



0 引言
频繁模式挖掘[1-2],能从大量数据中提取出有效信息,为利益相关方提供决策依据,其中不确定数据集[3]的频繁模式挖掘是其众多研究之一.此类算法主要分为三种:基于期望的频繁模式挖掘,基于概率的频繁模式挖掘和基于权重的频繁模式挖掘.
首先在基于期望的频繁模式挖掘算法中,许多算法是基于Apriori算法[4]的改进,如Chui等人首次提出的U-apriori算法[5],该算法主要通过统计数据项集的期望来逐层挖掘不确定数据集中的频繁模式,但是同Apriori算法的缺点一致,会产生过多的候选集,需要多遍扫描数据集,所以时间和空间的消耗较大.针对这个问题,Wang等人提出了MBP[6]算法,MBP算法直接删除部分期望支持度低于原定最小支持度的候选集,通过减少候选集来降低算法时间复杂度,同时,提前被认为是非候选集的数据项集,不再统计其实际期望支持度,提高了算法的效率.随后Sun等人在MBP算法的基础上提出了改进算法IMBP[7],利用一种新策略减少候选项集产生的个数,降低了内存消耗和运行时间.同时也有基于FP-growth[4]的改进算法,如Leung等人提出的UF-growth[8]算法,构建UF-tree来挖掘频繁模式,然而由于大量的数据集都被压缩到一棵树上,导致需要存储数据集的树较大,所以算法的时间空间复杂度较高.为了提高UF-Growth算法的效率,Lin等人提出了CUFP-growth[9]算法,该算法采用非递归模式和大规模缩减UF-Tree的方式达到了快速获得频繁模式的目的,但算法的内存开销较大,有待改进.
其次在基于概率的频繁模式挖掘算法中,Bernecker等人首次提出了一种基于Apriori的新颖算法[10],并采用可能世界语义的概率公式来解决概率频繁模式挖掘问题,按照数据项概率递增输出结果,该算法需要反复迭代才能筛选出频繁项集,算法的时间与空间复杂度较大.为此,Sun等人设计了一种p-FP结构并提出了TODIS[11]算法,来挖掘不确定数据集中的频繁模式.这两类算法只分析数据项存在概率或期望,没有考虑到数据项的重要性.
最后在基于权重的频繁模式挖掘算法中,Yun等人首次提出了序列模式挖掘算法Wspan[12],引用向下封闭属性,设定一个最低阈值来筛选频繁模式,然而数据项的权重参数关联规则不够清晰.因此,Wang等人提出了权重关联规则WAR[13],着重于规则是如何生成的,不干涉生成频繁模式的过程,适用于处理自带权重的不确定数据集,却没有考虑每个数据项在不同事务中可能存在的权重不同的问题.为此,Lan等人提出了IUA[14]和PWA[15]基于权重支持度的不确定数据集挖掘算法,能考虑到现实世界中数据项的不同权重值问题.为了拓展基于权重的频繁模式类型,Chun等人提出了RWFIM[16]和RWFI-Mine[17]算法.这类算法分析数据项的权重值却忽略其生存概率.因此,Lin等人提出了HEWI-Uapriori算法[18],利用数据项的期望和权重计算出数据项的期望权重支持度,该算法虽然兼顾数据项的权重和期望,但面对大规模海量数据,执行效率有待提高.
近些年在大数据背景[19]下,为提高频繁模式挖掘算法的效率,越来越多的研究利用分布式平台处理数据,如Qiu等人提出的算法YAFIM[20],直接将Apriori算法在Spark框架上实现,提高了Apriori算法的执行效率. Rathee等人提出的R-Apriori[21]算法,对基于Spark的Apriori算法进行了优化,通过消除候选集生成步骤,使算法的效率又在一定程度上得到了提高. Shi等人提出的LBPFP[22]是具有FP-Growth算法特点的并行算法,由于过程中不需要生成候选集和反复扫描数据集,执行效率明显优于具有Apriori算法特点的分布式算法.然而这些算法主要针对的是确定数据集的频繁模式挖掘,不确定数据集中频繁模式挖掘的分布式算法研究依旧很有必要.
综上,我们提出一种基于Spark的不确定数据集频繁模式挖掘算法(简称UWEFP),具有FP-Growth分布式算法特点,设计新颖的UWEFP-tree结构,在Spark框架中分布式处理数据集,通过计算数据项的最大期望权重提前剪枝,最后以数据项的期望权重支持度挖掘出频繁模式.该算法既能兼顾数据项的存在概率和权重,又能快速挖掘出频繁项集.
1 问题定义设I={i1,i2,…,im}是一个有m个数据项的集合. W={w(i1),w(i2),…,w(im)}是对应各个数据项的权重集.区别于确定数据集,不确定数据的每个元组序列带有一个存在可能属性,这个属性表明该元组存在的置信度,即存在的概率[23].定义不确定事务集为T={t1,t2,…,tn},p(im,tn)是事务tn中im数据项的存在概率.
定义1 事务中数据项集的权重:记为w(x,tn),表示数据项x在事务tn中的权重.
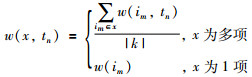
|
(1) |
其中,|k|是数据项集x的中包含的数据项个数.
定义2 数据项集的概率:事务中数据项集的概率表示数据项集存在的概率,记为p(x,tn).
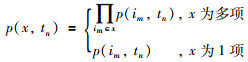
|
(2) |
定义3 事务中数据项的期望支持度:事务中数据项的期望支持度,是事务中x出现的所有概率之和,记为expsup(x,tn).
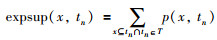
|
(3) |
定义4 事务中数据项的期望权重支持度:表示事务中数据项x的期望权重支持度,记为ewsup(x)
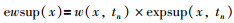
|
(4) |
定理1 向下封闭属性[14]:如果一个项集满足某个最小支持度要求,那么这个项集的任何非空子集都满足这个最小支持度.
2 UWEFP算法不确定数据集频繁模式的挖掘算法通常面临如下问题:1)传统算法通常以期望、概率或权重为单一的数据项支持度,不能挖掘出更具有价值的频繁模式;2)针对大量不确定数据集挖掘的算法效率仍然有待提高.对此,UWEFP算法提出以下应对措施:1)为了兼顾数据项的存在概率和权重,提出数据项的最大权重概率,并通过提前剪枝的方法来提高算法的效率;2)设计一种非递归模式的UWEFP-tree,将数据项及其超集的信息都存放在树中,无需多次扫描数据集,不用产生候选集,分布式构建频繁模式树;3)算法的整体设计与Spark平台的优势相结合,分布式挖掘,在保证挖掘结果的同时大大提高了效率. UWEFP算法可以分为3个阶段,首先,为了提高频繁模式挖掘效率,我们将原始确定数据集放在Spark平台下对其进行扩展,使其能够表示不确定数据集,并计算数据项的最大权重概率,提前剪枝;其次,设计一种具有FP-tree特征的UWEFP-tree,按事务号随机分组,分布式构建频繁模式树;最后合并UWEFP-tree中的数据集信息并挖掘出频繁模式.流程图如图 1所示.

|
| 图 1 UWEFP算法程序流程图 Fig.1 Procedure flow chart of UWEFP |
定义事务的最大权重值:表示事务中所有数据项的最高权重记为max w(tn).
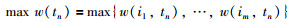
|
(5) |
定义事务的最大概率值:表示事务中所有数据项的最高概率值记为max p(tn)
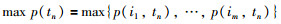
|
(6) |
定义事务的最大权重概率:表示事务中最高的概率和最高的权重之积,记为max wp(tn).
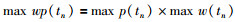
|
(7) |
定义数据项的最大权重概率:表示数据项存在于所有的事务中事务的最大权重概率之和,记为max wp(x)
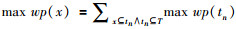
|
(8) |
其中,x为数据项集,tn是第n个事务,T为数据集.
定义频繁模式:设最小支持度为ε×|T|,其中|T|是原数据集中事务的个数,ε是0到1之间的任意实数,对任意的模式x(x⊆I),x的期望权重支持度大于等于最小支持度ε×|T|,则称x为频繁模式.
很多研究根据定理1的性质挖掘确定数据集的频繁模式.然而,该定理却不适用于不确定数据集频繁模式的挖掘,传统的剪枝策略不能用于此类算法,所以本文设计了一种新的剪枝策略.
假设xk是k项集,xk-1是xk的子集,则max wp(xk)≤max wp(xk-1).
证明:
设IDS(xk)表示xk存在的事务集
由于xk-1是xk的子集,则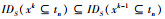
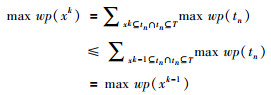
|
因此,如果max wp(x)小于最小支持度,那么x的所有超集都小于最小支持度.
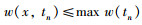
|
证明:
由于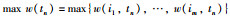
当x为多项时:
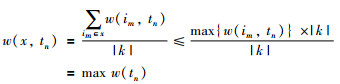
|
当x为1项时:
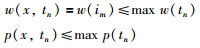
|
证明:
由于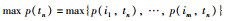
当x为多项时:
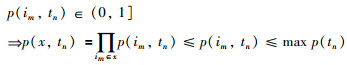
|
当x为1项时:
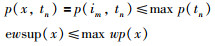
|
证明:
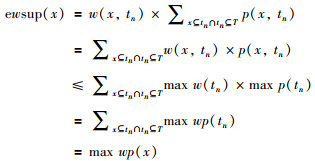
|
因此,如果max wp(x)小于最小支持度,那么x以及x的所有超集的期望权重支持度都小于最小支持度,即都不是频繁模式.所以在UWEFP算法中,我们通过利用max wp(x)初步剪枝,再计算数据项的ewsup(x)筛选出最终频繁项集.
Spark将原始数据文件,按照默认块大小分成多组,每组对应一个数据集,分组后的数据集在RDD0:<trans>中,其中trans表示事务. map函数进行预处理,生成有事务号、数据项、概率和权重四个域的不确定数据集RDD1:<ID,(key,p,w)>,其中ID为事务号,key表示数据项,p为数据项的存在概率,w为数据项的权重.预设最小阈值.
map和flatmap配合生成RDD2:<key,(ID,p,w,max wp(tn))>. GroupBykey函数统计数据项的最高概率权重生成RDD3:<key,(ID,p,w,max wp(x))>,filter函数过滤掉小于最小支持度的数据项得到RDD4:<key,(ID,p,w,max wp(x))>. 图 2为此阶段数据在RDD中的变化.

|
| 图 2 UWEFP算法第一阶段 Fig.2 Phase 1 of UWEFP |
| 算法1 RDD4生成算法 | |
| Phase 1 Algorithm | |
| //Input:Database | |
| //Output:RDD4 | |
| 1.RDD0←Database | //输入数据集 |
| 2.RDD1←Random RDD.p.w | //将数据集中的数据项附上概率和权重权 |
| 3.RDD2←calculate trans.max wp | //计算事务的max wp |
| 4.RDD3←calculate item.max wp | //计算数据项的max wp |
| 5.if item.max wp≥min sup | //数据项的max wp≥用户预设的最小阈值时 |
| 6.RDD4←item | |
频繁模式的挖掘过程,主要是基于一种具有FP-tree特征的UWEFP-tree,树的每个节点表示一个数据项,每个数据项中都存储着其ewsup(x),同时每个节点上也存储着其超集的信息.
| 算法2 UWEFP-tree的构建 |
| Phase 2 Algorithm |
| //Input:RDD4 |
| //Output:RDD5 |
| 1.Create null //建树的根节点null |
| 2.For each item in RDD4 |
| 3.Calculate item.ewsup //计算RDD中每个数据项的ewsup |
| 4.If tree.node=RDD4.item tree.node.ewsup=tree.node.ewsup +RDD4.item.ewsup//将RDD4中的每个节点插入 树中,如果树中有相应的节点,将该节点的值累加到相 应节点上. |
| 5.tree.node←supernode //并且附上该节点的超集信息 |
| 6.Else create newlist tree.node.ewsup //如果树中不存在相应节点, 建立新的分支,存储数据项信息 |
| 7.tree.node←supernode //并附上该节点超集的信息 |
| 8.Build supernode:{ while(tree.node!=null & & !(tree.node)) superlabel=RDD4.item+superrlabel}//为节点建立超集 |
| 9.For each node in tree |
| 10.RDD5←node.key node.ewsup//树中的每个节点信息 生成RDD5 |
在RDD4的各组数据集中分别构建UWEFP-tree,建树过程如上述伪代码所示.计算出局部数据项集的期望权重值ewsup(x),生成RDD5:<key,ewsup(x)>. 图 3为此阶段数据在RDD中的变化.

|
| 图 3 UWEFP算法第二阶段 Fig.3 Phase 2 of UWEFP |
GroupBykey函数整合两组数据集的UWEFP-tree中的所有数据项集得到RDD6:<key,ewsup(x)>.依次判断数据项的ewsup(x)是否不小于ε×|T|,删除小于ε×|T|的数据项集后得到RDD7:<key,ewsup(x)>. 图 4为此阶段数据在RDD中的变化.

|
| 图 4 UWEFP算法第三阶段 Fig.4 Phase 3 of UWEFP |
| 算法3 频繁项集的挖掘方法 |
| Phase 3 Algorithm |
| //Input:RDD5 |
| //Output:RDD6 |
| 1.RDD6←calculate RDD5.item.ewsup //将RDD5中的数 据项相同的ewsup累加起来生成RDD6 |
| 2.If RDD6.item.ewsup≥min sup RDD7←item //如果数据项的 ewsup≥min sup,保留数据生成RDD7 |
| 3.Return RDD7 //返回RDD7 |
原数据集,如表 1所示.算法整体过程在Spark平台上进行,预处理后生成不确定数据集,这里假设Spark将原数据集分成两组,如表 2所示.
| 第一组(事务号, 数据项, 概率, 权重) |
第二组(事务号, 数据项, 概率, 权重) |
| (1, B, 0.8, 0.9) | (6, A, 0.5, 0.5) |
| (1, C, 1.0, 1.0) | (6, C, 0.25, 1.0) |
| (2, C, 0.8, 1.0) | (6, D, 0.4, 0.3) |
| (2, D, 0.6, 0.3) | (6, E, 0.2, 0.8) |
| (2, F, 0.7, 0.6) | (7, D, 0.5, 0.3) |
| (3, B, 0.6, 0.9) | (7, F, 1.0, 0.6) |
| (3, C, 0.8, 1.0) | (8, A, 1.0, 0.5) |
| (4, D, 0.4, 0.3) | (8, C, 0.2, 1.0) |
| (4, E, 0.8, 0.8) | (8, E, 0.8, 0.8) |
| (4, F, 1.0, 0.6) | (9, D, 0.7, 0.3) |
| (5, A, 1.0, 0.5) | (9, E, 0.8, 0.8) |
| (5, B, 0.7, 0.9) | (10, B, 0.8, 0.9) |
| (5, C, 0.4, 1.0) | (10, C, 1.0, 1.0) |
| (10, E, 0.2, 0.8) |
预设最小阈值为0.3,|T|为事务的个数10,所以最小支持度为ε×|T|=0.3×10=3.
向下封闭属性不适用于不确定数据集频繁模式的挖掘,传统的剪枝策略无法用于此类算法,以下是新的剪枝策略.
根据式(5),计算max w(tn),例如t1中所有数据项的权重最大的是w(C)=1.0,所以max w(t1)=1.0.根据式(6),计算max p(tn),例如t1中所有数据项的概率最大的是p(C)=1.0,所以,max p(t1)=1.0.根据式(7),计算max wp(tn),例如,max wp(t1)=1.0×1.0=1.0.由此得到表 3.
| 第一组 (事务号,max w(tn), max p(tn),max wp(tn)) |
第二组 (事务号,max w(tn), max p(tn),max wp(tn)) |
| (1,1.0,1.0,1.0) | (6,1.0,0.5,0.5) |
| (2,1.0,0.8,0.8) | (7,0.6,0.6,0.6) |
| (3,1.0,0.8,0.8) | (8,1.0,1.0,1.0) |
| (4,1.0,0.8,0.8) | (9,0.8,0.8,0.64) |
| (5,1.0,1.0,1.0) | (10,1.0,1.0,1.0) |
根据式(8),A存在事务5,6,8中,max wp(A)=1.0+0.5+1.0=2.5.同理:{max wp(A)=2.5,max wp(B)=3.8,max wp(C)=6.1,max wp(D)=3.34,max wp(E)=3.94,max wp(F)=1.4}. filter函数过滤掉最小支持的数据项得到RDD4:<key,(ID,p,w,max wp(x))>,删除A、F更新后如表 4所示.
| 第一组(事务号,数据项) | 第二组(事务号,数据项) |
| (1,B C) | (6,C D E) |
| (2,C D) | (7,D) |
| (3,B C) | (8,C E) |
| (4,D E) | (9,D E) |
| (5,B C) | (10,B C E) |
UWEFP-tree是一种新颖的条件模式树,树的每个节点表示一个数据项,每个数据项中都存储着其支持度,区别于FP-tree,UWEFP-tree每个的节点上也存储着其超集的信息,从而挖掘过程中无需构造条件模式基.
接下来分别在每个分组中构建UWEFP-tree.如图 5(a)所示,建立第一组UWEFP-tree的根节点Null,扫描数据库中的事务1,建立节点B、C,附上各节点及超集的ewsup(x).根据式(1):w(B,t1)=0.9,w(BC,t1)=(w(B,t1)+w(C,t1))/2=(0.9+1.0)/2=0.95.根据式(3),expsup(B,t1)=0.8,expsup(BC,t1)=0.81.0=0.8.根据式(4),ewsup(B)=w(B,t1)×expsup(B,t1)=0.9×0.8=0.72,ewsup(BC)=w(BC,t1)×expsup(BC,t1)=0.95×0.8=0.76.同理得到,ewsup(C)=1.0. 图 5(b)所示.

|
| 图 5 频繁模式树的建立过程 Fig.5 Process of constructing UWEFP-tree |
由于树中不存在事务2中相应的节点,所以建立新的分支C,D;由于树中存在事务3中相应的节点B、C,只需将各项的ewsup(x)累加到相同节点上. 图 5(c)所示,新建事务4的分支,累加事务5到相同节点中.第一组数据集中的UWEFP-tree建立完毕.
同理构建第二组数据集中的UWEFP-tree.将每组数据集中相同项的ewsup(x)累加起来并更新.更新后的第一组数据集为:{B,1.89 C,3.0 BC,1.482 D,0.3 CD,0.312 E,0.64 DE,0.176};更新后第二组数据集为:{C,1.45 D,0.48 CD,0.065 E,1.6 CE,0.774 DE,0.352 B,0.72 BC,0.76 CDE,0.014 BE,0.136 BCE,0.144};合并所有分组中数据项相同的ewsup(x),得到:{B,2.61 C,4.45 D,0.78 E,2.24 BC,2.242 CD,0.377 DE,0.528 CE,0.774 CDE,0.014 BE,0.136 BCE,0.144}.依次判断数据项的ewsup(x)是否不小于ε×|T|=3,删除小于3的数据项后得到频繁项集:{C,4.45}.
3 实验结果与分析为了验证本文所提出UWEFP算法的性能,将其与CUFP-growth(基于期望的不确定数据集频繁模式挖掘算法),PWA(基于权重的不确定数据集频繁模式挖掘算法)进行对比分析,其中UWEFP算法的实验运行环境为Spark,数据存储平台为HDFS,开发语言为Scala,操作系统为Linux,开发工具为IntelliJ IDEA,Spark集群由17个节点构成,包括1个主节点和16个从节点,每个节点CPU核数为2,运行内存4 GB.实验数据集来源于UCI机器学习数据库,分别为T1014D100K、retail、mushroom.实验中,数据集有两个数据标识:事务个数(|T|),事务平均长度(L),如表 5所示.在不确定数据集频繁模式挖掘算法中,通常实验数据集都是由公共的确定数据集随机加入概率生成的[4, 24-25],所以我们提前为三组确定数据集随机加入概率.
| 数据集 | 事务个数 | 每条事务平均长度 |
| retail | 88 162 | 10.3 |
| mushroom | 8 124 | 23 |
| T10I4D100K | 100 000 | 10.1 |
为了评价UWEFP算法挖掘频繁模式的有效性,在不同的用户支持度阈值下本文采用UWEFP,CUFP-growth,PWA对三组数据集进行挖掘,对比生成的频繁模式个数.其中UWEFP的Minsupport为算法中所预设的值,CUFP-growth的Minsupport为算法中用户定义的minimum support threshold,PWA的Minsupport即为算法中定义的min Wsup.实验结果如图 6所示.

|
| 图 6 不同算法生成频繁模式个数 Fig.6 Frequent numbers of different algorithms |
图 6显示了CUFP-growth,PWA,UWEFP三种算法在不同的用户支持度阈值时对三组数据进行挖掘产生的频繁模式个数. CUFP-growth算法挖掘出的是基于期望的频繁模式,PWA算法挖掘出的是基于权重的频繁模式,UWEFP算法挖掘出的是基于期望和权重的频繁模式.从图中可以看出,UWEFP算法产生的频繁模式个数无论在哪种情况下都少于其他两种算法;这是因为CUFP-growth算法所生成的频繁模式没有考虑数据项的权重,PWA算法所生成的频繁模式没有考虑数据项的存在概率,这些频繁模式没有更精确有价值地反应现实世界的情况.同时,当最小支持度增加时,三种算法生成的频繁模式数量都急剧减少.
3.2 实验2 节点个数对算法运行时间的影响为了评价算法的效率,本文将UWEFP算法分别在同一用户支持度阈值不同节点个数下,对三组数据集进行挖掘对比运行时间,其中retail的最小阈值设为0.08%,T10I4D100K的最小阈值设为0.03%,Mushroom的最小阈值设为20%.实验结果如图 7所示.

|
| 图 7 不同节点个数的执行时间 Fig.7 Runtime of different number of nodes |
图 7显示,算法的执行时间会随着节点个数的增加而减少.这说明,在Spark平台上进行挖掘是有性能提升的.所以在针对大规模不确定数据集挖掘时,完全可以通过增加Spark集群中的节点数量,来缩短挖掘时间.由于算法只需对数据集进行一次扫描,提前剪枝,无需产生大量的候选集,保证了整体效率.
3.3 实验3 算法在不同数据集上的执行效率为验证本文提出的在Spark环境下UWEFP算法的效率,将本文提出的算法与相关传统单机上的算法进行对比,并在数据集retail和T10I4D100K上进行算法加速比测试.算法加速比,是算法在单机环境下和分布式环境下运行消耗时间的比率值,用来评价程序并行化后的效果.节点数量取{8,10,12,14,16}的最小阈值设为0.08%,T10I4D100K的最小阈值设为0.03%.通过对比实验,分析本文提出方法的效率. 图 8是UWEFP算法的加速比实验结果.

|
| 图 8 不同规模数据集的加速比对比 Fig.8 Speedup comparison of different scale datasets |
从图 8(a)的结果可以观察到,算法的加速比随着Spark集群计算节点的增加而逐渐上升,变化从线性增长到平稳状态.这是由于retail的数据集较小,以至于算法的分布式处理能力没有得到充分的利用.从图 8(b)的结果可以观察到,在相同节点的情况下,随着Spark集群计算节点的增加算法的加速比增长趋势更为明显,这是因为数据集较大时,Spark环境下算法的分布式处理能力得到了充分的利用.因此,在Spark环境下算法具有较好的并行化性能.
实验结果表明UWEFP算法能够精确地挖掘出更有价值的频繁模式,并且能提高算法的效率.
4 结语本文针对海量不确定数据集的频繁模式挖掘算法,提出了一种具有FP-Growth特征的UWEFP算法. FP-Growth算法采用分治策略,将提供频繁模式的数据库压缩到一棵频繁模式树(FP-tree)上,但是挖掘时仍然需要构建搜索条件模式基. UWEFP算法在FP-tree的基础上提出了UWEFP-tree,提前将条件模式基等数据项集的相关信息存储在UWEFP-tree上,将对数据集扫描的次数减少为一次,通过提前剪枝的方式,避免产生大量候选集,并较好地利用了Spark分布式平台高效的计算能力.实验结果表明,本方法在保证挖掘结果的前提下,提高了效率.
| [1] | Soysal Ö M, Gupta E, Donepudi H. A sparse memory allocation data structure for sequential and parallel association rule mining[J]. The Journal of Supercomputing, 2016, 72(2): 347–370. DOI:10.1007/s11227-015-1566-x |
| [2] | Lin C W, Gan W, Fournier-Viger P, et al. Efficient mining of weighted frequent itemsets in uncertain databases[C]//12th International Conference on Machine Learning. Berlin, Germany: Springer, 2016: 236-250. |
| [3] | Karim M R, Cochez M, Beyan O D, et al. Mining maximal frequent patterns in transactional databases and dynamic data streams:A spark-based approach[J]. Information Sciences, 2018, 432: 278–300. DOI:10.1016/j.ins.2017.11.064 |
| [4] | Chee C H, Jaafar J, Aziz I A, et al. Algorithms for frequent itemset mining:A literature review[J]. Artificial Intelligence Review, 2018(3): 1–19. |
| [5] | Chui C K, Kao B, Edward H. Mining frequent itemsets from uncertain data[C]//11th Pacific-Asia conference on Advances in knowledge discovery and data mining: vol. 4426. Berlin, Germany: Springer-Verlag, 2007: 47-58. |
| [6] | Wang L, Cheung D W, Cheng R, et al. Efficient mining of frequent item Sets on large uncertain datasets[J]. IEEE transactions on Knowledge and Data Engineering, 2012, 24(12): 2170–2183. DOI:10.1109/TKDE.2011.165 |
| [7] | Sun X, Lim L, Wang S. An approximation algorithm of mining frequent itemsets from uncertain dataset[J]. International Journal of Advancements in Computing Technology, 2012, 4(3): 42–49. DOI:10.4156/ijact |
| [8] | Leung C K, Carmichael C L, Hao B. Efficient mining of frequent patterns from uncertain data[C]//17th IEEE international Conference on Data Mining Workshops. Piscataway, NJ, USA: IEEE, 2007: 489-494. |
| [9] | Chun W L, Tzung P H. A new mining approach for uncertain datasets using CUFP-trees[J]. Expert Systems with Applications, 2012, 39(4): 4084–4093. DOI:10.1016/j.eswa.2011.09.087 |
| [10] | Bernecker T, Kriegel H P, Renz M, et al. Probabilistic frequent itemset mining in uncertain datasets[C]//15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, USA: ACM, 2009: 119-128. |
| [11] | Sun L, Cheng R, Cheung D W, et al. Mining uncertain data with probabilistic guarantees[C]//16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, USA: ACM, 2010: 273-282. |
| [12] | Yun U, Leggett J. WSpan: Weighted sequential pattern mining in large sequential datasets[C]//3th International IEEE Conference on Intelligent Systems. Piscataway, NJ, USA: IEEE, 2006: 512-517. |
| [13] | Wang W, Yang J, Yu P S. Efficient mining of weighted association rules (war)[C]//6th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, USA: ACM, 2000: 270-274. |
| [14] | Lan G C, Hong T P, Lee H Y. An efficient approach for finding weighted sequential patterns from sequences[J]. Applied Intelligence, 2014, 41(2): 439–452. DOI:10.1007/s10489-014-0530-4 |
| [15] | Lan G C, Hong T P, Lee H Y, et al. Mining weighted frequent itemsets[J]. The Workshop on Combinational Mathematics and Computation Theory, 2013: 85–89. |
| [16] | Lin C W, Gan W, Fournier-Viger P, et al. RWFIM:Recent weighted-frequent itemsets mining[J]. Engineering Applications of Artificial Intelligence, 2015, 45: 18–32. DOI:10.1016/j.engappai.2015.06.009 |
| [17] | Lin C W, Gan W, Fournier-Viger P, et al. Efficiently mining frequent itemsets with weight and regency constraints[J]. Applied Intelligence, 2017, 47(3): 769–792. DOI:10.1007/s10489-017-0915-2 |
| [18] | Lin C W, Gan W, Fournier-Viger P, et al. Weighted frequent itemset mining over uncertain datasets[J]. Applied Intelligence, 2016, 44(1): 232–250. DOI:10.1007/s10489-015-0703-9 |
| [19] |
何文韬, 邵诚.
工业大数据分析技术的发展及其面临的挑战[J]. 信息与控制, 2018, 47(4): 398–410.
He W T, Shao C. The development and challenges of industrial big data analysis technology[J]. Information and Control, 2018, 47(4): 398–410. |
| [20] | Qiu H, Gu R, Yuan C, et al. YAFIM: A parallel frequent itemset mining algorithm with spark[C]//IEEE International Parallel & Distributed Processing Symposium Workshops. Piscataway, NJ, USA: IEEE, 2014: 1664-1671. |
| [21] | Rathee S, Kaul M, Kashyap A. R-Apriori: An efficient apriori based algorithm on spark[C]//the 8th Workshop on Information and Knowledge Management. New York, USA: ACM, 2015: 27-34. |
| [22] | Shi L, Qian X Z. Research and implementation of parallel FP-Growth algorithm based on Hadoop[J]. Microelectronics&Computer, 2015, 32(4): 150–154. |
| [23] | Zhao Z, Yan D, Wilfred N G. Mining probabilistically frequent sequential patterns in uncertain databases[C]//Proceedings of the 15th International Conference on Extending Database Technology. New York: ACM Press, 2012: 74-85. |
| [24] | Lin C W, Gan W, Fournier-Viger P, et al. Efficiently mining uncertain high-utility itemsets[J]. Soft Computing, 2017, 21(11): 1–20. |
| [25] | Sethi K K, Ramesh D. HFIM:A Spark-based hybrid frequent itemset mining algorithm for big data processing[J]. Journal of Supercomputing, 2017, 73(1): 1–17. |