



2. 中国科学院机器人与智能制造创新研究院, 辽宁 沈阳 110016;
3. 北方重工集团有限公司, 辽宁 沈阳 110141;
4. 中国科学院大学, 北京 100049;
5. 中国科学院沈阳自动化研究所工业控制网络与系统研究室, 辽宁 沈阳 110016
2. Institutes for Robotics and Intelligent Manufacturing, Chinese Academy of Sciences, Shenyang 110016, China;
3. Northern Heavy Industries Group Co. Itd, Shenyang 110141, China;
4. University of Chinese Academy of Sciences, Beijing 100049, China;
5. Industrial Control Networks and Systems Department, Shenyang Institute of Automation, Chinese Academy of Sciences, Shenyang 110016, China
0 引言
选矿过程的磨矿系统是典型的基于数据驱动的工业过程优化控制系统,核心设备球磨机是磨矿系统的关键,而球磨机在生产过程中因其存在流程响应大滞后性、控制系统大惯性、多变量强耦合性、工作机理复杂等特点导致对其控制困难重重.随着球磨机大型化和智能化,传统的控制方法已不能满足现有需求,通过先进的控制方法保障设备平稳运行,提高生产效率,降低生产成本亟待解决.球磨机在运行过程中产生的运行数据中包含很多关联信息,目前对这些信息的使用主要是实时查看和存储历史数据查询,这是典型的“信息浪费”[1].如何用大数据进行挖掘分析已成为复杂工业过程优化控制的研究热点.同时,通过数据分析方法对设备的运行出现的故障进行诊断,已成为研究的难点之一.
故障诊断方法可分为两大类:基于传统数学解析模型的方法和基于数据驱动的人工智能优化模型的方法.
基于传统数学解析模型的故障诊断方法分为定量知识方法论法和数学解析模型法.
文[2]从复杂工业过程所可能具有的过程特性及数据存取过程中引入的数据特性分析出发,分别讨论了基于数据和基于知识方法进行故障诊断的优缺点发展方向.
文[3]提出基于主成分分析和贝叶斯网络相结合并简化算法,对不确定性问题的故障诊断,可以去除冗余信息,提高辨识正确率和诊断结果可靠性.
随着现代设备的大型化复杂化与非线性化,难以建立系统精确的数学模型,从而限制了基于传统数学解析模型故障诊断方法的应用.针对复杂工业过程优化控制系统的故障诊断,采用基于数据驱动的人工智能优化模型的方法以弥补该缺陷.
基于数据驱动的人工智能优化模型的故障诊断方法有信号处理法(谱分析和小波变换),统计分析法(单变量法和多变量法),信息融合法和智能机器学习法(如神经网络支持向量机和粗糙集)等.
文[4]采用信号处理法,提出利用小波变换对信号进行多尺度分析,提取信号在不同尺度上的特征用于故障诊断.
文[5]采用主元统计分析法(PCA),提出将系统高维历史数据组成矩阵,进行一系列矩阵运算后确定若干正交向量.
文[6]采用信息融合法,提出基于Type-2型模糊神经网络的多数据融合智能料位检测方法,将多传感器采集的变量参数按照模糊规则进行处理,并构造神经网络进行数据融合.
以上方法各自都有一定的局限性,信号处理法对信号采集的数据差异性依赖较大,对过程数据的处理方法有一定的要求;统计分析法的前提条件是需要历史数据作为训练数据,需要针对各种故障分类数据,对于多层次多尺度多范围的复杂系统是无法满足的;而信息融合方法通过利用不同传感器信息之间的互补和冗余关系,对多个信息源加以分析和综合,推算出精确的故障源位置,对于强耦合系统融合参数难以精确给出.
针对此问题研究方法多采用基于神经网络的人工智能优化模型诊断方法,其采取隐式表示,并将某一问题的若干知识表示在同一网络中,通用性高、便于实现,对知识的总体把握和联想推理.
文[7]针对神经网络极易陷入局部极小的问题,采用引入动量项和混沌映射的改进BP算法,讨论引入动量项和混沌映射的神经网络综合模型的建模思路及其算法实现,建立球磨机故障诊断的混沌神经网络模型.
文[8]采用多层感知器神经网络和系统辨识相结合的方法,运用Matlab系统辨识工具箱和神经网络工具箱,提出了由线性模型和非线性补偿模型组成的混合模型结构的精矿品位预报方法,建立了精矿品位预报模型.
传统的神经网络模型,优点是分类的准确度高,有较强的鲁棒性和容错能力,能够处理复杂的非线性函数并充分逼近复杂的非线性关系,并且能发现不同输入间的依赖关系.而缺点为需要大量的参数,学习过程无法观察且学习时间长.
文[9]针对故障诊断面临的故障样本少非线性强多故障处理等问题以及传统智能诊断方法存在的不足,提出了一种基于决策树(DT)和相关向量机(RVM)的智能故障诊断方法.通过构造决策二叉树,利用多个RVM进行二类分类,从而实现RVM的多类分类.
基于故障树的方法优点在于能够同时处理分类数据和数值数据,很容易处理变量之间的相互影响,适合小规模数据;缺点就是不擅长对数值结果进行预测.
在递归神经网络方面,自从LSTM的逻辑门结构获得了巨大成功,也有无数种LSTM的变体,如有窥视孔连接的LSTM[10]、门递归单元(GRU)[11]、深度门RNN[12],与可以追踪长程影响的发条RNN[13]等.然而,经过实验[14-15]证明,这些不同结构的LSTM的效果差别不大,所以,本文将采用应用最广泛的LSTM进行数据分析.
本文研究背景是针对磨矿过程中可能出现的故障进行预测,数据集的来源是磨矿工程中采集点长期以来采集到的数据集,然后对数据进行分析和数据预处理:对于故障的预测首先将其抽象成为一个监督问题,故障的类型也已经通过专业的人员标注出来,接下来需要确定输入向量维度、补全缺失数据、清洗噪声数据、定义故障表征方法,并进行数据关联分析建立起样本数据中特征向量与标签数据之间的映射关系.
数据集是每隔1 h在采集点处采集到的数据,因此具有相当强的时间相关性,整个数据集也可以看作是一个高维的时间序列,故障诊断问题也就转换成了一个关于时间序列的预测问题.传统的神经元网络针对时间序列预测问题表现不佳,近年来递归型神经网络(RNN)在时间序列预测领域有着很高的地位.本文采用的长短期记忆人工神经网络(long-short term memory,LSTM)是一种时间递归神经网络(RNN),用此网络来对本文数据集进行预测,达到了令人满意的结果.
1 数据分析与预处理以V型磨矿系统岗位记录数据集作为基础,对数据集分析研究,以便实现对磨矿系统在运行过程中所出现的故障进行分类预测.其中每隔一个小时对采集点(温度压力声音振动等)数据进行一次记录,总共1 000 h,30种测量指标.
通过观察,所有的测量指标里有部分指标是一些固有属性不会发生变化,这些指标区别性不太大,因此可以将这部分数据剔除掉.除此之外对数据进行了相应的可视化处理,发现有些指标之间存在着共线性的关系,耦合程度较大,这样不利于对模型进行预测分析,为了使数据更好地适配模型,在进行数据预处理的过程中可以有选择性的对数据进行选择和筛选,通过autoencoder的方法将数据集的纵向维度由30维降低为为24维,去掉无区分行特征和解耦特征.而对于数据集中所缺少的记录,本文利用相对应前后5 h之间的数据的均值进行填充.
对于磨矿生产过程中所出现的故障,一方面可能由设备本身引起,如轴承温度的异常;另一方面可能由工艺方面造成,如给料量的波动.本文对实际数据集中所发生的故障进行分析,最终的目的是要对故障进行诊断.数据集中对于故障已经进行了比较详细的说明,因此可以把该问题抽象成为监督学习问题,监督学习问题处理起来也比无监督学习问题简单一些.因此把这些故障作为标签(label),但是需要先对这些label进行一些处理.为了使网络更好地处理数据,对于这些数据的表征,本文采用“one-hot vector”表示,即对于第几类故障则在对应的位置上为1,其余的位置上为0,本文一共划分为8类故障,如表 1所示.
| 故障现象 | 故障原因 | 故障表征 |
| 正常 | 无 | 100 000 00 |
| 给矿压力低 | 进料端矿箱漏矿 | 010 000 00 |
| 给矿压力升高 | 旋流器穿孔 | 001 000 00 |
| 主电机电流低,离合器气罐压力低 | 气缸故障 | 000 100 00 |
| 主电机前后轴瓦油箱温度高 | 稀油站冷却水阀门损坏 | 000 010 00 |
| 主轴瓦给料右温度上升,供油压力给料右下降 | 油压低,轴瓦温度高 | 000 001 00 |
| 主轴瓦排料右温度升高,供油流量排料下降低 | 流量低,轴瓦温度升高 | 000 000 10 |
| 主电机温度高 | 油温高,油压低 | 000 000 01 |
由表 1可以看出,故障种类共分为进油压低、流量低、冷却水故障等8类故障,其中的几类指标相关性较强,比较难以辨识.通过分析数据,建立特征向量和目标之间的映射关系时发现:1 000组特征向量对应的标签其中有865类为无故障,135类为有故障的,为严重的不均衡分类情况.这里我们选择了其中的两维特征进行分析,如图 1所示.

|
| 图 1 第0,1维特征分类图 Fig.1 Classification of 0, 1 dimension |
图 1中,横纵坐标分别表示第0维特征(特征内容)与第1维特征(特征内容),每个图表示每种故障(或无故障)的分布特征.
由图 1可以看出8类故障中第一类故障(无故障)占了较大的比例,而其它故障所占的比例要小很多,这是严重的不均衡分类问题,同时,故障分布较分散,不利于分类器分类.
2 算法介绍 2.1 人工神经元网络首先,人工神经网络对于知识有很强的学习能力,由于可对数据进行并行处理,提高了其处理数据的速度.所以本文将神经网络技术应用于磨矿生产过程中的故障诊断,从而获得理想的诊断效果.
目前BP网络在众多的前馈型网络中应用较为广泛,其学习速度快,逼近能力和分类能力强,本文使用BP神经网络来对磨矿中的故障进行诊断,诊断系统功能结构见图 2.

|
| 图 2 磨矿神经网络故障诊断功能示意图 Fig.2 Function diagram of neural network fault diagnosis for mill |
传统的BP神经网络,容易陷入局部极小点,为了改善这个现象,选用“成批处理”的学习方法,这种方法在训练神经网络的过程中,不受学习样本排序的影响,加快收敛速度;并采用了学习率自调整的方法.本文构建的BP神经网络的模型为3层神经网络,即输入层、隐藏层和输出层.在样本数据输入网络之前,由于数据之间不存在很大的相关性,且数量级之间存在较大的差异,所以本文将数据进行归一化处理后,再进行数据输入.
2.2 AutoencoderSoftmax分类器本文中的训练样本集的输入维数为24维,对于神经网络来说,维度越高,收敛越慢.可以对训练样本输入进行进一步的特征提取,而Autoencoder自编码神经网络就是一种很好的选择.
实验中建立了2个网络,一个为Autoencoder自编码神经网络,可以看作一个3层神经网络,输入数目与输出数目相同,隐藏层神经元个数为10,少于输入个数,各层神经元的激活函数选为Sigmoid函数.其目的和PCA相似,就是把输入的特征进行进一步的提取.另外一个就是前端与Autoencoder网络前两层相同,输出层接一个Softmax分类器就形成了AutoencoderSoftmax分类器网络.该网络的隐藏层的输出值正好就是类似池化后的特征值,但其几乎包含了输入向量的所有信息,输出层为8个神经元,正好为输出的8种故障类别.与传统神经网络不同的是,输出层变为了一个Softmax分类器,网络的具体结构如图 3所示.

|
| 图 3 AutoencoderSofmax深度学习网络架构 Fig.3 AutoencoderSofmax learning network architecture |
网络训练时分为两部分,首先对Autoencoder网络训练,将1 000×24维的训练样本集全部输入,按照BP网络的梯度下降算法进行训练使输出尽可能地与输入均方差最小. Autoencoder网络训练完,将最终的权重和阈值保存下来.接下来就是训练AutoencoderSoftmax分类器网络,用前面训练好的网络保存下来的权重和阈值来初始化新构建的神经网络的权值和阈值,重新进行训练,此时训练的算法为L-BFGS,目标函数为使得“交叉熵”最小.在对AutoencoderSoftmax深度学习网络进行实验时,选择其中900组数据作为训练样本集,余下的100组数据作为测试集来进行交叉验证.为了验证自编码网络的性能,选取其中8维特征观察还原效果,如图 4所示.

|
| 图 4 自编码还原效果图 Fig.4 Restoring effect graph of autoencoder |
由图 4可以看出,编码还原后绝大多数的特征点还是与编码前的特征点比较接近,自编码网络经过多步训练后能够较好地复现输入,也就是说隐含层提取到的特征包含了输入特征的大部分信息,即可以用隐含层输出的更加明显的特征向量来代替原网络的高维输入向量,来实现数据降维.
训练完成后,获得编码后的隐藏层输出的特征如图 5所示.

|
| 图 5 自编码网络输出特征 Fig.5 Output features of autoencoder network |
由图 5可以看出自编码后的特征较编码前的特征在数量上大幅度下降,这正是自编码对高维冗余特征无损压缩使有效特征复现的结果.不仅在特征数量上有所降低,而且故障点的分布较集中,这样就可以利用分类器实现准确的分类.
2.3 递归神经网络(RNN)由前面的数据集描述可知,本文采用的数据集为1 000组24维特征的数据集,这1 000组数据是每隔一个小时在采集点处采得的数据.因此这1 000组数据可以看作是一个时间序列,时间间隔为1 h.每一组数据之间存在着一定的联系,即上一个小时采集到的数据和后一个小时采集到的数据都会对当前时刻的状态产生影响(有故障或无故障).
在每一组数据作为样本进行输入时,网络会对其进行分析预测得出一个预测的状态值.这与传统的神经网络不同,传统神经网络通过训练得到的先验知识对当前样本进行分析预测,先验信息不包括前后样本之间的关系信息,这样对于本文数据集将没有一个好的预测结果.本文数据集之间存在着一定的时间联系,因此对数据样本的分类问题可以转化成为一个时间序列的预测问题.
RNN被称为递归神经网络,即一个序列当前的输出与前面的输出也有关.具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再是无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出.具体结构示意见图 6.

|
| 图 6 递归神经网络(RNN)结构图 Fig.6 Structure of RNN |
长短期记忆人工神经网络LSTM算法是一种特殊的RNN模型,在传统的RNN中,训练算法使用的是BPTT,当时间比较长时,需要回传的残差指数下降,导致网络权重更新缓慢,无法体现出RNN的长期记忆的效果,因此需要一个存储单元(细胞状态)来存储记忆,通过“门”结构对细胞状态的信息增减进行控制. LSTM中有3个门,分别是遗忘门、输入门、输出门.
细胞状态(又称:信息传送带):传送带本身是无法控制哪些信息是否被记忆,起控制作用的是控制门.其中遗忘门决定了要从信息传送带中舍弃什么信息.其通过输入上一状态的输出和当前状态输入信息到一个Sigmoid函数中,产生一个介于0到1之间的数值,与信息传送带相乘之后来确定取舍信息. 0表示“完全舍弃”,1表示“完全保留”.公式为ft=σ(Wf[ht-1,xt]+bf).其中,σ为Sigmoid激活函数,xt和ht-1为输入累加,Wf为权值系数,bf为累加偏置.

|
| 图 7 RNN-LSTM结构简图 Fig.7 Structure of RNN-LSTM |
输入门:决定了要往信息传送带中保存什么新的信息.通过遗忘门确定是否存储新信息,同时,一个tanh层会通过上一状态的输出和当前状态输入信息来得到一个将要加入到信息传送带中的“候选新信息”.将刚得到的数值与“候选新信息”相乘得到真正要加入到信息传送带中的更新信息,即:
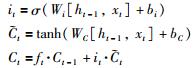
|
输出门:决定了要从信息传送带中输出什么信息.一个Sigmoid函数产生一个介于0到1之间的数值来确定我们需要输出多少信息传送带中的信息.传送带的信息在与上个阶段得到的Ct相乘时首先会经过一个tanh层进行“激活”(非线性变换).得到的就是这个LSTM的输出信息,即:
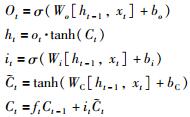
|
其中,it表示输入门,ft表示遗忘门,Ct表示t时刻遗忘单元的计算方法,bi、bC为对应的偏置,Wi、WC为对应的权值系数.
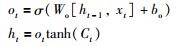
|
其中,ot表示输出门,ht为t时刻遗忘单元输出的计算方法,bo为对应的偏置,Wo为对应的权值系数.
以上的一带三门构成了LSTM算法.下面通过实验结论验证算法.
本文通过tensorflow深度学习框架分别搭建了传统的BP神经网络和LSTM神经网络,传统的BP神经网络采用3层网络结构,其中输入层的神经元个数为24,中间隐藏层的神经元个数为200,后一层的神经元个数为100最终输出层的神经元个数为2,最终的输出值为有无故障的概率分别是多少,在神经网络初始化时选用的是Xvair初始化方式,进行训练时采用的mini-batch梯度下降算法,在损失函数中添加了L2正则化,这样可以提高模型的鲁棒性,在网络训练的过程中学习率首先由低调到高,直到loss出现震荡现象,这样开始调节中间层的节点数,然后降低学习率,直到loss不再下降,这样得到网络的最终参数.
对于AutoencoderSoftmax网络的实现,同样是使用tensorflow编写,首先Autoencoder模块使用经典的3层神经网络:输入层、隐藏层和输出层,这里输入层和输出层的维数是一致的,这里输入的数据即是样本又是标签,损失函数为最小二乘损失函数,模型评价指标为RMSE.模型在训练过程中参数的调整和传统BP的类似,这里对于模型已经训练好的表现是,RSME loss非常小,也就是说输出和输入非常接近,输出可以很好地复现输入,保存模型参数.
接下来去掉Autoencoder的输出层,后面接上Softmax结构,这里的Softmax结构就是为了实现对故障的有效分类,也就是在输入样本经过Autoencoder降维以后的特征输入到Softmax结构中进行训练,在训练集上进行调参,最终获得最优的网络参数.
对于RNN-LSTM网络结构的实现,使用了最经典的LSTM网络模型,也是采用tensorflow深度学习框架实现.对于本文的数据来说,输入是24维、step为1,因为是每隔一小时采集的数据,batch-size为30,所以输入的维度为[batch-size,step,rnn-szie]其中的rnn-size就是输入的节点数也就是24,然后后面跟一系列隐藏层,最后为输出层.初始学习率为0.001,网络训练的方式和上面相同,保存网络最终参数并对测试集进行预测,实验结果在下面的章节进行分析.
3 实验结果与分析 3.1 传统BP网络本文分别采用1 000×24维的整体数据集划分为900×24维的数据作为训练样本集,剩下的100×24维数据作为测试集,进行交叉验证可以防止网络过拟合.在训练样本集输入到网络时,进行分批处理,即每次输入100×24维的数据,训练好网络后保存其权重和阈值.再将测试集输入到训练好的网络中,来验证网络可靠性和诊断的准确率.
训练样本集输入后网络的输出从大的层面上讲分为两类:一是有无故障,二是有故障.对于有故障的,接下来进行进一步的分析是哪一类故障.
在第1部分进行数据分析时得到样本数据集类别存在严重的分类不均衡问题,传统的分类器性能衡量指标在这个问题中并不适用.在非均衡分类中常用混淆矩阵来定义新的评价指标,本文定义了错误率,预测有故障的正确率,预测无故障的正确率三类指标.详见表 2.
说明如下:
True Positive(真正,TP):将有故障判断为有故障;
True Negative(真负,TN):将无故障判断为无故障;
False Positive(假正,FP):将无故障判断为有故障;
False Negative(假负,FN):将有故障判断为无故障.
常用的评估指标为:
1) 有故障的正确率S1:在所有判断有故障的样本中,实际同样有故障的样本所占的比例:
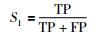
|
2) 无故障的正确率S2:在所有判断无故障的样本中,实际同样无故障的样本所占的比例:
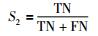
|
3) 错误率S3:在所有的样本中,判断错误的样本所占的比例:
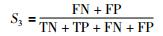
|
对传统的BP神经网络进行实验验证,实验结果见表 3.
通过实验结果可以计算出不作任何特征变换的BP神经网络,对于预测有故障的正确率为46.7%,无故障的正确率为69.6%,错误率为38.7%.可以看出,如果对于输入的特征向不作任何特征变化就输入到神经网络中,网络在有无故障的辨识正确率方面表现都比较差,并且错误率较高.这也进一步说明传统BP神经网络不适用高维输入的非均衡分类问题.
3.2 AutoencoderSoftmax对AutoencoderSoftmax神经网络进行实验验证,实验结果如下:
利用表 4中的数据代入上面的公式可以得到AutoencoderSoftmax深度学习网络预测有故障的正确率为82.2%,预测无故障的正确率为87.3%,而错误率降低为14.8%,可以看到在使用了Autoencoder进行降维以后,也就是将特征进行解耦操作,然后选择出承载信息量比较大的特征,送入Softmax结构进行预测,比直接将原始数据送入网络的效果有明显提升,这也印证了数据降维的操作必要性.
| 实际情况 | 预测情况 | |
| 有故障 | 无故障 | |
| 有故障 | 37 | 8 |
| 无故障 | 8 | 55 |
与前面实验相同,在这里本文也选取以上使用的3个指标进行实验,实验结果如下:
利用表 5中的数据使用公式计算可知,对于有故障预测的正确率为95.5%,无故障预测的正确率为98.3%,错误率也下降到3.0%.不难看出RNN-LSTM网络对于有无故障的预测的正确率都超过了90%,最令人满意的是对于故障预测的错误率下降到了3%,这样给整个系统的稳定运行提供可靠保障.
RNN-LSTM之所以能达到这么好的效果,其一是因为前端Autoencoder进行了特征解耦操作,其二是RNN-LSTM网络结构特有的属性,其实一个end-to-end的网络,在网络的内部做了一层特征提取的工作,提取一些隐性特征,这样能够让网络的表达性更好,除此之外LSTM特有的门限结构,能够很好地记忆前几个状态,这样对于强时间相关性数据样本的预测会产生巨大的影响,因此其表现远远超出了前两种方法.
对以上3种算法进行对比分析,结果如图 8所示.

|
| 图 8 3种网络辨识能力对比图 Fig.8 Identification effects comparison of three methods |
由图 8可知,RNN-LSTM网络在预测有无故障正确率方面明显优于前面两种网络,还大大降低了错误率,此外,RNN-LSTM网络在训练样本输入之前没有进行进一步的特征提取,较经过Autoencoder网络进行特征提取后的网络实现了对输入样本的信息的绝大程度化保留,避免丢失有用信息.由此可以看出该递归型网络对分均衡分类问题有着良好的分类效果.
4 结论本文提出的AutoencoderSoftmax深度学习网络能够很好地在繁冗的特征向量数据集中提取出有效特征并将输入数据的维数进行无损压缩,这样大大降低了网络的运算量.但是在实际的训练过程中,本文希望训练样本能够尽可能多地保留数据的有用信息,这样训练得到的网络会更加健壮,具有更强的鲁棒性和容错性.数据横向的特征维数较大,另外在纵向数据之间存在着一定的时间维度的联系,在处理高维度和具有时间关联的数据样本时RNN-LSTM网络其收敛速度和辨识效果都要优于AutoencoderSoftmax深度学习网络.另外在非均衡分类问题中,RNN LSTM网络也得到令人满意的结果. RNN-LSTM网络在本文故障诊断问题中对于预测有故障的正确率为95.5%,预测无故障的正确率为98.3%.这种方法将为今后的非传统分类问题提供一个理论依据,并将在深度学习实现故障辨识领域产生深远意义.
| [1] |
曲星宇, 曾鹏, 李俊鹏.
基于局部权重角度离群算法的球磨机故障诊断[J]. 信息与控制, 2017, 46(4): 489–494.
Qu X Y, Zeng P, Li J P. Fault diagnosis of ball mill based on FastVOA algorithm[J]. Information and Control, 2017, 46(4): 489–494. |
| [2] | Varior R R, Shuai B, Lu J, et al. A siamese long short-term memory architecture for human re-identification[C]//European Conference on Computer Vision. Berlin, Germany: Springer, 2016: 135-153. https://link.springer.com/chapter/10.1007%2F978-3-319-46478-7_9 |
| [3] | Liu Q, Chai T Y, Qin S Z. A summary of industrial monitoring and fault diagnosis based on data knowledge[J]. Control and Decisions, 2010(6): 801–807. |
| [4] | Lopez J E, Tenney R R, Deckert J C. Fault detection and identification using real-time wavelet feature extraction[C]//Proceedings of the IEEE-SP International Symposium on Time-Frequency and Time-Scale Analysis. Piscataway, NJ, USA: IEEE, 1994: 217-220. https://www.researchgate.net/publication/3613354_Fault_detection_and_identification_using_real-time_wavelet_feature_extraction |
| [5] | Yin S, Ding S X, Xie X, et al. A review on basic data-driven approaches for industrial process monitoring[J]. IEEE Transactions on Industrial Electronics, 2014, 61(11): 6418–6428. DOI:10.1109/TIE.2014.2301773 |
| [6] |
曲星宇, 崔宝侠, 段勇, 等.
基于Type-2 FNN数据融合的双进双出磨煤机料位检测[J]. 控制与决策, 2011, 26(8): 1259–1263.
Qu X Y, Cui B X, Duan Y, et al. Level detection of DIDO mills based on Type-2 RNN data fusion[J]. Control and Decision, 2011, 26(8): 1259–1263. |
| [7] | Ellis M, Durand H, Christofides P D. A tutorial review of economic model predictive control methods[J]. Journal of Process Control, 2014, 24(8): 1156–1178. DOI:10.1016/j.jprocont.2014.03.010 |
| [8] | Ranaee V, Ebrahimzadeh A, Ghaderi R. Application of the PSO-SVM model for recognition of control chart patterns[J]. ISA Transactions, 2010, 49(4): 577–586. DOI:10.1016/j.isatra.2010.06.005 |
| [9] | Garrido J, Vázquez F, Morilla F. An extended approach of inverted decoupling[J]. Journal of Process Control, 2011, 21(1): 55–68. DOI:10.1016/j.jprocont.2010.10.004 |
| [10] | Dazhi D. Research on coal mine electromechanical equipment closed-loop management system based on IOT and information technology[C]//2nd International Conference on Artificial Intelligence, Management Science and Electronic Commerce (AIMSEC). Piscataway, NJ, USA: IEEE, 2011: 5101-5104. https://www.researchgate.net/publication/241190713_Research_on_coal_mine_electromechanical_equipment_closed-loop_management_system_based_on_IOT_and_information_technology |
| [11] | Cho K, Van Merrienboer B, Gulcehre C, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation[J/OL]. arXiv, 2014: arXiv: 1508.06615. (2014-09-03)[2018-05-01]. http://arXiv.org/abs/1406.1078. |
| [12] | Yao S K, Cohn T, Vylomova K, et al. Depth-gated LSTM[J/OL]. arXiv, 2015: arXiv: 1508.03790v4. (2015-08-25)[2018-05-01]. http://arXiv.org/abs/1508.03790v4. |
| [13] | Koutník J, Greff K, Gomez F, et al. A clockwork RNN[C]. 31st International Conference on Machine Learning. New York, NJ, USA: ACM, 2014: Ⅱ-1863-Ⅱ-1871. |
| [14] | Greff K, Srivastava R K, Koutník J, et al. LSTM:A search space odyssey[J]. IEEE Transactions on Neural Networks & Learning Systems, 2016, 28(10): 2222–2232. |
| [15] | Jozefowicz R, Zaremba W, Sutskever I. An empirical exploration of recurrent network architectures[C]//International Conference on International Conference on Machine Learning. New York, USA: ACM, 2015: 2342-2350. https://dl.acm.org/citation.cfm?id=3045367 |