



0 引言
随着技术发展和应用需求的推动,人类已迈进大数据时代.数据从被动产生、主动产生逐渐过渡到自动产生,并以数据流的形式呈现,如社交网络、网络监控和金融领域等.众所周知,数据流中隐藏大量有价值的信息,如何从中分析挖掘出这些信息来辅助决策是十分重要.目前,在大数据环境进行数据分类挖掘研究已取得较多研究成果,但仍然面临许多挑战和亟待解决的问题[1].如在具有概念漂移的数据流环境中,新概念产生的初期阶段,标签样本数量不足,如何有效利用历史标签样本辅助实施监督学习以提高模型准确率,成为无法回避的问题.
按处理模式,数据流分类处理可分为流处理和批处理[2].其中,流处理[3-4]是一种在线处理方式,不需要对样本进行大量缓存;而批处理是先缓存适量样本再进行分析,适合于时效性要求不高但注重分类准确性的场合. Sun等[5]针对数据流中概念出现和概念消失场景,提出了一种基于类概念在线集成办法,能够迅速适应概念变化,并且采用欠采样的方法解决了不平衡现象.文[6]针对进化关联数据流中样本数多和未标注问题提出一种模糊在线分类方法,较好地解决数据流分类问题.文益民等[7]结合迁移学习实现一种在线迁移方案,解决数据流中概念重现问题,并且克服了负迁移现象.文[8]基于人类的“回忆和遗忘”认知机理实现集成式数据流挖掘模型,该模型通过批处理,按照记忆强度来选择基分类器进行集成预测,解决数据流分类问题.文[9]通过当前分类器对新样本预测结果的不确定性,来表征概念是否发生漂移,据此选择新概念样本进行增量学习.在文[10]中利用单类支持向量机构建增量学习模型,解决数据流单类学习问题,对于处理异常点、噪声、新类别出现或不平衡环境具有较好的效果.为提高数据流分类挖掘效率,文[11]提出基于参数间隔孪生支持向量机增量学习算法,利用违背广义KKT条件样本参与训练,在保证精度同时提高了训练效率.文[12]通过信息熵来检测相邻窗口概念变化,在此基础上按批处理学习新分类模型解决数据流中的概念变化,并通过缓存历史分类器解决了概念重现问题.
综上可知,数据流批处理方法大多是以增量学习为原型,其基本策略是以历史样本为参照,不断融合新样本更新分类模型.在具有概念漂移的数据流环境中,通过增量学习方式所获得的分类模型在概念表示上具有滞后性,难以获得较好的泛化能力.因此本文将逆向考虑以当前数据集为参考,保证及时跟踪数据流中的概念变化,同时利用历史样本进行迁移解决新概念样本标注数量不足问题.
1 预备知识 1.1 面向数据流的迁移学习模型迁移学习[13]是利用源领域中有用信息对不同但相关的目标领域进行求解的一种机器学习方法,在情感分类、推荐系统等领域中得到了广泛应用,可以解决目标领域中标注样本数量不足问题[14-16].
传统的迁移学习场景假设源领域和目标领域均已存在,与数据流分类场景有所区别.本文将结合迁移学习方法和数据流分类实际场景,构建出迁移学习源领域和目标领域.本文约定:数据流中已处理过的历史样本构成的源领域为Ds={(xis,yis),i=1,2,…,ns},当前未处理的样本构成目标域为Dt={(xit,yit),i=1,2,…,nt},其中xis、xit分别表示源领域和目标域样本,yis、yit分别对应源领域和目标领域中样本的类别,样本个数ns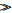
在基于实例迁移的学习框架中,如何选择最有益的迁移样本是关键.根据聚类思想可知,同类样本互相紧邻,异类样本互相远离.基于此,本文的选择标准是从源领域中选择出目标域的近邻样本作为迁移对象.为防止伪近邻(即一种非对称的邻居关系)迁移而导致负迁移出现,本文通过互近邻来保证近邻的真实性,提高迁移的质量,同时降低迁移时计算复杂性.
设数据集d={(xi,yi),i=1,2,…,n},其中xi表示样本,yi表示样本类别信息.
定义1 (k近邻)数据集d中与样本x距离最近的k个样本所构成的样本子集,记Nk(x).
定义2 (k互近邻)数据集d中样本xi∈Nk(xj)和xj∈Nk(xi)同时成立,则称样本xi、xj为k互近邻.
定义3 (互近邻集)数据集d中与样本x构成k互近邻关系的样本集,记Mk(x),Mk(x)={ xi∈d| xi∈Nk(x)∩ x ∈Nk(xi)}.
根据上述定义可获得相应的结论,为本文算法关于近邻求解降低复杂性、保证近邻的真实性和完备性提供理论保证.
性质1 样本x的互近邻样本一定是其k近邻样本,即Mk(x)⊆Nk(x).
证明 根据互近邻集的定义(定义3)可知,性质1中的集合包含关系是成立的.
性质1保证了本文模型通过求近邻样本来获得互近邻样本是完备的,不会丢失有益的目标样本信息.
性质2 样本x的k互近邻个数不超过k近邻个数,即|Mk(x)|⊇|Nk(x)|.
证明 由定义和性质1可知,样本x的近邻集合中含k个样本,而互近邻集合中样本个数不超过k,所以性质2中的不等式成立.
性质2保证了在迁移过程中,其迁移样本个数比近邻方式的样本个数要少,降低训练样本的复杂性,提高执行效率.
推论1 样本x与其互近邻中的所有样本满足互为k近邻关系.
推论1可由性质1直接可得.推论1保证通过互近邻求解求得样本互为近邻关系,避免伪近邻样本出现.
2 基于实例迁移的数据流分类挖掘模型根据上述分析,可以利用互近邻思想来选择迁移对象,通过合并迁移样本和目标域样本重新训练分类模型,以提高模型的准确性.融合互近邻思想的基于实例迁移数据流分类算法(instance-based transfer data streams classification algorithm,IBDSC),如算法1所示.
| 算法1 基于实例迁移数据流分类算法 |
| 输入:互近邻参数、数据块大小 输出:预测准确率 |
| Step 1:缓存初始数据块d,并在数据块上进行训练获得分类模型cls=SVM_Train(d); Step 2:for数据块di,i=1,2,…,n; Step 3:a=SVM_Test(cls,di) //用cls在数据块di上进行预测,输出预测准确率a; Step 4:提取分类模型cls的支持向量集作为源域,数据块di作为目标域; Step 5:利用求近邻思路求出数据块di中的每个样本在源域中的k互近邻样本集合,构成迁移集ic; Step 6:di=di∪ic //合并数据块di和迁移集ic; Step 7:在进行实例迁移过后的数据块di上进行训练获得新的分类模型cls=SVM_Train(di). |
在算法1中函数SVM_Train(·)表示在训练集上训练获得分类模型,函数SVM_Test(·)表示用分类模型在数据块上进行预测并返回预测准确率值. Step 3是对当前数据块di进行预测并输出准确率,检验分类模型在概念漂移环境中对概念变化的自适应能力;Step 4是利用当前分类模型的支持向量构建迁移学习框架源领域,当前待处理的数据块作为目标领域,为迁移学习作好数据准备;Step 5是根据互近邻的性质和推论从源域中选择迁移样本,构成迁移样本集.最后在新的训练样本集中训练新分类模型,以便模型能够自适应新概念,提高分类的准确性.
3 仿真实验为验证所提的融合互近邻思想进行实例迁移的数据流分类算法(IBDSC)模型的可行性,在公开数据流仿真数据集上进行验证,并与传统分类算法进行实验比较.
3.1 数据集实验数据集源自大型数据流分析仿真平台MOA[17],该平台是当前进行数据流分类挖掘仿真数据主要来源,已有较多的研究成果[18].本文的实验数据是该平台中的移动超平面数据集[19],可以用来模拟概念漂移中的缓漂移现象,通过调节参数构建不同漂移程度和噪声比的数据集.在m维超平面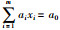
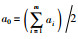
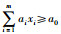
仿真实验环境在Matlab 2014a和Libsvm 3.2.2[20]软件完成.实验环节模拟批处理学习模式,把整个数据集分成若干大小固定的数据块,按照先测试后训练的方案进行.用支持向量机作为机器学习算法,相关参数采用默认值,数据块大小设置成100.由于数据流中概念漂移现象存在,通过更新分类模型要求能够及时反映数据流中的概念,因此记录实验中数据块系列的平均准确率和标准差进行分析,其中,平均准确率可以反映出算法的好坏,标准差可以反映出分类模型对概念漂移的适应性.
实验1 验证IBDSC算法的可行性.
首先测试算法在无噪声数据集h1上的性能,并验证不同的k值对算法执行的影响,实验记录的平均准确率和标准差值如表 1所示.
| 实验结果 | k=5 | k=10 | k=15 | k=20 |
| 平均准确率 | 0.918 | 0.924 | 0.923 | 0.921 |
| 标准差 | 0.039 1 | 0.039 | 0.041 | 0.041 7 |
对表 1中的实验结果统计值分析可知,平均准确率超过91%,标准差值约为0. 03.数据表明,本文所提融合互近邻思想实现的迁移学习模型具有较好的学习能力,能够及时反映出数据流中不断发生的概念变化,具有自适应能力.数据流中概念缓漂移特性是相邻数据块具有较高概率拥有相近或相同的概念,因此基于当前最新数据块进行迁移学习的方法可以提高分类模型在相邻样本上泛化能力.
由表 1可得,增加k值对于提高分类模型的准确率影响不大,表明本文所提的互近邻思想能够把真正的近邻样本找到,这些样本有助于分类模型的训练学习.随k值的增大,平均准确率略有降低,标准差反而逐渐增大,说明增加近邻数能够把相距较远的样本误认为是真邻居进行迁移,从而导致负迁移现象产生.通过观察实验过程中分类模型的支持向量变化发现,随着k值增加,支持向量个数将急剧增加.支持向量个数平均值及标准差变化趋势如图 1所示.

|
| 图 1 不同k值支持的向量个数 Fig.1 The number of support vector for different k |
由图 1变化曲线可知,k值增加导致支持向量个数增加,将增加分类模型的计算量.同时支持向量个数标准差也增加,说明提高k值会引入一些无效或作用不大的近邻样本.这导致分类模型在概念表示时波动较大、具有滞后性,无法及时地反映概念变化,这与表 1中的准确率标准差值变化相吻合.这种变化也说明在迁移学习过程中应该关注迁移的样本是真近邻样本,应避免伪近邻样本的影响.
实验2 验证本文算法的优势.
为说明数据流环境中进行迁移学习的必要性,将本文算法(IBDSC)与传统的数据流监督式学习方法(记TrSupL)进行比较.传统监督式数据流学习方法是在当前数据块上训练分类模型,在相邻后序数据块上进行测试,并记录平均准确率值.基于实验1的结果分析,本轮对比实验中参数k值为5,数据块大小取100,用支持向量机作为学习器,均采用默认的参数设置.
图 2描述了两种实验方案在4个数据集上的平均准确率的曲线情形. 图 2曲线很清晰地反映出基于实例迁移的数据流分类方案在无噪声(横坐标h1)和噪声环境(横坐标h2、h3和h4)中相比传统的分类方法优势明显.实验表明在标注样本数量不足的数据流分类环境中,可以通过迁移机制解决数据流中出现的概念漂移和噪声问题.同时也说明传统的监督学习方法在标注样本数量不足时,无法有效解决学习问题,对于数据流中的概念漂移现象更是难以解决.随着噪声增加,在数据集h2、h3和h4上两种方法的准确率均降低,图 2中曲线间距离也越来越大,说明基于迁移学习的数据流分类方法更具优势,在噪声环境中健壮性更好.

|
| 图 2 IBDSC与传统监督学习方法对比 Fig.2 Comparison between IBDSC and the traditional supervised learning method |
为解决数据流分类面临的概念漂移和样本标注问题,增量学习也成为有效解决途径之一,因此本文同文[8]中所提出的基于样本不确定性的增量学习方案进行对比.
在无噪声数据集h1上,基于样本不确定性的增量学习方案分类准确率平均值仅达到84. 3%,均低于表 1中4种不同k值情况下的平均准确率.而且基于样本不确定性的增量学习方案在无噪声数据集h1上标准差值为0. 176 7,远高于本文方案的0. 03,这也说明基于互近邻思想的样本迁移数据流分类方法具有更好的健壮性,更能适应概念的变化.在噪声数据集h2上平均准确率仅64. 8%,标准差达到0. 306,说明本文所提的方案更具优势.随着噪声增加,在数据集h3、h4上平均准确率和标准差表现更差.究其原因在于两种学习方案的学习基础差异导致的,增量学习方案是依赖于历史样本信息来选择新样本,其参考信息是历史信息,很明显概念漂移程度较强的数据流中历史样本信息是与当前样本信息是不相容的.而迁移学习是基于当前样本信息,从历史样本集中选择与当前样本最相近或相似的样本进行迁移学习,更能及时地反映出数据流中的概念变化,并且弥补标注样本数量不足问题.上述实验结果分析表明,迁移学习方案优势明显.
4 结论数据流中数据获取环境和概念漂移等因素的影响,导致数据流分类过程中无法获得足够多的标注样本(代表新概念)进行监督学习.本文结合迁移学习方法,利用大量的历史标注样本来辅助当前新概念的模型学习,解决了代表新概念标注样本数量不足的问题.为避免迁移学习过程中发生负迁移,提出互近邻的思想挖掘历史样本集中有价值的样本实施迁移,结果证实本文的方法是可行的.下一步将拓展应用范围,予以解决数据流中的概念突变性和周期性等问题.
| [1] |
何文韬, 邵诚.
工业大数据分析技术的发展及其面临的挑战[J]. 信息与控制, 2018, 47(4): 398–410.
He W T, Shao C. The development and challenges of industrial big data analysis technology[J]. Information and Control, 2018, 47(4): 398–410. |
| [2] |
孙大为, 张广艳, 郑纬民.
大数据流式计算:关键技术及系统实例[J]. 软件学报, 2014, 25(4): 839–862.
Sun D W, Zhang G Y, Zheng W M. Big data stream computing:Technologies and instances[J]. Journal of Software, 2014, 25(4): 839–862. |
| [3] | Zhou Z Z, Zheng W S, Hu J F, et al. One-pass online learning:A local approach[J]. Pattern Recognition, 2016, 51: 346–357. DOI:10.1016/j.patcog.2015.09.003 |
| [4] |
吕艳霞, 王翠容, 王聪, 等.
一种基于数据不确定性的概念漂移数据流分类算法[J]. 应用科学学报, 2017, 35(5): 559–569.
Lü Y X, Wang C R, Wang C, et al. Data stream classification with data uncertainty and concept drift[J]. Journal of Applied Sciences, 2017, 35(5): 559–569. DOI:10.3969/j.issn.0255-8297.2017.05.003 |
| [5] | Sun Y, Tang K, Minku L, et al. Online ensemble learning of data streams with gradually evolved classes[J]. IEEE Transactions on Knowledge and Data Engineering, 2016, 28(6): 1532–1545. DOI:10.1109/TKDE.69 |
| [6] | Sancho-Asensio A, Orriols-Puig A, Casillas J. Evolving association streams[J]. Information Sciences, 2016, 334-335: 250–272. DOI:10.1016/j.ins.2015.11.043 |
| [7] |
文益民, 唐诗淇, 冯超, 等.
基于在线迁移学习的重现概念数据流分类[J]. 计算机研究与发展, 2016, 53(8): 1781–1791.
Wen Y M, Tang S Q, Feng C, et al. Online transfer learning for mining recurring concept in data stream classification[J]. Journal of Computer Research and Development, 2016, 53(8): 1781–1791. |
| [8] |
赵强利, 蒋艳凰, 卢宇彤.
具有回忆和遗忘机的数据流挖掘模型与算法[J]. 软件学报, 2015, 26(10): 2567–2580.
Zhao Q L, Jiang Y H, Lu Y T. Ensemble model and algorithm with recalling and forgetting mechanisms for data stream mining[J]. Journal of Software, 2015, 26(10): 2567–2580. |
| [9] |
刘三民, 孙知信, 刘涛.
基于样本不确定性的增量式数据流分类研究[J]. 小型微型计算机系统, 2015, 36(2): 193–196.
Liu S M, Sun Z X, Liu T. Research of incremental data stream classification based on sample uncertainty[J]. Journal of Chinese Computer Systems, 2015, 36(2): 193–196. DOI:10.3969/j.issn.1000-1220.2015.02.001 |
| [10] | Bartosz K, Michal W. Incremental weighted one-class classifier for mining stationary data streams[J]. Journal of Computational Science, 2015, 9: 19–25. DOI:10.1016/j.jocs.2015.04.024 |
| [11] |
杨海涛, 肖军, 王佩瑶, 等.
基于参数间隔孪生支持向量机的增量学习算法[J]. 信息与控制, 2016, 45(4): 432–436.
Yang H T, Xiao J, Wang P Y, et al. Incremental learning method based on twin parametric-margin support vector machine[J]. Information and Control, 2016, 45(4): 432–436. |
| [12] |
孙艳歌, 王志海, 原继东, 等.
基于信息熵的数据流自适应集成分类算法[J]. 中国科学技术大学学报, 2017, 47(7): 575–582.
Sun Y G, Wang Z H, Yuan J D, et al. Adaptive ensemble classification algorithm for data streams based on information entropy[J]. Journal of University of Science and Technology of China, 2017, 47(7): 575–582. DOI:10.3969/j.issn.0253-2778.2017.07.005 |
| [13] | Weiss K, Taghi M K, Wang D D. A survey of transfer learning[J]. Journal of Big Data, 2016, 3(9): 1–40. |
| [14] | Aghamaleki J A, Baharlou S M. Transfer learning approach for classification and noise reduction on noisy web data[J]. Expert Systems with Applications, 2018, 105: 221–232. DOI:10.1016/j.eswa.2018.03.042 |
| [15] |
舒醒, 于慧敏, 郑伟伟, 等.
基于边际Fisher准则和迁移学习的小样本集分类器设计算法[J]. 自动化学报, 2016, 42(9): 1313–1321.
Shu X, Yu H M, Zheng W W, et al. Classifier-designing algorithm on a small dataset based on margin Fisher criterion and transfer learning[J]. Acta Automatica Sinica, 2016, 42(9): 1313–1321. |
| [16] |
杭文龙, 蒋亦樟, 刘解放, 等.
迁移近邻传播聚类算法[J]. 软件学报, 2016, 27(11): 2796–2813.
Hang W L, Jiang Y Z, Liu J F, et al. Transfer affinity propagation clustering algorithm[J]. Journal of Software, 2016, 27(11): 2796–2813. |
| [17] | Holmes G, Kirkby R, Pfahringer B. MOA: Massive online analysis[EB/OL]. (2018-06-30)[2018-09-30]. http://sourceforge.net/projects/moa-datastream. |
| [18] | Dong F, Lu J, Zhang G Q, et al. Active fuzzy weighting ensemble for dealing with concept drift[J]. Journal of Computational Intelligence System, 2018, 11: 438–450. DOI:10.2991/ijcis.11.1.33 |
| [19] | Hulten G, Spencer L, Domingos P. Mining time-changing data streams[C]//Internation Conference on Knowledge Discovery and Data Mining. New York, NJ, USA: ACM, 2001: 97-106. |
| [20] | Chang C C, Lin C J. LIBSVM: A Library for support vector machines[EB/OL]. (2018-07-15)[2018-09-30]. https://www.csie.ntu.edu.tw/~cjlin/libsvm/. |