



2. 湖州师范学院信息与控制技术研究所, 浙江 湖州 313000
2. Institute of Information and Control Technology, Huzhou University, Huzhou 313000, China
0 引言
间歇生产过程[1]是一类复杂工业过程,是指生产过程在同一位置而在不同的时间分批进行,已广泛应用于生物制药、食品、半导体加工等工业生产领域,其操作状态不稳定,过程参数随时间而变,与连续生产相比,过程更加复杂多变,即使任意过程微小的异常状况都会影响最终产品的质量,所以找到有效的过程监控方法对间歇过程进行故障检测具有重要意义.由于不同的操作阶段具有不同的过程特性,使得监测变量会受到时间维度的影响,所以针对具有多阶段操作特性的间歇生产过程进行正确的操作阶段划分,对实现间歇过程数据的检测具有很重要的作用.传统的基于数据驱动[2]的多向主元分析(multiple direction principal component analysis,MPCA)和多向偏最小二乘(multiple direction partial least squares,MPLS)方法已经被广泛应用于间歇过程的监控[3-8],但在具有多工序、非线性、非高斯等特征的间歇过程故障检测中使用情况并不理想,这两种方法均假设过程数据是高斯分布的,且均来自同一个操作阶段,没有考虑间歇过程的多阶段特性及其划分;常玉清[9]等提出的基于多时段MPCA模型的间歇过程监测方法研究,依据PCA方法对间歇过程的多阶段进行划分,但该划分方法需要一定的先验知识的假设;王建林[10]等提出的基于SVDD的多时段间歇过程故障检测,利用时间片数据样本集构建的SVDD超球体半径值与支持向量个数的变化划分间歇过程的多时段,不需要假设过程数据服从正态分布及变量间线性相关,同时实现了多时段间歇过程的时段划分和故障检测,但在面对数据量大、种类多的间歇过程,该方法建模速度较慢,易于过拟合.
近年来,随着现代工业系统呈现向大型化、复杂化方向发展,深度学习[11]在学术界和工业界发展迅速,在很多传统的识别任务上显著地提高了识别准确率,在故障诊断领域也有许多基于深度学习的模型[12],包括深度置信网络(deep belief network,DBN)[13]、卷积神经网络(convolutional neural network,CNN)[14]、自动编码器(auto encoders,AE)[15]、递归神经网络(recurrent neural network,RNN)[16]等.
对于间歇过程的故障诊断,本文提出了一种非线性特征的提取方法,即一维卷积自动编码器(one-dimensional convolutional auto encoders,1DC-AE),该方法基于AE方法,不需要对原始数据进行假设,采用自适应、非线性、多层编码的方式将高维原始数据转换成低维数据,并针对间歇过程的特性加入一维卷积和反卷积网络层,可以自动识别并提取具有多阶段特性的过程数据特征,然后在网络提取到的特征上建立高斯混合模型(Gaussian mixture model,GMM).近年来GMM在过程监控领域得到了广泛的应用[17-18],而在低维空间中建立GMM可以极大缩短建模时间,这里采用期望最大化(expectation maximization,EM)算法进行建模,能得到较为精确的高斯混合模型.最后结合马氏距离[19]提出全局概率检测指标,实现间歇过程故障检测.
1 间歇过程数据处理 1.1 数据等长化处理间歇过程的数据往往有批次、时间和变量三个维度的信息,其数据特征复杂,在实际生产过程中无法达到完全的重复生产,使得间歇过程产生批次长度不完全等长、采样步长不完全等长、采样进程易发生偏移等现象[1].为了配合卷积自动编码器进行降维,首先要处理批次数据不完全等长问题.
针对不完全等长问题,本文采用“最短长度法”[1]对不等长数据进行等长处理,具体为:在所有的批次中找到最短的一批数据,然后以这批数据作为标准,将其他批次的数据的相应区间进行截取,即使得所有批次具有等长数据.
1.2 数据按批次展开及缩放处理设一批等长数据X的批次总数为I,每批的采样数为J,变量数为K,则按批次展开的方式[1, 9-10]如图 1所示,将三维数据(J×K×I)按批次方向展开为二维矩阵(JK×I).

|
| 图 1 按批次方向展开 Fig.1 Batch-wise unfolded |
其中,展开后的矩阵每一列即为一批数据,最终得到训练数据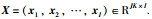
与主成分分析(principal component analysis,PCA)不同,自编码网络使用了非线性激活函数来进行非线性转换,如sigmoid函数或tanh函数等非线性函数,为了使自编码网络可以提取特征并重构数据,需要对原始数据进行缩放,否则自编码网络将无法以非线性的方式重构数据.以tanh激活函数为例:
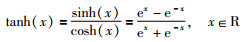
|
(1) |
tanh是双曲正切函数,其输出区间为[-1, 1],因此需要数据展开后对其进行缩放处理.具体方法为:
1) 对于训练数据X的每一列xi中的每一个元素xik(k=1,2,…,JK),采用如下的标准化处理,使数据处在[0, 1]区间.
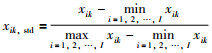
|
(2) |
其中,xik,std是标准化处理后的数据.
2) 对于每一个xik,std,按如下方式缩放到[-1, 1]区间.
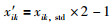
|
(3) |
其中,x′ik是最终缩放处理后的数据.
在线检测阶段将采用训练数据的最大最小值来对测试数据进行缩放处理.除了适应自编码网络,处理后的数据实际上是缩放了间歇过程正常操作下过程变量的平均运行轨迹,在一定程度上降低了变量轨迹中的非线性和动态特性(如进程漂移)对建模的影响,并突出了间歇过程不同操作批次之间的变化信息.
2 卷积自动编码器和高斯混合模型 2.1 自动编码器(AE)及一维卷积(1DC)深层自编码器的基本结构[20]如图 2所示,包括编码和解码两个过程.

|
| 图 2 深层自编码器网络结构 Fig.2 Network structure of deep auto-encoders |
对于高维的原始数据集,编码网络可通过特殊变换找到一组低维数据集,而解码网络属于重构部分,可视为编码网络的逆过程,可将低维数据重构为高维数据.
一般多层自编码器的工作原理如下:采用全连接神经网络的方式构造,首先用限制玻尔兹曼机(restricted Boltzmann machine,RBM)[11]初始化编码和解码中的权值,然后按照原始数据和重构数据之间误差最小化的原则对自编码网络进行训练,如采用均分误差损失函数以及反向传播误差导数的链式法则很容易取得各个权重的梯度值,也可按照堆叠编码器(stacked auto encoder,SAE)[11, 23]的方式进行训练,进而将自编码网络的权值训练到最佳值,本文将采用SAE的逐层预训练方式.
对于间歇过程,每一批次的样本数据由多个采样时刻的信息拼接而成,而AE采用全连接网络的方式提取特征则是不合理的,它默认把每个样本点认为一个时刻,并忽略了数据间的多时段特性,而无法提取到不同采样时刻之间的变化信息及变量的动态特性.因而本文在AE的第一层和最后一层分别加入了一维卷积层和反卷积层,以刻画数据的多时段特性,如图 3所示.

|
| 图 3 一维卷积层(1DC)及反卷积层结构图 Fig.3 Structure of one dimensional convolution and deconvolution layers |
在一维卷积层中,首先将一批预处理数据(JK×1)重新排列为二维数据(J×K),在局部感受域(local receptive field)范围内构造全连接神经网络,形成一个卷积核(convolution kernel),每个局部感受域可以有多个卷积核,之后每隔一定的卷积步长选取一次局部感受域,并构造同样数目的卷积核,以此类推,所有卷积核之间的权值均不共享.如图 3(a)所示,建立了一个局部感受域长度(卷积核的时域窗长度)为3、卷积核数目为2、卷积步长(strides)为2的一维卷积层,为保证自编码网络的重构数据与原始数据维数相同,之后建立的反卷积层应与卷积层对称,即如图 3(b)所示.
有了局部感受域,自编码网络想要更少损失的建立重构数据,就需要学习间歇过程数据中时间序列之间的变化信息,最终形成的一维卷积自动编码器(1DC-AE)网络和数据训练流程图如图 4所示.

|
| 图 4 一维卷积自动编码器的结构与数据训练流程 Fig.4 Structure and data training process of one-dimensional convolution auto-encoder |
采用该网络得到的降维数据进行建模不仅可以大大减少了计算量,而且网络不用假设原始数据的分布形式,充分考虑了间歇过程数据间的多时段特性,能有效提高特征提取的精确性.
2.2 高斯混合模型(GMM)复杂间歇过程往往具有多工况、多阶段特性,而采用高斯混合模型进行建模可以较好地模拟数据分布,并已成功应用到工业过程中的数据分类及故障检测[17-19].
假设按批次展开的间歇过程数据经过1DC-AE网络得到N批m维数据xn∈Rm,n=1,2,3,…,N,则GMM的概率密度函数将由下式表示:
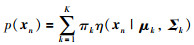
|
(4) |
其中,p为概率密度函数,K是高斯模型的数目,πk是第k类高斯模型的权重,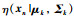
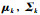
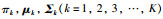
期望步(E-step),根据初始值或上一次迭代所得参数值来计算出隐性变量的后验概率(即隐性变量的期望),作为隐性变量的现估计值:
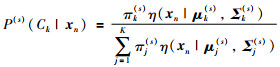
|
(5) |
P表示概率,Ck表示属于第k类高斯模型,P(s)(Ck|xn)表示在第s步迭代中,训练数据xn属于第k类高斯模型的后验概率.
最大化步(M-step),将似然函数最大化以获得新的参数值:
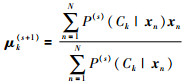
|
(6) |
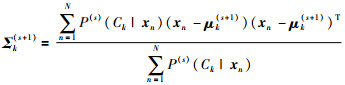
|
(7) |
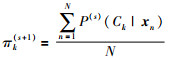
|
(8) |
式中(s+1)表示第s+1步迭代中相应的参数更新.最终检查参数或对数似然函数是否收敛,若不收敛则返回期望步继续迭代.
3 基于1DC-AE-GMM的故障检测方法 3.1 全局检测概率指标在使用训练数据建立起高斯混合模型之后,需要对新批次进行故障检测.由于整个高斯混合模型包括不同阶段和多个高斯成分,使用单一模型的监控指标进行检测不合适,因此需要全局监控概率指标[21].
假设经过卷积自编码网络降维后的测试样本为xtest∈Rm,第k类高斯模型的均值向量和协方差矩阵分别为μk,Σk,则该样本点到该高斯模型的马氏距离为
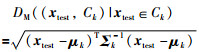
|
(9) |
由于DM2近似服从卡方分布,即DM2~χ2(m),可以得到测试样本与每个高斯成分的局部概率指标:
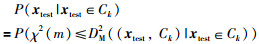
|
(10) |
而每个测试样本属于第k个高斯成分的后验概率根据贝叶斯公式得:
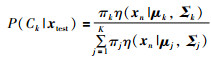
|
(11) |
最终得到作为检测的全局概率指标:
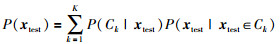
|
(12) |
可根据α=0.05的显著性水平判断,如果P(xtest)>0.95,则表明测试样本为故障样本.
3.2 基于1DC-AE-GMM的故障检测基于1DC-AE-GMM的间歇过程故障检测主要包括离线建模和在线检测两个部分.
离线建模:
1) 采集间歇过程中的正常历史数据并用第1节所述方法进行等长化处理得到一批训练数据X,同时对其进行按批次展开及缩放处理.
2) 根据图 4(a)搭建并初始化1DC-AE网络,用训练数据X训练该网络,训练完成后通过网络的中间编码层输出得到降维数据.
3) 在降维数据上建立如式(4)所示的高斯混合模型并进行训练,首先设定高斯模型数目为K,并通过EM算法即式(5)~(8)的不断迭代,得到高斯混合模型的最优模型参数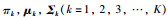
在线检测:
1) 对于测试数据和新的采样点,首先采用和正常历史数据相同的预处理方法(等长化处理、按批次展开及缩放).
2) 通过离线建模阶段训练好的1DC-AE网络进行特征提取和降维,得到测试样本xtest.
3) 采用离线建模阶段训练好的GMM模型,并利用式(9)~(12)计算xtest的全局检测概率指标,如果P(xtest)>0.95,则表明测试样本为故障样本.
本文故障检测方法的计算量主要集中在离线建模阶段,而在线检测时均为简单的线性计算,对于一般的工业过程来说完全可以保证在线监控的实时性.
4 仿真实验 4.1 半导体蚀刻工艺半导体蚀刻工艺是半导体制造过程中一个非常重要的环节,需要在不同的工况条件下运行,是一个典型的非线性、多时段和多工况的间歇过程.该实验在Lam9600等离子体蚀刻工具上进行堆叠蚀刻,目的是用一种电感耦合的Bl3/Cl2等离子体蚀刻TiN/A1-0.5% Cu/TiN/oxide堆叠.该实验所用的金属蚀刻机配备有三种传感器系统:设备状态(machine state)、射频监视器(radiofrequency monitors)和光发射光谱仪(optical emission spectroscopy),关于该过程的详细描述见文[22].设备状态传感器在晶片处理期间收集设备数据,包括40个过程设定点,在蚀刻过程中以1 s为间隔进行采样,如气体流量、腔室压力、射频功率等.在这过程中,使用了具有正常变化的19种非设定点过程变量进行监测,如表 1所示,并且实验表明这些变量将会影响到晶片最终的状态[22].本次实验将采用表一所示变量的数据进行.
| 编号 | 变量 |
| 1 | Flow |
| 2 | Flow |
| 3 | RF Btm Pwr |
| 4 | RF Btm Rfl Pwr |
| 5 | Endpt A |
| 6 | He Press |
| 7 | Pressure |
| 8 | RF Tuner |
| 9 | RF Load |
| 10 | RF Phase Error |
| 11 | RF Power |
| 12 | RF Impedance |
| 13 | TCP Tuner |
| 14 | TCP Phase Err |
| 15 | TCP Impedance |
| 16 | TCP Top Power |
| 17 | TCP Rfl Power |
| 18 | TCP Load |
| 19 | Vat Valve |
实验数据集采集于129个晶片,其中包括108个正常硅片和21个故障硅片,故障硅片是分别通过改变实验过程中的TCP功率、RF功率、室压、Cl2、Bl3流量或者He夹盘压力,使得21个硅片出现故障.其中正常晶片批次里第56号和故障晶片批次里第12号有大量数据缺失,所以舍去,即共有107批正常数据和20批故障数据.数据首先进行预处理,每批数据等长处理为85个采样时刻,并在正常数据里随机选出97批用于建模,得到Xtrain∈R97×1 445,其余的10批正常数据Xtest∈R10×1 445和20批故障数据Xfault∈R20×1 445用于测试模型故障检测能力.该过程变量5、7的变化如图 5所示,可见该过程工艺具有批次不等长、多个工况、进程轨迹漂移等复杂特性.

|
| 图 5 变量5、7变化轨迹 Fig.5 The change track of variables 5, 7 |
为了更好地说明本文所提方法的有效性,将与传统的MPCA-GMM模型[18]和不包含一维卷积层的AE-GMM模型进行比较,首先分别运用MPCA方法和1DC-AE模型将数据处理为二维,而MPCA模型中提取前两个主元PC1、PC2,卷积自动编码器的中间编码层设置为两个神经元x、y,取局部感受域长度(卷积核的时域窗长度)为5,卷积核数目为1,卷积步长为1,编码层不采用激活函数,其他层激活函数为tanh函数,网络除了卷积层外仅设置一层隐藏层. AE-GMM网络除了不包含卷积层,其它参数将与1DC-AE-GMM网络参数一致.
训练阶段,MPCA训练3 s即可完成,自编码网络视迭代次数不同总体训练时间不同,在GPU加速下每迭代训练一次约为500 μs.训练完成后,分别在三种模型提取到的特征数据上建立GMM模型,设定6个高斯成分,经过EM算法多次迭代后得出得聚类效果如图 6所示.

|
| 图 6 聚类效果 Fig.6 Clustering effect |
图中画圈部分为基于全局检测概率指标所表示的控制线,圈外即判断为故障点,数字代表故障批次.在本次实验中,MPCA-GMM模型将故障3、6、9、11、14判断为正常,AE-GMM模型将故障2、3、5、6、8、9、11、14、15、20判断为正常,而1DC-AE-GMM模型仅将故障7、11判断为正常,可见本次实验中本文方法的检测效果明显优于其它模型方法.
另外将10批正常测试数据Xtest分别对所建模型进行测试,检验模型处理正常数据的能力,详细的批次故障检测图如图 7所示.由图 7可以看出,本次实验AE-GMM模型对正常数据的检测率最低,将正常批次4、5、10判断为故障批次,而MPCA-GMM模型仅将正常批次9判断为故障批次,略优于1DC-AE-GMM模型.

|
| 图 7 三种模型的批次故障检测结果 Fig.7 Batch fault detection chart for three kinds of models |
由于自编码网络建模过程具有随机性,实验将进行多次并统计出三种模型对测试集的检测率,每次随机划分正常数据集和测试集并用于仿真实验,三种方法对正常和故障批次的检测结果如表 2所示.
| 数据集 | MPCA-GMM检测率/% | AE-GMM检测率/% | 1DC-AE-GMM检测率/% |
| 正常 | 86.3 | 68.9 | 82.9 |
| 故障1 | 100.0 | 69.5 | 100.0 |
| 故障2 | 100.0 | 23.1 | 100.0 |
| 故障3 | 10.5 | 31.4 | 52.6 |
| 故障4 | 100.0 | 100.0 | 100.0 |
| 故障5 | 100.0 | 3.2 | 98.4 |
| 故障6 | 0.0 | 4.2 | 100.0 |
| 故障7 | 100.0 | 63.2 | 97.9 |
| 故障8 | 100.0 | 85.1 | 97.4 |
| 故障9 | 0.0 | 4.2 | 100.0 |
| 故障10 | 100.0 | 63.8 | 100.0 |
| 故障11 | 0.0 | 32.1 | 42.1 |
| 故障12 | 100.0 | 92.1 | 100.0 |
| 故障13 | 100.0 | 89.6 | 100.0 |
| 故障14 | 42.1 | 44.5 | 58.4 |
| 故障15 | 100.0 | 84.5 | 100.0 |
| 故障16 | 100.0 | 100 | 100.0 |
| 故障17 | 100.0 | 100 | 100.0 |
| 故障18 | 100.0 | 100 | 100.0 |
| 故障19 | 100.0 | 100 | 100.0 |
| 故障20 | 100.0 | 74.5 | 96.7 |
由表 2得出,MPCA-GMM无法检测出故障6、9、11,对故障3、14的检测率较低. AE-GMM模型整体的故障检测率明显低于其它两种模型,说明全连接形式的自编码网络无法较好地学习具有多时段特性的数据,而1DC-AE-GMM方法加入一维卷积和反卷积层可以强迫AE网络在得到已随机分段的过程数据的情况下尽可能地重构原始数据,从而有效地提取间歇过程数据的特征.本文方法可以完全检测故障6、9,而且对故障3、11、14有较高检测率,对正常数据的检测率略低于MPCA-GMM模型,这对于工业过程的故障检测损失不大,总体而言,该方法具有较好的优势.另一方面,自编码网络训练时间要比MPCA方法长,与训练迭代次数和网络复杂度有关,但训练完成后参数固定,其在线检测过程与MPCA模型比较均可在短时间内完成检测,显示了该网络方法的优越性.
5 结论本文提出一种针对间歇过程的非线性和自适应时段的特殊特征提取方法,并结合高斯混合模型引入全局概率检测指标进行故障检测.最后将1DC-AE-GMM方法应用于一类半导体蚀刻工艺中进行故障检测,与AE-GMM方法比较得出,其故障检测率明显优于不加卷积和反卷积层的AE网络模型;同时与传统的MPCA-GMM比较得出,本文方法在快速建模和检测的同时有效地提高了检测准确率.此外实验发现自编码网络的训练过程具有很大的随机性,导致一些故障不能百分之百地检测出来,但作为一类人工智能模型,自编码网络可以加入有监督训练环节[11],在得知某个新样本为故障而又无法检测时,可以通过有监督学习该故障样本的特性并记住该类故障,这是传统的MPCA模型无法做到的.
| [1] |
赵春晖, 王福利, 姚远, 等.
基于时段的间歇过程统计建模、在线监测及质量预报[J]. 自动化学报, 2010, 36(3): 366–374.
Zhao C H, Wang F L, Yao Y, et al. Phase-based statistical modeling, online monitoring and quality prediction for batch processes[J]. Acta Automatica Sinica, 2010, 36(3): 366–374. |
| [2] | Ge Z Q. Review on data-driven modeling and monitoring for plant-wide industrial processes[J]. Chemometrics & Intelligent Laboratory Systems, 2017, 171: 16–25. |
| [3] | Zhu J, Ge Z, Song Z. Distributed parallel PCA for modeling and monitoring of large-scale plant-wide processes with big data[J]. IEEE Transactions on Industrial Informatics, 2017, 13(4): 1877–1885. DOI:10.1109/TII.2017.2658732 |
| [4] |
叶晓丰, 王培良, 杨泽宇.
基于混合MPLS的多阶段过程质量预报方法[J]. 山东大学学报(工学版), 2017, 47(5): 246–253.
Ye X F, Wang P L, Yang Z Y. Quality prediction method based on hybrid MPLS for multiphases process[J]. Journal of Shandong University (Engineering Science), 2017, 47(5): 246–253. |
| [5] | Hung H, Wu P, Tu I, et al. On multilinear principal component analysis of order-two tensors[J]. Biometrika, 2012, 99(3): 569–583. DOI:10.1093/biomet/ass019 |
| [6] | Wang J, He Q P, Qin S J, et al. Recursive least squares estimation for run-to-run control with metrology delay and its application to STI etch process[J]. IEEE Transactions on Semiconductor Manufacturing, 2005, 18(2): 309–319. DOI:10.1109/TSM.2005.846819 |
| [7] | Yu J. Fault detection using principal components-based Gaussian mixture model for semiconductor manufacturing processes[J]. IEEE Transactions on Semiconductor Manufacturing, 2011, 24(3): 432–444. DOI:10.1109/TSM.2011.2154850 |
| [8] | Zhu J, Ge Z, Song Z. Distributed parallel PCA for modeling and monitoring of large-scale plant-wide processes with big data[J]. IEEE Transactions on Industrial Informatics, 2017, 13(4): 1877–1885. DOI:10.1109/TII.2017.2658732 |
| [9] |
常玉清, 王姝, 谭帅, 等.
基于多时段MPCA模型的间歇过程监测方法研究[J]. 自动化学报, 2010, 36(9): 1312–1320.
Chang Y Q, Wang Z, Tan S, et al. Research on multistage-based MPCA modeling and monitoring method for batch processes[J]. Acta Automatica Sinica, 2010, 36(9): 1312–1320. |
| [10] |
王建林, 马琳钰, 邱科鹏, 等.
基于SVDD的多时段间歇过程故障检测[J]. 仪器仪表学报, 2017, 38(11): 2752–2761.
Wang J L, Ma L Y, Qiu K P, et al. Multi-phase batch processes fault detection based on support vector data description[J]. Chinese Journal of Scientific Instrument, 2017, 38(11): 2752–2761. DOI:10.3969/j.issn.0254-3087.2017.11.017 |
| [11] | Hinton G E, Salakhutdinov R R. Reducing the dimensionality of data with neural networks[J]. Science, 2006, 313(5786): 504–507. DOI:10.1126/science.1127647 |
| [12] |
任浩, 屈剑锋, 柴毅, 等.
深度学习在故障诊断领域中的研究现状与挑战[J]. 控制与决策, 2017, 32(8): 1345–1358.
Ren H, Qu J F, Chai Y, et al. Deep learning for fault diagnosis:The state of the art and challenge[J]. Control and Decision, 2017, 32(8): 1345–1358. |
| [13] | Wu S, Zhang L, Zheng W, et al. A DBN-based risk assessment model for prediction and diagnosis of offshore drilling incidents[J]. Journal of Natural Gas Science and Engineering, 2016, 34: 139–158. DOI:10.1016/j.jngse.2016.06.054 |
| [14] | Sun J, Xiao Z, Xie Y. Automatic multi-fault recognition in TFDS based on convolutional neural network[J]. Neurocomputing, 2017, 222: 127–136. DOI:10.1016/j.neucom.2016.10.018 |
| [15] | Lu C, Wang Z Y, Qin W L, et al. Fault diagnosis of rotary machinery components using a stacked denoising autoencoder-based health state identification[J]. Signal Processing, 2017, 130: 377–388. DOI:10.1016/j.sigpro.2016.07.028 |
| [16] | Tim D B, Kim V, Robert B. Railway track circuit fault diagnosis using recurrent neural networks[J]. IEEE Transactions on Neural Networks and Learning Systems, 2017, 28(3): 523–533. DOI:10.1109/TNNLS.2016.2551940 |
| [17] | Yu J, Qin S J. Multiway Gaussian mixture model based multiphase batch process monitoring[J]. Industrial and Engineering Chemistry Research, 2009, 48(18): 8585–8594. DOI:10.1021/ie900479g |
| [18] |
王静, 胡益, 侍洪波.
基于GMM的间歇过程故障检测[J]. 自动化学报, 2015, 41(5): 899–905.
Wang J, Hu Y, Shi H B. Fault detection for batch processes based on Gaussian mixture model[J]. Acta Automatica Sinica, 2015, 41(5): 899–905. |
| [19] |
张成, 李秀玉, 逄玉俊, 等.
基于GMM的马氏距离kNN故障检测方法研究[J]. 测控技术, 2014, 33(9): 13–17.
Zhang C, Li X Y, Pang Y J, et al. Mahalanobis distance kNN fault detection method based on gaussian mixture model[J]. Measurement & Control Technology, 2014, 33(9): 13–17. DOI:10.3969/j.issn.1000-8829.2014.09.004 |
| [20] |
胡昭华, 宋耀良.
基于Autoencoder网络的数据降维和重构[J]. 电子与信息学报, 2009, 31(5): 1189–1192.
Hu Z H, Song Y L. Dimensionality reduction and reconstruction of data based on autoencoder network[J]. Journal of Electronics & Information Technology, 2009, 31(5): 1189–1192. |
| [21] | Xie X, Shi H. Dynamic multimode process modeling and monitoring using adaptive Gaussian mixture models[J]. Industrial & Engineering Chemistry Research, 2012, 51(15): 5497–5505. |
| [22] | Wise B M, Gallagher N B, Butler S W, et al. A comparison of principal component analysis, multiway principal component analysis, trilinear decomposition and parallel factor analysis for fault detection in a semiconductor etch process[J]. Journal of Chemometrics, 1999, 13(3/4): 379–396. |