



0 引言
小批量、高附加值的间歇过程是现代工业生产的重要生产方式,激烈的市场竞争与环境保护压力,进行间歇过程优化以降低生产成本和稳定产品质量是必然的选择[1-2].相比于连续生产过程,一般地说,间歇过程没有稳定的静态工作点,过程操作的基本方式是确保批次过程跟踪设定操作曲线[3-4],在完成有效的动态控制基础上,优化间歇过程操作曲线成为提高效益的重要手段.随着计算机和传感检测技术的发展,以历史数据为基础的数据驱动型间歇过程优化方法成为新的研究点[5-8].
目前,主要的数据驱动优化方法分为基于实验设计的优化、无模型优化及基于经验模型的优化.相对于实验设计方法的高成本[9]和无模型优化方法短周期且低成本的实验要求[10],基于经验模型(如偏最小二乘模型、人工神经网络模型、支持向量机模型等)的优化方法近几十年来得到较快发展.如为降低模型不确定性影响,黄碧璇等[11]利用批次数据不断修正目标函数和约束条件,实施基于偏最小二乘模型的操作曲线优化. Camacho等[12]将展开的部分最小二乘算法与自整定优化算法结合计算一种梯度,再用批次数据信息更新梯度驱动操作曲线的迭代优化.进一步考虑间歇过程的非线性特性,Li等[13]建立输入数据矩阵的径向基函数网络,对原始输入矩阵与径向基函数网络数据构成的扩展矩阵与输出矩阵进行偏最小二乘分析,根据二次型性能指标迭代优化操作曲线. Zhang等[14]利用核偏最小二乘算法将具有非线性关系的原始数据映射到高维空间,而后用粒子群算法寻优操作曲线.刘毅等[15]用非线性回归的最小二乘支持向量机建模,基于二次性能指标迭代优化操作曲线.
上述基于数据的间歇过程优化方法,均以等长的间歇过程数据为研究前提.而实际间歇过程中,由于各种不确定因素的存在,不同批次生产周期的差异性,使得批次数据不等长成为最常见的问题.即使部分数据轨迹重合,其过程变化特征也不一定相同.目前间歇过程数据同步应用的主要方法有“最短长度法”和动态时间规整方法[16-17].这两种方法主要是从时间与距离信息上进行数据同步,而Frank等[18]提出了一种基于过程“本质时间”的特征轨线数据同步方法,实现数据基于过程内在变化特征的同步.但是该同步方法压缩了过程的时间变化信息,对于存在明显阶段特性变化的间歇过程,整体进行特征轨线同步会引起同步误差.
针对上述问题,本文提出基于特征轨线多阶段融合的不等长间歇过程数据同步方法.运用K均值算法对保留时间变化信息的均值轨线进行阶段划分,再根据欧氏距离最短原则计算各批次特征轨线上点之间的特征差异及对应的阶段节点,进行多阶段数据同步及融合.进一步地,针对同步后的批次数据进行载荷余弦相似度分析,并计算批次间指标增量,以实现基于批次间指标增量修正的操作曲线递推优化.
1 数据同步 1.1 获取特征轨线为了获得基于过程本质时间的特征轨线,将三维批次数据矩阵X3(m×r×k)展开成2维数据矩阵[19]并进行标准化处理,其中k为批次,m为采样点,r为变量数,得到矩阵X(mk×r)进行主成分分析:
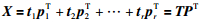
|
(1) |
其中,T(mk×r)=[t1,t2,…,tr]和P(r×r)=[p1,p2,…,pr]分别为得分矩阵(主元)和载荷矩阵,一般前2个主元可以包含过程的大多数信息且2维平面具有很好的可视性,所以本文特征轨线的获取都是在2维主元平面下进行.
当有新批次数据加入时,为避免重新进行数据分解,根据式(2)预估新的特征轨线:
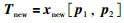
|
(2) |
其中,xnew为新的批次数据;Tnew为xnew的得分矩阵,即特征轨线.
1.2 特征轨线的多阶段融合过程阶段特性的显著变化,使得得分空间中特征轨线也发生明显的轨迹改变,文[18]中整体进行特征轨线同步可能引起同步误差,针对此问题将特征轨线进行阶段划分,在各阶段下同步数据,而后融合为完整的同步特征轨线.本文采用K均值算法[20]对一条均值特征轨线进行阶段划分,以该曲线的阶段节点作为各批次数据阶段节点划分依据,其中均值特征轨线的获取步骤:
1) 计算X中g个批次数据的特征轨线;
2) 选取较短的特征轨线作为同步标准,以保存该批次各采样点间时间变化信息;
3) 根据特征轨线形状进行数据截取,得到同步的g条特征轨线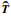
将T*利用K均值算法进行阶段划分:
1) 将T*的坐标集记为{(tpc1w1,tpc2w1)|w1=1,2,…,n1},tpc1w1为第1主元方向下第w1点坐标,tpc2w1为第2主元方向下第w1点坐标,n1为较短批次采样点数,从T*选出h个初始聚类中心记为:(tpc1(1),tpc2(1))1,(tpc1(2),tpc2(2))1,…,(tpc1(h),tpc2(h))1.
2) 第K次迭代中,对T*的各点进行分类:对h个聚类中心,u∈{1,2,…,h},v∈{1,2,…,h},u≠v,若‖Tw1*-(tpc1(v),tpc2(v))K‖ < ‖Tw1*-(tpc1(u),tpc2(u))K‖不等式成立,则Tw1*∈(lpc1(v),lpc2(v))K,其中Tw1*为T*的第w1个点.
3) 根据步骤2)得到的(lpc1(v),lpc2(v))K计算新的聚类中心(tpc1(v),tpc2(v))K+1:

|
(3) |
其中,Qv为(lpc1v,lpc2v)K中的样本数.
4) 若(tpc1(v),tpc2(v))K+1=(tpc1(v),tpc2(v))K对于h个聚类中心成立则终止;否则,返回步骤2).
将得到的均值特征轨线h-1个阶段节点构成的坐标集记为{Te*},e∈{1,2,…,h-1},批次数据特征轨线根据欧氏距离最短原则,找到特征轨线上距离{Te*}最近的点作为阶段节点.
为判断h个阶段下特征轨线上各点的特征差异,定义距离差异矩阵:
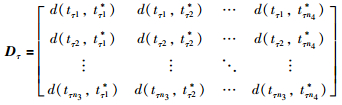
|
(4) |
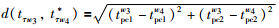
|
(5) |
其中,Dτ(τ=1,2,…,h)为第τ个阶段下的距离差异矩阵,d(tτw3,t*τw4)为计算点tτw3与点t*τw4之间的欧氏距离. tτw3=(tpc1w3,tpc2w3)(w3=1,2,…,n3)为第τ阶段下批次数据特征轨线上第w3个点的坐标,n3为第τ阶段下的坐标点数;t*τw4=(tpc1w4,tpc2w4)(w4=1,2,…,n4)为第τ阶段均值特征轨线上第w4个点坐标,n4为第τ阶段下的坐标点数.若两个点的特征越相似或者越接近,其值越接近0,反之越大.
将[t1,t2]下同步的h段特征轨线融合为一条完整的特征轨线,再与[t3,t4,…,tr]下对应点的坐标合并为全维度的矩阵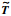
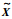

|
| 图 1 基于特征轨线的多阶段融合数据同步方法流程图 Figure 1 Flow chart of a data synchronization approach based on characteristic trajectory′s multistage fusion |
间歇过程的优化本质上是一个非线性优化问题,利用分段离散化的方法[21-22],将原非线性优化问题转化为线性优化问题:
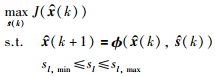
|
(6) |
其中,J为性能指标函数,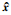
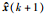
高维批次数据矩阵X蕴含丰富过程信息,建立一种仅利用数据信息无需构造模型的优化方法是一种新思考方向.在主元分析中,载荷表示过程变量的变异方向,根据主元贡献率选择的少数几个载荷元素就可以描述原始维度变量间的相关性信息[23],本文将X分段离散化后得到的时段变量矩阵与对应的指标矩阵构成扩展矩阵,记为Z(k×(j+1)),Z为已标准化处理后的矩阵,对Z进行主成分分析,通过计算载荷的余弦相似度得到各时段变量与指标之间的作用关系对操作曲线进行优化[24]:
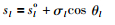
|
(7) |
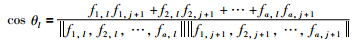
|
(8) |
其中,slo是初始操作曲线值;σl是时段变量的标准差;cos θl为时段变量与指标变量的夹角余弦值;fc1,l(c1=1,2,…,a)为Z主成分分析得到的载荷矩阵F前a列中的第l行第c1列元素,fc1,j+1为F前a列中的第j+1行第c1列元素,a的值根据主元贡献率选择[25].
进一步对操作曲线进行递推修正[24]:
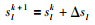
|
(9) |
其中,slk+1为前k+1批次数据得到的操作曲线值,slk为前k批次数据得到的操作曲线值,Δsl为对式(7)的sl求得的差分.文[24]中采用递推公式(9)更新操作曲线,未考虑新批次数据质量对曲线递推更新的影响.如由于不确定性因素的影响,新采集批次数据下的指标量较上一批次用于更新操作曲线的数据下的指标量低,使得更新后的操作曲线对应的预测指标量可能变差,从而影响优化效果.为了解决此问题,本文在操作曲线递推式(9)中,进一步引入指标增量修正项:
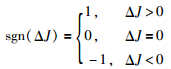
|
(10) |
其中,ΔJ=Jk+1-Jk为第k+1批次与第k批次间指标变化量;sgn(·)为符号函数,sgn(ΔJ)为第k+1批次相对于第k批次的指标变化情况,表征更新操作曲线的k+1批次数据质量.
式(11)为根据第k+1批次数据计算slk的校正量sgn(ΔJ)·Δsl以更新slk+1,sgn(ΔJ)·Δsl表征依据第k+1批次数据质量对Δsl的方向进行调整,使得低指标量批次数据更新后的操作曲线,其对应的预测指标量在第k-1批次预测值左右,从而将低质量批次数据对指标优化的影响限定在可控范围.
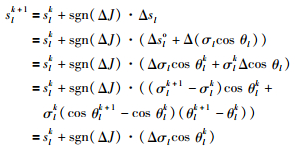
|
(11) |
其中,σlk+1、θlk+1和cos θlk+1为前k+1批次数据得到的标准差、时段变量与指标变量之间的夹角及其夹角余弦值;σlk、θlk和cos θlk为前k批次数据得到的标准差、时段变量与指标变量之间的夹角及其夹角余弦值;σlkΔcos θl值的变化相对于Δσlcos θlk可以忽略不计;slo为常数,则Δslo=0.式(11)中相应变量的计算公式为
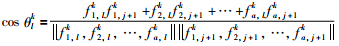
|
(12) |
其中,fkc1,l、fkc1,j+1分别为根据前k批次数据得到的fc1,l、fc1,j+1递推式.
标准差递推式[25]:
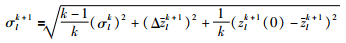
|
(13) |
其中,σlk+1为前k+1批次数据的标准差;zlk+1(0)为第k+1批次原始批次数据,zlk+1为前k+1批次数据的均值;Δzlk+1=zlk+1-zlk为前k+1批次数据均值与前k批次数据均值之间的增量.
均值递推式[25]:
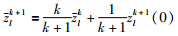
|
(14) |
其中,zlk为前k批次的均值.
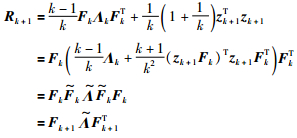
|
(15) |
其中,Rk+1为前k+1批次数据的自相关矩阵,Fk为Rk正交分解的载荷矩阵,Rk为前k批次数据的自相关矩阵,Λk为Rk正交分解的对角矩阵,zk+1为第k+1批标准化后的批次数据,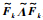
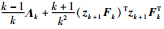
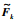
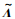
注1 如式(11)不考虑指标增量修正项,则退化为slk+1=slk+Δσlcos θlk.若Jk < Jk-1,式(11)对应的Δslk为-Δslk,使slk+1向slk-1的方向调整,Jk+1的值在Jk-1左右,批次数据质量对指标优化的影响控制在可控范围,而文[24]中优化算法(退化后的式子)则无该修正效果.
3 仿真实例结晶过程是典型的间歇生产过程,经过多个操作阶段从一定的混合溶液中析出所需要的晶体,一组结晶完成后清洗设备,再次进料重复整个操作过程继续生产.本文采集了双酚A生产过程中正常工况下的数据,采样时间间隔为1 min,共51批次.采集的不等长数据包括结晶器A温度(℃)、加热管道B温度(℃)、加热管道C温度(℃)、加热管道D温度(℃),测量曲线如图 2所示.采集的产品纯度为生产的指标变量且只能在一个批次生产结束时获得.

|
| 图 2 同步前的51批测量曲线 Figure 2 51 beaches of measure profiles before synchronization |
将51批次数据中前4个批次的数据根据式(1)进行主成分分析,得到第1主元与第2主元构成的平面下的4个批次对应特征轨线,如图 3所示.从图 3看出,4个批次数据呈现出相同的轨迹变化趋势.但由于结晶过程的多阶段性,许多不可控因素使得各阶段结束时间长短不一.因此利用K均值算法对4个批次的均值特征轨线进行阶段划分,进而得到划分阶段的51批次数据.根据式(4)~式(5)计算各阶段下的距离差异矩阵,得到同步的多阶段数据而后融合为完整的同步特征轨线,最后得到原变量形式下同步的数据,数据同步效果如图 4所示.

|
| 图 3 主成分1和主成分2下变量的特征轨线 Figure 3 Characteristic trajectory under the principal component 1 and the principal component 2 |

|
| 图 4 同步后的51批测量曲线 Figure 4 51 beaches of measure profiles after synchronization |
为了验证本文所提数据同步方法的有效性,将该方法与其它同步方法进行比较.以下将取长补短法与本文所提同步方法同步的51批次数据应用于双酚A纯度的递推优化,比较两种方法的数据同步质量对双酚A纯度的影响.
将同步后的温度数据进行时段划分,与对应的各批次产品纯度数据构成扩展矩阵.将标准化后的扩展矩阵进行主成分分析,根据式(8)得到各时段变量与双酚A纯度的作用关系,根据式(12)~式(15)对时段变量与双酚A纯度的相关关系进行递推更新,根据式(11)得到基于指标增量修正项的优化曲线,再通过偏最小二乘建立温度曲线与产品纯度之间的统计模型,得到不同方案下的产品纯度预测值,见表 1.
从表 1可以看出在同种优化方案下,相比较于直接截取数据容易造成数据不完善的取长补短方法,本文所提出的数据同步方法由于更多地保存了过程信息,从而可以获得更高的产品纯度预测值.同时为了验证所提优化方案的优越性,在同种数据同步方法下,将本文优化方法与文[24]进行了比较,结果表明由于引入了批次间指标增量信息,基于取长补短法的优化方法使得双酚A纯度优化值相比较于文[24]提高了2.32%,基于特征轨线的优化预测值比文[24]提高了0.75%.
4 总结本文所提基于特征轨线多阶段融合的数据同步方法,实现了数据基于本质时间的同步,也保留了原始数据时间变化信息,基于K均值算法的融合阶段划分保证了同步的数据具有正确的阶段特性,同时结合特征轨线的特性,针对均值特征轨线进行阶段划分得到阶段节点,以此确定所有批次的阶段节点位置,从而简化了阶段划分流程.仿真结果表明,本文所提数据同步方法使文[24]优化方案下的双酚A纯度提高了1.57%;基于批次间指标增量修正项的操作曲线递推优化算法,充分利用了批次间数据信息,使得文[24]中优化效果改善,双酚A纯度提升了1.32%,验证了本文方法的有效性.
| [1] | Srinivasan B, Bonvin D, Visser E, et al. Dynamic optimization of batch processes Ⅱ. Role of measurements in handling uncertainty[J]. Computers & Chemical Engineering, 2002, 27: 27–44. |
| [2] |
陈伟, 贾立.
间歇过程PSO-SQP混合优化算法研究[J]. 仪器仪表学报, 2016, 37(2): 339–347.
Chen W, Jia L. PSO-SQP hybrid optimization algorithm for batch processes[J]. Chinese Journal of Scientific Instrument, 2016, 37(2): 339–347. DOI:10.3969/j.issn.0254-3087.2016.02.014 |
| [3] |
史洪岩, 苑明哲, 王天然.
间歇过程动态优化方法综述[J]. 信息与控制, 2012, 41(1): 75–82.
Shi H Y, Yuan M Z, Wang T R. A survey on dynamic optimization methods of batch process[J]. Information and Control, 2012, 41(1): 75–82. |
| [4] |
王幼琴, 赵忠盖, 刘飞.
一种间歇过程多批次融合线性变参数建模方法[J]. 信息与控制, 2017, 46(1): 46–52.
Wang Y Q, Zhao Z G, Liu F. A multi-batch fusion linear parameter varying modeling method for batch process[J]. Information and Control, 2017, 46(1): 46–52. |
| [5] | Chen J H, Sheui R G. Optimal batch trajectory design based on an intelligent data-driven method[J]. Industrial & Engineering Chemistry Research, 2003, 42(7): 1363–1378. |
| [6] | Ye L J, Guan H W, Yuan X F, et al. Run-to-run optimization of batch processes with self-optimizing control strategy[J]. Canadian Journal of Chemical Engineering, 2017, 95(4): 724–736. DOI:10.1002/cjce.v95.4 |
| [7] | Jia R D, Mao Z Z, Wang F L. Self-correcting modifier-adaptation strategy for batch-to-batch optimization based on batch-wise unfolded PLS model[J]. Canadian Journal of Chemical Engineering, 2016, 94(9): 1770–1782. DOI:10.1002/cjce.v94.9 |
| [8] | Duran-Villalobos C A, Lennox B, Lauri D. Multivariate batch to batch optimisation of fermentation processes incorporating validity constraints[J]. Journal of Process Control, 2016, 46: 34–42. DOI:10.1016/j.jprocont.2016.07.002 |
| [9] | Fiordalis A, Georgakis C. Data-driven, using design of dynamic experiments, versus model-driven optimization of batch crystallization processes[J]. Journal of Process Control, 2013, 23(2): 179–188. DOI:10.1016/j.jprocont.2012.08.011 |
| [10] | Kong X S, Yang Y, Chen X. Quality control via model-free optimization for a type of batch process with a short cycle time and low operational cost[J]. Industrial and Engineering Chemistry Research, 2011, 50(5): 2994–3003. DOI:10.1021/ie1016927 |
| [11] |
黄碧璇, 毛志忠, 贾润达.
草酸钴合成过程批次间自适应优化[J]. 控制理论与应用, 2016, 33(2): 189–195.
Huang B X, Mao Z Z, Jia R D. A batch-to-batch adaptive optimization for the cobalt oxalate synthesis process[J]. Control Theory & Application, 2016, 33(2): 189–195. |
| [12] | Camacho J, Pico J, Ferrer A. Self-tuning run to run optimization of fed-batch processes using unfold-PLS[J]. AIChE Journal, 2007, 53(7): 1789–1804. DOI:10.1002/(ISSN)1547-5905 |
| [13] | Li C F, Zhang J, Wang G Z. Batch-to-batch optimal control of batch process based on recursively updated nonlinear partial least squares models[J]. Chemical Engineering Communications, 2007, 194(3): 261–279. DOI:10.1080/00986440600829796 |
| [14] | Zhang Y W, Fan Y P, Zhang P C. Combining kernel partial least-squares modeling and iterative learning control for the batch-to-batch optimization of constrained nonlinear processes[J]. Industrial & Engineering Chemistry Research, 2010, 49(16): 7470–7477. |
| [15] |
刘毅, 阳宪惠, 熊智华.
基于支持向量回归模型的间歇过程优化[J]. 华东理工大学学报:自然科学版, 2006, 32(7): 880–883.
Liu Y, Yang X H, Xiong Z H. Batch process optimization based on support vector regression model[J]. Journal of East China University of Science and Technology:Natural Science Edition, 2006, 32(7): 880–883. |
| [16] | Rothwell S G, Martin E B, Morris A J. Comparison of methods for dealing with uneven length batches[C]//Proceedings of the 7th International Conference on Computer Applications in Biotechnology. Berlin, Germany: Springer-Verlag, 1998: 387-392. |
| [17] | Kassidas A, Macgregor J F, Taylor P. Synchronization of batch trajectories using dynamic time warping[J]. AIChE Journal, 1998, 44(4): 864–875. DOI:10.1002/(ISSN)1547-5905 |
| [18] | Frank W, Lars G, Brad S, et al. Assumption free modeling and monitoring of batch process[J]. Chemometrics and Intelligent Laboratory Systems, 2015, 149: 66–72. DOI:10.1016/j.chemolab.2015.08.022 |
| [19] |
王姝, 常玉清, 杨洁, 等.
时段划分的多向主元分析间歇过程监测及故障变量追溯[J]. 控制理论与应用, 2011, 28(2): 149–156.
Wang S, Chang Y Q, Yang J, et al. Multiway principle component analysis monitoring and fault variable detection based on substage separation for batch processes[J]. Control Theory & Application, 2011, 28(2): 149–156. |
| [20] |
卫俊霞, 相里斌, 高晓惠, 等.
基于K-均值聚类与夹角余弦法的多光谱分类算法[J]. 光谱学与光谱分析, 2011, 31(5): 1357–1360.
Wei J X, Xiang L B, Gao X H, et al. Multi-spectral classification algorithm based on K-means clustering and cosine of the angle method[J]. Spectroscopy and Spectral Analysis, 2011, 31(5): 1357–1360. DOI:10.3964/j.issn.1000-0593(2011)05-1357-04 |
| [21] |
叶凌箭, 宋执环, 马修水.
间歇过程的批间自优化控制[J]. 化工学报, 2015, 66(7): 2573–2580.
Ye L J, Song Z H, Ma X S. Batch-to-batch self-optimizing control for batch processes[J]. CIESC Journal, 2015, 66(7): 2573–2580. |
| [22] |
叶凌箭, 马修水, 宋执环.
基于输入轨迹参数化的间歇过程迭代学习控制[J]. 化工学报, 2016, 67(3): 743–750.
Ye L J, Ma X S, Song Z H. Iterative learning control of batch process with input trajectory parameterization[J]. CIESC Journal, 2016, 67(3): 743–750. |
| [23] | Lu N Y, Gao F R, Wang F L. Sub-PCA modeling and on-line monitoring strategy for batch processes[J]. AIChE Journal, 2004, 50(1): 255–259. DOI:10.1002/(ISSN)1547-5905 |
| [24] |
仇力, 栾小丽, 刘飞.
基于主元相似度的间歇过程操作曲线递推优化[J]. 化工学报, 2017, 68(7): 2859–2865.
Qiu L, Luan X L, Liu F. A recursive method for trajectory optimization of batch processes based on similarity of principal components[J]. CIESC Journal, 2017, 68(7): 2859–2865. |
| [25] |
程龙, 王桂增.
改进的递推主元分析及递推主元回归算法[J]. 控制工程, 2010, 17(1): 5–8.
Cheng L, Wang G Z. Improved recursive PCA and recursive PCR algorithms[J]. Control Engineering of China, 2010, 17(1): 5–8. DOI:10.3969/j.issn.1671-7848.2010.01.002 |
| [26] | Li W H, Yue H H, Valle-Cervantes S, et al. Recursive PCA for adaptive process monitoring[J]. Journal of Process Control, 2000, 10(5): 471–486. DOI:10.1016/S0959-1524(00)00022-6 |