



2. 中国东方航空江苏有限公司飞机维修部, 江苏 南京 211113
2. Department of Aircraft Maintenance, China Eastern Airlines Jiangsu Ltd., Nanjing 211113, China
0 引言
非均衡数据学习问题主要集中在解决数据本身分布和提高算法性能两个方面[1-4].其中,基于聚类的采样是数据均衡化的常用方法[5],通过聚类中心表征每类数据平均特征,再围绕聚类中心对多数类降采样[6]、对少数类过采样[7],在一定程度上可以减少随机降采样造成多数类信息的损失及过采样过程中引起的合成样本类间边界重叠、样本过度泛化等问题,但通过对多数类提取子集再和少数类组成均衡的数据集的层次聚类算法结构复杂.常用的数据聚类(如模糊C均值(FCM)及后续很多基于加权的FCM算法[8-10])结构简单. Wang等提出的加权模糊k均值聚类(fuzzy k-means with variable weighting,WFCM)算法[11]引入了模糊权重,在一定程度上提高了算法对噪声和异常数据的处理能力,但只考虑了样本类内紧致,所以WFCM算法对分布不均衡数据聚类效果不好;Wu等提出的FCS(fuzzy compactness and separation)算法,考虑样本类内紧致性和类间散布性,实现样本的硬划分和模糊划分,其结果更接近数据的真实情况[12].宋风溪等提出了最大散度差判别准则的分类方法[13-14],该准则根据类间散布和类内紧致来求最优投影向量以对样本进行分类;皋军等将模糊度引入了最大散度差判别准则提出了FMSDC(fuzzy maximum scatter difference discriminant criterion)算法[15],在模糊聚类的同时对数据进行降维;支晓斌等指出皋军等的算法中的错误,提出FMSDC-FCS聚类算法[16],该算法利用FCM算法初始化隶属度和样本均值,再用FMSDC算法进行降维,最后用FCS算法对降维数据进行聚类,其聚类实质还是FCS算法. Deng等提出的增强子空间软聚类(enhanced soft subspace clustering,ESSC)算法[17]将类间散布引入目标函数,通过指定的参数η来平衡类内紧致和类间散布,但当η取值为0时ESSC算法退化为仅考虑类内紧致的熵加权k均值聚类(entropy weighting k-means clustering)算法[18].
考虑到非均衡分布的样本属性对聚类的影响,本文提出了簇特征加权的模糊紧致散布聚类(cluster feature weighting fuzzy compactness and separation,CFWFCS)算法,将样本属性对聚类的重要度(簇特征加权)和样本类内紧致性、类间散布性引入目标函数,在考虑样本属性分布特性前提下尽可能使得样本类内紧致、类间分散,对非均衡数据可达到更好的聚类效果且实现简单.指出了FCS算法中模糊隶属度表达式的不足之处,引入各属性对各类划分的影响,给出了聚类中心、样本隶属度和属性权重表达式.通过真实数据和仿真数据的验证、对比分析,证明本算法相对于FCS算法及类似加权的ESSC算法、未考虑样本类间散布的WFCM算法都有很好的表现,对于样本分布不均衡、噪声数据和异常数据的划分更有效,有更好的鲁棒性.
1 FCS算法介绍设有n个样本记为X={x1,…,xn},样本可分为c类,每类聚类中心为ai,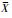
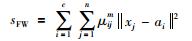
|
(1) |
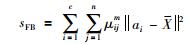
|
(2) |
其中,μij表示第j个样本对第i类的隶属度,μij∈[0, 1]且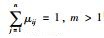
有目标函数:
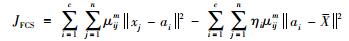
|
(3) |
其中,
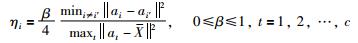
|
(4) |
为使目标函数最小化,求得:
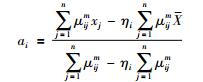
|
(5) |
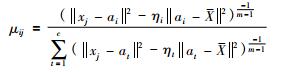
|
(6) |
通过式(5)、式(6)迭代运算,可实现最小化JFCS.
式(6)给出了各样本对不同类的隶属度,根据文[12],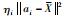
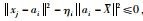
但是,对于某样本xj落在硬划分边界上的这种情况该算法未予以充分考虑(2维示意图如图 1所示),某样本点xj落在了第i类硬划分边界上,计算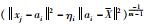

|
| 图 1 硬划分示意图 Figure 1 Schematic diagram of the hard-classification |
ωik表示第k个属性对于第i类的权重,定义样本簇特征加权类内紧致度sCFWFW和样本簇特征加权类间散度sCFWFB分别如式(7)、式(8)所示:
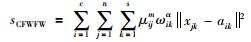
|
(7) |
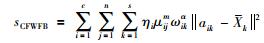
|
(8) |
加权系数α∈[-10,0)∪(1,10][20].
有目标函数:
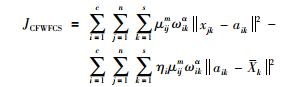
|
(9) |
簇特征加权的FCS聚类问题为
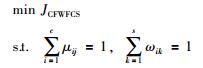
|
(10) |
利用拉格朗日乘子法,有:
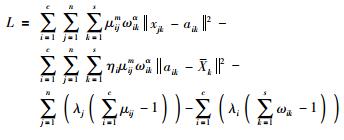
|
(11) |
式中λi、λj是拉格朗日乘子. L分别对μij、λi、ωk、λj、aik求偏导并令偏导结果为0,求得:
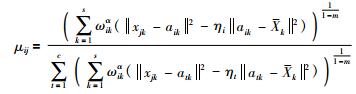
|
(12) |
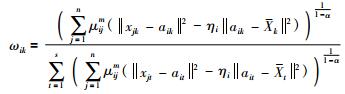
|
(13) |
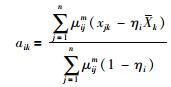
|
(14) |
1) μij的调整
记:
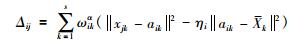
|
(15) |
对于式(12):
(1) 若Δij>0,则有
(2) 若Δij=0,则表明样本点xj落在硬划分边界上,式(12)计算得μij为正无穷大,算法无效.对于落在第i类硬划分边界的样本点本身就具有模糊性,如果把它进行硬化分是与实际情况不相符的,但是和其它落在硬划分区域外的样本点相比,xj对于第i类有更大的模糊隶属度.所以,若有Δij=0,则在保证各样本点对第i类聚类中心的距离尺度不变的前提下,在计算各样本相对于第i类的隶属度前,对所有Δij≥0的利用函数P(Δij)进行投影,如式(16)所示:
|
(16) |
此处
由于式(4)可保证各聚类中心的硬划分区域不会重叠[13],所以Δij < 0表明样本点xj落在第i类硬划分区域内,计算得μij < 0,对μij按照式(17)进行硬划分调整:
|
(17) |
2) ωik的讨论
由式(13)可知,ωik的大小是由样本点距离硬划分区域的距离和μij共同确定的,记:
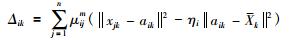
|
(18) |
因为第i类硬划分样本点仅对该类权重计算有效而对其它类无效,μij=1和μi′j=0保证了这点.
若Δik=0,则表明所有样本的第k个属性对第i类的影响一样,所以ωik=0.
若Δik < 0,表明所有样本的第k个属性对于第i类分布不均衡且该属性对第i类分类有影响,因此需将所有小于0的Δik以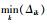
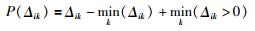
|
(19) |
利用式(19)所示的投影函数P(Δik)对Δik进行调整后再按式(13)计算ωik.
2.3 算法步骤步骤1 设置隶属度指数m、属性加权指数α、β,初始迭代次数p=0及迭代误差ε>0,随机生成初始聚类中心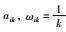
步骤2 根据式(4)计算ηi.
步骤3 根据式(12)、式(16)、式(17)更新隶属度μij.
步骤4 根据式(13)、式(19)计算特征权重ωik.
步骤5 根据式(14)计算聚类中心aik.
步骤6 p=p+1,直到maxi|a′i-ai| < ε;否则转到步骤2.
3 实验本文采用UCI respository of machine learning databases[21]的8个真实数据集进行实验(包含典型的分布均衡数据集和非均衡数据集),表 1给出了详细的数据信息描述.
| 数据集 | 样本数 | 维数 | 类别数(各类数据分布) |
| Wine | 205 | 3 | 2(59;71;48) |
| Iris | 150 | 4 | 3(50;50;50) |
| Balance-scale | 625 | 4 | 3(288;288;49) |
| bupa | 345 | 6 | 2(145;200) |
| Australian | 690 | 14 | 2(383;307) |
| Breast Cancer | 569 | 30 | 2(212;357) |
| Pimah | 377 | 30 | 2(500;286) |
| Ionosphere | 351 | 34 | 2(225;126) |
实验中模糊指数m分别设为1.5,2,2.5,3,3.5;迭代误差精度取10-6;CFWFCS算法中的参数β分别设为0.005,0.05,0.5,1;实验重复10次,考察最优结果和平均结果.用Rand(RI)[22]指标评价算法分类的准确度,用Xie-Beni(XB)[23]和Within-Between(WB)[24]指标评价算法的类内紧致度和类间离散度.实验机器配置为Intel Core i5-3210 M,主频为2.5 GHz,内存为8 GB,操作系统为64位Win 10.
3.1 算法基本性能分析 3.1.1 算法聚类中心、收敛性和硬划分特性为表示样本分布不均衡情况,对Iris数据集保留第1类、第2类所有数据并从第3类数据中随机选取10个样本,用geometric mean(G-mean)指标[25]评价算法整体分类性能,值越大表明算法对少数类聚类性能越好.图 2~图 5是CFWFCS算法对非均衡处理后的Iris数据集聚类结果在β不同取值对应的聚类中心、算法收敛性和硬划分特性的直观表示.

|
| 图 2 β=1,硬划分样本数=79 Figure 2 β=1, hard-classification number=79 |

|
| 图 3 β=0.5,硬划分样本数=64 Figure 3 β=0.5, hard-classification number=64 |

|
| 图 4 β=0.05,硬划分样本数=42 Figure 4 β=0.05, hard-classification number=42 |

|
| 图 5 β=0.005,硬划分样本数=0 Figure 5 β=0.005, hard-classification number=0 |
图 2(a)~图 5(a)中的3类聚类中心间距变化如表 2所示.
| 距离 | β=1 | β=0.5 | β=0.05 | β=0.005 |
| d12 | 51.295 3 | 37.454 5 | 31.052 7 | 30.695 6 |
| d13 | 70.536 7 | 52.566 1 | 40.721 5 | 40.743 4 |
| d23 | 20.731 8 | 16.633 7 | 12.249 0 | 12.518 9 |
当β由1减小到0.05时,系统模糊度增加,表现为3类聚类中心逐渐靠拢;由于第3类样本数远比第1类、第2类少且与第2类有重叠,为了使样本类内紧致同时也使类间散布尽可能大,所以当β取0.005时,第1类、第3类中心距离和第2类、第3类中心距离相对β=0.05时反而稍微增大一点.
图 2(b)~图 5(b)中随着β=0.05由1到0.005逐渐减小,110个样本中相应的硬划分样本数为79、64、42、0,说明β取值越大算法的硬划分程度越高.
可借助混淆矩阵[26]来进一步查看聚类情况.表 3是通过混淆矩阵得到的β不同取值对应的各类样本划分情况.其中,Pi表示被正确划分到第i类的样本数,Ni表示被错误划分到第i类的样本数(i=1,2,3).第1类样本总能正确被划分,β减小系统硬划分程度减小,第2类、第3类样本存在误划分(如β=0.5时),当β=0.005时各类聚类中心在自适应调整,所以相对β=0.05时第2类、第3类样本的误划分数都减小了.
| β | P1 | N1 | P2 | N2 | P3 | N3 | G-mean |
| 1 | 50 | 0 | 50 | 2 | 8 | 0 | 0.929 0 |
| 0.5 | 50 | 0 | 48 | 2 | 8 | 2 | 0.916 6 |
| 0.05 | 50 | 0 | 34 | 1 | 9 | 16 | 0.850 4 |
| 0.005 | 50 | 0 | 35 | 1 | 9 | 15 | 0.858 6 |
采用平均误分率考察参数α、β、m的不同组合时聚类性能,如图 6所示.

|
| 图 6 参数α、β、m对聚类结果的影响 Figure 6 the Influence of α、β、m on classification results |
图 6显示β越小,误分率越大;无论β取什么值,对同一个β,α=2、m∈{1.5,2},平均误分率最小且β < 0.5时,算法对α、m取值较敏感.
图 6(a)β=1、α>3时,m取整数(2、3)时是α越大误分率越小,否则是α越小误分率越小;α < 0时误分率随着α变小而变小,m则影响不大.
图 6(b)~图 6(d)显示当β < 1时,算法受α、m影响的趋势基本一致,对实验中采用的某一任意α有m越大误分率越大;对实验中采用的某一任意m(不考虑α=2的最优情况),若α>0则越大误分率越小,若α < 0则α越小误分率越小.
3.2 实验结果分析4种算法对8个数据集聚类最优参数如表 4所示.
| 数据集 | CFWFCS | ESSC | WFCM | FCS | ||||
| m | α | β | γ | η | α | β | β | |
| Australian | 1.5 | -8 | 1 | 1 000 | 0.9 | -9 | 1 | 1 |
| Breast Cancer | 3 | -10 | 0.005 | 5 | 0.5 | -6 | 1 | 1 |
| Balance-scale | 1.5 | 10 | 1 | 100 | 0.7 | 4 | 0.01 | 0.005 |
| Iris | 1 | 2 | 1 | 1 | 0.01 | 2 | 1 | 1 |
| Pima | 1.5 | -5 | 1 | 100 | 0.2 | -4 | 1 | 1 |
| Wine | 2 | 9 | 0.5 | 50 | 0.01 | -1 | 1 | 0.5 |
| Ionosphere | 2 | -1 | 1 | 50 | 0.01 | 9 | 1 | 1 |
| bupa | 3 | 6 | 1 | 2 | 0.01 | 10 | 0.005 | 0.005 |
以Iris数据集考察4种算法的收敛性,因4种算法的目标函数不一样,所以对4种算法的目标函数进行了归一化,结果如图 7,显见未考虑加权的FCS算法的目标函数值远高于其它3个考虑加权的聚类算法,根据目标函数最小化原则可知,加权的聚类算法由于未考虑加权的聚类算法.图 7中,CFWFCS算法迭代7次即收敛,ESSC算法迭代11次收敛,WFCM算法迭代26次收敛,FCS算法迭代27次收敛.

|
| 图 7 4种算法的收敛性 Figure 7 Convergence of the four algorithms |
4种算法对8个数据集聚类的RI指标如表 5所示(其中mean表示10次聚类平均值,std表示标准差,结果保留4位小数),该指标值越大表明聚类准确性越高.
| 数据集 | 指标 | CFWFCS | WFCM | ESSC | FCS |
| Australian | mean std |
0.723 1 0.060 5 |
0.755 9 0.000 0 |
0.691 9 0.107 0 |
0.730 2 0.012 5 |
| Breast Cancer | mean std |
0.892 4 0.007 7 |
0.883 2 0.012 5 |
0.877 0 0.006 3 |
0.872 1 0.000 0 |
| Balance-scale | mean std |
0.593 10 0.009 5 |
0.592 7 0.017 5 |
0.600 0 0.029 0 |
0.620 1 0.066 2 |
| Iris | mean std |
0.949 5 0.000 0 |
0.943 8 0.018 1 |
0.915 5 0.012 6 |
0.879 7 0.000 0 |
| Pima | mean std |
0.561 6 0.018 9 |
0.555 0 0.000 0 |
0.556 5 0.000 4 |
0.557 6 0.000 0 |
| Wine | mean std |
0.925 3 0.003 0 |
0.922 9 0.007 3 |
0.932 3 0.010 0 |
0.955 1 0.000 0 |
| Ionosphere | mean std |
0.596 2 0.000 0 |
0.586 5 0.033 0 |
0.588 9 0.000 0 |
0.490 3 0.000 0 |
| bupa | mea std |
0.506 0 0.004 2 |
0.502 1 0.002 8 |
0.502 4 0.000 2 |
0.460 7 0.000 0 |
由表 5可见,本文的CFWFCS算法对除Australian数据集、Banlance-scale数据集和Wine数据集以外的5个数据集获得了最好分类结果,考虑了类内紧致和类间散布的CFWFCS和FCS算法对非均衡数据集Balance-scale、Ionosphere和bupa的聚类结果高于其它两个算法.
表 6和表 7分别列出了4种算法对8个数据集聚类的XB指标及WB指标结果.
| 数据集 | 指标 | CFWFCS | WFCM | ESSC | FCS |
| Australian | mean std |
0.052 8 0.031 9 |
0.073 9 0.000 0 |
0.720 0 0.091 8 |
0.199 5 0.026 7 |
| Breast Cancer | mean std |
0.306 5 0.081 4 |
0.306 2 0.075 1 |
0.296 1 0.032 5 |
0.109 4 0.000 0 |
| Balance-scale | mean std |
0.247 2 0.103 5 |
0.395 0 0.175 8 |
0.687 1 0.015 2 |
2.847 5 0.097 9 |
| Iris | mean std |
0.254 3 0.046 3 |
0.114 1 0.016 4 |
0.199 0 0.006 4 |
0.175 1 0.000 0 |
| Pima | mean std |
0.179 3 0.058 6 |
0.456 3 0.000 0 |
0.718 2 0.022 6 |
0.244 3 0.000 0 |
| Wine | mean std |
0.239 8 0.087 8 |
0.420 9 0.072 27 |
0.502 2 0.002 4 |
0.257 7 0.000 0 |
| Ionosphere | mean std |
1.860 0 0.029 9 |
0.188 8 1.865 4 |
0.702 4 0.016 9 |
2.101 9 0.000 0 |
| bupa | mean std |
0.142 8 0.068 2 |
2.752 7 1.842 5 |
0.269 3 0.064 9 |
1.126 7 0.000 4 |
| 数据集 | 指标 | CFWFCS | WFCM | ESSC | FCS |
| Australian | mean std |
0.6227 0.186 1 |
0.758 6 0.000 0 |
6.195 6 0.746 5 |
1.597 1 0.214 5 |
| Breast Cancer | mean std |
2.697 1 0.011 4 |
2.715 2 0.015 4 |
2.918 2 0.010 8 |
2.451 0 0.000 0 |
| Balance-scale | mean std |
1.271 3 0.058 1 |
2.267 9 0.242 7 |
6.041 6 0.086 5 |
25.619 1 0.713 5 |
| Iris | mean std |
0.344 5 0.022 8 |
0.180 6 0.002 1 |
0.457 3 0.002 6 |
0.536 6 0.000 0 |
| Pima | mean std |
1.462 4 0.473 9 |
5.396 8 0.000 0 |
6.426 1 0.001 3 |
2.282 8 0.000 0 |
| Wine | mean std |
0.815 7 0.020 3 |
2.465 0 0.023 0 |
3.123 0 0.004 4 |
0.860 0 0.000 0 |
| Ionosphere | meanstd | 1.549 1 0.000 0 |
15.905 3 17.602 3 |
5.795 1 0.000 0 |
1.885 7 0.000 0 |
| bupa | mean std |
1.155 6 0.231 8 |
25.933 7 24.147 5 |
3.917 4 0.067 5 |
2.920 6 0.000 0 |
XB和WB指标值越小说明类内越紧密、类间划分越清晰、分类越合理.
对照表 5~表 7可知,RI指标值越大并不意味着XB指标值和WB指标值越小,说明没有哪个算法对所有数据集都优于其它算法. CFWFCS算法对所用的大多数数据集都拥有最小的XB值和WB值.
4种算法聚类平均性能如图 8所示,虽然4种算法的RI指标性能相近,但明显由于目标函数中引入了簇特征加权并考虑了类内紧致度、类间散布度,本文CFWFCS算法和ESSC算法明显优于其它没有考虑加权或没有考虑类间散布的聚类算法,又由于CFWFCS迭代过程中自动更新平衡参数ηi,因此聚类结果更合理,对少数类分类性能更好.

|
| 图 8 4种算法聚类平均性能 Figure 8 Average clustering performance of four algorithms |
在实际工程应用中,往往需要对非均衡数据聚类以获取各类特征,因此本文提出了一种簇特征加权的模糊散布紧致聚类算法,该算法考虑了样本的类内紧致性和类间散布性,及每个属性对簇划分的影响,解决了分布不均衡数据的聚类问题,分析了算法性能并修正了FCS算法无法处理硬划分边界点数据的问题.下一步的工作是找出寻求最优参数组合方法并尽量弱化算法对参数的敏感性.
| [1] | He H, Garcia E A. Learning from imbalanced data[J]. IEEE Transactions on Knowledge and Data Engineering, 2009, 21(9): 1263–1284. DOI:10.1109/TKDE.2008.239 |
| [2] | Galar M, Fernandez A, Barrenechea E, et al. A review on ensembles for the class imbalance problem:Bagging-, boosting-, and hybrid-based approaches[J]. IEEE Transactions on Systems, Man, and Cybernetics, Part C:Applications and Reviews, 2012, 42(4): 463–484. DOI:10.1109/TSMCC.2011.2161285 |
| [3] | Bekkar M, Alitouche T A. Imbalanced data learning approaches review[J]. International Journal of Data Mining & Knowledge Management Process, 2013, 3(4): 15. |
| [4] |
陶新民, 郝思媛, 张冬雪, 等.
不均衡数据分类算法的综述[J]. 重庆邮电大学学报(自然科学版), 2013, 25(1): 101–110.
Tao X M, Hao S Y, Zhang D X, et al. Overview of classification algorithms for unbalanced data[J]. Journal of Chongqing University of Posts and Telecommunications (Natural Science Edition), 2013, 25(1): 101–110. |
| [5] | Guo H X, Li Y J, Shang J, et al. Learning from class-imbalanced data:Review of methods and applications[J]. Expert Systems with Applications, 2017, 73: 220–239. DOI:10.1016/j.eswa.2016.12.035 |
| [6] | Sun Z, Song Q, Zhu X, et al. A novel ensemble method for classifying imbalanced data[J]. Pattern Recognition, 2015, 48(5): 1623–1637. DOI:10.1016/j.patcog.2014.11.014 |
| [7] | Nekooeimehr I, Lai-Yuen S K. Adaptive semi-unsupervised weighted oversampling (A-SUWO) for imbalanced datasets[J]. Expert Systems with Applications, 2016, 46: 405–416. DOI:10.1016/j.eswa.2015.10.031 |
| [8] | Wang X, Wang Y, Wang L. Improving fuzzy c-means clustering based on feature-weight learning[J]. Pattern Recognition Letters, 2004, 25(10): 1123–1132. DOI:10.1016/j.patrec.2004.03.008 |
| [9] | Li J, Gao X, Jiao L. A new feature weighted fuzzy clustering algorithm[J]. Acta Electronica Sinica, 2006, 34(1): 412–420. |
| [10] | Li D, Gu H, Zhang L. Fuzzy C-means algorithm with interval-supervised attribute weights[J]. Control and Decision, 2010, 25(3): 457–460. |
| [11] | Wang Q, Ye Y, Huang J Z. Fuzzy k-means with variable weighting in high dimensional data analysis[C]//The Ninth International Conference on Web-Age Information Management. Piscataway, NJ, USA: IEEE, 2008: 365-372. |
| [12] | Wu K L, Yu J, Yang M S. A novel fuzzy clustering algorithm based on a fuzzy scatter matrix with optimality tests[J]. Pattern Recognition Letters, 2005, 26(5): 639–652. DOI:10.1016/j.patrec.2004.09.016 |
| [13] |
宋枫溪, 程科, 杨静宇, 等.
最大散度差和大间距线性投影与支持向量机[J]. 自动化学报, 2004, 30(6): 890–896.
Song X F, Cheng K, Yang J Y, et al. Maximum scatter difference, large margin linear projection and support vector machines[J]. Acta Automatic Sinica, 2004, 30(6): 890–896. |
| [14] |
宋枫溪, 张大鹏, 杨静宇, 等.
基于最大散度差鉴别准则的自适应分类算法[J]. 自动化学报, 2006, 32(4): 541–549.
Song F X, Zhang D P, Yang J N, et al. Adaptive classification algorithm based on maximum scatter difference discriminant criterion[J]. Acta Automatic Sinica, 2006, 32(4): 541–549. |
| [15] |
皋军, 王士同.
基于模糊最大散度差判别准则的聚类方法[J]. 软件学报, 2009, 20(11): 2939–2949.
Gao J, Wang S T. Fuzzy maximum scatter difference discriminant criterion based clustering algorithm[J]. Journal of Software, 2009, 20(11): 2939–2949. |
| [16] |
支晓斌, 范九伦.
基于模糊最大散度差判别准则的自适应特征提取模糊聚类算法[J]. 电子学报, 2011, 39(6): 1360–1361.
Zhi X B, Fan J L. Adaptive feature extraction fuzzy clustering algorithm based on fuzzy maximum scatter difference discriminant criterion[J]. Acta Electronica Sinica, 2011, 39(6): 1360–1361. |
| [17] | Deng Z, Choi K S, Chung F L, et al. Enhanced soft subspace clustering integrating within-cluster and between-cluster information[J]. Pattern Recognition, 2010, 43(3): 767–781. DOI:10.1016/j.patcog.2009.09.010 |
| [18] | Jing L, Ng M K, Huang J Z. An entropy weighting k-means algorithm for subspace clustering of high-dimensional sparse data[J]. IEEE Transactions on Knowledge & Data Engineering, 2007, 19(8): 1026–1041. |
| [19] | Yu J, Cheng Q, Huang H. Analysis of the weighting exponent in the FCM[J]. IEEE Transactions on Systems, Man, and Cybernetics, Part B:Cybernetics, 2004, 34(1): 634–639. DOI:10.1109/TSMCB.2003.810951 |
| [20] | Huang J Z, Ng M K, Rong H, et al. Automated variable weighting in k-means type clustering[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27(5): 657–668. DOI:10.1109/TPAMI.2005.95 |
| [21] | UC Irvine machine learning repository[DB/OL].[2017-03-01]. http://www.ics.uci.edu/~mlearn/MLRepository.html. |
| [22] | Rand W M. Objective criteria for the evaluation of clustering methods[J]. Journal of the American Statistical association, 1971, 66(336): 846–850. |
| [23] | Xie X L, Beni G. A validity measure for fuzzy clustering[J]. IEEE Transactions on pattern analysis and machine intelligence, 1991, 13(8): 841–847. DOI:10.1109/34.85677 |
| [24] | Zhao Q, Fränti P. WB-index:A sum-of-squares based index for cluster validity[J]. Data & Knowledge Engineering, 2014, 92: 77–89. |
| [25] | Kubat M, Holte R C, Matwin S. Machine learning for the detection of oil spills in satellite radar images[J]. Machine learning, 1998, 30(2/3): 195–215. DOI:10.1023/A:1007452223027 |
| [26] | Provost F J, Fawcett T, Kohavi R. The Case Against Accuracy Estimation for Comparing Induction Algorithms[C]//Fifteenth International Conference on Machine Learning. San Francisco, CA, USA: Morgan Kaufmann Publishers Inc., 1997: 445-453. |