



0 引言
2016年3月,“人工智能”一词被写入中国“十三五”规划纲要,2016年10月美国政府发布《美国国家人工智能研究与发展战略规划》文件. Google、Microsoft、Facebook、百度、腾讯、阿里巴巴等各大互联网公司也纷纷加大对人工智能的投入.各类人工智能创业公司层出不穷,各种人工智能应用逐渐改变人类的生活.深度学习是目前人工智能的重点研究领域之一,应用于人工智能的众多领域,包括语音处理、计算机视觉、自然语言处理等.
1943年,McCulloch和Pitts[1]提出MP神经元数学模型. 1958年,第一代神经网络单层感知器由Rosenblatt[2]提出,第一代神经网络能够区分三角形、正方形等基本形状,让人类觉得有可能发明出真正能感知、学习、记忆的智能机器.但是第一代神经网络基本原理的限制打破了人类的梦想,1969年,Minsky[3]发表感知器专著:单层感知器无法解决异或XOR问题;神经网络的特征层是固定的,是由人类设计的,此与真正智能机器的定义不相符. 1986年,Hinton等[4]提出第二代神经网络,将原始单一固定的特征层替换成多个隐藏层,激活函数采用Sigmoid函数,利用误差的反向传播算法来训练模型,能有效解决非线性分类问题. 1989年,Cybenko和Hornik等[5-6]证明了万能逼近定理(universal approximation theorem):任何函数都可以被三层神经网络以任意精度逼近.同年,LeCun等[7-8]发明了卷积神经网络用来识别手写体,当时需要3天来训练模型. 1991年,反向传播算法被指出存在梯度消失问题.此后十多年,各种浅层机器学习模型相继被提出,包括1995年Cortes与Vapnik[9]发明的支持向量机,神经网络的研究被搁置. 2006年,Hinton等探讨大脑中的图模型[10],提出自编码器(autoencoder)来降低数据的维度[11],并提出用预训练的方式快速训练深度信念网[12],来抑制梯度消失问题. Bengio等[13]证明预训练的方法还适用于自编码器等无监督学习,Poultney等[14]用基于能量的模型来有效学习稀疏表示.这些论文奠定了深度学习的基础,从此深度学习进入快速发展期. 2010年,美国国防部DARPA计划首次资助深度学习项目. 2011年,Glorot等[15]提出ReLU激活函数,能有效抑制梯度消失问题.深度学习在语音识别上最先取得重大突破,微软和谷歌[16-17]先后采用深度学习将语音识别错误率降低至20%~30%,是该领域10年来最大突破. 2012年,Hinton和他的学生将ImageNet[18]图片分类问题的Top5错误率由26%降低至15%[19],从此深度学习进入爆发期. Dauphin等[20]在2014年,Choromanska等[21]在2015年分别证明局部极小值问题通常来说不是严重的问题,消除了笼罩在神经网络上的局部极值阴霾.深度学习发展历史如图 1所示. 图 1中的空心圆圈表示深度学习热度上升与下降的关键转折点,实心圈圈的大小表示深度学习在这一年的突破大小.斜向上的直线表示深度学习热度正处于上升期,斜向下的直线表示深度学习热度处于下降期.

|
| 图 1 深度学习发展历史 Figure 1 The history of deep learning |
深度学习其实是机器学习的一部分,机器学习经历了从浅层机器学习到深度学习两次浪潮[22].深度学习模型与浅层机器学习模型之间存在重要区别.浅层机器学习模型不使用分布式表示(distributed representations)[23],而且需要人为提取特征,模型本身只是根据特征进行分类或预测,人为提取的特征好坏很大程度上决定了整个系统的好坏.特征提取需要专业的领域知识,而且特征提取、特征工程需要花费大量时间.深度学习是一种表示学习[24],能够学到数据更高层次的抽象表示,能够自动从数据中提取特征[25-26].而且深度学习里的隐藏层相当于是输入特征的线性组合,隐藏层与输入层之间的权重相当于输入特征在线性组合中的权重[27].另外,深度学习的模型能力会随着深度的增加而呈指数增长[28].
1 基本网络结构 1.1 多层感知器多层感知器(multilayer perception,MLP)[2]也叫前向传播网络、深度前馈网络,是最基本的深度学习网络结构. MLP由若干层组成,每一层包含若干个神经元.激活函数采用径向基函数的多层感知器被称为径向基网络(radial basis function network).多层感知器的前向传播如图 2所示.

|
| 图 2 多层感知器的前向传播 Figure 2 The forward propagation of MLP |
MLP的前向传播公式如式(1)、式(2)所示:
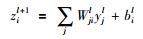
|
(1) |
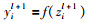
|
(2) |
其中,yjl是第l层的第j个神经元的输出,zil+1是第l+1层的第i个神经元被激活函数作用之前的值,Wjil是第l层的第j个神经元与第l+1层的第i个神经元之间的权重,bil是偏置,f(·)是非线性激活函数,常见的有径向基函数、ReLU、PReLU、Tanh、Sigmoid等.
如果采用均方误差(mean squared error),则损失函数为
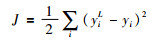
|
(3) |
其中,yiL是神经网络最后一层第i个神经元的输出,yi是第i个神经元的真实值.神经网络训练的目标是最小化损失函数,优化方法通常采用批梯度下降法.
1.2 卷积神经网络卷积神经网络(convolutional neural network,CNN)[29]适合处理空间数据,在计算机视觉领域应用广泛.一维卷积神经网络也被称为时间延迟神经网络(time delay neural network),可以用来处理一维数据. CNN的设计思想受到了视觉神经科学的启发,主要由卷积层(convolutional layer)和池化层(pooling layer)组成.卷积层能够保持图像的空间连续性,能将图像的局部特征提取出来.池化层可以采用最大池化(max-pooling)或平均池化(mean-pooling),池化层能降低中间隐藏层的维度,减少接下来各层的运算量,并提供了旋转不变性.卷积与池化操作示意图如图 3所示,图中采用3×3的卷积核和2×2的pooling.

|
| 图 3 卷积与池化操作示意图 Figure 3 The illustration for convolution and pooling |
最早期的卷积神经网络模型是LeCun等[29]在1998年提出的LeNet-5,其结构图如图 4所示.输入的MNIST图片大小为32×32,经过卷积操作,卷积核大小为5×5,得到28×28的图片,经过池化操作,得到14×14的图片,然后再卷积再池化,最后得到5×5的图片.接着依次有120、84、10个神经元的全连接层,最后经过Softmax函数作用,得到数字0~9的概率,取概率最大的作为神经网络的预测结果.随着卷积和池化操作,网络越高层,图片大小越小,但图片数量越多.

|
| 图 4 LeNet-5结构图 Figure 4 The structure of LeNet-5 |
CNN提供了视觉数据的分层表示,CNN每层的权重实际上学到了图像的某些成分,越高层,成分越具体. CNN将原始信号经过逐层的处理,依次识别出部分到整体.可以对CNN进行可视化来理解CNN[30]:CNN的第二层能识别出拐角、边和颜色;第三层能识别出纹理、文字等更复杂的不变性;第四层能识别出狗的脸、鸟的腿等具体部位;第五层能识别出键盘、狗等具体物体.比如说人脸识别,CNN先是识别出点、边、颜色、拐角,再是眼角、嘴唇、鼻子,再是整张脸. CNN容易在FPGA等硬件上实现并获得加速[31];CNN同一卷积层内权值共享,都为卷积核的权重. CNN的局部连接、权值共享、池化操作等特性减少了模型参数[32],降低了网络复杂性,也提供了平移、扭曲、旋转、缩放不变性.
1.3 循环神经网络循环神经网络(recurrent neural networks,RNN)[4]适合处理时序数据,在语音处理、自然语言处理领域应用广泛,人类的语音和语言天生具有时序性. RNN及其展开图如图 5所示.

|
| 图 5 RNN及其展开图 Figure 5 RNN and its unfolding |
RNN的前向传播公式如式(4)~(6)所示:
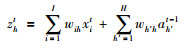
|
(4) |
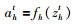
|
(5) |
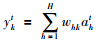
|
(6) |
其中,xit是t时刻输入层的第i个神经元,ah′t-1是t-1时刻隐藏层的第h′个神经元,zht是t时刻隐藏层第h个神经元被激活函数作用之前的值,ykt是t时刻输出层的第k个神经元,wih、wh′h、whk 分别是输入层与隐藏层、隐藏层与隐藏层、隐藏层与输出层之间的权重,fh(·)是非线性激活函数.
RNN将上一时刻隐藏层的输出也作为这一时刻隐藏层的输入,能够利用过去时刻的信息,即RNN具有记忆性. RNN在各个时间上共享权重,大幅减少了模型参数.但RNN训练难度依然较大,因此Sutskever等[33]和Pascanu等[34]都对RNN的训练方法进行了改进.
2 网络结构改进 2.1 卷积神经网络改进ImageNet[18]比赛(ImageNet large scale visual recognition competition,ILSVRC)极大促进了卷积神经网络的发展,不断有新发明的卷积神经网络刷新了ImageNet成绩.从2012年的AlexNet[19],到2013年的ZF Net[30],2014年的VGGNet[35]、GoogLeNet[36],再到2015年的ResNet[37],网络层数不断增加,模型能力也不断增强. AlexNet第一次展现了深度学习的强大能力,ZF Net是可视化理解卷积神经网络的结果,VGGNet表明网络深度能显著提高深度学习的效果,GoogLeNet第一次打破了卷积层池化层堆叠的模式,ResNet首次成功训练了深度达到152层的神经网络. CNN应用于物体检测的主流方法是R-CNN[38]及其之后的改进Fast R-CNN[39]、Faster R-CNN[40]、Mask R-CNN[41].改进的过程其实是用深度学习模型来替代浅层机器学习模型的过程,实现端到端的训练,速度也越来越快.另外,网中网结构[42]创新性地提出在网络里嵌套网络的想法;空间变换网络[43]说明模型效果的提升不一定需要改变网络结构,还可以通过对输入数据进行变换.
1) AlexNet. Hinton为了验证深度学习的有效性,2012年参加ILSVRC并取得第一名,所用到的神经网络模型被称为AlexNet. AlexNet网络包含5层卷积层、max-pooling层和dropout层,接着连接3层全连接层,最后输出层有1 000个神经元,对应1 000个分类,经过Softmax函数作用后得到每一类的概率. AlexNet采用平移、翻转、截取图片一部分等方式来增加训练数据,用dropout来防止过拟合,用带有动量和权重衰减的批梯度下降方法来训练模型. AlexNet用两块GPU并行训练了6天,而且采用ReLU作为激活函数比用Tanh训练时间缩短了6倍. AlexNet所采用的这一系列技术现在仍然被广泛使用.
2) ZF Net. ZF Net是ILSVRC 2013冠军,错误率为11.2%,ZF Net可以认为是AlexNet的微调,网络层数仍为8. Zeiler和Fergus利用反卷积网络对CNN进行可视化来理解CNN每一层的作用,可视化帮助找到了比AlexNet效果更好的网络结构ZF Net. ZF Net所需的训练数据更少,AlexNet用1 500万张图片来训练模型,而ZF Net只用了130万张图片. AlexNet第一层卷积核为11×11,而ZF Net为7×7,卷积核变小使得ZF Net在第一层能保留更多的相关信息.
3) VGGNet. Simonyan等逐次在AlexNet中增加卷积层,比较6种不同深度的网络,研究网络深度的影响.结果表明神经网络越深,效果越好,当增加到16、19层时,效果提升明显,19层的网络被称为VGG-19. VGGNet严格采用3×3的卷积核,步长(stride)和填补(padding)都为1;采用2×2的max-pooling,步长为2.相比于ZF Net 7×7的卷积核,VGGNet卷积核大小只有3×3,使得模型参数更少,而且连续两层的卷积层使其有7×7卷积核的效果,之后人们通常也使用3×3的卷积核. VGGNet模型用Caffe来实现,利用图片抖动来增加训练数据,在图片分类和物体定位任务方面都有很好的效果.
4) GoogLeNet. GoogLeNet是ILSVRC 2014冠军,top 5错误率为6.7%,其网络层数为22层. GoogLeNet表明CNN不一定是要将卷积层、池化层依次堆叠起来. GoogLeNet采用Inception模块,模块里的卷积层、池化层是并行的,所以不用选择这一层是用卷积层还是池化层.在Inception模块的最后不直接将所有神经元“拉直”排成一排,而是采用池化将7×7×1 024变成1×1×1 024,参数量减少到1/49,GoogLeNet总的参数量只有AlexNet的1/12.使用训练好的模型对图片进行分类时,对同一张图片的多张变形图片输出Softmax概率后求平均作为此图片的概率.
5) 深度残差网络(ResNet). ResNet是ILSVRC 2015冠军,同一网络赢得图片分类、物体定位、物体检测三项任务冠军,图像分类任务错误率为3.57%,超过人类错误率5.1%. ResNet网络层数达到152层,甚至1 000层.深层网络有梯度消失的问题,ResNet在两层或多层之间直接加上线性连通通路,即构成了残差模块,保证梯度能通过线性通路传到底层,也使得输入层的信息能直接保留到后面网络层.
6) R-CNN. Girshick等提出R-CNN用于完成计算机视觉中的物体检测任务.物体检测目标是将图片中所有物体用方框框出来,此任务可以分成两个子任务,首先是生成方框将物体框出来,然后对框出来的物体进行分类判断是具体哪个物体. R-CNN采用选择性搜索(selective search)方法生成大约2 000个方框,用已训练好的CNN比如AlexNet对每一个方框内的图片提取出特征,再将特征放进SVM进行分类,同时将特征放入回归器中得到更精确的候选方框.
7) Fast R-CNN. Fast R-CNN将R-CNN中CNN提取特征、SVM分类、回归这三个过程放在一起,形成端到端整体的模型,速度和准确率都得到提升. Fast R-CNN的输入数据是整张图片和若干方框.首先用若干卷积层、池化层处理整张图片得到特征图(feature map);用兴趣区域池化层(region of interest pooling layer)处理每个方框得到固定大小的特征图.然后接若干全连接层,最后同时输出是某个类别的概率、确定每个类的方框的4个值.
8) Faster R-CNN. Faster R-CNN首先用卷积层、池化层处理整张图片得到特征图,在此特征图上用region proposal network来生成方框,其它操作跟Fast R-CNN一样.即Faster R-CNN将生成方框的方法也换成了深度学习模型,并由原来在整张图上生成改成在更小的特征图上生成,使得模型训练速度进一步加快.
9) Mask R-CNN. Mask R-CNN在Faster R-CNN基础上增加语义分割的并行分支,在原来生成方框、分类、回归任务基础上增加分割任务,能同时实现物体检测和语义分割. Mask R-CNN的基础网络使用ResNeXt-101和FPN(feature pyramid network)[44].语义分割任务的误差由基于单像素Softmax多项式交叉熵变成了基于单像素Sigmoid二值交叉熵. Mask R-CNN加入了RoIAlign层,相当于对特征图进行插值.
10)网中网结构(network in network,NIN).网中网结构用微型神经网络比如多层感知器,来代替CNN中的卷积核,形成了神经网络里嵌套着微型神经网络的结构.因为已经用微型网络进行了复杂的局部建模,所以CNN中最后的全连接层可以由全局mean-pooling来代替.这使得模型参数大大减少,防止了过拟合,也增加了可解释性,NIN的参数有2 900万个,是AlexNet的1/10.
11)空间变换网络(spatial transformer networks,STNs).空间变换网络通过变换输入的图片来提升准确率,而不是通过改变网络结构. STNs里主要包含空间变换模块,其又由本地化网络(localization network)、网格生成器(grid generator)、采样器(sampler)三部分组成. STNs对于输入的图片,先用本地化网络来预测需要进行的变换,然后网格生成器和采样器对图片实施变换,变换得到的图片被放到CNN中进行分类. STNs的鲁棒性很好,具有平移、伸缩、旋转、扰动、弯曲等空间不变性.
12)其它卷积神经网络改进.此外,还有其它卷积神经网络改进,包括deconvolutional networks[45]、stacked convolutional auto-encoders[46]、SRCNN[47]、OverFeat[48]、FlowNet[49]、Mr-CNN[50]、FV-CNN[51]、DeepEdge[52]、DeepContour[53]、deep parsing network[54]、BoxSup[55]、TCNN[56]、3维CNN[57]等.
2.2 循环神经网络改进循环神经网络存在梯度消失或者梯度爆炸问题[58],无法利用过去长时间的信息,例如当激活函数是Sigmoid函数时,其导数是个小于1的数,多个小于1的导数连乘就会导致梯度消失问题. LSTM[59]、分层RNN[60-61]都是针对这个问题的解决方案. RNN一般只能处理时间序列等一维数据,多维RNN[62]被提出来处理图像等多维数据.针对很多自然语言处理任务都需要利用上下文信息,双向RNN[63]通过双向处理同一个序列来利用上下文信息. RNN存在训练算法复杂、计算量大的问题,回声状态网络[64]不需要反复计算梯度就能达到很高的精度,为RNN的训练提供了新思路.循环神经网络缺乏推理功能,无法完成需要推理的任务,神经图灵机[65]与记忆网络[66]通过增加记忆模块来解决此问题.
1) 长短时记忆网络(long short-term memory,LSTM).长短时记忆网络用LSTM单元替代RNN中的神经元,在输入、输出、忘记过去信息上分别加了输入门、输出门、遗忘门来控制允许多少信息通过. LSTM有单元状态(cell state)和隐藏状态(hidden state)两个传输状态,单元状态随时刻改变缓慢,而不同时刻的隐藏状态可能会很不同. LSTM建立了门机制来达到旧时刻输入与新时刻输入之间的权衡,本质是根据训练目标,调整出记忆的重点然后进行整串编码. LSTM能够记住需要长时间记忆的,忘记不重要的,能缓解梯度消失、梯度爆炸问题,在较长的序列上比RNN有更好的表现.
2) GRU(gated recurrent unit). GRU[67]是LSTM的轻量级变体,只有两个门:更新门和重置门.更新门决定保留过去多少信息,以及从输入层输入多少信息;重置门与LSTM里的遗忘门类似. GRU没有输出门,所以总是输出完整状态. GRU在所有的地方使用了更少的连接,参数更少,所以训练速度更容易更快.
3) 分层RNN(hierarchical RNN).分层RNN利用了时间依赖是分层结构化的先验知识,长时间依赖能够由一个变量来表示.分层多尺度RNN(hierarchical multiscale RNN)[61]通过编码不同时间尺度的时间依赖来捕捉序列中潜在的分层结构.分层RNN、分层多尺度RNN都能缓解梯度消失问题.
4) 双向RNN(bidirectional RNN).双向RNN向前、向后双向处理同一个序列,相当于有两个RNN,然后接着同一个输出层.向前和向后隐藏层之间没有连接,避免形成信息回路.比如对于自然语言处理任务,单词的上文跟下文都会对单词有影响,双向RNN就能利用单词的上下文信息.双向RNN能同时捕捉到前后的信息,双向LSTM[68-69]、双向GRU[70]也被证明非常有效.
5) 多维RNN(multi-dimensional RNN). RNN适合处理时间序列等一维数据,多维RNN能够处理多维数据,包括图像、视频、医学成像等.多维RNN的思想是将多维数据按照一定顺序排列成一维数据,进而能用RNN处理,当然这种排列顺序需要保持多维数据的空间连续性.
6) 回声状态网络(echo state network,ESN). ESN将RNN中的隐藏层变成了存储池,存储池内的神经元之间随机连接,存储池即隐藏层不是整齐划一的神经元网络层.输入会回荡在存储池中,就像有回声一样,故此网络被称为回声状态网络. ESN输入层到隐藏层、隐藏层到隐藏层的权重随机初始化后固定不变.模型训练的时候,只更新隐藏层到输出层的权重,即变成了线性回归问题,所以训练速度快.
7) 神经图灵机(neural Turing machines).神经图灵机本质是使用外部存储矩阵来进行交互的RNN,整体系统与图灵机类似,用神经网络的方法建立了“输入纸带到输出纸带的映射”.控制器网络(controller network)通过并行的读写头改变外部存储矩阵的值来读取或写入记忆.控制器网络会接收RNN的输入,也会输出给RNN.
8) 记忆网络(memory networks).记忆网络主要包含记忆单元和输入、生成、输出、应答四个模块.记忆单元其实是一个数组,数组的每一个元素保存一句话的记忆.记忆网络可以回答需要复杂推理的问题[71],实现自动问答.输入的文本被输入模块编码成特征向量,生成模块根据此向量对记忆单元进行读写操作,对记忆进行更新.输出模块会将记忆按照与问题的相关程度加权组合得到输出向量,最终应答模块根据输出向量编码生成问题的答案.神经图灵机与记忆网络都适合完成需要推理与符号处理的任务.
9) 其它循环神经网络改进.其它循环神经网络改进也主要是两个方向,一个是改进网络结构,另一个是额外加入记忆模块.结构方面有:GFRNN[72]、stacked RNN[73]、Tree-Structured LSTM[74]、grid LSTM[75]、segmental RNN[76]、seq2seq for sets[77]等.记忆方面有:neural GPU[78]、pointer network[79]、deep attention recurrent Q-Network[80]、dynamic memory networks[81]等.
2.3 其它改进有些创新能同时改进卷积神经网络和循环神经网络,比如批标准化与attention等.另外有些有意思的应用同时用到了卷积神经网络与循环神经网络.
1) 批标准化(batch normalization).训练过程权重更新会改变网络层输入的分布,导致需要更低的学习率与精细的权重初始化,训练时间也会变长.对每一网络层的输入进行批标准化能保证输入分布的统一,并在一定程度上能替代dropout.批标准化首先被应用于卷积神经网络[82],而后也被应用于循环神经网络[83]中.
2) 基于attention的模型[84].人在看东西时目光会集中于感兴趣的部分,当翻译文章时我们关注当前翻译的那部分,而不是整篇文章,这些都说明人类系统中存在注意力(attention).类似地,attention机制使得深度学习模型能够只集中关注输入数据中最为重要的一部分,相应的模型有基于attention的CNN[85]、基于attention的RNN[86]和基于attention的LSTM[87]. Attention其实是在网络中加入了关注区域的移动、缩放、旋转机制,此采用强化学习来实现.
3) 卷积神经网络与循环神经网络结合.卷积神经网络与循环神经网络结合可以做出很有意思的应用,比如根据图片生成描述文字[88]等.根据图片生成描述文字,首先是用卷积神经网络对图片信息进行编码,得到其固定长度的向量表示.然后用循环神经网络对此向量进行解码,生成图片对应的描述文字.
3 深度学习典型应用 3.1 语音处理深度学习最先在语音处理领域取得突破性进展[16],无论是在标准小数据集上[89]还是大数据集上[17].语音处理领域主要有两大任务:语音识别和语音合成.深度学习广泛应用于语音识别[90]中,Google[91]推出端到端的语音识别系统、百度[92]推出语音识别系统Deep Speech 2. 2016年,微软[93]在日常对话数据上的语音识别准确率达到5.9%,首次达到人类水平.各大公司也都用深度学习来实现语音合成,包括Google[94]、Apple[95]、科大讯飞[96]等. Google DeepMind[97]提出并行化WaveNet模型来进行语音合成,百度[98]推出产品级别的实时语音合成系统Deep Voice 3.
3.2 计算机视觉深度学习被广泛应用于计算机视觉各种任务,包括交通标志检测和分类[99]、人脸识别[100]、人脸检测[101]、图像分类[37]、多尺度变换融合图像[102]、物体检测[41]、图像语义分割[103]、实时多人姿态估计[104]、行人检测[105]、场景识别[106]、物体跟踪[56]、端到端的视频分类[107]、视频里的人体动作识别[108]等.另外,还有一些很有意思的应用,如给黑白照片自动着彩色[109]、将涂鸦变成艺术画[110]、艺术风格转移[111]、去掉图片里的马赛克[112]等.牛津大学和Google DeepMind[113]还共同提出了LipNet来读唇语,准确率达到93%,远超人类52%的平均水平.
3.3 自然语言处理NEC Labs America[114]最早将深度学习应用于自然语言处理领域.目前处理自然语言时通常先用word2vec[115]将单词转化成词向量,其可以作为单词的特征[4].自然语言处理领域各种任务广泛用到了深度学习技术,包括词性标注[81]、依存关系语法分析[116]、命名体识别[117]、语义角色标注[118]、只用字母的分布式表示来学习语言模型[119]、用字母级别的输入来预测单词级别的输出[119]、Twitter情感分析[120]、中文微博情感分析[121]、文章分类[122]、机器翻译[123]、阅读理解[124]、自动问答[71-81]、对话系统[125]等.
3.4 其它在生物信息学方面,深度学习能够被用来预测药物分子的活动[126],预测人眼停留部位[127],预测非编码DNA基因突变对基因表达与疾病的影响[128].金融行业积累了大量的数据,故深度学习在金融方面也有众多应用,包括金融市场预测[129]、证券投资组合[130]、保险流失预测[131]等,也相应涌现出一批金融科技创业公司.另外,基于深度学习的实时发电调度算法[132]能在满足实时发电任务的前提下,使机组总污染物排放量降低,达到节能减排的目的.深度学习还可以诊断电动潜油柱塞泵的故障[133],避免故障事故的发生,有效延长检泵周期.深度学习应用于强非线性、复杂的化工过程软测量建模[134]中也能获得很好的精度.
4 深度学习目前问题及进一步研究方向虽然深度学习使得诸多领域取得突破性进展,但是深度学习仍然存在一些问题,攻克解决这些问题是学者们的进一步研究方向,本文针对这些问题也探讨了相应的可能解决思路.问题被分为训练问题、落地问题、功能问题和领域问题,训练问题指的是深度学习训练时间太长等问题,落地问题指的是限制了深度学习实际落地应用的问题,功能问题指的是深度学习目前还不能很好完成的任务,领域问题指的是针对计算机视觉和自然语言处理特定领域的问题.
4.1 训练问题1) 训练时间太长,需要大量训练计算资源.在WMT′14英语到法语的数据集上,Google[135]用96块NVIDIA K80 GPU需要训练6天来得到基本的机器翻译模型,另外还需要3天来微调进一步改进模型.这还只是训练一次模型,再加上需要调各种超参数,总的训练时间非常长,而且96块K80 GPU成本也非常高.深度学习模型需要的计算资源太多了,训练时间也太长了,需要全新的硬件、算法、系统设计来加速模型的训练.例如硬件方面不只采用具有通用性的GPU,还可以采用高性能低功耗的可编程可配置型FPGA芯片、为了某种特定需求而专门定制的ASIC芯片. Google为TensorFlow深度学习框架专门设计了ASIC芯片TPU及二代Cloud TPU.自动驾驶领域也倾向于采用ASIC芯片,Nvidia发布针对L5级全自动驾驶的AI处理器Drive PX Pegasus.
2) 梯度消失问题,训练难度大.深层模型的训练难度非常大,网络层数太多的模型存在梯度消失问题.激活函数例如Sigmoid函数的导数是个很小的数,多个很小的数连乘之后几乎为0,则梯度无法从输出层传到输入层.可以从训练方法、技巧、网络结构等方面来缓解梯度消失问题.训练方法上:Hinton等[12]提出先预训练后微调的训练方法,先无监督逐层预训练,再用反向传播算法对整个网络进行微调训练,预训练每次只训练一层隐藏层避免了梯度消失问题.技巧上:用ReLU[15]来代替Sigmoid作为激活函数、使用dropout、批标准化(batch normalization)[82],这些技巧都能缓解梯度消失问题.网络结构上:LSTM采用门机制,加了输入门、输出门、遗忘门来控制允许多少信息通过;highway networks[136]加入携带门(carry gate)和转化门(transform gate)使得输出由直接输入和转化后的输入两部分组成;ResNet[37]在在两层或多层之间直接加上线性连通通路,保证梯度能通过线性通路传到底层.
3) 依赖大规模带标签训练数据.深度学习严重依赖大规模带标签数据来训练模型.人工数据标注耗时耗力,代价高昂;某些特定领域如疑难杂症等,几乎不可能收集到足够多的带标签数据.因此无监督学习是深度学习接下来的一个重要研究方向,目前已经有一些成果,包括Goodfellow等[137]提出的生成对抗网络(generative adversarial nets,GANs)、微软[138]提出的新的学习范式对偶学习.
4) 分布式训练问题.深度学习模型在单机上训练时间过长,尤其是当训练数据太多时,而且规模过大的模型也无法放入一台机器里.所以需要进行大规模分布式训练深度学习模型.分布式并行训练可以分为数据并行、模型并行和混合并行.混合并行里同时使用了数据并行和模型并行,例如可以在不同机器间使用数据并行,同一台机器上使用模型并行.数据并行是目前多数分布式系统的首选,各种数据并行方法的区别在于是参数平均法还是更新式方法、是同步更新还是异步更新、是中心化同步还是分布式同步.参数平均法是传输各节点的参数到参数服务器,然后所有参数求平均得到全局参数,更新式方法传输的不是参数,而是参数的更新量.微软[139]提出延迟补偿的异步更新方法,在同步更新与异步更新中寻找合适的平衡,并开源了参数服务器框架Multiverso. Strom[140]去掉中心的参数服务器,平等地在各节点间传输参数更新量,高度压缩节点间的更新使得网络通信减少了3个数量级.
4.2 落地问题1) 对抗性样本攻击. Szegedy等[141]发现深度学习会被对抗性样本攻击,即本来正确分类的图片加上小的扰动能使深度学习模型误判成别的类别.知道神经网络结构的攻击被称为白盒攻击(white box attack);对抗性样本还可以迁移,一个模型产生的对抗性样本也会被另一模型错误分类,此为黑盒攻击(black box attack).对抗性样本攻击说明深度学习并没有那么可靠,Goodfellow等[142]认为这是由于深度学习模型在高维空间中的线性性质导致的.为了防止对抗性样本攻击,可以进行对抗性训练,将对抗性样本跟普通样本都作为训练数据来训练模型,使用对抗目标函数,能使模型更加正则化.
2) 鲁棒性差.即使深度学习的平均准确率很高,但在某些测试用例上的预测效果可能很差.高可靠性系统如无人车,远程外科手术,卫星发射等,不允许出现某个很离谱的结果.故需要提高深度学习的鲁棒性,保证坏的时候不至于太坏,使得深度学习的应用领域更广泛.
3) 太多的超参数.针对实际问题,如何设计一个最适合的深度模型?深度学习有太多的超参数,包括如何进行数据采集、生成、选择、划分;神经网络结构是用MLP、CNN还是RNN;神经网络层数、每层的神经元数量;权重初始化方法;正则项系数(weight decay);动量(momentum)、学习率、learning rate decay、dropout;迭代次数、batch;模型更新规则是用SGD还是Adam;分布式训练结果如何聚合等等.可以用另一个神经网络来学习这些超参数,让神经网络设计变得自动化. Google DeepMind[143]采用Learning to learn算法,用另一个网络来调整学习率,使得收敛更快. Google发布了能自动搜索最优网络结构的Cloud AutoML.韩红桂等[144]提出利用竞争机制来动态增加或删减隐藏层神经元,动态优化神经网络结构.张昭昭等[145]提出多层自适应模块化神经网络结构设计方法.
4) 可解释性差.深度学习模型的可解释性差,是典型的黑箱算法,模型复杂,通常包含上亿个参数.线上应用模型后,如果对某个用户造成严重影响,无法确定是哪个参数出了问题,从而无法针对性地调整某个参数来解决此用户的问题.而且模型的可解释性问题限制了其在医学、自动驾驶、军事、航天等重要领域的应用.可以尝试将深度学习与符号学习、可解释性算法进行结合,使其既有深度学习强大的表达能力,又有一定的可解释性.微软用图学习机(Graph Engine)来统一机器学习与知识图谱. Stanford博士生Wu等[146]将深度学习与可解释性决策树算法结合起来,用树正则化方法来提高深度学习的可解释性.
5) 模型太大.深度学习模型本身非常大,不方便放在GPU中,更不方便在移动端使用.特别对于语言模型来说,词表非常大,输出神经元很多,导致模型非常大.所以需要在保证准确率的前提下,进行模型压缩,将模型变小.模型压缩方法主要有参数修剪和共享[147]、低秩分解[148]、压缩卷积滤波器[149]、知识精炼[150]四类[151].参数修剪和共享是去除对准确率没有提升的冗余参数,根据减少信息冗余或参数空间冗余的方式,参数修剪和共享又可以细分为量化和二进制、剪枝和共享、设计结构化矩阵三类.低秩分解是用矩阵分解或张量分解来评估最具信息量的参数;压缩卷积滤波器是设计特殊结构的卷积滤波器来减少存储和计算的复杂度;知识精炼是提取大型模型里的知识来训练更小更紧凑的模型.
4.3 功能问题1) 不能像人类一样进行小样本学习.深度学习需要大规模的训练数据,样本利用率不高,但是人类的学习只需要极少几个样本.其实小孩在学习过程中,利用了大人传授的知识.目前还缺乏统一的框架向深度学习模型提供领域先验知识.要像人类一样进行小样本学习,可以尝试将深度学习与知识图谱、逻辑推理、符号学习等结合在一起,同时利用好数据与知识.
2) 不能很好完成动态决策性任务.决策性任务会随着时间而改变,是动态的;而且往往与环境有复杂的交互,各种因素互相影响.金融股票预测是个典型的动态决策性任务,同一股票同一价格在不同的时间可能就需要进行相反的买卖操作;一只股票的涨跌会对其他股票产生影响.动态决策性任务内部之间互相博弈,可以尝试将深度学习与博弈论结合来完成动态决策性任务.
3) 不能很好完成逻辑推理任务.深度学习目前只是在图像识别、语音识别等感知层面的任务有较好的表现,缺乏逻辑推理能力,无法很好地完成需要逻辑推理的任务.可以考虑将深度学习与擅长逻辑推理的符号学习、存储了知识的知识图谱结合;另外还可以给深度学习模型增加记忆模块,如神经图灵机[65]与记忆网络[66]等.
4) 不能很好处理已有特征的小数据问题.深度学习由于能够自动提取特征,所以在图像识别等人为很难提取特征的任务上表现很好.但是一些任务如保险用户流失预测等,人工能够很好地提取有效特征,而且训练数据较少.深度学习在这些已有特征的小数据问题上效果还不如GBDT、XGBoost、LightGBM[152]等集成学习算法,甚至不如普通的浅层机器学习算法[153].
5) 无法同时处理多任务.人脑是多才多艺的,能同时识别语音,识别图像,理解文字等.而目前深度学习模型都是针对某一特定任务用特定数据集训练的,训练得到的模型也只能完成这一特定任务.为了能完成多任务,进一步实现通用人工智能,可以尝试将不同功能的神经网络以某种方式连接成更大的神经网络. Google[154]通过稀疏门矩阵将多个多层感知器子网络组合成超大网络,用反向传播同时训练所有子网络.
6) 终极算法.机器学习有五大流派:符号主义、连接主义、进化主义、贝叶斯主义、分析主义,深度学习属于连接主义.深度学习的扩展性很强,可以尝试以深度学习为基础,将其他流派包含进来,形成集成了五大流派的终极算法(master algorithm)[155]. OpenAI[156]发现用进化主义的遗传算法替代反向传播算法来训练深度强化学习能更快收敛. Google[157]开源了概率建模推理库Edward,清华大学[158]开源了贝叶斯深度学习的概率编程库ZhuSuan,Uber和Stanford开源了深度概率编程库Pyro,这些都证明了贝叶斯主义与深度学习可以结合在一起.另外,深度学习还可以跟逻辑回归等广义线性模型结合[131].
4.4 领域问题1) 图像理解问题.深度学习目前在图像识别等感知任务有较好的表现,但在图像理解如视觉关系理解、图片内容问答、视觉注意点预测等方面成果还并不多.视觉关系理解首先需要检测出关键对象,然后预测对象之间的关系.图片内容问答是根据给定的图片,回答相应的问题.视觉注意点预测是对于给定的图片,预测人最感兴趣图片的哪一部分.这些都需要对图像内容有很好的理解,图像理解问题需要学者们的进一步探索.
2) 自然语言处理问题.语言其实是比语音、图像更高级的非自然信号,是完全由人脑产生和处理的符号系统.深度学习在自然语言处理上的效果还不像语音、图像那么显著,但是深度学习是受人脑启发得到的算法,相信深度学习接下来会在自然语言处理领域有更多的成果.
| [1] | McCulloch W S, Pitts W H. A logical calculus of the ideas immanent in nervous activity[J]. Bulletin of Mathematical Biology, 1943, 5(4): 115–133. |
| [2] | Rosenblatt F. The perceptron:A probabilistic model for information storage and organization in the brain[J]. Psychological Review, 1958, 65(6): 386–392. DOI:10.1037/h0042519 |
| [3] | Minsky M L, Papert S A. Perceptrons:An introduction to computational geometry[M]. Cambridge, USA: MIT Press, 1969. |
| [4] | Rumelhart D E, Hinton G E, Williams R J. Learning representations by back-propagating errors[J]. Nature, 1986, 323(6088): 533–536. DOI:10.1038/323533a0 |
| [5] | Cybenko G. Approximation by superpositions of a sigmoidal function[J]. Mathematics of Control Signals and Systems, 1989, 2(3): 17–28. |
| [6] | Hornik K, Stinchcombe M, White H. Multilayer feedforward networks are universal approximators[J]. Neural Networks, 1989, 2(5): 359–366. DOI:10.1016/0893-6080(89)90020-8 |
| [7] | Lecun Y, Boser B, Denker J S, et al. Backpropagation applied to handwritten zip code recognition[J]. Neural Computation, 1989, 1(4): 541–551. DOI:10.1162/neco.1989.1.4.541 |
| [8] | Lecun Y, Boser B, Denker J S, et al. Handwritten digit recognition with a back-propagation network[C]//Annual Conference on Neural Information Processing Systems. Cambridge, USA: MIT Press, 1989: 396-404. |
| [9] | Cortes C, Vapnik V. Support-vector networks[J]. Machine Learning, 1995, 20(3): 273–297. |
| [10] | Hinton G E. What kind of graphical model is the brain?[C]//International Joint Conference on Artificial Intelligence. Burlington, USA: Morgan Kaufmann, 2005: 1765-1775. https://www.mendeley.com/research-papers/kind-graphical-model-brain/ |
| [11] | Hinton G E, Salakhutdinov R R. Reducing the dimensionality of data with neural networks[J]. Science, 2006, 313(5786): 504–507. DOI:10.1126/science.1127647 |
| [12] | Hinton G E, Osindero S, Teh Y W. A fast learning algorithm for deep belief nets[J]. Neural Computation, 2006, 18(7): 1527–1554. DOI:10.1162/neco.2006.18.7.1527 |
| [13] | Bengio Y, Lamblin P, Popovici D, et al. Greedy layer-wise training of deep networks[C]//Annual Conference on Neural Information Processing Systems. Cambridge, USA: MIT Press, 2006: 153-160. https://www.researchgate.net/publication/200744514_Greedy_layer-wise_training_of_deep_networks |
| [14] | Poultney C, Chopra S, Lecun Y. Efficient learning of sparse representations with an energy-based model[C]//Annual Conference on Neural Information Processing Systems. Cambridge, USA: MIT Press, 2006: 1137-1144. https://www.researchgate.net/publication/216792739_Efficient_Learning_of_Sparse_Representations_with_an_Energy-Based_Model |
| [15] | Glorot X, Bordes A, Bengio Y. Deep sparse rectifier neural networks[C]//International Conference on Artificial Intelligence and Statistics. Piscataway, NJ, USA: IEEE, 2011: 315-323. https://www.researchgate.net/publication/319770387_Deep_Sparse_Rectifier_Neural_Networks |
| [16] | Hinton G E, Deng L, Yu D, et al. Deep neural networks for acoustic modeling in speech recognition:The shared views of four research groups[J]. IEEE Signal Processing Magazine, 2012, 29(6): 82–97. DOI:10.1109/MSP.2012.2205597 |
| [17] | Dahl G E, Yu D, Deng L, et al. Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition[J]. IEEE Transactions on Audio Speech & Language Processing, 2011, 20(1): 30–42. |
| [18] | Deng J, Dong W, Socher R, et al. ImageNet: A large-scale hierarchical image database[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2009: 248-255. https://www.researchgate.net/publication/221361415_ImageNet_a_Large-Scale_Hierarchical_Image_Database |
| [19] | Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[C]//Annual Conference on Neural Information Processing Systems. Cambridge, USA: MIT Press, 2012: 1097-1105. http://dl.acm.org/citation.cfm?id=2999257 |
| [20] | Dauphin Y N, Pascanu R, Gulcehre C, et al. Identifying and attacking the saddle point problem in high-dimensional non-convex optimization[C]//Annual Conference on Neural Information Processing Systems. Cambridge, USA: MIT Press, 2014: 2933-2941. https://www.researchgate.net/publication/263011979_Identifying_and_attacking_the_saddle_point_problem_in_high-dimensional_non-convex_optimization |
| [21] | Choromanska A, Henaff M, Mathieu M, et al. The loss surfaces of multilayer networks[C]//International Conference on Artificial Intelligence and Statistics. Piscataway, NJ, USA: IEEE, 2015: 192-204. http://www.oalib.com/paper/4066912 |
| [22] |
余凯, 贾磊, 陈雨强, 等.
深度学习的昨天, 今天和明天[J]. 计算机研究与发展, 2013, 50(9): 1799–1804.
Yu K, Jia L, Chen Y Q, et al. Deep learning:Yesterday, today, and tomorrow[J]. Journal of Computer Research and Development, 2013, 50(9): 1799–1804. DOI:10.7544/issn1000-1239.2013.20131180 |
| [23] | Bengio Y, Delalleau O, Roux N L. The curse of highly variable functions for local kernel machines[C]//Annual Conference on Neural Information Processing Systems. Cambridge, USA: MIT Press, 2006: 107-114. https://www.researchgate.net/publication/221620465_The_Curse_of_Highly_Variable_Functions_for_Local_Kernel_Machines |
| [24] | Bengio Y, Courville A, Vincent P. Representation learning:A review and new perspectives[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(8): 1798–1828. DOI:10.1109/TPAMI.2013.50 |
| [25] | LeCun Y, Bengio Y, Hinton G. Deep learning[J]. Nature, 2015, 521(7553): 436–444. DOI:10.1038/nature14539 |
| [26] | Goodfellow I, Bengio Y, Courville A. Deep learning[M]. Cambridge, USA: MIT Press, 2016. |
| [27] | Bengio Y. Learning deep architectures for AI[J]. Foundations & Trends® in Machine Learning, 2009, 2(1): 1–127. |
| [28] | Montufar G F, Pascanu R, Cho K, et al. On the number of linear regions of deep neural networks[C]//Annual Conference on Neural Information Processing Systems. Cambridge, USA: MIT Press, 2014: 2924-2932. http://www.oalib.com/paper/4044104 |
| [29] | LeCun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278–2324. DOI:10.1109/5.726791 |
| [30] | Zeiler M D, Fergus R. Visualizing and understanding convolutional networks[C]//European Conference on Computer Vision. Cham, Switzerland: Springer International Publishing AG, 2014: 818-833. https://link.springer.com/chapter/10.1007%2F978-3-319-10590-1_53 |
| [31] | Dicecco R, Lacey G, Vasiljevic J, et al. Caffeinated FPGAs: FPGA framework for convolutional neural networks[C]//International Conference on Field-Programmable Technology. Piscataway, NJ, USA: IEEE, 2017: 265-268. https://www.researchgate.net/publication/308804967_Caffeinated_FPGAs_FPGA_Framework_For_Convolutional_Neural_Networks?ev=prf_high |
| [32] |
周飞燕, 金林鹏, 董军.
卷积神经网络研究综述[J]. 计算机学报, 2017, 40(6): 1229–1251.
Zhou F Y, Jin L P, Dong J. Review of convolutional neural network[J]. Chinese Journal of Computers, 2017, 40(6): 1229–1251. DOI:10.11897/SP.J.1016.2017.01229 |
| [33] | Sutskever I. Training recurrent neural networks[D]. Toronto, Canada: University of Toronto, 2013. http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.417.53 |
| [34] | Pascanu R, Mikolov T, Bengio Y. On the difficulty of training recurrent neural networks[C]//International Conference on Machine Learning. New York, NJ, USA: ACM, 2013: 1310-1318. http://www.oalib.com/paper/4063862 |
| [35] | Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[J]. Eprint Arxiv, 2014. |
| [36] | Szegedy C, Liu W, Jia Y, et al. Going deeper with convolutions[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2015: 1-9. http://ieeexplore.ieee.org/xpls/icp.jsp?arnumber=7298594 |
| [37] | He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2016: 770-778. http://www.oalib.com/paper/4016438 |
| [38] | Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2014: 580-587. |
| [39] | Girshick R. Fast R-CNN[C]//International Conference on Computer Vision. Piscataway, NJ, USA: IEEE, 2015: 1440-1448. https://www.researchgate.net/publication/275669302_Fast_R-CNN |
| [40] | Ren S, He K, Girshick R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[C]//Annual Conference on Neural Information Processing Systems. Cambridge, USA: MIT Press, 2015: 91-99. http://europepmc.org/abstract/MED/27295650 |
| [41] | He K, Gkioxari G, Dollár P, et al. Mask R-CNN[C]//International Conference on Computer Vision. Piscataway, NJ, USA: IEEE, 2017: 2980-2988. |
| [42] | Lin M, Chen Q, Yan S. Network in network[J]. Eprint Arxiv, 2013. |
| [43] | Jaderberg M, Simonyan K, Zisserman A. Spatial transformer networks[C]//Annual Conference on Neural Information Processing Systems. Cambridge, USA: MIT Press, 2015: 2017-2025. http://www.oalib.com/paper/4084121 |
| [44] | Lin T Y, Dollár P, Girshick R, et al. Feature pyramid networks for object detection[J]. Eprint Arxiv, 2016. |
| [45] | Zeiler M D, Krishnan D, Taylor G W, et al. Deconvolutional networks[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2010: 2528-2535. https://www.computer.org/csdl/proceedings/cvpr/2010/6984/00/05539957-abs.html |
| [46] | Masci J, Meier U, Cireşan D, et al. Stacked convolutional auto-encoders for hierarchical feature extraction[C]//International Conference on Artificial Neural Networks. Berlin, Germany: Springer, 2011: 52-59. https://link.springer.com/chapter/10.1007%2F978-3-642-21735-7_7 |
| [47] | Dong C, Loy C C, He K, et al. Learning a deep convolutional network for image super-resolution[C]//European Conference on Computer Vision. Cham, Switzerland: Springer International Publishing AG, 2014: 184-199. https://link.springer.com/chapter/10.1007%2F978-3-319-10593-2_13 |
| [48] | Sermanet P, Eigen D, Zhang X, et al. OverFeat: Integrated recognition, localization and detection using convolutional networks[C]//International Conference on Learning Representations. Piscataway, NJ, USA: IEEE, 2014. http://www.oalib.com/paper/4042258 |
| [49] | Dosovitskiy A, Fischer P, Ilg E, et al. FlowNet: Learning optical flow with convolutional networks[C]//International Conference on Computer Vision. Piscataway, NJ, USA: IEEE, 2015: 2758-2766. http://www.oalib.com/paper/4073896 |
| [50] | Liu N, Han J, Zhang D, et al. Predicting eye fixations using convolutional neural networks[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2015: 362-370. http://ieeexplore.ieee.org/xpls/icp.jsp?arnumber=7298633 |
| [51] | Cimpoi M, Maji S, Vedaldi A. Deep filter banks for texture recognition and segmentation[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2015: 3828-3836. http://ieeexplore.ieee.org/document/7299007/ |
| [52] | Bertasius G, Shi J, Torresani L. DeepEdge: A multi-scale bifurcated deep network for top-down contour detection[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2015: 4380-4389. http://www.oalib.com/paper/4067380 |
| [53] | Shen W, Wang X, Wang Y, et al. DeepContour: A deep convolutional feature learned by positive-sharing loss for contour detection[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2015: 3982-3991. https://www.computer.org/csdl/proceedings/cvpr/2015/6964/00/07299024-abs.html |
| [54] | Liu Z, Li X, Luo P, et al. Semantic image segmentation via deep parsing network[C]//International Conference on Computer Vision. Piscataway, NJ, USA: IEEE, 2015: 1377-1385. http://www.oalib.com/paper/4052147 |
| [55] | Dai J, He K, Sun J. BoxSup: Exploiting bounding boxes to supervise convolutional networks for semantic segmentation[C]//International Conference on Computer Vision. Piscataway, NJ, USA: IEEE, 2015: 1635-1643. http://www.oalib.com/paper/4072190 |
| [56] | Nam H, Baek M, Han B. Modeling and propagating cnns in a tree structure for visual tracking[J]. Eprint Arxiv, 2016. |
| [57] | Tran D, Bourdev L, Fergus R, et al. Learning spatiotemporal features with 3D convolutional networks[C]//International Conference on Computer Vision. Piscataway, NJ, USA: IEEE, 2015: 4489-4497. http://www.oalib.com/paper/4067376 |
| [58] | Bengio Y, Simard P, Frasconi P. Learning long-term dependencies with gradient descent is difficult[J]. IEEE Transactions on Neural Networks, 1994, 5(2): 157–166. DOI:10.1109/72.279181 |
| [59] | Hochreiter S, Schmidhuber J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735–1780. DOI:10.1162/neco.1997.9.8.1735 |
| [60] | Hihi S E, Bengio Y. Hierarchical recurrent neural networks for long-term dependencies[C]//Annual Conference on Neural Information Processing Systems. Cambridge, USA: MIT Press, 1995: 493-499. https://www.researchgate.net/publication/2818396_Hierarchical_Recurrent_Neural_Networks_for_Long-Term_Dependencies |
| [61] | Chung J, Ahn S, Bengio Y. Hierarchical multiscale recurrent neural networks[J]. Eprint Arxiv, 2016. |
| [62] | Graves A, Fernández S, Schmidhuber J. Multi-dimensional recurrent neural networks[C]//International Conference on Artificial Neural Networks. Berlin, Germany: Springer, 2007: 549-558. https://link.springer.com/chapter/10.1007/978-3-540-74690-4_56 |
| [63] | Schuster M, Paliwal K K. Bidirectional recurrent neural networks[J]. IEEE Transactions on Signal Processing, 2002, 45(11): 2673–2681. |
| [64] | Jaeger H. The "echo state" approach to analysing and training recurrent neural networks-with an erratum note[R]. Bonn, Germany: German National Research Center for Information Technology GMD Technical Report, 2001. |
| [65] | Graves A, Wayne G, Danihelka I. Neural turing machines[J]. Eprint Arxiv, 2014. |
| [66] | Weston J, Chopra S, Bordes A. Memory networks[J]. Eprint Arxiv, 2014. |
| [67] | Chung J, Gulcehre C, Cho K, et al. Empirical evaluation of gated recurrent neural networks on sequence modeling[J]. Eprint Arxiv, 2014. |
| [68] | Graves A, Schmidhuber J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures[J]. Neural Networks the Official Journal of the International Neural Network Society, 2005, 18(5/6): 602–610. |
| [69] | Thireou T, Reczko M. Bidirectional long short-term memory networks for predicting the subcellular localization of eukaryotic proteins[J]. IEEE/ACM Transactions on Computational Biology & Bioinformatics, 2007, 4(3): 441–446. |
| [70] | Vukotic V, Raymond C, Gravier G. A step beyond local observations with a dialog aware bidirectional GRU network for spoken language understanding[C]//Conference of the International Speech Communication Association. Piscataway, USA: IEEE, 2016: 3241-3244. |
| [71] | Weston J, Bordes A, Chopra S, et al. Towards ai-complete question answering:A set of prerequisite toy tasks[J]. Eprint Arxiv, 2015. |
| [72] | Chung J, Gulcehre C, Cho K, et al. Gated feedback recurrent neural networks[C]//International Conference on Machine Learning. New York, NJ, USA: ACM, 2015: 2067-2075. http://www.oalib.com/paper/4071471 |
| [73] | Hermans M, Schrauwen B. Training and analysing deep recurrent neural networks[C]//Annual Conference on Neural Information Processing Systems. Cambridge, USA: MIT Press, 2013: 190-198. http://papers.nips.cc/paper/5166-training-and-analysing-deep-recurrent-neural-networks |
| [74] | Tai K S, Socher R, Manning C D. Improved semantic representations from tree-structured long short-term memory networks[J]. Eprint Arxiv, 2015. |
| [75] | Kalchbrenner N, Danihelka I, Graves A. Grid long short-term memory[J]. Eprint Arxiv, 2015. |
| [76] | Kong L, Dyer C, Smith N A. Segmental recurrent neural networks[J]. Eprint Arxiv, 2015. |
| [77] | Vinyals O, Bengio S, Kudlur M. Order matters:Sequence to sequence for sets[J]. Eprint Arxiv, 2015. |
| [78] | Kaiser Ł, Sutskever I. Neural gpus learn algorithms[J]. Eprint Arxiv, 2015. |
| [79] | Vinyals O, Fortunato M, Jaitly N. Pointer networks[C]//Annual Conference on Neural Information Processing Systems. Cambridge, USA: MIT Press, 2015: 2692-2700. http://dl.acm.org/citation.cfm?id=2969540&CFID=881154957&CFTOKEN=94800336 |
| [80] | Sorokin I, Seleznev A, Pavlov M, et al. Deep attention recurrent Q-network[J]. Eprint Arxiv, 2015. |
| [81] | Kumar A, Irsoy O, Ondruska P, et al. Ask me anything: Dynamic memory networks for natural language processing[C]//International Conference on Machine Learning. New York, NJ, USA: ACM, 2016: 1378-1387. http://www.oalib.com/paper/4083155 |
| [82] | Ioffe S, Szegedy C. Batch normalization: Accelerating deep network training by reducing internal covariate shift[C]//International Conference on Machine Learning. New York, NJ, USA: ACM, 2015: 448-456. http://www.oalib.com/paper/4071527 |
| [83] | Laurent C, Pereyra G, Brakel P, et al. Batch normalized recurrent neural networks[C]//IEEE International Conference on Acoustics, Speech and SP. Piscataway, NJ, USA: IEEE, 2016: 2657-2661. http://www.oalib.com/paper/4053026 |
| [84] | Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Annual Conference on Neural Information Processing Systems. Cambridge, USA: MIT Press, 2017: 6000-6010. https://www.researchgate.net/publication/317558625_Attention_Is_All_You_Need |
| [85] | Yin W, Schütze H, Xiang B, et al. ABCNN:Attention-based convolutional neural network for modeling sentence pairs[J]. Transactions of the Association for Computational Linguistics, 2016, 4(1): 259–272. |
| [86] | Liu B, Lane I. Attention-based recurrent neural network models for joint intent detection and slot filling[C]//Conference of the International Speech Communication Association. Piscataway, USA: IEEE, 2016: 685-689. |
| [87] | Yang M, Tu W, Wang J, et al. Attention based LSTM for target dependent sentiment classification[C]//AAAI Conference on Artificial Intelligence. Keystone, USA: AAAI, 2017: 5013-5014. |
| [88] | Vinyals O, Toshev A, Bengio S, et al. Show and tell: A neural image caption generator[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2015: 3156-3164. http://www.oalib.com/paper/4066456 |
| [89] | Mohamed A R, Dahl G E, Hinton G. Acoustic modeling using deep belief networks[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2012, 20(1): 14–22. DOI:10.1109/TASL.2011.2109382 |
| [90] | Graves A, Mohamed A R, Hinton G. Speech recognition with deep recurrent neural networks[C]//IEEE International Conference on Acoustics, Speech and SP. Piscataway, USA: IEEE, 2013: 6645-6649. |
| [91] | Chiu C C, Sainath T N, Wu Y, et al. State-of-the-art speech recognition with sequence-to-sequence models[J]. Eprint Arxiv, 2017. |
| [92] | Amodei D, Ananthanarayanan S, Anubhai R, et al. Deep speech 2: End-to-end speech recognition in english and mandarin[C]//International Conference on Machine Learning. New York, NJ, USA: ACM, 2016: 173-182. http://www.oalib.com/paper/4015889 |
| [93] | Xiong W, Droppo J, Huang X, et al. Achieving human parity in conversational speech recognition[J]. Eprint Arxiv, 2016. |
| [94] | Ze H, Senior A, Schuster M. Statistical parametric speech synthesis using deep neural networks[C]//IEEE International Conference on Acoustics, Speech and SP. Piscataway, USA: IEEE, 2013: 7962-7966. https://www.researchgate.net/publication/261230379_Statistical_parametric_speech_synthesis_using_deep_neural_networks |
| [95] | Capes T, Coles P, Conkie A, et al. Siri on-device deep learning-guided unit selection text-to-speech system[C]//Conference of the International Speech Communication Association. Piscataway, USA: IEEE, 2017: 4011-4015. https://www.researchgate.net/publication/319185318_Siri_On-Device_Deep_Learning-Guided_Unit_Selection_Text-to-Speech_System |
| [96] | Liu L J, Chuang Ding Y J, Zhou M, et al. The IFLYTEK system for blizzard challenge[R]. 2017. |
| [97] | Oord A V, Li Y, Babuschkin I, et al. Parallel WaveNet:Fast high-fidelity speech synthesis[J]. Eprint Arxiv, 2017. |
| [98] | Ping W, Peng K, Gibiansky A, et al. Deep voice 3:2000-speaker neural text-to-speech[J]. Eprint Arxiv, 2017. |
| [99] | Zhu Z, Liang D, Zhang S, et al. Traffic-sign detection and classification in the wild[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2016: 2110-2118. https://www.researchgate.net/publication/311610541_Traffic-Sign_Detection_and_Classification_in_the_Wild |
| [100] | Hu G, Yang Y, Yi D, et al. When face recognition meets with deep learning: An evaluation of convolutional neural networks for face recognition[C]//International Conference on Computer Vision. Piscataway, NJ, USA: IEEE, 2015: 142-150. |
| [101] | Yang S, Luo P, Loy C C, et al. Faceness-Net:Face detection through deep facial part responses[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2017, PP(99): 1–14. |
| [102] |
蔺素珍, 韩泽.
基于深度堆叠卷积神经网络的图像融合[J]. 计算机学报, 2017, 40(11): 2506–2518.
Lin S Z, Han Z. Images fusion based on deep stack convolutional neural network[J]. Chinese Journal of Computers, 2017, 40(11): 2506–2518. DOI:10.11897/SP.J.1016.2017.02506 |
| [103] | Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2015: 3431-3440. https://www.researchgate.net/publication/301921832_Fully_convolutional_networks_for_semantic_segmentation?_sg=nhWGyMIeHeDJbI-fzm9Y7poHoJXJ9iKDoEQ8CZ6j7h8qC3EpAFRqOXcl5dZdu4WerYxTecalQqfVvJy6wrc0rg |
| [104] | Cao Z, Simon T, Wei S E, et al. Realtime multi-person 2D pose estimation using part affinity fields[J]. Eprint Arxiv, 2016. |
| [105] | Tian Y, Luo P, Wang X, et al. Deep learning strong parts for pedestrian detection[C]//International Conference on Computer Vision. Piscataway, NJ, USA: IEEE, 2015: 1904-1912. https://www.researchgate.net/publication/300412405_Deep_Learning_Strong_Parts_for_Pedestrian_Detection |
| [106] | Zhou B, Lapedriza A, Xiao J, et al. Learning deep features for scene recognition using places database[C]//Annual Conference on Neural Information Processing Systems. Cambridge, USA: MIT Press, 2014: 487-495. https://www.researchgate.net/publication/279839496_Learning_Deep_Features_for_Scene_Recognition_using_Places_Database |
| [107] | Fernando B, Gould S. Learning end-to-end video classification with rank-pooling[C]//International Conference on Machine Learning. New York, NJ, USA: ACM, 2016: 1187-1196. https://www.researchgate.net/publication/310020983_Learning_End-to-end_Video_Classification_with_Rank-Pooling |
| [108] | Lan Z, Zhu Y, Hauptmann A G, et al. Deep local video feature for action recognition[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2017: 1219-1225. http://ieeexplore.ieee.org/document/8014895/ |
| [109] | Cheng Z, Yang Q, Sheng B. Deep colorization[C]//International Conference on Computer Vision. Piscataway, NJ, USA: IEEE, 2015: 415-423. https://www.researchgate.net/publication/301818846_Deep_Colorization?ev=auth_pub |
| [110] | Champandard A J. Semantic style transfer and turning two-bit doodles into fine artworks[J]. Eprint Arxiv, 2016. |
| [111] | Gatys L A, Ecker A S, Bethge M. Image style transfer using convolutional neural networks[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2016: 2414-2423. |
| [112] | Dahl R, Norouzi M, Shlens J. Pixel recursive super resolution[J]. Eprint Arxiv, 2017. |
| [113] | Assael Y M, Shillingford B, Whiteson S, et al. LipNet:End-to-end sentence-level lipreading[J]. Eprint Arxiv, 2016. |
| [114] | Collobert R, Weston J, Bottou L, et al. Natural language processing (almost) from scratch[J]. Journal of Machine Learning Research, 2011, 12(1): 2493–2537. |
| [115] | Mikolov T, Sutskever I, Chen K, et al. Distributed representations of words and phrases and their compositionality[C]//Annual Conference on Neural Information Processing Systems. Cambridge, USA: MIT Press, 2013: 3111-3119. http://www.oalib.com/paper/4088113 |
| [116] | Weiss D, Alberti C, Collins M, et al. Structured training for neural network transition-based parsing[J]. Eprint Arxiv, 2015. |
| [117] | Lample G, Ballesteros M, Subramanian S, et al. Neural architectures for named entity recognition[J]. Eprint Arxiv, 2016. |
| [118] | He L, Lee K, Lewis M, et al. Deep semantic role labeling: What works and what's next[C]//Annual Meeting of the Association for Computational Linguistics. New York, NJ, USA: ACM, 2017: 473-483. https://www.researchgate.net/publication/318740296_Deep_Semantic_Role_Labeling_What_Works_and_What's_Next |
| [119] | Kim Y, Jernite Y, Sontag D, et al. Character-aware neural language models[C]//AAAI Conference on Artificial Intelligence. Keystone, USA: AAAI, 2016: 2741-2749. https://www.researchgate.net/publication/281312208_Character-Aware_Neural_Language_Models |
| [120] | Severyn A, Moschitti A. Twitter sentiment analysis with deep convolutional neural networks[C]//International Conference on Research on Development in Information Retrieval. New York, NJ, USA: ACM, 2015: 959-962. https://www.researchgate.net/publication/291044875_Twitter_Sentiment_Analysis_with_Deep_Convolutional_Neural_Networks |
| [121] |
何炎祥, 孙松涛, 牛菲菲, 等.
用于微博情感分析的一种情感语义增强的深度学习模型[J]. 计算机学报, 2017, 40(4): 773–790.
He Y X, Sun S T, Niu F F, et al. A deep learning model enhanced with emotion semantics for microblog sentiment analysis[J]. Chinese Journal of Computers, 2017, 40(4): 773–790. |
| [122] | Joulin A, Grave E, Bojanowski P, et al. Bag of tricks for efficient text classification[J]. Eprint Arxiv, 2016. |
| [123] | Gehring J, Auli M, Grangier D, et al. Convolutional sequence to sequence learning[J]. Eprint Arxiv, 2017. |
| [124] | Hermann K M, Kocisky T, Grefenstette E, et al. Teaching machines to read and comprehend[C]//Annual Conference on Neural Information Processing Systems. Cambridge, USA: MIT Press, 2015: 1693-1701. http://www.oalib.com/paper/4083139 |
| [125] | Zhou X, Dong D, Wu H, et al. Multi-view response selection for human-computer conversation[C]//Conference on Empirical Methods in Natural Language Processing. New York, NJ, USA: ACM, 2016: 372-381. https://www.researchgate.net/publication/311990210_Multi-view_Response_Selection_for_Human-Computer_Conversation |
| [126] | Ma J, Sheridan R P, Liaw A, et al. Deep neural nets as a method for quantitative structure-activity relationships[J]. Journal of Chemical Information & Modeling, 2015, 55(2): 263–274. |
| [127] | Liu N, Han J, Zhang D, et al. Predicting eye fixations using convolutional neural networks[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2015: 362-370. https://www.researchgate.net/publication/308868583_Predicting_eye_fixations_using_convolutional_neural_networks |
| [128] | Leung M K, Xiong H Y, Lee L J, et al. Deep learning of the tissue-regulated splicing code[J]. Bioinformatics, 2014, 30(12): i121–i129. DOI:10.1093/bioinformatics/btu277 |
| [129] | Dixon M, Klabjan D, Bang J H. Classification-based financial markets prediction using deep neural networks[J]. Eprint Arxiv, 2016. |
| [130] | Heaton J B, Polson N G, Witte J H. Deep learning for finance:Deep portfolios[J]. Applied Stochastic Models in Business & Industry, 2016, 33(1): 3–12. |
| [131] | Zhang R, Li W, Tan W, et al. Deep and shallow model for insurance churn prediction service[C]//International Conference on Services Computing. Piscataway, NJ, USA: IEEE, 2017: 346-353. https://www.researchgate.net/publication/319854610_Deep_and_Shallow_Model_for_Insurance_Churn_Prediction_Service |
| [132] |
柯余洋, 杨训政, 熊焰, 等.
基于递归神经网络和蚁群优化算法的发电环保调度[J]. 信息与控制, 2017, 46(4): 415–421.
Ke Y Y, Yang X Z, Xiong Y, et al. Power generation dispatching for environmental protection based on recursive neural network and ant colony optimization algorithm[J]. Information and Control, 2017, 46(4): 415–421. |
| [133] |
于德亮, 李妍美, 丁宝, 等.
基于思维进化算法和BP神经网络的电动潜油柱塞泵故障诊断方法[J]. 信息与控制, 2017, 46(6): 698–705.
Yu D L, Li Y M, Ding B, et al. Failure diagnosis method for electric submersible plunger pump based on mind evolutionary algorithm and back propagation neural network[J]. Information and Control, 2017, 46(6): 698–705. |
| [134] |
李军, 桑桦.
基于SCKF的Elman递归神经网络在软测量建模中的应用[J]. 信息与控制, 2017, 46(3): 342–349.
Li J, Sang H. Elman recurrent neural network method based on SCKF algorithm and its application to soft sensor modeling[J]. Information and Control, 2017, 46(3): 342–349. |
| [135] | Wu Y, Schuster M, Chen Z, et al. Google's neural machine translation system:Bridging the gap between human and machine translation[J]. Eprint Arxiv, 2016. |
| [136] | Srivastava R K, Greff K, Schmidhuber J. Training very deep networks[C]//Annual Conference on Neural Information Processing Systems. Cambridge, USA: MIT Press, 2015: 2377-2385. http://www.oalib.com/paper/4049453 |
| [137] | Goodfellow I, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets[C]//Annual Conference on Neural Information Processing Systems. Cambridge, USA: MIT Press, 2014: 2672-2680. https://www.researchgate.net/publication/319770355_Generative_Adversarial_Nets?ev=prf_high |
| [138] | He D, Xia Y, Qin T, et al. Dual learning for machine translation[C]//Annual Conference on Neural Information Processing Systems. Cambridge, USA: MIT Press, 2016: 820-828. https://www.researchgate.net/publication/309606886_Dual_Learning_for_Machine_Translation |
| [139] | Zheng S, Meng Q, Wang T, et al. Asynchronous stochastic gradient descent with delay compensation[C]//International Conference on Machine Learning. New York, NJ, USA: ACM, 2017: 4120-4129. https://www.researchgate.net/publication/308692359_Asynchronous_Stochastic_Gradient_Descent_with_Delay_Compensation_for_Distributed_Deep_Learning |
| [140] | Strom N. Scalable distributed dnn training using commodity gpu cloud computing[C]//Conference of the International Speech Communication Association. Piscataway, USA: IEEE, 2015. |
| [141] | Szegedy C, Zaremba W, Sutskever I, et al. Intriguing properties of neural networks[C]//International Conference on Learning Representations. Piscataway, USA: IEEE, 2014. http://www.oalib.com/paper/4042297 |
| [142] | Goodfellow I J, Shlens J, Szegedy C. Explaining and harnessing adversarial examples[J]. Eprint Arxiv, 2014. |
| [143] | Andrychowicz M, Denil M, Gomez S, et al. Learning to learn by gradient descent by gradient descent[C]//Annual Conference on Neural Information Processing Systems. Cambridge, USA: MIT Press, 2016: 3981-3989. |
| [144] |
韩红桂, 甄博然, 乔俊飞.
动态结构优化神经网络及其在溶解氧控制中的应用[J]. 信息与控制, 2010, 39(3): 354–360.
Han H G, Zhen B R, Qiao J F. Dynamic structure optimization neural network and its applications to dissolved oxygenic (DO) control[J]. Information and Control, 2010, 39(3): 354–360. |
| [145] |
张昭昭, 乔俊飞, 余文.
多层自适应模块化神经网络结构设计[J]. 计算机学报, 2017, 40(12): 2827–2838.
Zhang Z Z, Qiao J F, Yu W. Structure design of hierarchical adaptive modular neural network[J]. Chinese Journal of Computers, 2017, 40(12): 2827–2838. DOI:10.11897/SP.J.1016.2017.02827 |
| [146] | Wu M, Hughes M C, Parbhoo S, et al. Beyond sparsity:Tree regularization of deep models for interpretability[J]. Eprint Arxiv, 2017. |
| [147] | Tran J, Tran J, Tran J, et al. Learning both weights and connections for efficient neural networks[C]//Annual Conference on Neural Information Processing Systems. Cambridge, USA: MIT Press, 2015: 1135-1143. |
| [148] | Denton E L, Zaremba W, Bruna J, et al. Exploiting linear structure within convolutional networks for efficient evaluation[C]//Annual Conference on Neural Information Processing Systems. Cambridge, USA: MIT Press, 2014: 1269-1277. http://www.oalib.com/paper/4080970 |
| [149] | Cohen T, Welling M. Group equivariant convolutional networks[C]//International Conference on Machine Learning. New York, NJ, USA: ACM, 2016: 2990-2999. |
| [150] | Hinton G, Vinyals O, Dean J. Distilling the knowledge in a neural network[J]. Eprint Arxiv, 2015. |
| [151] | Cheng Y, Wang D, Zhou P, et al. A survey of model compression and acceleration for deep neural networks[J]. Eprint Arxiv, 2017. |
| [152] | Ke G, Meng Q, Finley T, et al. LightGBM: A highly efficient gradient boosting decision tree[C]//Annual Conference on Neural Information Processing Systems. Cambridge, USA: MIT Press, 2017: 3149-3157. |
| [153] | Mo T, Zhang R, Li W, et al. An influence-based fast preceding questionnaire model for elderly assessments[J]. Intelligent Data Analysis, 2018, 22(2): 407–437. DOI:10.3233/IDA-163320 |
| [154] | Shazeer N, Mirhoseini A, Maziarz K, et al. Outrageously large neural networks:The sparsely-gated mixture-of-experts layer[J]. Eprint Arxiv, 2017. |
| [155] | Domingos P. The master algorithm:How the quest for the ultimate learning machine will remake our world[M]. New York, USA: Basic Books, a member of the Perseus Books Group, 2015. |
| [156] | Salimans T, Ho J, Chen X, et al. Evolution strategies as a scalable alternative to reinforcement learning[J]. Eprint Arxiv, 2017. |
| [157] | Tran D, Kucukelbir A, Dieng A B, et al. Edward:A library for probabilistic modeling, inference, and criticism[J]. Eprint Arxiv, 2016. |
| [158] | Shi J, Chen J, Zhu J, et al. ZhuSuan:A library for Bayesian deep learning[J]. Eprint Arxiv, 2017. |