



2. 鲁东大学资产处, 山东 烟台 264025
2. Assets Department, Ludong University, Yantai 264025, China
0 引言
Dempster证据理论具有较强表达和融合不确定信息的能力,近年来被广泛应用于目标识别、故障诊断、不确定决策及人工智能等领域[1-4].但在遇到高冲突或者一些焦元的信度赋值趋近于0的证据时,Dempster证据组合规则会出现有悖于常理的融合结论[5-6].
为此,研究者们相继提出了诸多改进算法,主要包括针对Dempster证据组合规则自身的改进[7-10]和对冲突证据的预处理算法[11-17].前者主要是针对经典证据组合规则的推广[7]和对全局及局部冲突信息的再分配[8-10],而后者则是通过估算证据的权数对证据进行修正.针对后者,Murphy[11]提出对J条证据的平均证据体进行自身融合J-1次的改进算法,该算法的不足是忽略了不同证据之间的差异.邓勇等[12]对Murphy所提算法进行改进,提出对基于Jousselme证据距离[13]的加权证据体进行自身融合J-1次的改进算法,该方法在一定程度上减少了冲突证据对证据融合结果的影响.宋亚飞等[14]在邓勇算法的基础上,引进证据虚假度[15]概念,用证据余弦距离和虚假度共同度量证据之间的冲突,但仔细分析可以发现,该算法并不是在所有情况下都优于邓勇所提算法,而是主要适用于差异性不是很高的证据之间的融合.上述3种改进算法均是从对证据进行预处理的角度降低冲突证据对融合结果的影响.其优点是可以避免经典Dempster证据组合规则在特殊情况下容易出现悖论和“一票否决”现象的不足且算法聚焦速度较快;不足之处是目标识别结果依赖于加权证据体的目标判别结果,如果加权证据体对目标判别结果出错,再利用Dempster证据组合规则进行自身融合J-1次后,其目标识别结果仍是错误的. Silva等[16]采用多分类准则,将证据分为不同的冲突类别,通过多目标优化,确定证据权数.其优点是保留了Dempster证据组合规则优良的数学特性,不足是计算过程相对复杂且该算法对冲突程度判别的准确性仍依赖于对不同冲突度量参数的选取和对其权重的确定.文[18-20]综合利用对证据的预处理和改进证据组合规则两种策略提高冲突证据的融合效果,其中曹洁等[18]在利用证据距离计算证据及各焦元的可信度的基础上,将计算结果用于对局部冲突信息进行再分配,在一定程度上提高了冲突信息的利用率,但该算法也存在一些不足之处:其一是该算法针对任何证据类型,都仅仅基于证据距离计算证据和焦元权重,忽略了其它度量参数在一些场合下对描述证据冲突所起的作用;其二是该算法不满足结合律,证据融合结果受证据融合次序影响较大,算法稳定性不足.
本文在对冲突证据融合算法进行多方面研究的基础上,首先研究了度量证据冲突程度的参数,提出针对不同冲突情况,采用不同的参数对证据冲突程度进行度量,并分析改进了基于证据距离计算证据支持度的计算公式,在较大程度上提高了证据权重计算的准确性.其次,改进了焦元权重计算式.以上针对证据权重和不同证据中焦元权重的优化计算,为后续针对局部冲突信息的有效加权分配提供了保证,也为证据合理融合次序的确定提供了依据.通过算例和仿真实验对所提算法和已有相关算法进行了对比分析,理论分析和实验结果验证了本文所提算法处理高冲突证据时的有效性和稳定性.
1 证据融合规则 1.1 Dempster证据组合规则设Θ={θ1,θ2,…,θn}是由一些两两互斥且穷举的元素构成的一个辨识框架,Θ的幂集2Θ构成命题集合,定义m:2Θ→[0, 1].如果对任一命题A(A∈2Θ)满足:
1) m(∅)=0,∅为空集;
2) 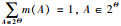
对于两两相互独立的证据源mj(j=1,2,…,J),其Dempster证据组合规则为
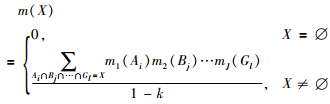
|
(1) |
其中,
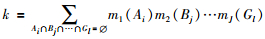
|
(2) |
式(2)中,k表示多条证据之间的不一致因子,如果采用的是两两证据融合规则,则其表示待融合的两条证据之间的不一致度量.当k=1时,Dempster组合规则失效且据已有研究,当k趋近于1时,式(1)的融合结果也会出现与实际情况相悖的结论.针对这一现象,文[12]将J条证据的加权证据体进行自身融合J-1次作为J条证据的最终融合结果的做法,可以有效避免悖论的产生,也通常具有较快的聚焦速度,但其融合结果的正确与否依赖于加权证据体的目标识别结果,如例1所示.
例1 目标识别框架为Θ={A,B,C},4条证据分别为
m1:m1(A)=0.10,m1(B)=0.80,m1(C)=0.10
m2:m2(A)=0.60,m2(B)=0.30,m2(C)=0.10
m3:m3(A)=0.45,m3(B)=0.55,m3(C)=0.00
m4:m4(A)=0.60,m4(B)=0.30,m4(C)=0.10
对上述4条证据分别采用式(6)、式(7)和文[12]所提算法计算证据权重,可得到不同加权证据体:
mw1:mw1(A)=0.46,mw1(B)=0.47,mw1(C)=0.07
mw2:mw2(A)=0.49,mw2(B)=0.44,mw2(C)=0.07
显然,两种不同权重计算方式,导致目标识别结果不一致.再对上述两条加权证据体分别利用Dempster组合规则进行3次自身融合,所得结果也只能向加权证据体所识别目标方向进行快速聚焦,使得两种算法的融合结果对焦元A和B的基本概率分配出现更大的差异.
文[14]利用虚假度和Jousselme证据余弦距离共同对证据之间的冲突进行衡量,但仔细分析不难发现,针对差异性较高的冲突证据,引入虚假度会降低对冲突证据的融合效果,如例2所示.
例2 目标识别框架为Θ={A,B,C},4条证据分别为
m1:m1(A)=0.60,m1(B)=0.30,m1(C)=0.10
m2:m2(A)=0.55,m2(B)=0.35,m2(C)=0.10
m3:m3(A)=0.50,m3(B)=0.40,m3(C)=0.10
m4:m4(A)=0.00,m4(B)=1.00,m4(C)=0.00
对上例利用文[12]邓勇算法的融合结果为
m[12]:m(A)=0.55,m(B)=0.45,m(C)=0.00
而采用文[14]中宋亚飞算法的融合结果为
m[14]:m(A)=0.48,m(B)=0.52,m(C)=0.00
再利用其它较可靠的相关算法,可以得到与文[12]相一致的融合结论.客观分析本例中3条证据的特点,也可以认为证据4是一条冲突证据,因此正确目标识别结果应该是焦元A.
上述结果说明当对上述4条证据进行融合时,引入虚假度与证据距离共同对证据冲突程度进行度量并没有起到提高目标识别准确性的目的.因此,有必要对度量证据冲突的参数进行更进一步的探讨与研究.
1.3 冲突证据的融合由1.2节的讨论可知,对证据进行预处理算法的关键是采用恰当的冲突度量参数准确计算各条证据的权重.为有效提高冲突证据的融合效果,本文考虑将对证据的预处理算法和对证据组合规则的改进算法相结合,即在准确计算证据权重的基础上,将计算结果应用于对局部冲突信息的加权再分配.通过提高证据权重计算的准确性和对矛盾信息再分配的有效性,达到全面提高证据冲突情况下目标识别准确率的目的.
2 改进融合次序的目标识别算法 2.1 证据融合次序的优化曹洁等[18]所提算法是将两两证据融合过程中产生的形如AB的不一致因子所含矛盾信息根据不同证据及不同焦元所占权重大小进行重新分配.但由于该算法不满足结合律,使得证据融合结果受证据融合次序的影响较大,尤其是当冲突证据被置于融合顺序末端时,该算法的融合精度明显下降.为避免上述不足,可将文[18]所提算法扩展到多条证据进行直接融合的情形,扩展后的算法不仅可以有效降低融合次序对融合结果的影响且由于其对诸多高维冲突因子所含矛盾信息均进行了重新加权分配,提高了矛盾信息的利用率,使得算法具有较高的稳定性.其不足是随着待融合证据条数的增加,扩展算法的计算负担较重.
避免基于局部冲突信息再分配的两两证据融合算法稳定性较差这一不足的另一思路,是将冲突证据置于融合顺序的前端,如此便可减少冲突证据对融合结果的影响,这样问题又归结到证据冲突的有效度量问题上.下面讨论给出基于证据融合次序优化的目标识别算法.
2.2 改进证据融合次序的目标识别算法如果任意两条证据之间的证据距离的最大值不超过一定阈值,说明不同证据之间的差异性不大,此时,Dempster组合规则中的不一致因子k中含有一定量反映证据之间冲突程度的信息,可以考虑采用文[14]中宋亚飞所提算法利用虚假度和证据距离共同来刻画证据之间的冲突程度.而如果证据距离矩阵中的最大值超过一定的阈值,说明某些证据之间的差异性不是很小,此时文[14]所提算法不一定完全适用,应该先分析清楚证据之间的冲突状况:是少数证据与其它证据之间均存在冲突,还是部分证据与其它证据之间存在冲突.根据冲突情况的不同,采用适当的参数对证据之间的冲突程度进行度量,并依此计算各证据的权数.
2.2.1 冲突度量参数的确定首先,证据mi与mj之间的Jousselme证据距离可表示为
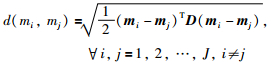
|
(3) |
这里,mi、mj是mi、mj的向量形式,矩阵D中的元素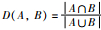
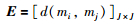
|
(4) |
令:
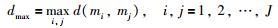
|
(5) |
如果各条证据之间的证据距离的最大值小到一定程度,则有理由认为任意两条证据之间均不存在过大的差异,这时两条证据之间的不一致因子能够在很大程度上反映出证据之间的冲突状况,即当dmax≤α1(α1为一给定阈值)时,应采用证据距离和虚假度共同刻画证据之间的冲突.
当dmax>α1时,则认为某些证据之间存在比较大的差异.为了解此时证据之间的差异情况,有必要先考察基于Jousselme证据距离的证据可信度的取值情况.为此,引进证据mi被其它证据支持的支持度:
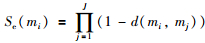
|
(6) |
其中,Se表示证据的支持度.于是,证据mi的可信度可以描述为
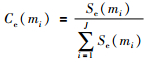
|
(7) |
其中,Ce表示证据的可信度.如此,J条证据的平均可信度可表示为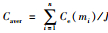
定义:
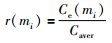
|
(8) |
若存在证据mi,使得r(mi)≤α2(α2为一个给定的阈值),则有理由认为此时证据mi与其它多数证据之间均存在非常大的差异.这时由于一些特异的焦元信度赋值的存在,不一致因子不能很好地刻画证据之间的不一致性,不应引入虚假度与证据距离共同对证据冲突进行衡量,而仅利用证据距离就能较好地刻画冲突.与文[12]和文[18]描述证据mi被其它证据支持的支持度的表示式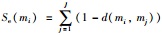
若r(mi)>α2,则有理由认为尽管不同证据之间存在较大冲突,但存在其它证据与冲突证据mi具有一定的一致性,此时不一致因子中仍含有能够反映证据之间冲突情况的有用信息,应采用证据距离和虚假度共同来刻画证据之间的冲突.
2.2.2 改进算法描述改进算法利用确定的冲突度量参数计算证据的综合可信度,并利用综合可信度计算不同证据中各焦元的可信度和对两两证据融合顺序进行优化,下面给出新的基于局部冲突再分配的改进证据融合规则.
1) 冲突参数的确定
首先,计算J条证据之间的Jousselme证据距离矩阵,求得矩阵元素中最大值dmax.
(1) 若dmax≤α1(取α1=0.5),则基于式(9)计算证据mi的综合可信度:
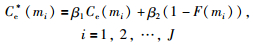
|
(9) |
其中,F(mi)是证据mi的虚假度归一化后的取值,0≤β1,β2≤1,β1+β2=1.
(2) 若dmax>α1,①当r(mi)≤α2(取α2=0.25),用式(7)中Ce(mi)替代综合可信度Ce*(mi);②当r(mi)>α2,仍利用式(9)计算证据的综合可信度.
2) 融合次序的优化
按各证据综合可信度取值由小到大的顺序对各证据进行排序,即得到优化的证据融合次序.
3) 焦元可信度的计算
基于证据综合可信度,定义证据mi中焦元Ak的支持度Sf(mi(Ak))为
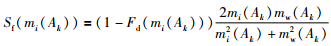
|
(10) |
其中,mw(Ak)表示焦元Ak的加权概率赋值,即:
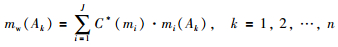
|
(11) |
而证据mi中焦元Ak与其加权值之间的焦元距Fd(mi(Ak))可表示为
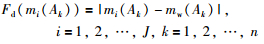
|
(12) |
于是,证据mi中焦元Ak的可信度可表示为
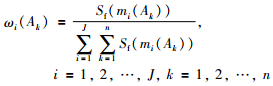
|
(13) |
4) 改进的证据融合算法
证据mi和mj融合时焦元Ak′的概率赋值可表示为
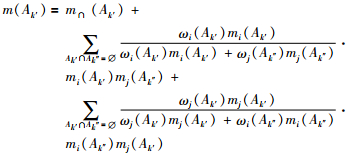
|
(14) |
其中,k′,k″=1,2,…,n,k′≠k″.
5) 多证据融合
按优化后的证据融合次序对多条证据利用式(14)进行两两融合,得到最终融合结果.
与曹洁[18]改进算法相比,本文所提改进算法不仅在冲突参数度量和证据支持度计算方面对证据权重的计算方法进行了改进,并依此优化证据融合次序,而且改进了焦元可信度的计算公式.由式(13)可知,改进算法考虑了待融合两条证据与其它证据之间的联系,可提高焦元可信度的准确性且根据焦元的信度赋值与其中心值之间的关系直接求取其相似度,不需要计算证据体中的各焦元距,相对减小了算法的计算负担.
3算例与仿真分析
例3 目标识别框架为Θ={A,B,C},7条证据分别为
m1:m1(A)=0.70,m1(B)=0.25,m1(C)=0.05
m2:m2(A)=0.05,m2(B)=0.40,m2(C)=0.55
m3:m3(A)=0.60,m3(B)=0.30,m3(C)=0.10
m4:m4(A)=0.10,m4(B)=0.30,m4(C)=0.60
m5:m5(A)=0.70,m5(B)=0.20,m5(C)=0.10
m6:m6(A)=0.10,m6(B)=0.20,m6(C)=0.70
m7:m7(A)=0.75,m7(B)=0.20,m7(C)=0.05
解 采用不同相关算法的证据融合结果如表 1所示.
| 算法 | m(A) | m(B) | m(C) |
| 邓加法加权 | 0.939 9 | 0.021 4 | 0.038 7 |
| 邓乘法加权 | 0.992 6 | 0.006 3 | 0.001 1 |
| 邓乘法加权加虚假度 | 0.994 6 | 0.004 7 | 0.000 7 |
| 加法加权 | 0.451 2 | 0.262 8 | 0.286 0 |
| 乘法加权 | 0.536 1 | 0.260 2 | 0.203 7 |
| 直接乘法加权 | 0.621 2 | 0.204 0 | 0.174 8 |
| 直接乘法加权加虚假度 | 0.636 5 | 0.201 6 | 0.161 9 |
| 直接加法加权 | 0.543 5 | 0.207 6 | 0.248 9 |
| 直接加法加权加虚假度 | 0.592 7 | 0.203 7 | 0.203 6 |
| 宋算法 | 0.976 7 | 0.012 1 | 0.011 1 |
| Dempster证据组合规则 | 0.586 4 | 0.382 9 | 0.030 7 |
| 曹加法加权算法 | 0.736 8 | 0.128 4 | 0.134 8 |
| 曹乘法加权算法 | 0.786 7 | 0.124 6 | 0.088 7 |
表 1算法中的乘法加权指的是利用式(6)、式(7)计算证据的可信度所得加权证据体,邓乘法加权即是指对上述加权证据体自身融合6次的结果,直接乘法加权和曹洁乘法加权分别指在多证据直接融合算法和曹洁两两证据融合算法中利用乘法加权算法计算证据权重并依此对冲突信息进行加权分配的结果.而加法加权是利用文[12]中邓勇所提计算权重算法,也就是将本文式(6)中的乘积符号替换成求和符号,而后用式(7)计算证据可信度的方法.其它算法中的加法加权含义即是指将上述算法中的乘法加权算法替换成加法加权算法.宋算法指文[14]宋亚飞所提利用证据余弦距离和虚假度共同度量证据综合可信度的算法.
从表 1可以看出,多种算法在引入虚假度后,所得证据融合效果均有提升,将曹洁乘法加权算法引入虚假度后,其融合结果为
m(A)=0.802 8,m(B)=0.123 2,m(C)=0.073 9
该结果也优于一般的曹洁乘法加权算法的对应结果.
考虑本文算法,该例证据距离矩阵中最大元素为0.650 0,由于0.650 0>0.5,故转而计算基于Jousselme证据距离和乘法加权算法的证据可信度:
w(1)=0.18,w(2)=0.08,w(3)=0.26
w(4)=0.10,w(5)=0.20,w(6)=0.06
w(7)=0.13
由于0.056 2/(1/7)>0.25,故根据新算法规则应引入虚假度和证据距离共同度量证据冲突,取β2=β1=0.5,利用式(9)计算得到不同证据的综合信任度:
w′(1)=0.19,w′(2)=0.05,w′(3)=0.23
w′(4)=0.09,w′(5)=0.20,w′(6)=0.08
w′(7)=0.18
按原证据自然顺序编号依综合信任度由小到大的顺序对证据进行排序,得新排序次序为2,6,4,7,1,5,3.按新排序利用本文所提算法的融合结果:
m(A)=0.87,m(B)=0.12,m(C)=0.01
显然,该结果远远优于排序前使用原有曹洁加法加权算法的融合结果.
由以上分析可以看出,对该例引入虚假度和证据距离共同度量证据之间的冲突,并对证据融合顺序进行优化的做法,能在较大程度上提高证据融合效果. 表 2给出例3中不同算法各运行100次所费时间的比较结果.
| 算法 | 时间花费 /s |
| 邓加法加权 | 0.021 0 |
| 邓乘法加权 | 0.033 7 |
| 邓乘法加权加虚假度 | 0.039 0 |
| 加法加权 | 0.010 9 |
| 乘法加权 | 0.010 9 |
| 直接乘法加权 | 4.347 2 |
| 直接乘法加权加虚假度 | 4.326 6 |
| 直接加法加权 | 4.224 8 |
| 直接加法加权加虚假度 | 4.289 5 |
| 宋算法 | 0.074 8 |
| Dempster组合规则 | 0.004 1 |
| 曹加法加权算法 | 0.087 2 |
| 曹乘法加权算法 | 0.089 3 |
| 本文所提算法 | 0.369 9 |
由表 2可以看出,本文所提改进算法,较其它一般算法的时间花费要高,但与具有较好稳定性的各种直接融合算法相比,其时间花费低于直接融合算法时间花费的1/10.
例4 有4部雷达同时对某一区域中3个未知飞行体进行观测,识别框架Θ={A,B,C},其中A为战斗机,B和C均为普通飞机,4条证据为
m1(A)=x1,m1(B)=x2,m1(C)=1-x1-x2
m2(A)=y1,m2(B)=y2,m2(C)=1-y1-y2
m3(A)=y1,m3(B)=y2,m3(C)=1-y1-y2
m4(A)=y1,m4(B)=y2,m4(C)=1-y1-y2
∀x1,x2∈[0, 1],∀y1,y2∈[0, 1]
其中,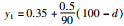
3个目标A、B、C均在与雷达观测系统相距100 km处相对飞行,战斗机和普通机的相对速度均是1 000 m/s.雷达1正确判断3个目标的机型种类的置信度始终分别为0.5,0.4,0.1,雷达2、3、4在100 km处对目标A机型的置信度均为0.35,在10 km处对A战斗机进行准确判别的可能性均为0.85,在该期间,对战斗机的判别准确程度与其实时相隔距离成反比;在整个飞行过程中,除干扰阶段外,雷达2、3、4对B飞行器判断的置信度始终为0.2.
在与目标相距30 km~20 km处,雷达4受到干扰,正确判别A、B两飞机类别的可能性大小是0.
图 1和图 2分别给出了在一般和干扰阶段,主要的6种算法,包括4条证据直接融合算法(4D算法)、本文算法(新算法)、文[14]宋亚飞所提算法(宋算法)、文[12]邓勇所提算法(邓算法)、文[18]曹洁所提算法(曹算法)及Dempster证据组合规则(Dempster规则)分别判断飞机A和B为战斗机的概率.可以看出,在一般无冲突阶段,新算法及4条证据直接融合算法的目标识别效果不如经典Dempster组合规则和各种加权算法好,但在高冲突过程中,只有新算法和多证据直接融合算法能够正确判别出目标种类,而新算法优于直接融合算法.

|
| 图 1 判别A机是战斗机的概率 Figure 1 The probability of the aircraft A as a fighter |

|
| 图 2 判别B机是战斗机的概率 Figure 2 The probability of the aircraft B as a fighter |
由以上两例可以看出,本文算法不仅继承了多证据直接融合算法抗干扰能力较强的特点,在一般情况下,其算法的证据融合精度也相对较高且其时间花费远远低于直接融合算法的对应结果.
4 结论本文研究了度量证据冲突程度的参数,针对不同类型冲突证据,分别采用不同的冲突度量参数来计算证据的综合可信度,并依此对证据融合次序进行优化和对冲突信息进行改进的加权再分配.理论分析和算例、仿真分析结果表明,与只针对证据权重进行修正的改进算法相比,基于证据预处理的局部冲突信息改进再分配算法,能够通过对更多冲突信息的有效利用,提高高冲突情况下的证据融合效果,提高目标识别结果的可靠性.
由例4仿真结果可知,在高冲突阶段,与基于较差证据融合次序的曹洁算法相比,本文所提基于综合可信度和改进证据融合次序的局部冲突信息改进再分配算法的目标识别概率提高了0.48多个点,在较大程度上提高了算法的稳定性.同时,与具有较高稳定性的多证据直接融合算法相比,本文所提算法不仅具有较高的目标识别概率且具有较低的时间花费.如何进一步减少新算法的时间花费,提高其在复杂探测环境下的稳定性尚需进行进一步的研究;如何对不同证据类型所适用的冲突度量参数进行更细致、精准的分类讨论,也是未来一项具有实际意义的研究工作.
| [1] | Shafer G. A mathematical theory of evidence turns 40[J]. International Journal of Approximate Reasoning, 2016, 79: 7–25. DOI:10.1016/j.ijar.2016.07.009 |
| [2] | Yager R R, Alajlan N. Decision making with ordinal payoffs under Dempster-Shafer type uncertainty[J]. International Journal of Intelligent Systems, 2013, 28(11): 1039–1053. DOI:10.1002/int.2013.28.issue-11 |
| [3] | Frikha A, Moalla H. Analytic hierarchy process for multi-sensor data fusion based on belief function theory[J]. European Journal of Operational Research, 2015, 241(1): 133–147. DOI:10.1016/j.ejor.2014.08.024 |
| [4] |
文成林, 徐晓滨.
多源不确定信息融合理论及应用——故障诊断与可靠性评估[M]. 北京: 科学出版社, 2012: 1-40.
Wen C L, Xu X B. Theories and applications in multisource uncertain information fusion-Fault diagnosis and reliability evaluation[M]. Beijing: Science Press, 2012: 1-40. |
| [5] | Burger T. Geometric views on conflicting mass functions:From distances to angles[J]. International Journal of Approximate Reasoning, 2016, 70: 36–50. DOI:10.1016/j.ijar.2015.12.006 |
| [6] | Destercke S, Burger T. Toward an axiomatic definition of conflict between belief functions[J]. IEEE Transactions on Cybernetics, 2013, 43(2): 585–596. DOI:10.1109/TSMCB.2012.2212703 |
| [7] | Deng Y. Generalized evidence theory[J]. Applied Intelligence, 2015, 43(3): 530–543. DOI:10.1007/s10489-015-0661-2 |
| [8] | Yager R R. On the Dempster-Shafer framework and new combination rules[J]. Information Sciences, 1987, 41(5): 93–138. |
| [9] | Smets P. Jeffrey's rule of conditioning generalized to belief functions[C]//9th Conference on Uncertainty in Artificial Intelligence. New York, NJ, USA: ACM, 1993: 500-505. |
| [10] |
权文, 王晓丹, 周进登, 等.
一种修正的Dubois-Prade证据推理组合规则[J]. 控制与决策, 2012, 27(1): 139–142.
Quan W, Wang X D, Zhou J D, et al. A modified Dubois-Prade combination rule of evidence theory[J]. Control and Decision, 2012, 27(1): 139–142. |
| [11] | Murphy C K. Combining belief functions when evidence conflicts[J]. Decision support systems, 2000, 29(1): 1–9. DOI:10.1016/S0167-9236(99)00084-6 |
| [12] |
邓勇, 施文康, 朱振福.
一种有效处理冲突证据的组合方法[J]. 红外与毫米波学报, 2004, 23(1): 27–32.
Deng Y, Shi W K, Zhu Z F. Efficient combination approach of conflict evidence[J]. Journal of Infrared and Millimeter Waves, 2004, 23(1): 27–32. DOI:10.3321/j.issn:1001-9014.2004.01.006 |
| [13] | Jousselme A L, Maupin P. Distances in evidence theory:Comprehensive survey and generalizations[J]. International Journal of Approximate Reasoning, 2012, 53(2): 118–145. DOI:10.1016/j.ijar.2011.07.006 |
| [14] |
宋亚飞, 王晓丹, 雷蕾, 等.
基于信任度和虚假度的证据组合方法[J]. 通信学报, 2015, 36(5): 104.
Song Y F, Wang X D, Lei L, et al. Evidence combination based on the degree of credibility and falsity[J]. Journal on Communications, 2015, 36(5): 104. |
| [15] | Schuber T J. Conflict management in Dempster-Shafer theory using the degree of falsity[J]. International Journal of Approximate Reasoning, 2011, 52(3): 449–460. DOI:10.1016/j.ijar.2010.10.004 |
| [16] | Silva L G D O, Filho A T D A. A multicriteria approach for analysis of conflicts in evidence theory[J]. Information Science, 2016, 346-347: 275–285. DOI:10.1016/j.ins.2016.01.080 |
| [17] |
陈圣群, 王应明.
基于Pignistic概率距离的最优证据合成法[J]. 信息与控制, 2013, 42(2): 213–217, 228.
Chen S Q, Wang Y M. Optimal combination of evidence based on Pignistic probability distance[J]. Information and Control, 2013, 42(2): 213–217, 228. |
| [18] |
曹洁, 郭雷雷.
一种基于局部冲突分配的证据组合规则[J]. 计算机应用研究, 2013, 30(7): 2033–2035.
Cao J, Guo L L. Evidence combination rule based on local conflict distribution strategy[J]. Application Research of Computers, 2013, 30(7): 2033–2035. DOI:10.3969/j.issn.1001-3695.2013.07.029 |
| [19] | Li X D, Dezert J, Smarandache F, et al. Evidence supporting measure of similarity for reducing the complexity in information fusion[J]. Information Sciences, 2011, 181(10): 1818–1835. DOI:10.1016/j.ins.2010.10.025 |
| [20] |
周莉, 唐文静, 郭伟震.
基于改进D-S证据组合规则的目标识别算法[J]. 北京邮电大学学报, 2016, 36(5): 47–50.
Zhou L, Tang W J, Guo W Z. Target-recognition algorithm based on improved D-S evidence combination rule[J]. Journal of Beijing University of Posts and Telecommunications, 2016, 36(5): 47–50. |