



0 引言
云计算的发展为海量的数据存储提供了一个新的方向——云存储[1].它将数据部署在廉价的底层硬件上,为保证其可用性,系统将文件划分为大小相等的数据块并采用多副本存储技术将数据块存放在系统的相应位置[2].根据雅虎Hadoop分布式文件系统(HDFS)访问日志分析,数据中心的冷热数据分布符合帕累托法则,而冷数据的第2副本、第3副本很少被访问[3].此外,在云存储中,节点故障时有发生,设备更换较为频繁.因此云存储中存在着几个问题:
1) 文件以多副本形式存储,系统的存储代价较高;
2) 随着数据中心的运行与扩展,节点的异构性越来越显著,但数据块的部署没有考虑到节点的异构性,随机部署的方式降低了数据的可靠性;
3) 传统的副本放置策略忽略了存储节点的负载情况,容易造成节点负载不均衡.
本文提出了一种新的数据块部署方案,在保证数据可靠性的前提下,降低系统成本、提升系统负载均衡能力.本文的主要贡献是:
1) 对系统中大量的冷数据采用纠删码技术进行存储;
2) 对于异构的存储节点,提出一个低成本、高可靠性的存储方案;
3) 提出了一种新的负载均衡方案,解决了HDFS中负载不均衡问题;
4) 改进传统HDFS中机架感知与副本放置策略的不足,设计一种新型节点选取算法——段排序交换算法(fragment sort swap algorithm,FSSA).
1 研究背景与现状 1.1 研究背景 1.1.1 纠删码技术EC(erasure code)[4]是一种利用纠删码来代替多副本存储的技术.纠删码的运用起源于通讯传输领域对数据传输过程中的错误检测及纠错,并逐步应用于大数据存储系统中.纠删码主要是将原始数据块通过编码的方式生成少量冗余数据块,存储系统将两者都进行存储以达到容错的目的.
Reed-Solomon(RS)[5]是最为常见的纠删码.由原始m个数据块计算产生k个奇偶校验块,记为RS(m,k).存储矩阵由编码矩阵与数据块列向量的乘积产生,编码过程如图 1所示.

|
| 图 1 RS码编码方案 Fig.1 RS code encoding |
当系统中存在受损数据块时,系统将根据受损数据块的位置信息构建译码矩阵,通过译码矩阵与残余数据矩阵的乘积即可计算出受损数据快,译码过程如图 2所示.

|
| 图 2 RS码译码方案 Fig.2 RS code decoding |
基于纠删码的数据存储技术需要对数据进行编码、译码操作,其间需要进行复杂的矩阵运算导致系统的时间开销较大.但是随着计算机软硬件技术的发展,系统编译码的时间开销明显减少.文[6]指出,英特尔已经设计出一个智能存储加速库ISA-L,使用英特尔的Xeon系列处理器能够使编、译码时间大大缩短.
1.1.2 机架感知与副本放置策略大型Hadoop集群以机架的形式进行构建.在HDFS中,NameNode节点通过机架感知绘制出所有DataNode的网络拓扑图[7-10]. HDFS放置副本时,第1个副本存储在本地DataNode节点上,第2个副本放在同一机架的不同DataNode节点上,最后1个副本放置在不同机架的DataNode节点上.
客户端向HDFS系统写入数据时,数据首先被存放在本地临时文件中.当本地临时文件累积到1个数据块的大小(128 M)时,客户端从NameNode获取一个DataNode列表用于存放副本;然后客户端开始向第1个DataNode传输数据,第1个DataNode对数据进行写操作,并同时传输该数据到列表中第2个DataNode节点.同理,第2个DataNode节点采用相同的方法将数据传输到列表中的第3个节点.最后,第3个DataNode接收数据并存储在节点上. DataNode流水线式地从前一个节点接收数据,并同时转发给下一个节点,数据以流水线的方式从前一个DataNode复制到下一个DataNode[11-14],副本的复制与传输过程如图 3所示.

|
| 图 3 副本的复制与传输 Fig.3 Replication and transmission of the data replica |
在存储系统中,虽然单个节点发生故障的概率是随机的,但当有大量的存储节点时,节点故障曲线随时间变化呈现出外高中低的浴盆形,所以节点失效曲线称为浴盆曲线[15].节点故障率随着时间的发展可分为3个阶段:
1) 早期故障期.该阶段出现在节点的早期阶段,主要是由设备的设计、原材料及制造过程中的缺陷造成的,故设备开始使用时,失效率较高,可靠性低.
2) 偶然失效期.该阶段也可被称作随机失效期.节点在此时期失效率较低且较为稳定.因此它可以近似为一个几乎与时间无关的常数.该阶段是产品使用性能最好的阶段.偶然失效主要由节点质量缺陷、材料使用寿命、节点使用环境及节点不当操作等引起.
3) 磨损故障.磨损故障是由于节点长期运行而引起的,主要表现为因磨损、老化和耗损产生的节点失效.其特征是随时间增加,节点间的故障率迅速增加.根据Backblaze公司提供的节点故障率报告显示,磁盘的使用寿命一般为3 y~5 y[16].因此,数据中心的磁盘状况统计信息对于存储节点的选取具有重要的意义.
1.2 研究现状HDFS具有易扩展、高带宽的特点,大数据和云计算采用HDFS作为存储的基础[17].但是,随着数据量的迅速增加,HDFS中关于负载、能耗、存储效率等问题日益显著[18].因此,国内外的许多研究学者开始致力于数据中心存储节点选取的研究中.文[19]提出了一种自适应数据复制算法(DARE),利用现有的远程数据访问系统优化文件副本个数和数据定位问题.文[20]提出了一种数据放置模型,设计了一种双重排序交换算法(DSEC);该算法通过计算系统中节点的性能将其划分为划分为rest set与remaining set两个集合.然后对这2个集合进行双重排序,交换两组元素,直至找到最低成本和可靠性.算法在保证冷数据的可靠性的基础之上降低了系统的存储代价.文[21]通过研究Yahoo公司HDFS集群数据块访问规律,提出基于数据划分的Green HDFS集群,将集群人为地分成Cold区和Hot区,在Hot区的节点驻留着常用数据且具有高功率、高性能的CPU,集群的负载较轻时可将处于Cold区转化成低功耗模式以节省能耗.文[22]将功率控制器和数据块的迁移策略相结合,提出了一种基于动态重新配置数据块的放置方法.该算法根据集群中节点的负载情况动态地控制节点的活跃状态,从而达到节能的目的.文[23]在研究数据块的存储结构与机制、服务器状态及数据块可用性之间的关系后,提出了一种有效平衡数据可用性与QoS的方案.同时定义了分布式存储系统的节能问题.将RACK划分为Active-Zone和Sleep-Zone两个不同的存储区域,使用数据块重新配置算法重新配置集群中的数据存储结构.将Sleep-Zone中的节点设置为休眠状态,从而降低了集群中的能量消耗,提升了存储系统的能效.在企业中,百度HDFS集群采用数据压缩机制[24].对于不经常使用的数据进行周期性压缩,减小系统存储量,以达到降低数据中心资源使用和能耗的效果.
2 方案的设计与实现 2.1 数学建模假设数据中心有N个属性(容量、存储代价、读写速度、可靠性、负载)不完全相同的存储节点.存储节点的可靠性决定了节点中数据的可靠性,同时存储节点的负载又与系统的整体性能息息相关[25].进行数据存储时,如何在保证数据可靠性的基础上,选择综合性能最佳的节点进行存储是数据存储研究的热点.
在HDFS系统中,假设共有N个存储节点.文件传输到HDFS系统时,首先被分割为m个数据块;根据容错度设置的不同,系统将生成k个校验块.
定义1 数据的可靠性.采用纠删码技术对数据存储时,任意k个数据块出现异常系统都可通过译码机制对数据块进行修复.数据可靠性为
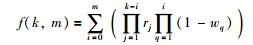
|
(1) |
其中,rj为未出错节点的理论可用性,wq为出错节点的理论可用性.
定义2 数据的存储代价.对于数据存储所选择的n(n=m+k)个节点,其存储代价为
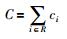
|
(2) |
其中,ci是节点i的存储代价,R是数据存储的节点集合.
定义3 系统的负载均衡能力.在系统中,各个节点与平均负载的绝对值之和在一定程度上可以代表系统的负载能力,系统的负载均衡能力为
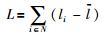
|
(3) |
其中,li是节点i的负载,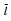
定义4 最优存储节点选取问题(optional datanode selection problem,ODSP).本文的目标是:在保持数据可靠性的前提下,降低存储代价、提升负载均衡.因此,ODSP问题可形式化为
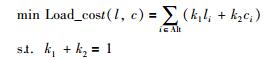
|
(4) |
其中,Load_cost表示ODSP问题的目标函数,(l,c)表示函数中的自变量,li表示节点i的负载,ci表示节点i的存储代价,k1、k2表示参数常量,Alt表示选取节点集合.
由定义4可知,ODSP是一个NP-Hard问题.基于此,本文利用启发式算法的思想提出了段排序交换算法.该算法主要分为节点选择和可靠性验证两个阶段.
为便于下文对算法的描述,将下文中出现的符号及其意义予以描述,见表 1.
| 符号 | 意义 |
| Alt | 备选节点集合 |
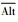
|
非备选节点集合 |
| t_WN | 数据块验证集合 |
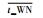
|
非数据块验证集合 |
| N{n1,n2,n3,…} | 节点集合 |
| Alt{nx,…,ny} | 备用节点集合 |
| L | 轻量级负载集合 |
| B | 中量级负载集合 |
| H | 重量级节点集合 |
| .size() | 统计元素个数函数 |
| .push_back() | 入栈函数 |
| .empty() | 判空函数 |
| .pop | 出栈函数 |
| δ | 数据可靠性的需求 |
首先,确认系统中节点的效用函数.用∂i表示节点i的效用函数值,效用函数值由每个节点的可靠性ri、存储代价ci及节点相对负载li构成.效用函数值受3个不同权重值(α1、α2、α3)的影响.节点的可靠性越高、存储代价越低、负载越小被选中的概率越大,各节点的效用函数值如式(5)所示:
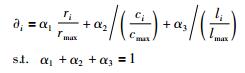
|
(5) |
式(5)中,ri为节点i的可靠性,rmax为集群中最大节点可靠性,ci为节点i的存储代价,cmax为集群中最大存储代价,li为节点i的负载,lmax为集群中最大负载.
其次,根据效用函数对节点集合中各节点进行降序排序.选取前n个节点进入Alt,剩余节点进入
| 算法1 段排序交换算法 |
| 输入 节点集合N{n1,n2,n3,…}. 输出 备用节点集合Alt{nx,…,ny}. Step 1 对集合N以效用函数值降序进行排序. Step 2 对N进行归类处理,前n个元素归并为Alt,剩余节点归并为 ,并对Alt中的节点按照可靠性升序排序. Step 3 验证Alt的整体可靠性,如满足需求,则输出Alt,反之转Step 4. Step 4 对 进行归类处理,按照实际负载将其归并为L、B、H,即:
={L,B,H}并分别按照节点可靠性对3类节点进行降序排序.若节点可靠性相同则存储代价低的节点优先排序. Step 5 从
[i]中选取节点nk,并与Alt中的节点n′k进行对比:若nk的可靠性大于n′k,则将nk与n′k进行交换;反之,i=i+1. Step 6 返回Step 3. |
可靠性验证是对系统选取的备选节点可靠性的验证.由式(1)知,采用纠删码技术对数据进行存储时,数据的可靠性不仅与选取的存储节点的可靠性相关,而且与数据块的冗余个数也相关.方案可靠性验证算法见算法2.
| 算法2 可靠性验证算法 |
| 输入 备用节点集合Alt{nx,…,ny}. 输出 bool(0,1). Step 1 根据系统容错度的设置,获取存储方案中最多可同时失效数据块个数k,并设置循环变量初始值i=0,Result=0. Step 2 设置状态标记符flag=true,t_WN=null.如果i>k,则转Step 6. Step 3 若t_WN.size() < i,则t_WN.push_back(Alt[n]),n--. Step 4 若t_WN.size() < i,则转Step 3;若t_WN. size()=i,则:  Step 5 若t_WN.empty(),则i=i+1,转Step 2;反之,若t_WN.popID=lastNode,则t_WN.pop(),转Step 3. Step 6 如果Result≥δ,则输出true;反之,输出false. |
为了测试段排序交换算法的性能,在300个异构节点仿真集群中通过填充数据的方式进行实验.其中,仿真平台硬件环境为Inter(R) Core(TM)i5-6400 CPU@2.70 GHz,内存(RAM) 8.00 GB;仿真实验采用基于Codeblocks的C++编写,其中编译器及其版本为MinGW GCC-63.0-1.数据块默认大小为128 M,由文[26]中对各种型号硬盘失败率调查,获取硬盘信息,如表 2所示,其中存储代价参照同期京东商城硬盘报价信息.
| 品牌 | 型号 | 内存/T | 可靠性 | 存储代价/¥ | 节点个数/个 |
| Seagate | ST4000DX000 | 4 | 92%±2% | 899 | 120 |
| WDC | WD30EFRX | 3 | 95%±2% | 789 | 120 |
| HGST | HMS5C4040ALE640 | 4 | 99%±1% | 1 159 | 60 |
将FSSA与DSEC[20]、RANDEC算法进行对比. DSEC算法的基本思想是对于系统中的冷数据采用纠删码技术进行存储,在存储节点的选取过程中,首先选择n个节点组成rest set;若可靠性满足需求,则节点选取完成;反之将rest set与remaining set进行双重排序,交换两组元素,直至找出在满足可靠性需求前提下的最低成本结果集合.与DSEC算法相似,RandEC(Random Erasure Code placement)算法也使用删除码技术进行数据存储.将文件分成n个块,包括m个数据块和k个校验块.不同之处在于,该算法在节点上随机放置块,而不考虑每个节点的异构性.
3.1 算法性能 3.1.1 可行性证明由式(4)可知,ODSP问题即在满足数据可靠性的基础之在集群中寻找出存储代价低并能保证系统负载均衡的备选存储节点集合.因此在FSSA中,该问题可以表述为
|
其中,|Alt|表示集合Alt的模,
同理在DSEC中,ODSP可表述为
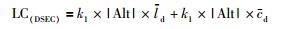
|
其中,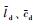
RANDEC中,ODSP可表述为
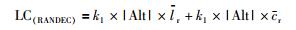
|
其中,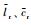
设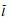
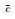
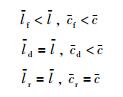
|
所以:
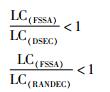
|
因此在保证数据可用性的基础之上,采用FSSA可以最大程度的降低数据的存储代价、提升系统的负载均衡能力.
3.1.2 算法时间复杂度分析在算法1中,设Step 1的时间复杂度分别为O(Step 1).
而Step 1是对存储集群中的节点按照效用函数值进行降序排序,因此O(Step 1)=O(nlog n).
对于Step 2与Step 4,可等价看为对集合中的节点按照可靠性为第1排序项、存储代价为第2排序项进行排序,因此O(Step 2)+O(Step 4)=O(nlog n).
对于Step 5与Step 6分别为数据的交换与的跳转,因此O(Step 5)=O(Step 6)=O(1).
Step 3是对算法产证的中间结果进行可靠性的验证,因此O(Step 3)=O(VA),其中O(VA)为算法2的时间复杂度.
同理可证,O(VA)=O(n).
根据算法的运算流程,本文算法的时间复杂度可表示为
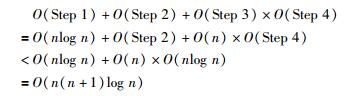
|
由于不同类型的文件对数据可靠性的需求不同,一些重要数据对数据可靠性需求较高,如财务数据等,而日志文件等数据对可靠性的需求较低.本次实验在不同可靠性需求的前提下,对比了3种存储方案在R(15,2)、R(15,3)两种情况下的存储代价,其相应的存储代价如图 4、图 5所示.其中横坐标表示系统对数据可靠性的需求(如0.99表示为2),纵坐标表示选取节点的存储代价(数据产生的存储空间的花费及后期对数据管理时产生的花费).

|
| 图 4 R(15,2)时需求与存储代价关系图 Fig.4 Relationship between reliability and cost at R(15, 2) |

|
| 图 5 R(15,3)时需求与存储代价关系图 Fig.5 Relationship between reliability and cost at R(15, 3) |
由图 4、图 5可以看出,RANDEC对数据的存储代价最高,随着可靠性需求的增高,FSSA的存储代价逐渐低于DSEC.这是因为RANDEC采用随机选取存储节点的方式,在对存储节点进行选取时,未对节点的异构性进行考虑. DSEC只对节点的存储代价进行优化,故在数据可靠性需求较低时,存储代价略高于FSSA.随着数据可靠性需求的增加,采用FSSA在对存储代价的优化略显明显,数据可靠性需求在0.999 9时,算法性能达到最优.
3.3 节点负载对比在存储系统中,提高各个存储节点的负载均衡能力有助于提升系统整体的性能.因此,各个节点的负载均衡指数在一定程度上可以反映整个系统的稳定性.本组实验采取向文件系统中持续写入数据文件的方式,比较在数据可靠性需求为0.999、0.999 99两种情况下系统的整体负载均衡能力.其中横坐标表示文件的存储次数,纵坐标表示各个节点之间的负载方差值.两种可靠性需求时节点负载如图 6、图 7所示.

|
| 图 6 可靠性99.9%时节点负载 Fig.6 Node load at 99.9% reliability |

|
| 图 7 可靠性99.999%时节点负载 Fig.7 Node load at 99.999% reliability |
由图 6、图 7可以看出,随着存储次数的增大,RANDEC与DSEC的节点负载值明显增大,系统负载不均衡,而FSSA中,各个节点之间的负载差异未有明显变化.这是因为,采用FSSA算法在对存储节点进行选取时,首先依据现有负载情况对系统存储节点进行分类.然后当选取存储节点时,充分考虑节点负载能力对系统整体性能的影响,使得系统具有较好的负载均衡能力.
3.4 节点综合性能对比在综合考虑数据存储时的数据安全性、可靠性、存储代价及系统负载均衡能力的前提下,对比了3种存储方案在R(15,2)、R(15,3)两种情况下所选节点集合的综合性能,其对应的节点性能指数如图 8、图 9所示.其中横坐标表示系统对数据可靠性的需求(如0.99表示为2),纵坐标表示选取节点的综合性能(节点的安全性、存储代价、系统整体负载能力).

|
| 图 8 R(15,2)时节点综合性能图 Fig.8 Node comprehensive performance at R(15, 2) |

|
| 图 9 R(15,3)选取节点综合性 Fig.9 Node comprehensive performance at R(15, 3) |
由图 8、图 9可以看出,FSSA选取的节点的综合性能最好,DSEC次之,RANDED选取的节点相对综合性能较差.这是因为采用FSSA选取节点时,对系统中所有的节点分段排序,在相同的分段内,优先选取综合性能较好的节点成为备选节点.之后,在整个系统内进行备选节点的选取,以挑选出综合性能最优的节点进行存储.在满足存储数据基本的需求的前提下,FSSA大大地提升了备选节点的整体性能.
4 总结随着网络空间中数据量的快速增长,传统的HDFS机架感知策略存在着存储冗余度高、负载不均衡等问题.本文在分析不同数据对存储节点性能需求不同的基础上,提出了FSSA算法.采用该算法可以在满足数据对可靠性需求的基础上,最大程度地降低数据的存储代价,同时提高系统中各节点的负载均衡能力.但是,对数据采用纠删码技术进行存储时,未考虑如何提高数据编码与译码的效率,这将是下一步研究的重点.
| [1] |
邱宁佳, 胡小娟, 王鹏, 等.
一致性哈希的数据集群存储优化策略研究[J]. 信息与控制, 2016, 45(6): 747–752.
Qiu N J, Hu X J, Wang P, et al. Research on optimization strategy for data clustered storage using a consistent hash algorithm[J]. Information and Control, 2016, 45(6): 747–752. |
| [2] |
杨挺, 王萌, 张亚健, 等.
云计算数据中心HDFS差异性存储节能优化算法[J]. 计算机学报, 2018, 41(23): 1–14.
Yang T, Wang M, Zhang Y J, et al. HDES differential storage energy-saving optimal algorithm in cloud data center[J]. Chinese Journal of Computers, 2018, 41(23): 1–14. |
| [3] | Kaushik R T, Bhandarkar M. GreenHDFS: Towards an energy-conserving, storage-efficient, hybrid Hadoop compute cluster[C]//International Conference on Power Aware Computing and Systems. Berkeley, CA, USA: USENIX Association, 2010: 1-9. |
| [4] |
宋宝燕, 王俊陆, 王妍.
基于范德蒙码的HDFS优化存储策略研究[J]. 计算机学报, 2015, 38(9): 1825–1837.
Song B Y, Wang J L, Wang Y. Optimized storage strategy research of HDFS based on vandermonde code[J]. Chinese Journal of Computers, 2015, 38(9): 1825–1837. |
| [5] |
傅颖勋, 文士林, 马礼, 等.
纠删码存储系统单磁盘错误重构优化方法综述[J]. 计算机研究与发展, 2018, 55(1): 1–13.
Fu Y X, Wun S L, Ma L, et al. Survey on single disk failure recovery methods for erasure coded storsge systems[J]. Journal of Computer Research and Development, 2018, 55(1): 1–13. |
| [6] | Tucker G, Oursler R, Stern J. ISA-L Igzip: Improvements to a fast deflate[C]//Data Compression Conference. Piscataway, NJ, USA: IEEE, 2017: 465-465. |
| [7] |
徐光伟, 白艳珂, 燕彩蓉, 等.
大数据存储中数据完整性验证结果的检测算法[J]. 计算机研究与发展, 2017, 54(11): 2487–2496.
Xu G W, Bai Y K, Yan C R, et al. Check algorithm of data integrity verification results in big data storage[J]. Journal of Computer Research and Development, 2017, 54(11): 2487–2496. DOI:10.7544/issn1000-1239.2017.20160825 |
| [8] |
燕彩蓉, 钱凯.
云存储中基于相似性的客户-服务端双端数据去重方法[J]. 东华大学学报(自然科学版), 2018, 44(1): 1–8.
Yan C R, Qian K. Similarity-based client-server data dedupli-cation method in cloud storage[J]. Journal of Donghua University (Natural Sciences), 2018, 44(1): 1–8. DOI:10.3969/j.issn.1671-0444.2018.01.001 |
| [9] | Chen D, Chen Y, Brownlow B N, et al. Real-time or near real-time persisting daily healthcare data into HDFS and elasticsearch index inside a big data platform[J]. IEEE Transactions on Industrial Informatics, 2017, 13(2): 595–606. DOI:10.1109/TII.2016.2645606 |
| [10] | Chen S, Pedram M. Efficient peak shaving in a data center by joint optimization of task assignment and energy storage management[C]//9th IEEE International Conference on Cloud Computing. Piscataway, NJ, USA: IEEE, 2017: 77-83. |
| [11] | Liao B, Yu J, Zhang T, et al. Energy-efficient algorithms for distributed storage system based on block storage structure reconfiguration[J]. Journal of Computer Research & Development, 2013, 48(1): 71–86. |
| [12] | Kim J, Chou J, Rotem D. iPACS:Power-aware covering sets for energy proportionality and performance in data parallel computing clusters[J]. Journal of Parallel & Distributed Computing, 2014, 74(1): 1762–1774. |
| [13] | Luo S, Zhang G, Wu C, et al. Boafft: Distributed deduplication for big data storage in the cloud[J/OL]. IEEE Transactions on Cloud Computing, doi: 10.1109/TCC.2015.2511752.[2015-05-01].https://www.computer.org/csdl/trans/cc/preprint/07364228-abs.html. |
| [14] | Paulo J, Pereira J. Efficient Deduplication in a distributed primary storage infrastructure[J]. ACM Transactions on Storage, 2016, 12(4): 1–35. |
| [15] | Song Y, Wang B. Survey on reliability of power electronic systems[J]. IEEE Transactions on Power Electronics, 2012, 28(1): 591–604. |
| [16] | Backblaze hard drive stats for 2016[EB/OL].[2017/01/31]. https://www.backblaze.com/blog/hard-drive-benchmark-stats-2016/?highlight=Backblaze%20Hard%20Drive%20Stats%20for%202018. |
| [17] | Chen D, Chen Y, Brownlow B N, et al. Real-time or near real-time persisting daily healthcare data into HDFS and elasticsearch index inside a big data platform[J]. IEEE Transactions on Industrial Informatics, 2017, 13(2): 595–606. DOI:10.1109/TII.2016.2645606 |
| [18] | Chen S, Pedram M. Efficient peak shaving in a data center by joint optimization of task assignment and energy storage management[C]//International Conference on Cloud Computing. Piscataway, NJ, USA: IEEE, 2017: 77-83. |
| [19] | Abad C L, Lu Y, Campbell R H. DARE: Adaptive data replication for efficient cluster scheduling[C]//IEEE International Conference on CLUSTER Computing. Piscataway, NJ, USA: IEEE, 2011: 159-168. |
| [20] | Du Y, Xiong R, Jin J, et al. A cost-efficient data placement algorithm with high reliability in hadoop[C]//International Conference on Advanced Cloud & Big Data. Piscataway, NJ, USA: IEEE, 2017: 100-105. |
| [21] | Kaushik R T, Bhandarkar M, Nahrstedt K. Evaluation and Analysis of GreenHDFS: A self-adaptive, energy-conserving variant of the hadoop distributed file system[C]//IEEE Second International Conference on Cloud Computing Technology and Science. Piscataway, NJ, USA: IEEE, 2011: 274-287. |
| [22] | Maheshwari N, Nanduri R, Varma V. Dynamic energy efficient data placement and cluster reconfiguration algorithm for MapReduce framework[J]. Future Generation Computer Systems, 2012, 28(1): 119–127. DOI:10.1016/j.future.2011.07.001 |
| [23] | Liao B, Yu J, Zhang T, et al. Energy-efficient algorithms for distributed storage system based on block storage structure reconfiguration[J]. Journal of Computer Research & Development, 2013, 48(1): 71–86. |
| [24] |
孙桂林.百度HDFS集群的数据压缩[R/OL]. (2012-04-15)[2018-06-08]. http://dtcc.it168.com/2012/3.html. Sun G L. Data compression of Baidu HDFS cluster[R/OL]. (2012-04-15)[2018-06-08]. http://dtcc.it168.com/2012/3.html. |
| [25] |
王宁, 杨扬, 孟坤, 等.
云计算环境下基于用户体验的成本最优存储策略研究[J]. 电子学报, 2014, 42(1): 20–27.
Wang N, Yang Y, Meng K, et al. A customer experience-based cost minimization strategy of storing data in cloud computing[J]. Acta Electronica Sinica, 2014, 42(1): 20–27. DOI:10.3969/j.issn.0372-2112.2014.01.004 |
| [26] | Klein A. Hard drive stats for Q22017[EB/OL]. (2017-08-29)[2018-06-08]. https://www.backblaze.com/blog/hard-drive-failure-stats-q2-2017/. |