



0 引言
时间序列数据挖掘是近年来数据挖掘领域的热点研究内容[1],在金融、工业、农业、气候等领域应用尤为广泛.如何从庞大的历史数据库中挖掘出有价值的信息和知识,是目前时间序列数据挖掘的目标所在[2].时间序列数据不同于传统静态数据,它具有“高维、海量”等特性[3],由于数据随时间变化而变化,在实际应用中易受环境影响而产生噪声.因此,直接对原始数据进行挖掘建模不仅计算复杂,且会影响后续结果分析预测的准确性.
对于时间序列数据,其趋势特征是一个重要信息,它直观地反映了时间序列的变化模式[4].提取时间序列的趋势特征,压缩数据,对提高数据挖掘算法性能有重要意义.为此,人们提出了时间序列特征表示方法,将原始时间序列映射到另一论域中,并保留其主要特征[5].目前常见的时序数据特征表示方法包括频域表示法(如傅里叶变换和离散小波变换)[6]、符号化表示[7]、奇异值分解法[8]、经验模态分解法[9]和分段线性表示法[10]等.傅里叶变换等信号处理方法一般基于点距离,无法描述时序数据的动态特性,而分段线性表示法(piecewise linear representation,PLR)[11]具有形式直观、时间多解析性、维数约简度高等优点,目前得到了广泛应用.传统的PLR算法如Keogh的自底向上的分段线性化方法[12-13]、Keogh[14]和Yi[15]的时间序列PAA分段表示算法等,对原始数据分段均采用单一的拟合误差作为依据,其分段拟合难以达到理想效果.为了提高算法本身的通用性、降低时间复杂度,许多学者进行了这方面的研究,如陈帅飞等[16]提出的一种基于关键点的时间序列分段方法,Sanghyun等[17]提出的用特征点作为时间序列的分段点,廖俊[11]和尚福华[18]的基于趋势转折点的分段线性表示等.上述基于PLR方法均对时间序列的趋势提取、数据压缩起到良好的效果,但是其中关键点、特征点、转折点及其评价函数均使用相邻3点的关系来确定,属于局部分析方法,难以反映整体趋势,且其输入参数的选取对算法性能影响较大,结果不稳定.
为了更好地发掘时间序列的变化模式,本文在时间序列PLR的基础上,提出了基于重要点双重评价因子的时序趋势提取算法,创造性地提出了时间序列重要点距离因子的概念,并将两种评价因子相结合对时间序列重要点进行评价,以此为依据选取分段点.既保留了分段线性表示法的所有优点,又避免了传统PLR算法评价函数单一以及局部分析方法输出结果不稳定的缺点,可以有效削弱噪声干扰,实现时间序列变化趋势信息的准确提取.
1 基于分段线性化的时间序列分段趋势表示时间序列分段线性近似表示算法由Keogh[12]于1997年引入时间序列数据挖掘领域.该方法将原时间序列曲线用若干条首尾相接的直线段近似代替,直接提取其线性结构特征,有利于发现时间序列相似变化模式,对原始数据进行了有效地压缩,且能直观反映时序曲线变化趋势.该方法简单易实现,应用广泛.为了更好地说明该方法,下面给出时间序列的相关定义,如表 1所示.
| 变量 | 含义 |
| X={x(ti)}i=1n | 时间序列 |
| X*={xq*}q=1m | 重要点序列 |
| pq | 第q个重要点的位置 |
| D(xq*) | 第q个重要点距离因子 |
| Q(xq*) | 第q个重要点趋势因子 |
| J(xq*) | 第q个重要点综合评价值 |
| N | 分段数 |
| ε | 距离因子阈值 |
| β | 距离因子权值 |
| E | 拟合误差 |
定义1 (时间序列) 时间序列X={X(ti)}i=1n为n项数据记录组成的有限集合,其中X(ti)为在ti时刻的记录值,t1<t2<…<tn,每一个数据记录包括记录时间及M种不同属性值,X(ti)={ti,x1(ti),x2(ti),…,xM(ti)}.
上述定义中,属性值是随时间动态变化的,标号ti以合适的粒度表示(如分钟).本文研究只有一种属性的时间序列,即M=1,此时可将时间序列记为X={x(ti)}i=1n.
Keogh的分段线性化方法以最小化原时间序列与其分段线性近似表示之间的残差平方和为目标,通过寻找最佳分段位置并计算每一分段区间上的最优线性函数来拟合原始曲线.然而,该单一目标函数不能保证时间序列的每个分段内只具有一种基本趋势(如上升、下降、平稳),致使时间序列的某些点的基本趋势被错误提取;同时,原序列中重要数据点被线性拟合的数据点代替,在原始曲线本身存在噪声时此线性近似难以反映真实变化情况.
在时间序列分段线性化的同时,需要保留原始重要数据点,如达到一定变化幅度的极值点或是局部极值点,这些数据点保存着时间序列变化的主要特征模式[18].此外,相邻重要数据点之间的趋势不能被错误提取,因此必须找出趋势变化的重要转折点,将其作为分段点保留,相邻分段点间的数据可以通过直线插补来拟合.因此,本文采用的分段线性模型表示如下:
定义2 (分段线性表示模型) 时间序列X={x(ti)}i=1n分为N段的PLR模型表示为
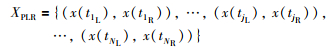
|
(1) |
其中,jL,jR∈{1,2,…,n}为第j分段左右端点在时间序列中的位置,1L=1,NR=n.其分段趋势特征如图 1所示.

|
| 图 1 时间序列分段基本趋势 Figure 1 The basic segmentation trend of time series |
将时间序列分段线性表示可以有效过滤噪声并压缩数据,更高效地提取时间序列的变化趋势特征.时间序列分段线性表示与原序列之间存在的拟合误差定义如下:
定义3 (时间序列PLR拟合误差) 设时间序列X={x(ti)}i=1n通过PLR算法得到时间序列的分段线性表示为XPLR,对其线性插值,得到时间序列Xc={xc(t1),…,xc(ti),…,xc(tn)},那么该PLR表示与原始时间序列之间的拟合误差为[19]
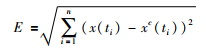
|
(2) |
时间序列分段线性表示中,为了准确刻画时序趋势变化,分段点的选取尤为重要.在数据挖掘领域,时间序列的极值点一般都具有重要意义[20].它带有较多的信息,是时间序列趋势的自然转折点.文[21]根据极值点概念给出了时间序列重要点的定义.
定义4 (时间序列重要点) 给定时间序列X={x(ti)}i=1n.定义X的第q个重要点为xq*=x(tpq),其中pq∈{1,2,…,n}表示第q个重要点在时间序列中的位置. x(tpq)为满足以下关系的数据记录:
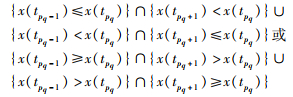
|
(3) |
此外,规定一个有限长度的时间序列起点和终点为重要点.由定义可知,重要点是孤立的局部极值点.位于重要点前后的时序数据变化趋势是完全不同的,而相邻重要点之间具有相同的基本趋势,它是趋势变化的自然转折点.
上述定义中重要点是根据相邻3点的关系来确定的,具有一定局部性.在噪声干扰时所求重要点中有一部分是干扰点,其特点是具有局部性,且与相邻点的差异程度较小,这些点不能够作为分段点.另外,对于每个重要点而言,其对整体趋势的影响程度不一.因此需要有评价因子对其进行评价,以此作为依据从中选取分段点.为了滤除噪声干扰,保留对整体趋势影响大的重要点,本文采用距离因子和趋势因子作为重要点的评价因子.
定义5 (距离因子) 给定重要点序列X*={xq*}q=1m,xq*=x(tpq),定义重要点xq*与其相邻K点的差异程度为距离因子:
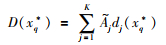
|
(4) |
式中,K=min{|pq-1-pq|,|pq+1-pq|},即xq*与其相邻最近重要点之间的数据点个数;dj(xq*)为重要点xq*=x(tpq)到点x(tpq-j)和点x(tpq+j)的正交距离,其具体表示如图 2所示. 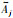
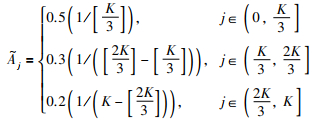
|
(5) |

|
| 图 2 重要点正交距离示意图 Figure 2 Illustration for orthogonal distance of important points |
式(5)中,将重要点的相邻区间分为3个部分,距离重要点越近的区间其正交距离权重系数越高,对重要点距离因子的贡献越大.
图 2中虚线所示即为正交距离,当x(tpq)变到x′(tpq)位置时,其相应正交距离由dj增大到d′j,即当重要点与其相邻点的差异程度越大时,其正交距离越大,相应地,由K点差异程度所确定的距离因子也越大.
本文距离因子定义参考了文[22]中的三角形中线距离,但是其仅用相邻3点所确定的三角形中线距离来度量差异程度,并以此作为时间序列关键点选取依据,结果易受噪声影响.而本文距离因子由两个重要点之间相邻K点的正交距离确定,对重要点的评价结果更为可靠.
距离因子在局部范围内衡量重要点的相对差异程度,距离因子越大的点与其相邻点的差异程度越大,其是重要转折点的可能性越大,而距离因子越小的点是干扰极值点的可能性越大,可以通过选择合适的阈值去除干扰点.但是距离因子不能在全局上衡量每个重要点对整体趋势的重要程度,且时间序列的起点与终点无法用距离因子评价,仅用距离因子作为重要点评价因子是不够的.因此,下面给出重要点趋势因子的概念,作为另一评价因子.
定义6 (趋势因子) 给定重要点序列X*={xq*}q=1m,xq*=x(tpq),定义第q个重要点xq*=x(tpq)对整体趋势的影响程度为趋势因子Q(xq*),若x(tpq)(pq∈{1,2,…,n})满足:
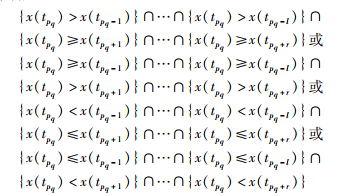
|
其中,1≤pq-l<n,1<pq+r≤n,则趋势因子Q(xq*)的值为
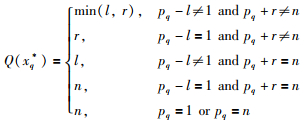
|
(6) |
定义6中比较每个重要点与1≤(l+r)≤n个点(包括其他重要点)的关系来确定趋势因子,从全局上充分考虑每个重要点对整体趋势的影响,趋势因子值越大,该重要点对整体趋势的贡献越大,在分段时应予以保留.由趋势因子的定义可以看出,时序数据的起点和终点,以及全局的最大、最小值都具有最大的趋势因子值,即Q(xq*)=n.
2.2 时间序列趋势提取算法本文提出基于重要点双重评价因子的趋势提取方法,将具有局部性的距离因子和具有全局性的趋势因子相结合对时间序列重要点进行综合评价,为后续剔除干扰点和选取合适数目的重要点作为分段点来对时间序列进行分段线性趋势表示提供依据.重要点综合评价模型如下:
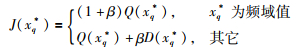
|
(7) |
式(7)中,D(xq*)为重要点xq*的距离因子,Q(xq*)为其趋势因子,β为距离因子的权值.
该重要点综合评价模型将重要点距离因子与趋势因子相结合,评价重要点对整体趋势的重要程度.在上述模型中,由于时间序列的起点与终点无法用距离因子评价,故其综合评价值由趋势因子确定.此外,由于距离因子属于局部因子,其重要程度比全局性的趋势因子低,故其权值为0<β<1.
对时间序列重要点进行综合评价排序确定分段点获取趋势具体算法步骤如下:
给定:时间序列X={x(ti)}i=1n,所需分段数N,分段点数N+1,距离因子阈值ε,权值β.
1) 获取初始重要点序列.根据重要点定义提取时间序列X的重要点作为分段点备选集,记为X*={xq*}q=1m,xq*=x(tpq),其中pq∈{1,2,…,n}表示第q个重要点在时间序列中的位置,并按定义5计算时间序列重要点的距离因子,将D(xq*)<ε的干扰点去除,将去除干扰点后的重要点序列记为X*={xq*}q=1l,l≤m,当N+1>l时,设置的分段数N太大,不能剔除干扰点,程序结束.
2) 重要点综合评价排序.按定义6计算时间序列各重要点的趋势因子Q(xq*),按式(7)计算重要点综合评价值J(xq*),并按照其综合评价值从大到小的顺序将重要点进行排序,将排序后的重要点序列记为X*={xq*}q=1l.
3) 分段点确定.在综合排序后的时间序列重要点序列中选取前N+1个重要点,得到最终分段点序列和分段位置,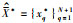
4) 提取趋势.将相邻位置的分段点依次用直线段连接起来,得到时间序列分段线性趋势表示,此时可以直观地看出时间序列的趋势变化情况.
本文算法流程图如图 3所示.

|
| 图 3 基于重要点双重评价因子的趋势提取算法流程图 Figure 3 The flow chart of trend feature extraction method for time series based on double evaluation factors of important points |
参数说明:在本文算法中,距离因子阈值ε和权值β是两个主要的参数.设置阈值ε的目的是过滤噪声,ε值过小时降噪效果不佳,导致过大的拟合误差;ε值过大时不仅会过滤噪声,还会过滤原时间序列中重要转折点,导致拟合误差的增大,同时可能会导致重要点数达不到分段数要求从而结束程序,其最大值不能超过距离因子平均值D.权值β用来调节距离因子对最终综合评价值的相对贡献大小,由于距离因子属于局部因子,重要程度比全局性的趋势因子低,故其权值为0<β<1. β过小时距离因子几乎不起作用,许多重要的局部趋势信息被丢弃,导致拟合效果变差,拟合误差增大;β过大时距离因子对综合评价结果影响太大,导致局部趋势信息过多提取,拟合误差增大,难以反映整体趋势.
参数确定:本文采用粒子群寻优算法结合十折交叉验证来确定模型参数,E选取使平均拟合误差最小的一组参数值作为最终模型参数,简要步骤为:
1) 将时间序列数据X={x(ti)}i=1n按照时间先后顺序均分成10等份{X1,X2,…,X10},轮流将其中9份作为训练数据,1份作为测试数据,计算训练集距离因子平均值D;
2) 初始化粒子群个体:设置种群大小m=20,最大更新代数Nmax=300,设置ε和β的取值范围ε∈(0,D),β∈(0,1);
3) 对每组训练集数据,用粒子群寻优算法找到使拟合误差E最小的一组参数(ε,β),其中拟合误差计算方法如式(2)所示,计算测试集在此组参数下的拟合误差E′,则10个数据集的平均拟合误差为E=(E+E′)/10;
4) 所有数据集均测试完毕后,选取使平均拟合误差E最小的一组(ε,β)作为最终参数.
3 实例分析 3.1 数值仿真验证实验数据:序列
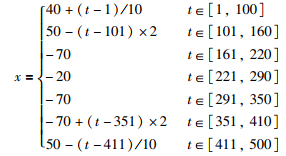
|
(8) |
t为整数,共500个数据.该组序列包含线性上升和下降、平稳及阶跃上升和下降几种模式,可以较全面地测试本文算法的性能.
实验方法:本文选择两种时间序列线性分段算法作为比较对象:
1) 自底向上的分段线性化方法[12](Keogh方法);
2) 基于趋势转折点的时间序列PLR方法[18](简称PLR-TP方法).
对序列X加上均值为μ、方差为σ的正态随机误差,比较不同情况下,本文方法、Keogh方法、PLR-TP方法对噪声的适应程度.序列X的几个分段趋势比较明显,在[1, 100]、[101, 160]、[161, 220]、[220, 221]、[221, 290]、[290, 291]、[291, 350]、[351, 410]、[411, 500]时间段,趋势分别为上升、下降、平稳、上升、平稳、下降、平稳、上升、下降.
实验中对序列X分别加上μ=0,σ=0.5,1,1.5,2,2.5,3的噪声.在分为9段的统一要求下,比较其拟合误差和分段趋势提取结果,显然,选取的重要点越接近原有趋势分段点,误差越小.实验结果如表 2和图 4所示,其中参数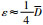
| PLR-TP方法 | Keogh方法 | 本文方法 | |
| σ=0.5 | 92.58 | 66.85 | 15.23 |
| σ=1.0 | 273.27 | 129.57 | 63.52 |
| σ=1.5 | 611.21 | 360.39 | 101.29 |
| σ=2.0 | 460.34 | 526.37 | 185.34 |
| σ=2.5 | 1 048.39 | 688.93 | 337.85 |
| σ=3.0 | 944.56 | 867.51 | 435.34 |

|
| 图 4 不同噪声下三种方法分段线性拟合结果 Figure 4 The pairwise linear fitting results with three methods under different noises |
表 2是不同噪声情况下的几种时间序列线性分段算法的拟合误差,由表可知,本文方法虽受噪声影响,但比另外2种方法拟合误差小,去除噪声的能力有所增强.
图 4是不同噪声情况下,不同方法的分段拟合效果图.可以看出,本文方法在不同噪声下对这9个分段基本趋势提取准确,而Keogh方法和PLR-TP方法均有明显错误,如图 4(a)中[220, 235]、[236, 291]时间段以及图 5(b)中[0, 100]、[101, 160]、[161, 220]、[221, 290]、[291, 350]、[421, 500]时间段均有趋势被错误提取.

|
| 图 5 分段线性拟合提取灰度变化趋势结果比较 Figure 5 Comparison of the results of trend extraction for with different linear fitting methods |
这是因为Keogh方法以逼近原时间序列为目标,原时间序列噪声越大时其拟合误差越大,且不能保证每一分段内只有一种基本趋势,即分段点选取不准确,导致某些点的基本趋势被错误提取. PLR-TP方法仅通过由相邻3点的关系选取变化幅度大的极值点和短期大波动数据点作为重要趋势转折点,属于局部分析方法,对于整体趋势的刻画效果不佳,选取结果不准确且具有偶然性,噪声增强时拟合结果不稳定,误差增长不平稳.这两种方法都受噪声影响较大,在噪声干扰下难以准确找出原序列分段点.而本文所提方法在全局上综合考虑每个重要点的重要程度,能滤除干扰,准确拟合原始序列趋势,在相同分段数下与其他两种方法相比提取趋势准确度有很大的提高.
3.2 工业实例应用泡沫浮选是根据不同矿物疏水性质的差异将有价矿物与脉石分离,获得品位高的矿物质,从而满足后续生产和应用的需要[23].典型的金锑矿泡沫浮选操作流程,包括粗选、精选、粗扫和精扫作业.实际生产中,加药量、充气量等诸多操作变量的调整都会引起浮选泡沫状态变化,进而影响精矿品位和回收率.通过分布机器视觉系统获取泡沫图像并从中提取出灰度、尺寸、纹理等信息,进而对泡沫图像进行趋势分析,可以获取泡沫图像特征变化的规律,预估浮选生产状态和变化趋势,为实现过程的自动监控提供指导信息,对于浮选过程的优化控制有着重要意义.
由于泡沫浮选现场诸多因素的干扰,获得的泡沫图像往往含有大量噪声,在经过小波变换等去噪处理后再提取出的泡沫图像各特征值中仍旧带有噪声干扰,增大了趋势准确提取的难度.为了验证本文方法的有效性,将其应用到泡沫灰度变化趋势提取中.
实验数据:选取基于分布机器视觉的金锑矿泡沫浮选过程在粗选槽获取的图像中提取的一组泡沫灰度数据,时间间隔为1 min,共400组数据,剔除异常值后作为原始数据.在这400 min内主要操作变量黄药剂量的改变如表 3所示,理论上,在一定范围内,黄药剂量的增大会使灰度值波动上升,而黄药剂量的减小会使灰度值波动下降,波动是化学药剂反应的不稳定性造成的.针对这组数据,分别用自底向上的分段线性化方法[12](Keogh方法)、基于趋势转折点的时间序列PLR方法[18](简称PLR-TP方法)和本文基于重要点双重评价因子的趋势提取方法分析泡沫灰度的变化趋势,给定分段数N=85,由粒子群算法确定的距离因子阈值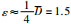
| 时间t /min | 黄药剂量 |
| [0,25) | 380 |
| [25,55) | 360 |
| [55,155) | 380 |
| [155,365) | 380 |
| [365,400) | 390 |
| 方法 | 拟合误差E |
| PLR-TP方法 | 906.87 |
| Keogh方法 | 487.53 |
| 本文方法 | 307.39 |
图 5(a)中,Keogh方法拟合曲线在[55,85]、[90, 125][155, 165]、[350, 365]等多个时间段均与原始曲线分段基本趋势不相符. 图 5(b)中PLR-TP方法拟合曲线在[10, 25]、[95, 126]、[155, 170]、[350, 365]等多个时间段与原始曲线分段基本趋势不相符.这是因为在Keogh的分段线性表示方法中,分段拟合的目标是最小化原时间序列与其线性近似表示之间的残差平方和,导致时间序列的某些点的基本趋势被错误提取;同时,原序列中重要数据点被线性拟合的数据点代替,导致拟合结果失真.而PLR-TP方法属于局部分析方法,过多地保留了局部趋势信息,对于整体趋势的刻画效果不佳.
本文方法将具有全局性的趋势因子和具有局部性的距离因子相结合作为分段点选取的依据,通过图 5中3种方法对比可以看出本文方法有较强的过滤局部噪声干扰的能力,相比Keogh方法和PLR-TP方法获取的灰度变化趋势更贴近其原有变化趋势.另外,从表 4中3种PLR表示的拟合误差对比可知,本文方法最大程度保留了原始数据特征,拟合误差最小. 图 5中,本文方法拟合曲线在[25, 55]时间段内,由于黄药剂量从380下降到360,灰度值呈现明显的波动下降趋势;在[55, 155]时间段,黄药剂量由360上升到380,灰度值呈现明显的波动上升趋势;在[155, 365]时间段,没有改变药剂量,灰度值变化呈平稳趋势;在[365, 400]时间段内,黄药剂量由380上升到390,灰度值再次呈现明显的波动上升趋势.基本上与理论估计相符,说明了本文方法对浮选泡沫图像灰度特征趋势提取的准确性.
4 结论本文在时间序列分段线性表示的基础上,研究重要点对过程数据整体趋势的重要程度,首次用重要点距离因子来度量数据点之间的差异程度,给出了重要点趋势因子和距离因子的定量计算方法,最后得到重要点综合评价模型,这是基于重要点双重评价因子的分段线性趋势表示方法的核心.重要点是趋势上升、下降和平稳的自然转折点,将其作为分段点可使基本趋势不被错误提取.同时,将具有局部性的重要点距离因子和具有全局性的趋势因子相结合作为选取分段点的度量依据,可以有效削弱噪声干扰,准确提取趋势.仿真实验证明了在相同分段条件下本文方法提取趋势准确度比Keogh方法和基于趋势转折点的时间序列PLR方法高.最后将本文方法应用于金锑矿泡沫浮选粗选槽获取的泡沫灰度数据,提取其变化趋势,并与基于趋势转折点的分段线性表示方法和Keogh方法对比,再次证明了所提方法对趋势提取的有效性和准确性.
| [1] |
郑宝芬.时间序列数据挖掘算法研究及其应用[D].杭州: 浙江大学, 2015. Zheng B F. Research and application of time series data mining algorithm[D]. Hangzhou: Zhejiang University, 2015. http://cdmd.cnki.com.cn/Article/CDMD-10335-1015305324.htm |
| [2] |
陈海燕, 刘晨晖, 孙博.
时间序列数据挖掘的相似性度量综述[J]. 控制与决策, 2017, 32(1): 1–11.
Chen H Y, Liu C H, Sun B. A survey of similarity measures in time series data mining[J]. Control and Decision, 2017, 32(1): 1–11. |
| [3] |
刘中华, 周静波, 陈燚, 等.
距离保持投影非线性降维技术的可视化与分类[J]. 电子学报, 2009, 37(8): 1820–1825.
Liu Z H, Zhou J B, Chen Y, et al. Distance visualization and classification of non-linear dimensionality reduction[J]. Journal of Electronics, 2009, 37(8): 1820–1825. DOI:10.3321/j.issn:0372-2112.2009.08.035 |
| [4] |
刘帆, 刘兵, 陈军, 等.
一种基于时序形态的航天器动态模式提取方法[J]. 飞行器测控学报, 2016, 35(3): 193–199.
Liu F, Liu B, Chen J, et al. A spacecraft dynamic pattern extraction method based on time series morphology[J]. Journal of Aircraft Measurement and Control, 2016, 35(3): 193–199. |
| [5] |
孙吉红.长时间序列聚类方法及其在股票价格中的应用研究[D].武汉: 武汉大学, 2011. Sun J H. Long time series clustering method and its application in stock price[D]. Wuhan: Wuhan University, 2011. http://cdmd.cnki.com.cn/Article/CDMD-10486-1015535112.htm |
| [6] |
熊英志.时间序列的特征表示与聚类方法研究[D].重庆: 重庆大学, 2016. Xiong Y Z. Research on time series representation and clustering method[D]. Chongqing: Chongqing University, 2016. http://cdmd.cnki.com.cn/Article/CDMD-10611-1016731606.htm |
| [7] |
刘博, 郭建胜.
改进的多元时间序列符号化表示方法研究[J]. 计算机仿真, 2015, 32(1): 314–317.
Liu B, Guo J S. Improved multivariate time series symbolic representation method[J]. Computer Simulation, 2015, 32(1): 314–317. DOI:10.3969/j.issn.1006-9348.2015.01.066 |
| [8] |
吴虎胜, 张凤鸣, 钟斌.
基于二维奇异值分解的多元时间序列相似匹配方法[J]. 电子与信息学报, 2014, 36(4): 847–854.
Wu H S, Zhang F M, Zhong B. Multivariate time series similarity matching method based on two-dimensional singular value decomposition[J]. Journal of Electronics & Information Technology, 2014, 36(4): 847–854. |
| [9] |
白朝阳, 胡子涵, 刘晓莹.
面向装备制造业的非平稳时间序列需求组合预测方法[J]. 信息与控制, 2017, 46(4): 495–502.
Bai C Y, Hu Z H, liu X Y. Combination forecasting method of non-stationary time series demand on the equipment manufacturing industry[J]. Information & Control, 2017, 46(4): 495–502. |
| [10] |
赵建秀, 王洪国, 邵增珍, 等.
一种基于信息熵的时间序列分段线性表示方法[J]. 计算机应用研究, 2013, 30(8): 2391–2394.
Zhao J X, Wang H G, Shao Z Z, et al. A piecewise linear representation of time series based on information entropy[J]. Computer Application Research, 2013, 30(8): 2391–2394. DOI:10.3969/j.issn.1001-3695.2013.08.037 |
| [11] |
廖俊, 于雷, 罗寰, 等.
基于趋势转折点的时间序列分段线性表示[J]. 计算机工程与应用, 2010, 46(30): 50–53.
Liao J, Yu L, Luo H, et al. Time series segmentation linear representation based on trend turning point[J]. Computer Engineering and Applications, 2010, 46(30): 50–53. |
| [12] | Keogh E. A fast and robust method for pattern matching in time series databases[C]//Proceedings of the 9th International Conference on Tools with Artificial Intelligence. Piscataway, NJ, USA: IEEE, 1997: 578-584. https://www.researchgate.net/publication/2758105_A_Probabilistic_Approach_to_Fast_Pattern_Matching_in_Time_Series_Databases |
| [13] | Keogh E, Chu S, Hart D, et al. An online algorithm for segmenting time series[C]//Proceedings of the 1st IEEE International Conference on Data Mining. Piscataway, NJ, USA: IEEE, 2001: 289-296. |
| [14] | Keogh E J, Chakrabarti K, Pazzani M J, et al. Dimensionality reduction for fast similarity search in large time series databases[J]. Journal of Knowledge and Information Systems, 2001, 3(3): 263–286. |
| [15] | Yi B K, Faloustsos C. Fast time sequence indexing for arbitrarylp norms[C]//Proceedings of the 26th International Conference on Very Large Data Bases. San Francisco: Morgan Kaufmann Publishers Inc, 2000: 385-394. https://www.researchgate.net/publication/243785467_Fast_Time_Sequence_Indexing_for_Arbitrary_Lp_Norms |
| [16] |
陈帅飞, 吕鑫, 戚荣志, 等.
一种基于关键点的时间序列线性表示方法[J]. 计算机科学, 2016, 43(5): 234–237.
Chen S F, Lu X, Qi R Z, et al. A time series linear expression method based on key points[J]. Computer Science, 2016, 43(5): 234–237. |
| [17] | Park S, Kim S W, Chu W W. Segment-based approach for subsequence searches in sequence databases[C]//Proceedings of the 16th ACM Symposium on Applied Computing. New York, USA: ACM, 2001: 248-252. https://www.researchgate.net/publication/2433429_Segment-Based_Approach_for_Subsequence_Searches_in_Sequence_Databases |
| [18] |
尚福华, 孙达辰.
基于时间序列趋势转折点的分段线性表示[J]. 计算机应用研究, 2010, 27(6): 2075–2077.
Shang F H, Sun D C. Segmentation linear representation based on time series trend turning point[J]. Computer Application and Research, 2010, 27(6): 2075–2077. DOI:10.3969/j.issn.1001-3695.2010.06.022 |
| [19] |
詹艳艳, 徐荣聪, 陈晓云.
基于斜率提取边缘点的时间序列分段线性表示方法[J]. 计算机科学, 2006, 33(11): 139–142.
Zhan Y Y, Xu R C, Chen X Y. Time-based piecewise linear representation method based on slope extraction edge point[J]. Computer Science, 2006, 33(11): 139–142. DOI:10.3969/j.issn.1002-137X.2006.11.038 |
| [20] |
肖辉, 胡运发.
基于分段时间弯曲距离的时间序列挖掘[J]. 计算机研究与发展, 2004, 42(1): 72–78.
Xiao H, Hu Y F. Time series mining based on piecewise time bending distance[J]. Computer Research and Development, 2004, 42(1): 72–78. |
| [21] |
周黔, 吴铁军.
基于重要点的时间序列趋势特征提取方法[J]. 浙江大学学报(工学版), 2007, 41(11): 1782–1787.
Zhou Q, Wu T J. Technologyof time series trend feature extraction based on important points[J]. Journal of Zhejiang University (Engineering Science), 2007, 41(11): 1782–1787. DOI:10.3785/j.issn.1008-973X.2007.11.003 |
| [22] |
杜奕, 卢德唐, 李道伦, 等.
基于三角形中线的数据序列线性拟合算法[J]. 计算机工程, 2008, 34(13): 21–23.
Du Y, Lu D T, Li D L, et al. Linear fitting algorithm of data sequence based on triangular midline[J]. Computer Engineering, 2008, 34(13): 21–23. DOI:10.3969/j.issn.1000-3428.2008.13.008 |
| [23] |
卢青, 王雅琳, 彭凯, 等.
EMD包络线拟合算法改进及在泡沫尺寸趋势提取中的应用[J]. 江南大学学报(自然科学版), 2015, 14(6): 695–702.
Lu Q, Wang Y L, Peng K, et al. Improvement of EMD envelope fitting algorithm and its application in foam dimension tendency extraction[J]. Journal of Jiangnan University (Natural Science Edition), 2015, 14(6): 695–702. DOI:10.3969/j.issn.1671-7147.2015.06.003 |