交叉点表示图像平面中心点坐标(512, 384) T,即期望图像特征fd,矩形框表示定位目标并显示目标类别属性,目标中的青色点表示目标质心,即当前图像特征f=(u, v)T.当蓝色圆圈与红色的十字交叉点接近重合时,表示目标定位过程结束(如图 4(f1)和图 4(f2)所示),即此时图像特征误差接近0.从图 4可以看出本文所提方法可以有效地实现机器人对未知刚体目标的视觉定位.

|
| 图 4 无光照变化情况下未知刚体目标视觉定位过程 Figure 4 Process of robot visual positioning on unknown rigid object without illumination variation |
实验2 光照变化时机器人对未知刚体目标视觉定位
该实验的目的是为了进一步验证所提定位算法对光照变化的鲁棒性.本次实验分别选择水瓶和香蕉作为定位目标,完成了2组光照变化情况下机器人视觉定位实验.定位过程中人为使光照发生了多次变化,如先提高机器人操作的整体光照亮度,然后再人为随机混合调整亮度,直至定位结束,其它情况和实验1完全相同. 2组实验的定位过程分别如图 5(c1~f1)和图 5(c2~f2)所示,其中图 5(d1)和图 5(d2)分别是光线亮度先增加和减小时的定位结果,图 5(e1)和图 5(e2)分别是光线亮度逐渐减小和增加时的定位结果,图 5(f1)和图 5(f2)分别表示定位结束帧.实验结果表明,光照变化情况下所提方法仍能使机器人有效地完成对未知物体的视觉定位任务.

|
| 图 5 光照混合变化时未知刚体的视觉定位 Figure 5 Visual positioning procedure of unknown rigid body with mixture illumination variations |
实验3 机器人对未知非刚体目标视觉定位
该实验的目的是为了验证所提算法对未知非刚体定位的有效性和鲁棒性.与刚体不同,非刚体的模型会因形变而发生较大的改变,从而降低检测性能进而影响整个机器人定位系统的性能.本次实验选择teddy bear毛绒玩具作为非刚体定位目标.在视觉定位过程中人为使teddy bear发生了多次形变,其它情况和实验1完全相同.机器人对非刚体定位目标(teddy bear)的视觉定位过程图如图 6(c~f)所示.从图 6所示的实验结果可以看出,当非刚体目标物体发生较大形变时,机器人仍然可以完成对非刚体的视觉定位任务.

|
| 图 6 未知非刚体姿态发生改变时的视觉定位 Figure 6 Visual positioning procedure of unknown non-rigid body with posture variation |
从图 4~图 6所示的定位过程可以看出,本文所提出的基于卷积神经网络的机器人视觉定位控制策略可以完成在复杂环境下对用户随机选定的未知目标(包括刚体和非刚体)的视觉定位任务,且定位性能对环境光照变化有较强的鲁棒性.
机器人对未知物体视觉定位定量结果如图 7及表 1所示.其中图 7表示无光照变化情况下,刚体目标视觉定位过程中图像平面和机器人运动空间中的定位结果.其中,图 7(a)、7(b)分别表示图像平面的定位轨迹及其误差曲线;图 7(c)、图 7(d)分别表示图像平面u, v方向的定位轨迹及其误差曲线; 图 7(e)表示视觉定位过程中x, y方向的机器人控制量变化曲线;图 7(f)表示机器人手爪在机器人运动空间中的运动轨迹.视觉定位结束后目标在图像平面中的坐标为(511, 385)T,与期望的图像特征坐标即图像平面中心坐标(512, 384)T相比,图像平面定位误差为1. 414像素.

|
| 图 7 无光照变化时机器人对未知刚体的视觉定位结果 Figure 7 Visual positioning results of the unknown rigid body without illumination variation |
| e | mean /mm | std /mm | max |
| x方向 | 0.040 | 0.0267 | 0.8130% |
| y方向 | 0.036 | 0.0295 | 0.8658% |
表 1给出了对应的未知刚体处于机器人工作平面上任意10个不同的位姿时的视觉定位误差,其中mean和std分别指10次定位误差的均值和标准差. max表示最大绝对相对误差,定义为10次定位误差绝对值中最大的定位误差与该方向的运动范围之比.从表 1可以看出,所提定位方法在x、y方向的定位误差的均值分别为0.04 mm和0.036 mm,即定位误差为0.054 mm;最大绝对相对误差和标准差都较小,可见定位算法的定位稳定性较好.
4 结论本文提出了一种基于卷积神经网络的机器人对未知物体视觉定位控制策略.定位任务开始前,机器人系统对未知物体的任何先验知识且所处场景均未知,用户在线随机地从多个物体中选择机器人拟定位的目标物体,此后在整个机器人视觉定位控制过程中,机器人控制系统便可根据当前采集到的视觉信息对任一选定物体进行自主高精度的视觉定位任务.在六自由度工业机器人MOTOMAN-SV3X上进行了5组未知刚体和非刚体的视觉定位实验,实验结果表明所提出的机器人定位控制策略对不同类别、不同规则形状、不同摆放位置的任一未知物体均具有良好的定位性能,定位精度可以达到0.054 mm,是一种有效的机器人对未知物体视觉定位控制策略.
| [1] | Liu X, Zeng B, Ye X. Research on adaptive dunghill cleaning algorithm of the cleaning robot based on wasp colony algorithm[C]//International Conference on Computer, Mechatronics, Control and Electronic Engineering. Piscataway, NJ, USA: IEEE, 2010: 394-397. |
| [2] | Terada S, Luo Z. Wearable EEG-based human intention detection and its application in human care-robot systems[C]//Society of Instrument and Control Engineers of Japan. Piscataway, NJ, USA: IEEE, 2015: 91-94. |
| [3] | Mallik A, Solomon Raju K, Tanwar P. Design of an elementary level surface sweeping and wiping robot for domestic use[C]//International Conference on Devices, Circuits and Communications. Piscataway, NJ, USA: IEEE, 2014: 1-5. |
| [4] | Guizzo E. A robot in the family[J]. Spectrum IEEE, 2015, 52(1): 28–58. DOI:10.1109/MSPEC.2015.6995630 |
| [5] | Mahony R, Corke P, Chaumette F. Choice of image features for depth-axis control in image based visual servo control[C]//Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway, NJ, USA: IEEE, 2002: 390-395. |
| [6] | Lin Y, Sun Y. Robot grasp planning based on demonstrated grasp strategies[J]. International Journal of Robotics Research, 2015, 34(1): 26–42. DOI:10.1177/0278364914555544 |
| [7] | Lazar C, Burlacu A. Performance evaluation of point feature detectors for eye-in-hand visual servoing[C]//Proceeding of the 5th IEEE International Conference on Industrial Informatics. Piscataway, NJ, USA: IEEE, 2007: 497-502. |
| [8] |
孙凤连, 李扬.
工业机器人视觉系统中双目摄像头标定算法研究[J]. 计算机与数字工程, 2015, 43(4): 562–565.
Sun F L, Li Y. Research on calibration algorithm of binocular camera in industrial robot vision system[J]. Computer and Digital Engineering, 2015, 43(4): 562–565. |
| [9] |
辛菁, 刘丁, 徐庆坤.
基于LS-SVR的机器人空间4DOF无标定视觉定位[J]. 控制理论与应用, 2010, 27(1): 77–85.
Xin J, Liu D, Xu Q K. 4DOF non-calibrated vision localization of robot space based on LS-SVR[J]. Control Theory and Application, 2010, 27(1): 77–85. |
| [10] |
董彩霞. 自然场景下的机器人非刚体视觉伺服研究[D]. 西安: 西安理工大学, 2015. Dong C X. Robot non-rigid visual servoing research in natural scene[D]. Xi'an: Xi'an University of Technology, 2015. |
| [11] | Wang H, Yang B, Wang J, et al. Adaptive visual servoing of contour features[J]. IEEE/ASME Transactions on Mechatronics, 2018, 23(2): 811–822. DOI:10.1109/TMECH.2018.2794377 |
| [12] | Hinton G E, Salakhutdinov R R. Reducing the dimensionality of data with neural networks[J]. Science, 2006, 313(5786): 504–507. DOI:10.1126/science.1127647 |
| [13] | Wan J, Wang D, Hoi S C H, et al. Deep learning for content-based image retrieval: A Comprehensive Study[C]//The ACM International Conference. New York, NJ, USA: the ACM, 2014: 157-166. |
| [14] | Yu D, Deng L. Automatic speech recognition:a deep learning approach[M]. Berlin, Germany: Springer, 2014. |
| [15] | Bollegala D. Deep learning for natural language processing(deep learning(6))[J]. Journal of the Japanese Society for Artificial Intelligence, 2014, 29. |
| [16] | Girshick R. Fast R-CNN[C]//IEEE International Conference on Computer Vision. Piscataway, NJ, USA: IEEE, 2015: 1440-1448. |
| [17] | Ren S, Girshick R, Girshick R, et al. Faster R-CNN:Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6): 1137. |
| [18] | Redmon J, Divvala S, Girshick R, et al. You only look once: Unified, real-time object detection[C]//Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2016: 779-788. |
| [19] | Redmon J, Farhadi A. YOLO9000: Better, faster, stronger[J]. IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2017: 6517-6525. |
| [20] |
仲训杲, 徐敏, 仲训昱, 等.
基于多模特征深度学习的机器人抓取判别方法[J]. 自动化学报, 2016, 42(7): 1022–1029.
Zhong X G, Xu M, Zhong X Y, et al. A robot grasping discrimination approach based on multimode feature deep learning[J]. Journal of Automation, 2016, 42(7): 1022–1029. |
| [21] | Wu H, Andersen T T, Andersen N A, et al. Application of visual servoing for grasping and placing operation in slaughterhouse[C]//International Conference on Control, Automation and Robotics. Piscataway, NJ, USA: IEEE, 2017: 457-462. |
| [22] |
杜学丹, 蔡莹皓, 鲁涛, 等.
一种基于深度学习的机械臂抓取方法[J]. 机器人, 2017, 39(6): 820–828, 837.
Du X D, Cai Y H, Lu T, et al. A robotic arm grasping approach based on deep learning[J]. Robot, 2017, 39(6): 820–828, 837. |
| [23] |
伍锡如, 黄国明, 孙立宁.
基于深度学习的工业分拣机器人快速视觉识别与定位算法[J]. 机器人, 2016, 38(6): 711–719.
Wu X R, Huang G M, Sun L N. Fast visual recognition and location algorithm of industrial sorting robots based on deep learning[J]. Robot, 2016, 38(6): 711–719. |
| [24] | Ahlin K, Joffe B, Hu A P, et al. Autonomous leaf picking using deep learning and visual-servoing[J]. IFAC PapersOnLine, 2016, 49(16): 177–183. DOI:10.1016/j.ifacol.2016.10.033 |
| [25] |
刘金琨.
滑模变结构控制MATLAB仿真[M]. 北京: 清华大学出版社, 2012: 15.
Liu J K. Sliding mode variable structure control and MATLAB simulation[M]. Beijing: Tsinghua University Press, 2012: 15. |