



2. 西安交通大学电子与信息学部自动化科学与工程学院, 陕西 西安 710049;
3. 青岛星跃铁塔有限公司, 山东 青岛 266300
2. School of Automation Science, Xi'an Jiaotong University, Xi'an 710049, China;
3. Qingdao Xingyue Iron Tower and Engineering Co., Ltd, Qingdao 266300, China
0 引言
基于内容的图像检索[1]方法一直以来都是计算机视觉领域的研究重点.基于手工设计特征的方法(如SIFT[2]、Fisher Vector[3]和VLAD[4])大多数都依赖于词袋模型(BoW[5]),虽然也能在图像检索方面取得不错的效果,但由于提取的图像特征维度过高,导致存储损耗较大、搜索效率较低.近年来,卷积神经网络(CNN[6-8])在计算机视觉领域获得了巨大的成功,与手工设计特征的方法相比,从卷积神经网络中获得的图像特征更具有区分性、可靠性和稳定性,甚至成为视觉识别领域的通用特征[9-10].
早期,基于卷积神经网络的图像检索模型获取全连接层的输出作为图像特征[6, 10].随后Liang[11]和Liu[12]等人证明,从最后一个卷积层提取的图像特征即深度卷积特征比全连接层更具有显著性.之后基于卷积神经网络的图像检索模型大多使用深度卷积特征,并取得了不错的检索效果(如R-MAC[13]、SpoC[14]、CroW[15]和SBA[16]). R-MAC对每个特征图使用滑动窗口来获取多个局部特征,并认为该局部特征具有区分性,再将获取的局部特征求和聚合为全局特征向量. SPoC假设最具有区分性的区域都位于图像的中心位置,并设计了空间高斯加权矩阵,对深度卷积特征进行加权,最后采用求和池化的聚合方法将图像特征聚合为紧凑的全局特征向量. CroW受SpoC和BoW模型启发,设计了空间加权矩阵和通道加权向量. SBA将数据集中图像的深度卷积特征聚合为全局特征向量,并按通道计算方差,选取方差最大的一些通道的特征图对深度卷积特征进行加权聚合.
图像显著性区域[17]特征为图像中最能表现图像内容区域的特征,由于上述方法仍然存在图像显著性区域特征不突出,噪声抑制不充分的问题,本文基于CroW提出了一种加权聚合深度卷积特征的图像检索方法.相较于CroW,本文设计了一种全新的空间加权和通道加权方法.在设计通道加权之前,先对图像的深度卷积特征进行简单加权;再根据逆文档频率,对拥有较少特征和紧密特征的特征图赋予较大通道权重,生成差异性加权向量.受SBA启发,本文在设计空间加权时,通过挑选显著性较高的一部分特征图进行求和,并对其进行滤波处理,得到选择滤波加权矩阵.本文所提方法以检索图像为目标,旨在实现“以图搜图”.
1 深度卷积特征聚合框架图像检索方法包括离线建库和在线检索两个过程.基于深度卷积特征的图像检索方法在离线建库和在线检索过程中,都需要将图像输入到预先训练好的卷积神经网络来提取图像的深度卷积特征,再使用合适的聚合方法将其聚合为全局特征向量.其中,聚合方法是基于深度卷积特征的图像检索方法的关键部分,也是本文研究的主要内容.本文使用的深度卷积特征聚合框架如表 1所示.
| 算法:深度卷积特征聚合框架 |
| 输入:深度卷积特征X,全局特征向量维数d,滤波器S,参数n,白化参数P. |
| 输出:K维的全局特征向量Tr∈RK |
| V=fV(X,S) //差异性加权向量 |
| F=fF(X,S,V,n) //选择滤波加权矩阵 |
| SXk=XkeF //空间加权 |
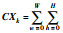 (SXkwh*Vk) //通道加权 (SXkwh*Vk) //通道加权 |
| Tr′=normalize (CX) //规范化 |
| Tr′=PCA (Tr′,P,d); //白化 |
| Tr=normalize (Tr′); //规范化 |
| Return Tr |
表 1中,深度卷积特征为三维张量X ∈R(K×W×H),其中K为特征图数量,W和H分别为特征图的宽和高.差异性加权向量V ∈RK和选择滤波加权矩阵F ∈R(W×H)分别通过差异性加权向量生成函数fV和选择滤波加权矩阵生成函数fF获得. S为滤波器,符号e表示两个矩阵相同位置元素进行相乘.
2 加权生成函数 2.1 差异性加权向量生成函数CroW[15]根据逆文档频率提出基于特征图稀疏性的通道加权策略来提高图像的检索精度.然而,特征图每个位置上的数值仅代表特征强度,且可能存在噪声.因此,CroW设计的通道权重并不能充分利用特征图信息,且存在放大噪声的问题.此外,在用于图像检索的卷积神经网络中,相同的卷积核通常会学习相同的图像语义并产生相应的深度卷积特征. SBA[16]将所有图像中,经过相同卷积核所产生的特征图进行比较,找出其中具有较大差异性的特征图进行加权.受此启发,本文认为同一个图像经过不同卷积核产生的特征图代表不同的语义信息,通过比较图像的所有特征图的聚合情况,认为聚合紧密的特征图存在容易被忽略的显著性区域特征,且该特征图存在噪声的可能性较小,因此应该赋予这些特征图较大的权重.
为了缓解空间加权引起的特征爆炸现象[18],对深度卷积特征X进行简单滤波空间加权,加权后的卷积特征X ′为
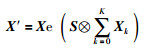
|
(1) |
其中,S为滤波器,定义符号⊗表示使用滤波器进行滤波操作.每个特征图的加权值vk为
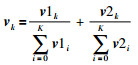
|
(2) |
其中,v1k为综合考虑特征图的强度与稀疏性的加权值;v 2k表示聚合紧密度,它的值越小表示聚合越紧密.具体计算过程如下:
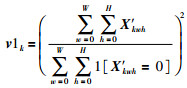
|
(3) |
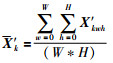
|
(4) |
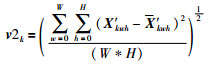
|
(5) |
为了说明本文设计的通道权重的合理性,在公开数据集Paris6k[19]上进行相关性分析,该数据集有55张查询图像,按巴黎建筑物或地标分为11类.对这55张图像按类别进行排序,每张图像用向量v表示,两两之间计算相关性,画出相关性矩阵的热图,如图 1所示,1(a)为CroW设计的稀疏敏感度权重相关性热图,1(b)为本文设计的权重相关性热图,1(c)为未对卷积特征做处理的权重相关性热图,1(d)为特征图的强度与稀疏性权重相关性热图,1(e)为特征图聚合紧密度权重关性热图.图中颜色越蓝代表两图像相似度越低,颜色越红代表两图像相似度越高.比较图 1(a)和1(b)可知,同类别图像都拥有很高的相关性,但本文设计的权重使不同类别图像具有更大区分性;比较图 1(b)和1(c)可知,对卷积特征X进行滤波空间加权能够提高同类别图像的相关性和不同类别图像的区分性.比较图 1(b)、1(d)和1(e)可知,综合考虑特征图的强度与稀疏性、聚合紧密度可以尽可能地提高同类别图像的相关性和不同类别图像的区分性.

|
| 图 1 不同图像间权重向量相关性热图 Fig.1 The heat map of weight vector correlation between different images |
在聚合深度卷积特征时,后文介绍的选择滤波加权矩阵已经在空间上对频繁出现的特征进行大幅度加强,而较少出现的特征也会提供很重要特征信息,并且聚合紧密的特征图能够很好抑制噪声,因此需要给这些通道赋予更大的权重.使用对数变换获取最终的差异性加权向量Vk为
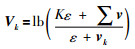
|
(6) |
其中,ε为常数,用来保证计算的稳定性.
从公开数据集Paris6k里随机选取一张图像,计算差异性差异性加权向量,如图 2所示.

|
| 图 2 原始图像和对应的差异性加权向量数值柱状图 Fig.2 Original image and differential weighting vector numerical histogram |
图 2(a)为随机选出的原始图像,图 2(b)为该原始图像的深度卷积特征计算出的差异性加权向量.
2.2 选择滤波加权矩阵生成函数CroW对所有特征图进行求和,并对其进行归一化,得到空间加权矩阵,在一定程度上突出了显著性比较强烈的特征,提高了图像检索性能,但CroW并没有考虑特征图存在背景噪声的情况.此外不同特征图代表的语义不同,不同的图像突出的语义也不同.因此本文提出的选择滤波加权矩阵,对深度卷积特征的特征图进行选择求和,并对其进行滤波处理.
根据SBA对不同图像的特征图的选择策略,并综合考虑特征图的稀疏性对特征图进行选择,本文提出特征图选择的权重计算结果Qk为
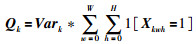
|
(7) |
其中,Vark为第k个特征图的方差.根据选择权重结果对被选择的特征图求和,结果记作F ′
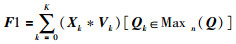
|
(8) |
其中,Maxn(Q)为Q中前n个最大结果.最后对F1进行滤波为F2,再对F2做归一化处理为F,计算过程如下:
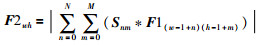
|
(9) |
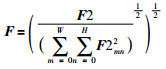
|
(10) |
其中,S为滤波器,N和M表示滤波器的宽和高.
为了验证本文设计的空间权重的合理性,实验对比如图 3所示.第一行是从数据集Paris6k和Oxford5k[20]中随机选取的6张原始图像,第二行是第一行原始图像的深度卷积特征所对应的热图,第三行是第一行原始图像经过加权处理后的深度卷积特征所对应的热图.可以看出,相较于第二行原始图像深度卷积特征所对应的热图,第三行原始图像经过加权处理后的深度卷积特征所对应的热图更加突出了图像的显著性区域,且很好地抑制了图像的背景噪声区域.

|
| 图 3 原始图像、原始深度卷积特征所对应的热图和加权后的深度卷积特征所对应的热图 Fig.3 Original images, heat maps of the original deep convolutional features and the weighted deep convolutional features |
实验选择图像检索领域4个公开数据集:Paris6k[19]来自Flickr收集的6 392张图像,包括55张查询图像,按巴黎建筑物或地标分为11类;Paris106k包括Paris6k和Flickr收集的100k张干扰图像;Oxford5k[20]来自Flickr收集的5 062张图像,包含55张查询图像,按牛津建筑物或地标分为11类;Oxford105k包括Oxford5k和Flickr收集的100k张干扰图像.为了避免其他因素对实验结果的影响,本文在Caffe[21]框架下提取预先训练好的VGG16[22]网格的最后一个卷积层输出结果作为图像的深度卷积特征,并不涉及该网络的全连接层,因此,并不需要对图像进行分类.原始图像大小与获取的深度卷积特征大小比较如表 2所示.
| 原始图像 | 深度卷积特征 | |||
| 宽 | 高 | 特征图数 | 宽 | 高 |
| 1 024 | 747 | 512 | 32 | 24 |
| 768 | 1 024 | 512 | 24 | 32 |
| 1 024 | 646 | 512 | 32 | 21 |
| 819 | 1 024 | 512 | 26 | 32 |
| 683 | 1 024 | 512 | 22 | 32 |
图像检索的评价指标采用图像检索精度(mAP),计算公式为
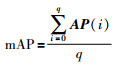
|
(11) |
其中,q为查询图像数量,AP (i)表示第i张查询图像的检索精度. AP (i)计算公式为
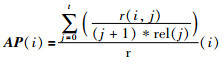
|
(12) |
其中,t为数据集中图像的个数,函数rel(j)返回第i张查询图像的第j个查询结果与查询图像是否相关,相关为1,不相关为0,函数r(i)返回数据集中与第i张查询图像相关的图像数量,函数r(i,j)返回第i张查询图像的前j个查询结果中与查询图像相关的图像数量.
3.2 实验环境本文实验环境如下:
硬件环境:处理器为Intel(R)Core(TM)i5-5200U;内存为8.00 GB的笔记本电脑;
软件环境:64位Windows 7操作系统;
编程语言:Python2.7;
编程软件:Visual Studio Code.
3.3 滤波器S选择与参数n选取本文在设计差异性加权向量生成函数和选择滤波矩阵生成函数时,使用了滤波器S与参数n,下面通过实验具体介绍S和n的选取.
3.3.1 滤波器选择本文设计的差异性加权向量和选择滤波加权矩阵都使用了滤波器S,不同的滤波器对实验结果有很大的影响.通过选取图像处理领域常用的一些滤波器,如高斯算子滤波器、拉普拉斯算子滤波器和Sobel算子不同方向的滤波器,来验证以及确定使用哪种滤波器能有效地提升图像检索性能,实验对比如图 4所示.

|
| 图 4 不同滤波器图像检索精度比较 Fig.4 Comparison of image retrieval accuracy between different filters |
由图 4可知,在数据集Oxford5k和Paris6k的不同维度上,当使用Sobel-X滤波器时,检索精度达到最大,即本文所使用的滤波器S为
|
(11) |
Sobel-X提取水平方向边缘信息,Sobel-Y提取垂直方向边缘信息.如图 5所示.

|
| 图 5 Sobel不同方向对深度卷积特征处理 Fig.5 Deep convolutional feature processing in different directions of Sobel |
图 5(a)是从Paris6k数据集上随机选取的原始图像,图 5(b)使用Sobel-X对深度卷积特征进行滤波获取的权重矩阵热图,图 5 (c)使用Sobel-Y对深度卷积特征进行滤波获取的权重矩阵热图,图 5 (d)使用Sobel-X获取的权重矩阵对深度卷积特征进行加权后的图像特征热图,图 5 (e)使用Sobel-X获取的权重矩阵对深度卷积特征进行加权后的图像特征热图.使用Sobel-X比使用Sobel-Y效果好,原因如下:
1) 通常拍照片如图 5(a)所示,图像中会出现上下背景不一致的情况,导致使用Sobel-Y提取边缘会比使用Sobel-X出现更多的噪声信息,如图 5(b)和图 5(c)对深度卷积特征分别进行Sobel-X和Sobel-Y操作获取加权矩阵.
2) 本文使用滤波器是为了获取图像的轮廓信息,从图 5(b)和图 5(c)可知,使用Sobel-X能够有效地从深度卷积特征中提取出图像轮廓信息,而Sobel-Y提取信息却并不理想.从图 5(d)和图 5(e)可知,使用Sobel-X获取的加权矩阵对深度卷积进行加权比使用Sobel-Y更能突出显著性区域特征.
3.3.2 参数n的选取在计算选择滤波加权矩阵中,参数n表示所选特征图的数量.若n值太小,则所选特征图不能充分反映图像的深度卷积特征;若n值太大,则无法将需要突出显著性区域的特征放大.由于n的可选范围相对较大,先对n进行均匀采样并在数据集Paris6k和Oxford5k上进行试验,如图 6所示.

|
| 图 6 选择特征图数占总数百分比的图像检索精度 Fig.6 The accuracy of image retrieval selected as a percentage of the total number of feature maps |
图 6中横坐标表示所选特征图数量占特征图总数量的百分比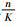
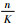
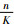
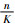
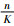
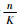
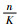
为了进一步确定n的具体取值,在n=102附近做精细取值.如表 3所示,当n=110时图像检索精度在各个维度上相对较好.
| n | 检索精度 | |||||
| Paris6k | Oxford5k | |||||
| 512 | 256 | 128 | 512 | 256 | 128 | |
| 118 | 0.836 | 0.809 | 0.782 | 0.740 | 0.712 | 0.660 |
| 114 | 0.836 | 0.810 | 0.782 | 0.739 | 0.712 | 0.660 |
| 110 | 0.836 | 0.809 | 0.782 | 0.741 | 0.713 | 0.660 |
| 106 | 0.836 | 0.809 | 0.782 | 0.741 | 0.713 | 0.658 |
| 102 | 0.836 | 0.809 | 0.782 | 0.740 | 0.712 | 0.656 |
| 98 | 0.836 | 0.808 | 0.782 | 0.740 | 0.710 | 0.657 |
| 94 | 0.836 | 0.808 | 0.782 | 0.738 | 0.709 | 0.656 |
本文分别在Paris6k和Oxford5k数据集上进行验证实验,结果如图 7所示.

|
| 图 7 不同加权策略对应的图像检索精度 Fig.7 Image retrieval accuracy of different weighting strategies |
图 7中Original表示没有进行任何加权的图像检索精度,Original+V表示只使用本文设计的通道权重(差异性加权向量)进行加权,Original+F表示只使用本文设计的空间权重(选择滤波加权矩阵)进行加权,Original+V+F表示本文所提差异性加权向量和选择滤波加权矩阵两种策略进行加权.从图 9可以看出,相较于Original方法,本文设计的空间权重Original+F在数据集Paris6k和Oxford5k上的图像检索精度都有明显的提升;而本文设计的通道权重是为了解决空间加权后出现的特征爆炸问题,因此,单独使用通道权重Original+V进行加权时,图像检索精度并不一定都会提升,但采用两种加权策略Original+V+F进行加权时,图像检索精度在数据集Paris6k和Oxford5k的各个维度上均有了进一步地提升.
3.5 对比实验结果在同等实验条件下,本文所提方法与其他同类算法如Razavian[9]、R-MAC[12]、SpoC[13]、CroW[14]、SBA[15]和NetVLAD[23]等在4个公开数据集上的检索性能对比结果如表 4所示.可以看出,本文所提出方法在不同维度上的图像检索精度都优于目前其他同类方法,说明本文设计的选择滤波加权矩阵能有效地突出显著性区域特征并在一定程度上抑制背景噪声,本文设计的差异性加权向量能够有效的缓解特征爆炸现象.因此,本文方法能够进一步提高图像检索精度.
| 方法 | 维度 | 检索精度 | |||
| Paris6k | Paris106k | Oxford5k | Oxford105k | ||
| NetVLAD[23] | 512 | 0.749 | - | 0.676 | - |
| R-MAC[13] | 0.830 | 0.757 | 0.669 | 0.616 | |
| CroW[15] | 0.797 | 0.722 | 0.708 | 0.653 | |
| SBA[16] | 0.823 | 0.758 | 0.720 | 0.662 | |
| 本文方法 | 0.836 | 0.765 | 0.741 | 0.690 | |
| NetVLAD[23] | 256 | 0.735 | - | 0.635 | - |
| Razavian[10] | 0.670 | - | 0.533 | 0.489 | |
| R-MAC[13] | 0.729 | 0.601 | 0.561 | 0.470 | |
| SpoC[14] | - | - | 0.531 | 0.501 | |
| CroW[15] | 0.765 | 0.691 | 0.684 | 0.637 | |
| SBA[16] | 0.796 | - | 0.687 | - | |
| 本文方法 | 0.809 | 0.739 | 0.713 | 0.665 | |
| NetVLAD[23] | 128 | 0.695 | - | 0.614 | - |
| CroW[15] | 0.746 | 0.670 | 0.641 | 0.590 | |
| SBA[16] | 0.769 | - | 0.645 | - | |
| 本文方法 | 0.782 | 0.708 | 0.660 | 0.605 | |
为了提高图像检索精度,本文提出了一种加权聚合深度卷积特征的图像检索方法.首先,将图像输入到预训练好的VGG16网络中提取图像的深度卷积特征.然后,通过设计差异性加权向量和选择滤波加权矩阵对其进行加权,加权处理后的深度卷积特征更能突出图像的显著性区域,并在某种程度上有效地抑制了背景噪声.在4个公开数据集上的实验结果表明,本文所设计的方法在图像检索精度上具有明显的优势.
| [1] |
宋广为, 刘程军, 王庆鹏, 等.
一种新的基于本体论描述的内容图像检索模型[J]. 信息与控制, 2012, 41(3): 319–325.
Song G W, Liu C J, Wang Q P, et al. A new model of content image retrieval based on the ontology theory description[J]. Information and Control, 2012, 41(3): 319–325. DOI:10.3724/SP.J.1219.2012.00319 |
| [2] | Lowe D G.Object recognition from local scale-invariant features[C]//Proceedings of the 1999 Seventh IEEE International Conference on Computer Vision.Piscataway, NJ, USA: IEEE, 1999: 1150-1157. |
| [3] | Perronnin F, Dance C.Fisher kernels on visual vocabularies for image categorization[C]//2007 IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ, USA: IEEE, 2007: 1-8. |
| [4] | Arandjelovic R, Zisserman A.All about VLAD[C]//Proceedings of the IEEE conference on Computer Vision and Pattern Recognition.Piscataway, NJ, USA: IEEE, 2013: 1578-1585. |
| [5] | Csurka G, Dance C, Fan L, et al.Visual categorization with bags of keypoints[C]//Workshop on Statistical Learning in Computer Vision.Piscataway, NJ, USA: IEEE, 2004: 1-2. |
| [6] | Gong Y, Wang L, Guo R, et al.Multi-scale orderless pooling of deep convolutional activation features[C]//European Conference on Computer Vision.Berlin, Germany: Springer, 2014: 392-407. |
| [7] | Oquab M, Bottou L, Laptev I, et al.Learning and transferring mid-level image representations using convolutional neural networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ, USA: IEEE, 2014: 1717-1724. |
| [8] | Azizpour H, Sharif Razavian A, Sullivan J, et al.From generic to specific deep representations for visual recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops.Piscataway, NJ, USA: IEEE, 2015: 36-45. |
| [9] | Chatfield K, Simonyan K, Vedaldi A, et al.Return of the devil in the details: Delving deep into convolutional nets[EB/OL].(2014-11-05)[2018-11-15].https://arxiv.org/pdf/1405.3531.pdf. |
| [10] | Sharif R A, Azizpour H, Sullivan J, et al.CNN features off-the-shelf: An astounding baseline for recognition[C]//Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition Workshops.Piscataway, NJ, USA: IEEE, 2014: 806-813. |
| [11] | Zheng L, Zhao Y, Wang S, et al.Good practice in CNN feature transfer[EB/OL].(2016-04-01)[2018-11-15].https://arxiv.org/pdf/1604.00133.pdf. |
| [12] | Liu L, Shen C, van den Hengel A.The treasure beneath convolutional layers: Cross-convolutional-layer pooling for image classification[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ, USA: IEEE, 2015: 4749-4757. |
| [13] | Tolias G, Sicre R, Jégou H.Particular object retrieval with integral max-pooling of CNN activations[EB/OL].(2016-02-24)[2018-11-15].https://arxiv.org/pdf/1511.05879.pdf. |
| [14] | Babenko A, Lempitsky V.Aggregating local deep features for image retrieval[C]//Proceedings of the 2015 IEEE International Conference on Computer Vision.Piscataway, NJ, USA: IEEE, 2015: 1269-1277. |
| [15] | Kalantidis Y, Mellina C, Osindero S.Cross-dimensional weighting for aggregated deep convolutional features[C]//European Conference on Computer Vision.Berlin, Germany: Springer, 2016: 685-701. |
| [16] | Xu J, Wang C, Qi C, et al. Unsupervised semantic-based aggregation of deep convolutional features[J]. IEEE Transactions on Image Processing, 2018, PP(99): 1–1. |
| [17] |
肖传民, 史泽林, 夏仁波, 等.
一种基于视觉显著性的边缘检测算法[J]. 信息与控制, 2014, 43(1): 9–13.
Xiao C M, Shi Z L, Xia R B, et al. Edge-detection algorithm based on visual saliency[J]. Information and Control, 2014, 43(1): 9–13. |
| [18] | Jegou H, Douze M, Schmid C.On the burstiness of visual elements[C]//Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ, USA: IEEE, 2009: 1169-1176. |
| [19] | Philbin J, Chum O, Isard M, et al.Lost in quantization: Improving particular object retrieval in large scale image databases[C]//Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ, USA: IEEE, 2008: 1-8. |
| [20] | Philbin J, Chum O, Isard M, et al.Object retrieval with large vocabularies and fast spatial matching[C]//Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ, USA: IEEE, 2007: 1-8. |
| [21] | Jia Y, Shelhamer E, Donahue J, et al.Caffe: Convolutional architecture for fast feature embedding[C]//Proceedings of the 22nd ACM International Conference on Multimedia.New York, NJ, USA: ACM, 2014: 675-678. |
| [22] | Simonyan K, Zisserman A.Very deep convolutional networks for large-scale image recognition[EB/OL].(2015-04-10)[2018-11-15].https://arxiv.org/pdf/1409.1556.pdf. |
| [23] | Arandjelovic R, Gronat P, Torii A, et al.NetVLAD: CNN architecture for weakly supervised place recognition[C]//Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ, USA: IEEE, 2016: 5297-5307. |