



2. 北京理工大学化学与化工学院, 北京 100081
2. School of Chemistry and Chemical Engineering, Beijing Institute of Technology, Beijing 100081, China
0 引言
在工业生产中,参数的在线检测是过程监测、控制及优化的必要条件.然而,由于经济或技术方面的制约,一些关键的产品质量参数难以实时测量.软测量技术为此类难测参数的在线估计提供了有效途径[1-2].软测量技术的基本思想是选择一组与主导变量密切相关的辅助变量,通过构建辅助变量与主导变量之间的函数关系式,从而实现主导变量的实时估计.
一般而言,软测量建模方法可分为机理建模和数据驱动建模.尽管机理模型具有很强的可解释性,但是对于复杂的工业过程来说,很难建立精确的机理模型.相比而言,数据驱动建模方法只需要基于过程数据即可建立相应的软测量模型,而且随着信息技术的发展,现代工业生产中的过程数据被大量的保存下来,为数据驱动软测量建模提供了强大的数据支撑.因此,基于数据驱动的软测量建模日益受到青睐[3-4].常见的数据驱动软测量建模方法有偏最小二乘(PLS)[5]、独立主成分回归(ICR)[6]、人工神经网络(ANN)[7]、支持向量回归(SVR)[8-9]、高斯过程回归(GPR)[10-13]等.
从模型结构上看,数据驱动软测量模型主要分为全局建模和局部建模.全局建模寻求建立一个单一的预测模型,并且期待在所有过程状态上获得满意的预测性能.然而,实际的过程对象往往呈现复杂的过程特性,全局模型难以有效描述局部过程特征,导致模型预测性能较差.相比之下,局部学习模型采用“分而治之”的思想,能够精准地描述局部过程特征,而且显著降低了计算复杂度,因而在软测量建模领域备受关注[14].而即时学习作为局部建模的典型代表,能够有效地处理过程的非线性和时变性,被广泛应用于软测量建模领域[15-16].
即时学习,又称为懒惰学习(lazy learning)[17],主要包含两种建模方式:
1) 选择相似样本进行局部建模,如k最近邻分类器(kNN)[18];
2) 基于相似度对建模样本进行加权,如局部加权偏最小二乘(LWPLS)[19].
目前,即时学习软测量建模的关注点集中在半监督即时学习[20]、概率即时学习[21]、即时学习与其它方法的融合[22-23]及集成即时学习[24-25]等方面.本研究主要关注集成即时学习软测量建模.
在即时学习算法中,相似度指标的定义尤为关键,常见的相似度指标有距离相似度[26]、角度相似度[27]、相关相似度[28]、高斯相似度[29]等,但传统的相似度指标没有考虑输入输出变量之间的相关性存在差异这一事实,而加权相似度是解决这一问题的有效途径[30-32].
此外,传统的即时学习模型以使用单一的相似度函数为主,但在一些实际化工生产中,过程对象往往表现出强非线性、多模式、多时段等复杂特性,单一的相似度难以满足所有过程状态的要求且由于过程数据和专家知识的局限性等因素,往往无法获得最优的相似度指标,只能获得多样性的次优相似度指标,进而构建多样性的次优即时学习模型.但是,随之而来的两个重要问题是:
1) 如何构建多样性的相似度指标;
2) 如何基于这些弱即时学习模型构建高性能的软测量模型.
为解决上述问题,本文提出一种基于多样性加权相似度的集成局部加权偏最小二乘(diverse weighted similarity measures based ensemble locally weighted partial least squares,DWS-ELWPLS)软测量建模方法.该方法融合了即时学习与集成学习的优势.首先通过随机子空间法和高斯混合聚类,构建多样性的训练样本子集,并基于PLS回归分析获取输入特征的权重,以此为基础定义多样性的加权相似度指标.随后,通过PLS算法对多样性的LWPLS模型输出进行集成融合得到最终的预测结果.将所提出的DWS-ELWPLS软测量建模方法用于数值仿真例子和工业脱丁烷塔过程,实验结果表明了该方法的有效性.
1 算法简介 1.1 局部加权偏最小二乘算法(LWPLS)LWPLS是一种基于局部加权回归和PLS的即时学习建模方法.假设X∈RN×M,Y∈RN×P为模型的输入、输出数据矩阵,第n个输入输出样本可表示为
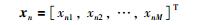
|
(1) |
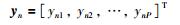
|
(2) |
其中,N代表输入、输出样本数,M、P分别代表输入、输出变量维度.
当查询样本xq到来时,根据某种相似度准则计算查询样本与数据库中历史样本的相似度ωn,从而获得相似度矩阵. Ω∈RN×N:
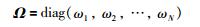
|
(3) |
利用LWPLS算法获得查询样本对应的预测输出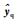
1) 假设需要的主成分个数为R,在算法中的初始值设为r=1.
2) 计算相似度矩阵Ω.
3) 对输入、输出及查询点样本进行数据预处理,分别计算出Xr,Yr和xq,r的值:
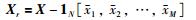
|
(4) |
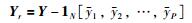
|
(5) |
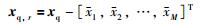
|
(6) |
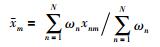
|
(7) |
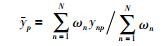
|
(8) |
其中,1N∈RN为全1的列向量.
4) 计算X的第r个主成分:
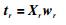
|
(9) |
其中,wr是XrTΩYrYrTΩXr的最大特征值对应的特征向量.
5) 计算X的第r个负载向量和回归系数向量:
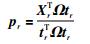
|
(10) |
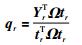
|
(11) |
6) 计算xq的第r个主成分:
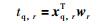
|
(12) |
7) 若r=R,计算结束.否则,令:
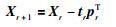
|
(13) |
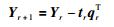
|
(14) |
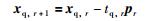
|
(15) |
8) 令r=r+1,并转到步骤4).
9) 计算查询样本的预测输出值
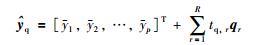
|
(16) |
GMM是一种概率模型方法,被广泛用于处理非监督学习问题,如连续过程模式辨识[33]、间歇过程时段划分[34]等.对于一个M维的样本. x∈RM,其概率密度可以表示为高斯混合密度函数:
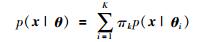
|
(17) |
其中,K为高斯成分个数;πk为各成分的权重且满足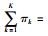
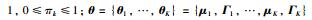
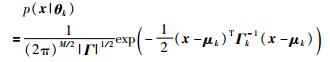
|
(18) |
通常以最大化样本的似然函数为优化目标,采用EM算法[35]实现GMM模型参数Θ={{π1,μ1,ΓK},…,{πK,μK,ΓK}}的估计:
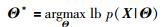
|
(19) |
其中,似然函数表示为
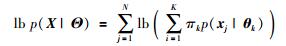
|
(20) |
LWPLS即时学习模型的预测性能很大程度上依赖于相似度函数的定义.但传统的欧氏距离相似度仅以输入输出变量之间的距离为衡量指标,并未考虑变量之间的相关性.实际上,不同的输入输出变量之间的相关性存在一定的差异.使用加权相似度是解决这一问题的有效途径.为此,本文在常规欧氏距离相似度的基础上定义加权欧氏距离相似度:
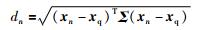
|
(21) |
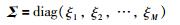
|
(22) |
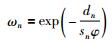
|
(23) |
其中,dn表示查询样本与历史样本之间的加权欧氏距离,Σ∈RM×M为对角加权矩阵,ξm是第m个输入变量的权值,sn是{dn}n=1M的标准差,φ是局部化参数.当φ取值较小时,相似度下降速率较快;反之,当φ取值较大时,相似度下降变缓;当φ=∞时,LWPLS等价于PLS.
2.2 多样性加权相似度构建在集成学习中,提高模型预测精度和可靠性的一个关键因素是使各基模型之间存在较大的差异性,即确保基模型的多样性[36-37].对于LWPLS建模,相似度指标的不同必然引起模型预测性能的差异.对于复杂的过程对象,单一的相似度指标难以有效适应所有过程状态,因此建立多样性的相似度指标势在必行.本研究中,通过构建多样性的加权相似度指标以实现LWPLS模型性能的多样性.
由式(22)、式(23)可知,ξm值的差异会导致加权相似度指标的差异.因此,如何确定输入变量权值成为了构建多样性加权相似度的关键问题. Shigemori等[30]将权值ξm定义为MRA全局模型中第m个输入变量回归系数的绝对值. Kim等[31]将权值ξm定义为PLS回归模型中第m个回归系数的绝对值.研究结果表明,采用回归分析确定输入输出之间的相关性是一种有效途径.为了降低模型的复杂度和计算负荷,本研究中采用PLS回归分析法确定输入变量权值.构建多样性加权相似度的具体实施步骤为:
1) 采用随机子空间法,随机选取输入样本的部分特征,获得训练样本子空间,从而得到训练样本子空间数据集Ds={Xs,Ys}.
2) 基于GMM算法对子空间样本集进行聚类操作,得到K类子空间训练样本集D*={{X*(1),Y*(1)},{X*(2),Y*(2)},…,{X*(k),Y*(k)}},k=1,2,…,K.
3) 利用聚类所得样本子集的索引对原始训练样本集进行分组,从而获得K类训练样本子集D={{X(1),Y(1)},{X(2),Y(2)},…,{X(k),Y(k)}}.
4) 对训练样本子集进行PLS回归分析,得到回归系数集C={c(1),c(2),…,c(k)},其中一组训练样本对应的回归系数为c(k)={c1(k),c2(k),…,cm(k)}.
5) 将回归系数绝对值作为输入变量的权值,即ξm(k)=|cm(k)|,从而获得第k类样本的加权矩阵Σ(k)=diag(ξ1(k),ξ2(k),…,ξM(k)),所有多样性样本集对应的加权矩阵为Σ=[Σ(1),Σ(2),…,Σ(k)].基于这些加权矩阵即可定义相应的加权相似度函数.
通过重复上述步骤可以获得更多的训练样本子集,同时进一步提升了数据子集的多样性,进而构建一组多样性的加权欧氏距离相似度指标.
2.3 多样性LWPLS模型集成当查询样本xq到来时,基于多样性加权相似度指标可以构建一系列多样性的LWPLS模型,并获得相应的局部预测输出值.为了得到最终预测值,需要将局部预测值进行集成处理.最常见的集成学习方法是简单平均法,但该方法并未考虑子模型性能的差异性,导致其预测性能受限.因此,加权集成策略更为合理.本文采用Stacking集成策略,基本原理如图 1所示.首先基于原始建模数据构建第1层次模型(first-level learners),然后基于独立的验证数据集训练第2层次模型(second-level learner).其中,多样性LWPLS基模型的输出作为集成模型的输入,第2层次模型的输出作为DWS-ELWPLS模型的输出.

|
| 图 1 Stacking集成框架 Fig.1 Framework of stacking ensemble |
加权融合模型的权值确定可转化为式(24)的优化问题:
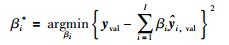
|
(24) |
其中,βi为单个模型的权值,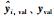
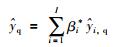
|
(25) |
集成学习策略的引入使得从一系列弱LWPLS模型中获得高性能集成LWPLS软测量模型成为可能.除了模型预测性能的提升,DWS-ELWPLS方法的另一个显著优势是算法效率高,可有效确保在线预测的实时性. DWS-ELWPLS算法的在线计算负载主要集中在多样性LWPLS基模型的构建和集成上,而这两个关键操作只涉及到简单的线性计算,其计算复杂度为O(n).相比而言,基于非线性建模技术的即时学习软测量建模具有较高的计算复杂度,如高斯过程回归(计算复杂度为O(n3))、支持向量机(计算复杂度为O(n2))等.
2.4 实施原理DWS-ELWPLS软测量建模方法主要包括离线操作和在线实施两个阶段,其基本原理框架如图 2所示.

|
| 图 2 DWS-ELWPLS软测量建模方法原理框图 Fig.2 Schematic diagram of the proposed DWS-ELWPLS soft sensor method |
离线操作主要步骤为:
1) 采集输入输出样本,并将其分为训练集、验证集和测试集.
2) 通过随机子空间法,抽取训练样本的部分特征作为子空间,并对子空间训练样本进行GMM聚类,然后基于聚类样本索引获得K个训练样本子集.
3) 将分类获得的训练样本子集进行PLS回归分析,得到模型回归系数.
4) 将步骤3)所得回归系数的绝对值作为加权相似度的权值,从而获得相应的加权相似度.
5) 多次重复步骤2)~步骤4),获得一组多样性加权相似度.
6) 采用多样性LWPLS模型对验证样本进行预测,然后建立局部预测输出与实际输出之间的PLS回归模型,用于LWPLS模型融合.
在线实施主要步骤为:
1) 给定查询点xq,基于多样性加权相似度构建多样性的LWPLS模型,并给出相应的预测值.
2) 通过PLS集成模型对多样性LWPLS模型的预测结果进行融合,最终得到查询点的预测输出.
3 应用研究本文通过数值例子和工业脱丁烷塔过程来验证所提方法的有效性.分别构建PLS、LWPLS和DWS-ELWPLS软测量模型,并采用均方根误差RMSE评价模型的预测性能:
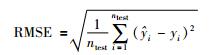
|
(26) |
其中,ntest为测试样本数目;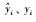
实验过程中各模型需要确定的参数为:
1) PLS:主成分个数R.
2) LWPLS:主成分个数R、局部建模样本数L、局部化参数φ;
3) DWS-ELWPLS:主成分个数R、局部建模样本数L、局部化参数φ、随机子空间变量个数g、随机子空间重构次数h.
上述参数值均通过最小化验证误差来确定.同时,在预精度一定的情况下,以最小化模型在线预测时间为标准进行参数选择.
实验计算机配置为:OS:Windows 10(64 bit);CPU:Inter(R) Core(TM) i7-6700(3.40 GHz×2);RAM:4.00 G byte;Matlab版本:2010a.
3.1 数值例子本数值例子来源于文[38].输入输出之间的函数关系为
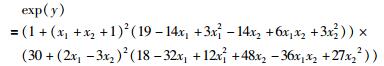
|
(27) |
其中,x1、x2为输出变量,y为输出变量.输入输出的响应曲线如图 3所示.

|
| 图 3 仿真函数三维图 Fig.3 3D graph of the numerical simulation function |
将输入变量取值范围设为[-2, 2],通过式(27)的函数产生1 000个建模样本,并对输入输出变量加入均值为0、标准差为0.01的随机噪声.将建模样本分为训练集(50%)、验证集(25%)和测试集(25%).其中,训练集用于模型构建,验证集用于模型参数确定,测试集用于模型性能评估.
不同模型的参数寻优范围设置为:
1) 隐变量个数R∈[1,2],用于PLS、LWPLS和DWS-ELWPLS.
2) 局部建模样本数L∈[30,50,100,…,500],用于LWPLS和DWS-ELWPLS.
3) 局部化参数φ∈[0.1,0.5,1.5],用于LWPLS和DWS-ELWPLS.
4) 随机子空间变量个数g∈[1,2],用于DWS-ELWPLS.
5) 随机子间重构次数h∈[1,2,…,10],用于DWS-ELWPLS.
基于上述参数范围,不同软测量模型的最优参数为:
1) PLS:R=1.
2) LWPLS:R=2,L=30/50/100,φ=0.1.
3) DWS-ELWPLS:R=2,L=30/50/100,φ=0.1,g=1,h=3.
表 1给出了3种建模方法在数值例子中的预测结果,可以看出,PLS的RMSE明显高于LWPLS和DWS-ELWPLS,这是因为PLS模型难以处理过程的非线性特征,因此预测性能较低.相比而言,LWPLS模型由于具有较强的非线性处理能力,预测性能大幅提升.在局部样本数分别取30、50和100三种情形下,对比LWPLS方法,DWS-ELWPLS方法的预测RMSE分别降低了21.9%、22.7%、23.5%.此外,图 4给出了实际输出与DWS-ELWPLS方法预测输出之间的散点图,从图中可以看出DWS-ELWPLS模型的预测结果与实际值高度吻合.由此可见,相比于PLS和LWPLS方法,DWS-ELWPLS软测量模型具有更强的非线性处理能力,因此预测性能获得了显著提升.
| 算法 | RMSE |
| PLS | 2.122 3 |
| LWPLS (L=30) | 0.249 3 |
| DWS-ELWPLS (L=30) | 0.194 6 |
| LWPLS (L=50) | 0.256 3 |
| DWS-ELWPLS (L=50) | 0.198 2 |
| LWPLS (L=100) | 0.258 6 |
| DWS-ELWPLS (L=100) | 0.197 9 |

|
| 图 4 数值例子中实际输出与DWS-ELWPLS方法预测输出之间的散点图(L=100) Fig.4 Scatter plot between actual output and predicted values using DWS-ELWPLS in numerical example (L=100) |
除了预测精确度,实时性也是软测量模型的一个关键性指标.对于数值案例来说,DWS-LWPLS模型的平均在线预测CPU时间为0.669 8 s,由此可见该方法能够保障变量预测的实时性.
3.2 脱丁烷塔过程脱丁烷塔是工业炼油过程中脱硫和石脑油分离的一部分装置,其目标是最小化塔底丁烷的浓度.但是,目前丁烷浓度还难以实现实时在线检测.采用软测量方法对丁烷浓度进行在线预测,能够有效提高脱丁烷塔的脱硫效率.图 5给出了脱丁烷塔的过程结构示意图,其中灰色标记部分为7个实时变量的监测位置,这7个监测变量在本文中用作构建软测量模型的辅助变量,分别为:x1塔顶温度,x2塔顶压力,x3塔顶回流量,x4塔顶产品流出量,x5第6层塔板温度,x6塔低温度1,x7塔底温度2.

|
| 图 5 脱丁烷塔过程流程图 Fig.5 Flowchart of the debutanizer column process |
本实验所用的脱丁烷塔工业过程数据共有2 394个数据样本,将其划分为训练集(50%)、验证集(25%)和测试集(25%),分别用于模型训练、参数优化和预测性能评估.
不同模型的参数寻优范围设置:
1) 隐变量个数R∈[1,2,…,7],用于PLS、LWPLS和DWS-ELWPLS.
2) 局部建模样本数L∈[30,50,100,…,500],用于LWPLS和DWS-ELWPLS.
3) 局部化参数φ∈[0.1,0.5,1.5],用于LWPLS和DWS-ELWPLS.
4) 随机子空间变量个数g∈[1,2,…,7],用于DWS-ELWPLS.
5) 随机子间重构次数h∈[1,2,…,10],用于DWS-ELWPLS.
基于上述参数范围,不同软测量模型的最优参数为:
1) PLS:R=7.
2) LWPLS:R=1,L=30/50/100,φ=0.1.
3) DWS-ELWPLS:R=3,L=30/50/100,φ=0.1,g=5,h=1.
3种建模方法在脱丁烷塔工业过程中的预测结果如表 2所示.同时,图 6给出了丁烷浓度的预测趋势曲线.
| 算法 | RMSE |
| PLS | 0.143 7 |
| LWPLS (L=30) | 0.054 4 |
| DWS-ELWPLS (L=30) | 0.048 9 |
| LWPLS (L=50) | 0.054 6 |
| DWS-ELWPLS (L=50) | 0.048 4 |
| LWPLS (L=100) | 0.054 8 |
| DWS-ELWPLS (L=100) | 0.048 4 |

|
| 图 6 DWS-ELWPLS方法在脱丁烷塔过程中的丁烷浓度预测趋势曲线(L=100) Fig.6 Trend plot of butane concentration predictions using DWS-ELWPLS method for the debutanizer column process (L=100) |
由表 2可知,DWS-ELWPLS软测量建模方法获得了最佳的预测效果.由于PLS方法只能处理线性问题,因此预测效果较差. LWPLS方法是在PLS的基础上对样本进行加权,使非线性问题线性化,因此模型的预测效果有所提升.而DWS-ELWPLS方法综合了训练样本的多样性和加权相似度的多样性,通过集成局部模型的方法,进一步提高了模型的预测精度.在局部建模样本数分别取30、50和100的情况下,DWS-ELWPLS的RMSE比LWPLS分别降低了10.1%、11.4%、11.7%.由图 5也可以看出,在DWS-ELWPLS建模方法下,脱丁烷塔丁烷浓度的预测值与实际值高度吻合,由此说明该方法具有优异的预测性能.此外,丁烷浓度的平均在线预测CPU时间仅为0.144 7 s,能够保证脱丁烷塔工业过程中丁烷浓度的实时性预测.
4 结论本文提出了一种基于多样性加权相似度的集成即时学习软测量建模方法DWS-ELWPLS.该方法通过融合随机子空间法和GMM聚类构建多样性的训练样本子集,并以此为基础建立多样性的加权相似度指标.同时,通过引入集成学习思想,对多样性的LWPLS模型进行融合. DWS-ELWPLS充分继承了传统即时学习方法的优良特性,能够有效处理过程的非线性特征.此外,多样性加权相似度的引入有效地克服了传统方法使用单一相似度的局限性.实验结果表明,相比于传统的LWPLS软测量方法,DWS-ELWPLS方法显著提升了难测变量的预测精度.此外,该建模框架具有较高的灵活性,可根据不同的应用需求选择相应的局部建模技术,如ANN、SVR、GPR等.
| [1] | Fortuna L G, Graziani S, Rizzo A, et al. Soft sensors for monitoring and control of industrial processes[M]. Springer Science & Business Media, 2007. |
| [2] |
曹鹏飞, 罗雄麟.
化工过程软测量建模方法研究进展[J]. 化工学报, 2013, 64(3): 788–800.
Cao P F, Luo X L. Modeling of soft sensor for chemical process[J]. CIESC Journal, 2013, 64(3): 788–800. DOI:10.3969/j.issn.0438-1157.2013.03.003 |
| [3] | Kano M, Nakagawa Y. Data-based process monitoring, process control, and quality improvement:Recent developments and applications in steel industry[J]. Computers & Chemical Engineering, 2008, 32(1): 12–24. |
| [4] | Kadlec P, Gabrys B, Strandt S. Data-driven soft sensors in the process industry[J]. Computers & Chemical Engineering, 2009, 33(4): 795–814. |
| [5] | Kadlec P, Gabrys B. Local learning-based adaptive soft sensor for catalyst activation prediction[J]. AIChE Journal, 2011, 57(5): 1288–1301. DOI:10.1002/aic.v57.5 |
| [6] | Ge Z Q, Song Z H. Ensemble independent component regression models and soft sensing application[J]. Chemometrics and Intelligent Laboratory Systems, 2014, 130: 115–122. DOI:10.1016/j.chemolab.2013.09.009 |
| [7] | Gonzaga J C B, Meleiro L A C, Kiang C, et al. ANN-based soft-sensor for real-time process monitoring and control of an industrial polymerization process[J]. Computers & Chemical Engineering, 2009, 33(1): 43–49. |
| [8] | Kaneko H, Funastu K. Adaptive soft sensor based on online support vector regression and Bayesian ensemble learning for various states in chemical plants[J]. Chemometrics and Intelligent Laboratory Systems, 2014, 137: 57–66. DOI:10.1016/j.chemolab.2014.06.008 |
| [9] | Jin H P, Chen X G, Yang J W, et al. Multi-model adaptive soft sensor modeling method using local learning and online support vector regression for nonlinear time-variant batch processes[J]. Chemical Engineering Science, 2015, 131: 282–303. DOI:10.1016/j.ces.2015.03.038 |
| [10] |
熊伟丽, 张伟, 徐保国.
一种基于EGMM的高斯过程回归软测量建模[J]. 信息与控制, 2016, 45(1): 14–19.
Xiong W L, Zhang W, Xu B G. A Soft sensor modeling method based on EGMM using Gaussian process regression[J]. Information and Control, 2016, 45(1): 14–19. |
| [11] | Xiong W L, Li Y J, Zhao Y J, et al. Adaptive soft sensor based on time difference Gaussian process regression with local time-delay reconstruction[J]. Chemical Engineering Research and Design, 2017, 117: 670–680. DOI:10.1016/j.cherd.2016.11.020 |
| [12] | Mei C L, Su Y, Liu G H, et al. Dynamic soft sensor development based on Gaussian mixture regression for fermentation processes[J]. Chinese Journal of Chemical Engineering, 2017, 25(1): 116–122. DOI:10.1016/j.cjche.2016.07.005 |
| [13] | Grbić R, Slišković D, Kadlec P. Adaptive soft sensor for online prediction and process monitoring based on a mixture of Gaussian process models[J]. Computers & Chemical Engineering, 2013, 58: 84–97. |
| [14] | Shao W M, Tian X M. Adaptive soft sensor for quality prediction of chemical processes based on selective ensemble of local partial least squares models[J]. Chemical Engineering Research and Design, 2015, 95: 113–132. DOI:10.1016/j.cherd.2015.01.006 |
| [15] | Kano M, Fujiwara K. Virtual sensing technology in process industries:Trends and challenges revealed by recent industrial applications[J]. Journal of Chemical Engineering of Japan, 2013, 46(1): 1–17. |
| [16] | Jin H P, Chen X G, Yang J W, et al. Adaptive soft sensor modeling framework based on just-in-time learning and kernel partial least squares regression for nonlinear multiphase batch process[J]. Computer & Chemical Engineering, 2014, 71: 77–93. |
| [17] | Aha D W. Editorial[M]. Netherlands: Springer, 1997: 7-10. |
| [18] | Zhou Z H, Yu Y. Ensembling local learners through multimodal perturbation[J]. IEEE Transactions on Systems, Man, and Cybernetics, Part B:Cybernetics, 2005, 35(4): 725–735. DOI:10.1109/TSMCB.2005.845396 |
| [19] | Kim S, Kano M, Hasebe S, et al. Long-term industrial applications of inferential control based on just-in-time soft-sensors:Economical impact and challenges[J]. Industrial & Engineering Chemistry Research, 2013, 52(35): 12346–12356. |
| [20] | Yuan X F, Ge Z Q, Huang B, et al. Semisupervised JITL framework for nonlinear industrial soft sensing based on locally semisupervised weighted PCR[J]. IEEE Transactions on Industrial Informatics, 2017, 13(2): 532–541. DOI:10.1109/TII.2016.2610839 |
| [21] | Yuan X F, Ge Z Q, Huang B, et al. A probabilistic just-in-time learning framework for soft sensor development with missing data[J]. IEEE Transactions on Control Systems Technology, 2017, 25(3): 1124–1132. DOI:10.1109/TCST.2016.2579609 |
| [22] | Xiong W L, Zhang W, Xu B G, et al. JITL based MWGPR soft sensor for multi-mode process with dual-updating strategy[J]. Computers & Chemical Engineering, 2016, 90: 260–267. |
| [23] | Chen M L, Khare S, Huang B. A unified recursive just-in-time approach with industrial near infrared spectroscopy application[J]. Chemometrics and Intelligent Laboratory Systems, 2014, 135: 133–140. DOI:10.1016/j.chemolab.2014.04.007 |
| [24] | Liu Y, Zhang Z J, Chen J H. Ensemble local kernel learning for online prediction of distributed product outputs in chemical processes[J]. Chemical Engineering Science, 2015, 137: 140–151. DOI:10.1016/j.ces.2015.06.005 |
| [25] | Liu Y, Gao Z L. Industrial melt index prediction with the ensemble anti-outlier just-in-time Gaussian process regression modeling method[J]. Journal of Applied Polymer Science, 2015, 132(22): 41958. |
| [26] | Ge Z Q, Song Z H. A comparative study of just-in-time-learning based methods for online soft sensor modeling[J]. Chemometrics and Intelligent Laboratory System, 2010, 1049(2): 306–317. |
| [27] | Cheng C, Chiu M-S. A new data-based methodology for nonlinear process modeling[J]. Chemical Engineering Science, 2004, 59(13): 2801–2810. DOI:10.1016/j.ces.2004.04.020 |
| [28] | Fujiwara K, Kano M, Hasebe S, et al. Soft-sensor development using correlation-based just-in-time modeling[J]. AIChE Journal, 2009, 55(7): 1754–1765. DOI:10.1002/aic.v55:7 |
| [29] | Fan M, Ge Z Q, Song Z H. Adaptive Gaussian mixture model-based relevant sample selection for JITL soft sensor development[J]. Industrial & Engineering Chemistry Research, 2014, 53(51): 19979–19986. |
| [30] | Shigemori H, Kano M, Hasebe S. Optimum quality design system for steel products through locally weighted regression model[J]. Journal of Process Control, 2011, 21(2): 293–301. DOI:10.1016/j.jprocont.2010.06.022 |
| [31] | Kim S, Kano M, Nakagawa H, et al. Estimation of active pharmaceutical ingredients content using locally weighted partial least squares and statistical wavelength selection[J]. International journal of pharmaceutics, 2011, 421(2): 269–274. DOI:10.1016/j.ijpharm.2011.10.007 |
| [32] | Hazama K, Kano M. Covariance-based locally weighted partial least squares for high-performance adaptive modeling[J]. Chemometrics and Intelligent Laboratory Systems, 2015, 146: 55–62. DOI:10.1016/j.chemolab.2015.05.007 |
| [33] | Yu J. Online quality prediction of nonlinear and non-Gaussian chemical processes with shifting dynamics using finite mixture model based Gaussian process regression approach[J]. Chemical Engineering Science, 2012, 82: 22–30. DOI:10.1016/j.ces.2012.07.018 |
| [34] | Yu J. Multiway Gaussian mixture model based adaptive kernel partial least squares regression method for soft sensor estimation and reliable quality prediction of nonlinear multiphase batch processes[J]. Industrial & Engineering Chemistry Research, 2012, 51(40): 13227–13237. |
| [35] | Figueiredo M A T, Jain A K. Unsupervised learning of finite mixture models[J]. IEEE Transactions on pattern analysis and machine intelligence, 2002, 24(3): 381–396. DOI:10.1109/34.990138 |
| [36] | Brown G, Wyatt J, Harris R, et al. Diversity creation methods:A survey and categorization[J]. Information Fusion, 2005, 6(1): 5–20. DOI:10.1016/j.inffus.2004.04.004 |
| [37] | Zhou Z H. Ensemble methods: Foundations and algorithms[M]. Florida, USA: Chapman and Hall/CRC, 2012. |
| [38] | Li G, Aute V, Azarm S. An accumulative error based adaptive design of experiments for offline metamodeling[J]. Structural and Multidisciplinary Optimization, 2010, 40(1/2/3/4/5/6): 137. |