



2. 华中科技大学自动化学院, 湖北 武汉 430074
2. School of Automation, Huazhong University of Science&Technology, Wuhan 430074, China
0 引言
工业过程中的诸多应用,包括高级控制、故障诊断、过程仿真以及在线监测等,是通过获取准确的系统数学模型来得到保证的[1].然而,大多数物理系统包含复杂的非线性及耦合关系等因素,导致很难建立准确的数学模型;此外,对来自控制系统中的过程参数变化、外部干扰或传感器失效也对控制系统的设计增加了诸多不确定性[2].这些现象的存在更需要探索一种更有效的建模方法,能够实现复杂的输入—输出映射及非线性函数逼近.因此,出现了基于数据或数据驱动的建模方法[3-4],即通过传感器或其他数据获取设备获取被控对象的输入—输出数据,采用神经网络[5]、T-S模糊模型[6]、自回归滑动平均模型[7]等方法建立复杂系统的数学模型,这些方法的共同特点是建立的数学模型一般是确定的,不受系统参数变化、测量噪声或其他不确定性等因素的影响,具有一定的局限性:1)确定的数学模型不能自适应系统的变化,易受外界干扰;2)基于训练数据建立的数学模型结构较复杂、泛化性能差等.
神经网络(NN)方法及其变体在基于数据建模过程中得到了广泛应用[8-9].文[10]针对复杂的效能评估问题,提出了基于遗传算法的反向传播NN方法构建评估模型.在非线性系统建模的应用中,文[11]仍以神经网络为核心,通过引入两阶段学习算法以及增量学习算法从收敛时间和泛化性能上对传统的建模方法做了较大改进,使获取的最终模型更具紧凑性;文[12]将正交最小二乘算法引入径向基NN,提高神经网络模型的预测精度以及提高模型的计算效率.众所周知,NN在模型结构选择上存在主观性较大、复杂,以及参数求解主要是基于最小二乘的目标优化,也可能导致模型泛化性能差.由Vapnik及其研究团队提出的基于结构风险最小化理论的支持向量回归[13]成了各领域研究的热点,在模式识别和函数逼近问题上也得到了成功的应用.鉴于SVM所具有的优点,文[4, 14-15]提出了基于支持向量学习方法的模糊回归分析,该方法较传统神经网络方法在泛化性能上做了较好的改进.此外,基于数据的另一种T-S模糊建模方法,也将基于增量平滑SVR的结构风险最小化作为优化问题[16],进而提高模型泛化性能.近年来,深度学习俨然成为研究的热点,文[17-19]围绕非线性系统的建模问题,提出了一种基于改进型深度学习的非线性建模方法.
目前,各种数据建模方法主要集中在确定性数学模型建模的研究,其鲁棒性差,易受外界干扰,很少有针对来自模型结构、参数以及测量数据的不确定性等因素所引起的下界建模的研究;此外,对如何控制模型结构的复杂性,进而提高其泛化性能,在模型辨识过程中也是需要考虑的一个重点.鉴于此,本文考虑到基于结构风险最小化的支持向量机所具有的优良特性,将逼近误差的L∞范数思想与结构风险最小化理论相结合,建立求解最优下界回归模型的优化问题,再应用较简单的线性规划求解下界回归模型的稀疏解.该方法可归纳为:1)提出了最小化最大逼近误差的范数定理,作为分别建立区间模型的下界回归模型的优化问题;2)建立基于结构风险最小化的代价函数,在保证辨识区间回归模型精度的同时,尽可能对模型结构复杂性进行有效控制,进而提高模型的泛化性能;3)下界输出模型包括了由各种不确定性因素引起的输出,进而提高建模的鲁棒性.
1 支持向量回归及其优化问题转化 1.1 支持向量回归问题随着Vapnik的不敏感损失函数的引入[20-21],支持向量机的分类问题被扩展到回归问题,即支持向量回归(SVR),已在最优控制、时间序列预测、区间回归分析等方面得到了广泛应用. SVR方法是对一组带有噪声的测量数据{(x1,y1),(x2,y2),…,(xN,yN)}的未知函数进行逼近,其中xk=(xk1,xk2,…,xkd)表示d维特征模式.假设一组基函数{gs(x),s=1,…,l},可用基函数的线性展开描述任意的非线性系统.因此,函数的逼近问题可转化为寻求如下基函数线性展开的最优参数求解[20]:
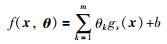
|
(1) |
其中,θ =(θ1,θ2,…,θm)为需要被寻优的参数向量,b是一个常量.进一步,该问题的参数寻优即为寻找满足如下优化问题的非线性函数f:
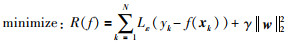
|
(2) |
其中,R(f)为结构风险,γ表示规则化常量,用于对模型结构与建模精度重视程度的权衡,||w||22的引入在于控制模型的复杂度,Lε(·)描述ε不敏感损失函数,定义为
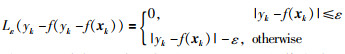
|
(3) |
从上述ε域定义可知,如果|yk-f(xk)|的值在该ε区域内,损失为0;否则为|yk-f(xk)|与ε的差值.
通过应用拉格朗日乘子方法,对式(2)最小化可转化为它的对偶优化问题:
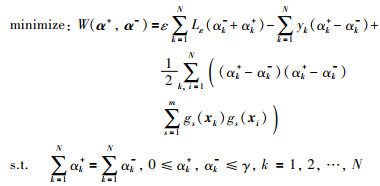
|
(4) |
其中,αk+,αk-表示拉格朗日乘子,α+=(α1+,…,αN+),α-=(α1-,…,αN-).式(4)中gs(x)的内积可用核函数代替:
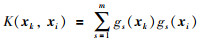
|
(5) |
其中核函数的选取对优化问题(4)的稀疏解具有至关重要的作用.通过大量的实验研究表明[22-23],高斯核函数相比于其它核函数具有更强的映射能力.因此,高斯核函数将被用于本文的OLRM辨识.式(4)的优化问题可从写为
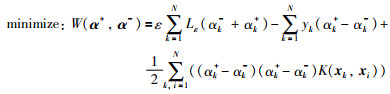
|
(6) |
基于Vapnik的研究,SVR方法的解以核函数的线性展开描述为
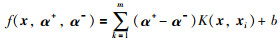
|
(7) |
其中,常量b的计算为
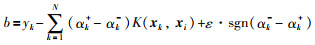
|
(8) |
显然,仅当αk+-αk- ≠0时,对应的样本xk称为支持向量(SV).由于本文使用高斯核函数,可将式(7)写成,
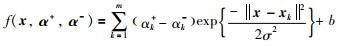
|
(9) |
其中,σ称为高斯核参数.
1.2 优化问题转化众所周知,支持向量回归(support vector regression,SVR)是将基于2范数的结构风险最小化作为优化目标,实现对回归模型结构复杂性的控制,从而提高模型的泛化性能;然而,从1. 1节的SVR回归问题所描述的优化问题(4)来看以及在文[21]中指出,SVR中的优化目标求解采用的是二次规划,会产生模型的冗余描述以及昂贵的计算成本;同时,二范数的优化问题不能直接用于本文提出的最优下边界回归模型辨识的优化问题,需要进行2范数到1范数的转化.对于QP-SVR,基于式(2)的优化问题:
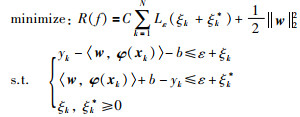
|
(10) |
其中,φ (·)表示从输入空间到高维空间的非线性特征映射,即φ:Rn→Rm(m>n);ξk,ξk*为松弛变量,分别对应超出正、负方向偏差值时的大小;常量C>0,反映非线性f与偏差大于ε时两者之间的平衡.对于式(9),令βk=αk+-αk-,则有:
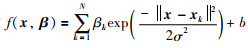
|
(11) |
其中,β =(β1,β2,…,βN)T.考虑到式(2)的优化问题,||w||22范数的引入是为了控制模型的复杂度,根据范数的等价性可知,在结构风险中引入其它范数也可以同样对模型复杂性进行控制.接下来,将QP-SVR的优化问题(10)变成:
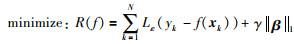
|
(12) |
其中,f(x)以式(9)形式描述,||β||1表示系数空间的1范数.因此,新的约束优化问题为
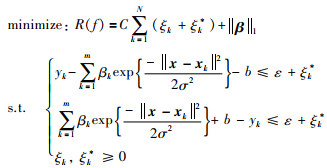
|
(13) |
从几何的角度来看,ξk和ξk*之间的关系在SVR中满足ξkξk*=0.因此,在优化问题(13)中仅引入一个松弛变量ξk即可[25],即:
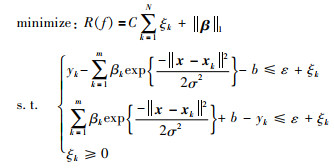
|
(14) |
为了转化上述优化问题为线性规划问题,将βk和|βk|进行分解:
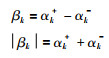
|
(15) |
其中,αk+,αk-≥0.考虑到αk+和αk-不能同时大于0,对应3种不同情况的解,即(αk+,0),(0,αk-),(0,0),因此式(15)的分解是唯一的.下面对线性规划问题(14)在式(15)的分解下,αk+和αk-不能同时大于0进行简单证明.采用反证法,假设在问题(14)的最优解中存在某一个k,使得αk+和αk-同时大于零,现取τ=min(αk+,αk-),将αk+和αk-分别换成αk+-τ和αk--τ,仍然满足αk+-τ>0和αk--τ>0,但是目标函数中的αk++αk-将减少αk++αk--2τ,这显然与最优解的假设相矛盾.因此,αk+和αk-不能同时大于0,即αk+·αk-=0.
基于式(15),优化问题(14)进一步变成:
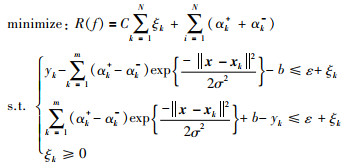
|
(16) |
现定义向量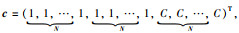
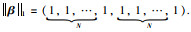
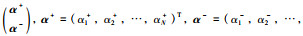
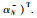
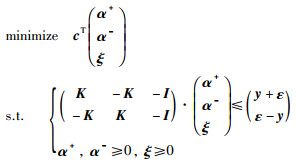
|
(17) |
其中,ξ =(ξ1,ξ2,…,ξN)T,I为N×N的单位矩阵,y =(y1,y2,…,yN)T,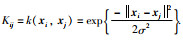
基于上一节介绍的支持向量回归及优化问题转化的基础上,该部分将讨论模型参数估计的另一种方法,即使用L∞范数作为建模误差的评判标准.假设通过传感器或数据获取设备获取一组测量数据{(x1,y1),(x2,y2),…,(xN,yN)},其中{ x1,x2,…,xN}描述输入测量数据,对应的输出定义为{y1,y2,…,yN}.设测量满足非线性系统模型:
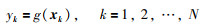
|
(18) |
根据统计学理论可知[24],存在以式(11)描述的非线性回归模型f对测量模型g的任意逼近,当逼近精度越小时,需要的支持向量越少;反之,逼近精度越高,则支持向量越多.因此,对任意给定的实连续函数g及较小的正实数η>0,存在回归模型f满足:
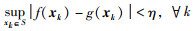
|
(19) |
由于下边界回归模型是基于获取到的输入—输出数据来辨识的,其中集合S是指被建模对象的数据输入集.值得指出的是,较小的η值,对应式(11)较多的支持向量.现讨论回归模型,式(11)的另一种参数求解方法.在非线性系统模型的逼近情况下,定义实际输出与由式(11)定义的SVR模型输出之间的偏差ek:
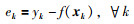
|
(20) |
为了估计SVR模型的最优参数,考虑最大建模误差的最小化:
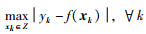
|
(21) |
Z表示整个输入数据集.显然,这是一个最小—最大(min-max)优化问题.在式(19)描述的回归模型情况下,式(21)的最小化可通过如下两个阶段完成:1)核函数中的核宽度σ的参数寻优,通常采用经典的交叉验证或其他方法来实现,其详细过程在本文中不再讨论;2)式(11)的参数确定可通过min-max优化问题求解,即:
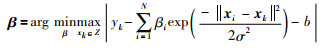
|
(22) |
定理 1 min-max优化问题中的参数可通过最小化λ,且满足如下不等式约束的线性规划求解,即:
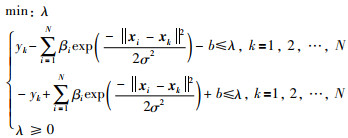
|
(23) |
其中,β =(β1,β2,…,βN)T和b为被求解参数,λ表示最大逼近误差.
证明:定义λ:
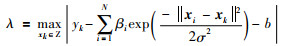
|
(24) |
可直接得出不等式:
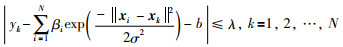
|
(25) |
根据去绝对值运算,可知式(25)的约束条件成立.
3 带稀疏特性的最优下界回归模型(OLRM)辨识有了基于L∞范数的回归模型辨识的基础之后,接下来将讨论带稀疏特性的最优下界回归模型辨识方法,为了能给出辨识方法的清晰思路,整个辨识过程如图 1所示.

|
| 图 1 最优下界回归模型建模方法流程图 Fig.1 Flow chart of the proposed method for OLRM |
假定不确定非线性函数或非线性系统属于函数簇Γ由名义函数gnom(x)和不确定性Δg(x)两部分组成:
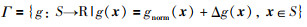
|
(26) |
其中不确定性Δg(x)满足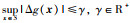
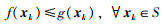
|
(27) |
在上式约束的意义下,来自函数簇的任一成员函数总能在LRM上方中找到.显然,这样的LRM有无穷多个,本文的目的就是根据提出的约束(27),确定尽可能逼近成员函数的下界.在本文,是通过提出的方法将L∞范数、结构风险最小化理论以及线性规划相结合,给出LRM更好的逼近.由式(11),给出下界回归模型的表达式,
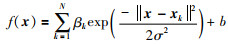
|
(28) |
下界回归模型f(x)可通过线性规划对式(29)的优化问题进行求解:
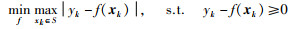
|
(29) |
定理 2 对于下界回归模型f(x)的参数β,b的求解,对应min-max优化问题(29)可通过最小化λ,且满足不等式约束(30)的线性规划求解.
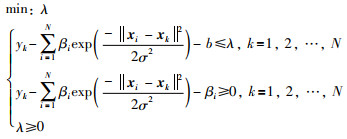
|
(30) |
其中, λ表示最大逼近误差.
证明 上述定理2直接通过定理1推出.
从上述区间回归模型辨识的思想来看,仅考虑上边模型输出与实际输出之间的逼近误差,而回归模型本身的结构复杂性却没有被考虑,这样一来,通过上述优化问题获取的参数解有可能出现不全为零的情况,不具有稀疏特性,对应N个样本数据可能都是支持向量,导致模型结构复杂.为了解决模型稀疏解的问题,在求解区间回归模型的优化问题中,有必要将结构风险最小化的思想融合其中,在保证回归模型逼近精度的同时,尽可能让模型结构复杂性得到有效控制.基于此,将下界回归模型优化问题(30),融合到基于结构风险最小化的优化问题(16).因此,对于带有稀疏特性的下界回归模型f(x)的优化问题,有:
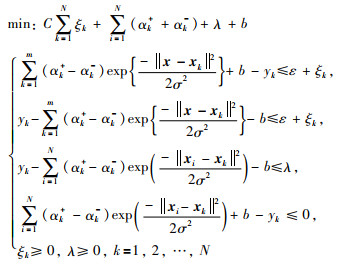
|
(31) |
其中, λ表示最大逼近误差,参数αk+,αk-,b,ε,ξk与第2节的定义一样.
从优化问题(31)可知,为典型的线性规划问题,可用向量及矩阵形式表述为
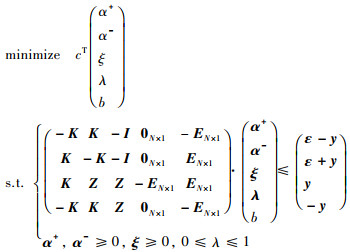
|
(32) |
其中,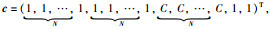
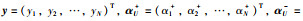
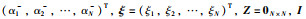
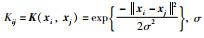
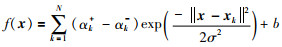
|
(33) |
从应用提出方法来建立OLRMf(x)的整个过程来看,优化问题既包括了对模型结构复杂性控制的目标函数,又包括了如何获取较好的模型精度所对应的逼近误差作为目标函数,而且模型结构复杂性控制和模型精度之间的权衡可以通过规则化参数进行调整.总而言之,提出方法在保证获取下界模型建模精度的同时,而且还对模型结构复杂性进行有效控制,从而提高下界回归模型的泛化性能.
4 仿真计算这部分内容将通过如下仿真计算分析,论证所提出方法的最优性与稀疏性;同时为了更直观的去评判提出的方法,将考虑如下两个性能指标,即均方根误差(root mean square error,RMSE)和支持向量占整个样本数据的百分比SVs%.对于RMSE指标定义如下,
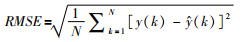
|
(34) |
其中,N表示测试数据的总数,y(k)为实际输出,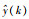
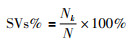
|
(35) |
显然,在保证下界模型建模精度的同时,指标SVs%越小越好,越小则表示求解的下界回归模型有稀疏解,模型结构简单,说明具有较好的泛化性能.
接下来本文将对提出的方法从下界回归模型的辨识精度以及稀疏特性展开仿真计算分析.对于函数逼近,采用提出的方法分两种情况进行讨论:1)当被建模对象不含有噪声时,论证传统的确定性建模方法是提出方法的特殊情况;2)当被建模对象含有噪声时,论证带稀疏特性的最优下界回归模型.
其中sin c(x)=sin x/x是支持向量回归机理论最常采用的仿真计算[24],用于论证模型建模精度以及泛化性能.对于该仿真,在不含噪声情况下,取x∈[-10,10],超参数集(ε,γ,σ)选择为(0.000 1,10 000,3. 2),图 2给出了实际输出、LRM输出以及建立LRM(黑色实线)所使用的支持向量(SV),从中发现建立LRM仅用了9个SV(其中蓝色实心圆表示SV),具有较好的稀疏特性;同时对应的建模精度RMSE为0.003 6,表明LRM的输出有着较好的建模精度.在不含噪声情况下,LRM输出与实际输出几乎重合,因此可以认为传统的确定性建模方法是提出方法的特殊情况,实际上LRM与实际输出满足条件f(x)-y≤0,即实际输出永远在LRM的上方(图 3所示的逼近误差),也进一步证明了LRM在所有实际输出的下方.为了清晰地给出LRM的建模精度与稀疏特性之间的比较,表 1从不同的核宽度选择上列出了RMSE以及SVs%.接下来,考虑sin c(x)受噪声干扰的情况.类似地,在区间[-10, 10]上获取100个带均匀分布噪声为[-0.2,0.2]的等间隔噪声样本.取设超参数集(ε,γ,σ)为(0.1,1 000,2. 8),则sin c(x)的OLRM输出逼近如图 4所示,反映了由噪声所引起的不确定性数据都在OLRM的上方,图 5给出了OLRM与实际输出之间在满足f(x)-y≤0的条件下的逼近误差.同样地,从100个带噪声的测量数据中,辨识OLRM用了9个支持向量,体现了较好的稀疏特性,如图 6所示;对应的建模精度RMSE为0.112 6.当核宽度σ取为0.1是,提出方法所对应的RMSE为2. 631×10-6,对应较高的建模精度,但SVs%达到了100%,几乎丧失了模型的稀疏特性,泛化性能变差,如图 7所示.可知,RMSE与SVs%是一对矛盾体,随核宽度的增大,RMSE在增大,对应建模精度降低,但SVs%却在减小,说明模型稀疏特性较好.因此,可根据对被控对象建模的要求,从建模精度与稀疏特性之间取其平衡.

|
| 图 2 无噪声时的OLRM建模输出 Fig.2 The output of OLRM with no noise (其中蓝色实心圆表示支持向量(SVs)) |

|
| 图 3 无噪声时的OLRM逼近误差,且满足f(x)-y≤0 Fig.3 Approximation error corresponding to the OLRM subject to f(x)-y≤0 |
| 核参数σ | SVs% | RMSE | 核参数σ | SVs% | RMSE |
| 0.5 | 0.44 | 6.25×10-4 | 3.4 | 0.10 | 5.90×10-3 |
| 1 | 0.24 | 6.36×10-4 | 3.6 | 0.10 | 5.3×10-3 |
| 1.5 | 0.18 | 6.13×10-4 | 3.8 | 0.10 | 4.20×10-3 |
| 2 | 0.14 | 6.08×10-4 | 4.0 | 0.10 | 1.90×10-3 |
| 2.5 | 0.12 | 1.30×10-3 | 4.2 | 0.08 | 6.56×10-2 |
| 3 | 0.12 | 2.20×10-3 | 4.4 | 0.08 | 7.94×10-2 |
| 3.2 | 0.10 | 3.60×10-3 | 5.0 | 0.08 | 1.10×10-1 |

|
| 图 4 含噪声时的OLRM建模输出 Fig.4 The output of OLRM with noise, (其中蓝色实心圆表示支持向量(SVs)) |

|
| 图 5 带噪声时的OLRM逼近误差,且满足f(x)-y≤0 Fig.5 Approximation error corresponding to the OLRM subject to f(x)-y≤0 |

|
| 图 6 本文求解的参数 Fig.6 Parameters are solved by the proposed method (红色矩形表示应用提出方法求解的参数|αk+-αk-|≥δ) |

|
| 图 7 含噪声时的OLRM建模输出,其中SVs%达到了100%,丧失了稀疏特性 Fig.7 The output of the OLRM, where SVs% reach up to 100% and it lacks of sparsity |
继上述来自测量数据的不确定性仿真计算分析后,下面考虑来自模型参数不确定性的OLRM建模.假设不确定性参数的非线性函数类Γ,其成员函数为f(x),由名义函数fnorm(x)和不确定性Δf(x)构成,即:
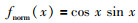
|
(36) |
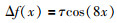
|
(37) |
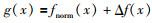
|
(38) |
0≤τ≤1,设该函数类的定义域为-1≤x≤1.为获取建立模型所需要的样本数据,不妨取xk=0.021k,k=-47,…,47,图 8给出了由不确定性参数τ引起的不确定性输出.接下来用提出的方法建立由不确定性参数τ值所引起的测量输出的最优下界回归模型.当模型的超参数集(ε,γ,σ)选择为(0.000 1,10,15)时,如图 9所示,仅用了9个数据(SV)建立LRM且较平坦,其中SVs%为9. 47%,RMSE为0.046 3,对应的逼近误差如图 10所示.

|
| 图 8 由不确定性参数τ值所引起的测量输出 Fig.8 The different outputs of the selected uncertain parameter τ |

|
| 图 9 由不确定性参数τ引起的OLRM建模输出,σ=15 Fig.9 The output of OLRM, where σ=15 |

|
| 图 10 由不确定性参数τ引起的OLRM逼近误差且满足f(x)-y≤0 Fig.10 Approximation error corresponding to the OLRM subject to f(x)-y≤0 |
当核宽度σ选择为3. 5时,对应的LRM如图 11所示,SVs%为31. 58%,RMSE为0.0052,显然,LRM建模精度相比于σ=15有较大改善,但LRM稀疏特性降低(对比图 9与图 11).因此,通过上面的仿真计算分析可知,应用提出的方法可以通过建模精度及其模型稀疏特性进行有效控制,且互为矛盾,只能从精度和稀疏特性(泛化性能)之间取其平衡.

|
| 图 11 由不确定性参数τ引起的OLRM建模输出,σ=3. 5 Fig.11 The output of OLRM caused by the uncertain parameter τ, where σ=3. 5 |
| k | αk+-αk- | k | αk+-αk- | k | αk+-αk- |
| 1 | 18.218 5 | 190 | 26.578 5 | 305 | -63.053 9 |
| 10 | 10.170 2 | 191 | 26.578 5 | 316 | -63.053 9 |
| 11 | 10.170 2 | 200 | 10.170 2 | 381 | 18.218 5 |
| 20 | 18.218 5 | 201 | 10.170 2 | 390 | 10.170 2 |
| 85 | -63.053 9 | 210 | 26.578 5 | 391 | 10.170 2 |
| 96 | -63.053 9 | 211 | 26.578 5 | 400 | 18.218 5 |
| 181 | 10.170 2 | 220 | 10.170 2 | 其它 | 0 |
接下来考虑来自文[27]的二元函数的仿真,包括含噪声以及无噪声两种情况讨论.当不含噪声时,
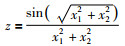
|
(39) |
其中,-5≤x1,x2≤5,每个变量从该区间等间隔采样20个数据,共计400(20×20)个实际输出.当超参数集(ε,γ,σ)选择为(0.1,10,2. 0)时,应用提出的方法建立LRM如图 12所示,对应的建模精度RMSE为0.139 1,稀疏特性SVs%为0.050 0,表明从400个数据中建立LRM,真正对LRM其决定性作用的只有20个数据(即支持向量),表二给出了这20个支持向量所对应的αk+-αk-≥10-8值,当αk+-αk-≤10-8时,认为αk+-αk-太小,对应的第k个数据对建立LRM的过程中几乎不起作用,图 13给出了起作用的αk+-αk-值,对应红色实心圆表示,其余大部分αk+-αk-值太小,分布于横坐标.然而,传统的LRM辨识方法,没有将结构风险融合到目标函数中,以最小化最大逼近误差为目标,因此无法对模型结构复杂性进行有效控制.采用传统LRM方法所对应RMSE为0.143 6,SVs%为0.570 0,与提出方法的0.050 0相比,显然稀疏特性较差.

|
| 图 12 二维函数在无噪声时的OLRM Fig.12 The output of OLRM for the two-dimensional function with free-noise |

|
| 图 13 红色实心圆表示应用提出方法求解的参数|αk+-αk-|≥10-8 Fig.13 Parameters are solved by the proposed method, where the red circles describe the |αk+-αk-|≥10-8 |
当二元函数(5.6)含噪声时,即:
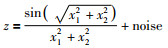
|
(40) |
类似地,在区间[-5, 5]上获取400个带均匀分布噪声noise为[-0.2,0.2]的等间隔噪声样本.当超参数集(ε,γ,σ)选择为(0.01,100,1. 0)时,提出方法获取的LRM如图 14所示,辨识精度RMSE为0.199 1,稀疏特性SVs%为0.095 0,LRM与含噪声实际输出之间的逼近误差如图 15所示,由于所有的测量数据都在LRM的上方,因此逼近误差满足f(x)-y≤0.然而,采用传统的LRM方法时,其辨识精度为0.120 1,稀疏特性SVs%为0.683 4,尽管LRM的辨识精度优于提出的方法,但在建立LRM过程中用到了较多的支持向量(与提出的方法为SVs%为0.095 0相比),其稀疏特性表现较差.

|
| 图 14 二维函数在含噪声时的OLRM Fig.14 The output of OLRM for the two-dimensional function with noise |

|
| 图 15 二维函数在含噪声时的逼近误差 Fig.15 Approximation error of the OLRM for the two-dimensional function with noise |
因此,通过上述仿真计算对提出的两个指标,即SVs%以及RMSE进行分析可知,提出的方法可以:1)很好地建立来自不确定性测量数据或系统模型参数不确定性的OLRM,采用下边界输出代替传统的点输出建模方法,更易于实际问题的研究;2)很好的解决了模型结构复杂性与辨识精度之间的平衡,在提高模型泛化性能的同时,模型辨识精度也能得到保证.
5 结论当获取一组由测量或参数不确定性等因素导致的测量数据集时,提出了一种新的区间回归模型辨识方法.该方法将结构风险最小化理论与逼近误差的L∞范数最优化思想相结合,给出了在保证被辨识模型精度条件下,对模型结构复杂性进行有效控制的目标优化问题,同时将复杂的凸二次规划求解转化为较简单的线性规划问题求解.克服了传统方法在辨识非线性系统过程中,目标优化问题仅考虑模型输出与实际输出之间的偏差达到最小,致使模型结构复杂.提出的区间回归模型由包含所有测量数据的下界回归模型构成,可应用于被观测系统的参数在某个区间变化时的函数簇建模、也可用于数据挖掘中的信息压缩以及故障检测.
| [1] | Kukolj D, Levi E. Identification of complex systems based on neural and Takagi-Sugeno fuzzy models[J]. IEEE Transactions on Systems, Man, and Cybernetics, Part B:Cybernetics, 2004, 34(1): 272–282. DOI:10.1109/TSMCB.2003.811119 |
| [2] |
李金娜, 高溪泽, 柴天佑, 等.
数据驱动的工业过程运行优化控制[J]. 控制理论与应用, 2016, 33(12): 1584–1592.
Li J N, Gao X X, Chai T Y, et al. Data-driven operational optimization control of industrial processes[J]. Control Theory&Applications, 2016, 33(12): 1584–1592. DOI:10.7641/CTA.2016.60455 |
| [3] |
郭晏, 宋爱国, 包加桐, 等.
基于差分进化支持向量机的移动机器人可通过度预测[J]. 机器人, 2011, 33(3): 257–264, 272.
Guo Y, Song A G, Bao J T, et al. Mobile robot traversability prediction based on differential evolution support vector machine[J]. Robot, 2011, 33(3): 257–264, 272. |
| [4] |
胡昌华, 施权, 司小胜, 等.
数据驱动的寿命预测和健康管理技术研究进展[J]. 信息与控制, 2017, 46(1): 72–82.
Hu C H, Shi Q, Si X S, et al. Data driven life prediction and health management:State of the art[J]. Information and Control, 2017, 46(1): 72–82. |
| [5] | Luzi M, Paschero M, Rizzi A, et al. A novel neural networks ensemble approach for modeling electrochemical cells[J]. IEEE Transactions on Neural Networks and Learning Systems, 2018(99): 1–12. |
| [6] | Lv Z, Zhao J, Zhai Y W, et al. Non-iterative T-S fuzzy modeling with random hidden-layer structure for BFG pipeline pressure prediction[J]. Control Engineering Practice, 2018, 76: 96–103. DOI:10.1016/j.conengprac.2018.04.002 |
| [7] |
辛斌, 白永强, 陈杰.
基于偏差消除最小二乘估计和Durbin方法的两阶段ARMAX参数辨识[J]. 自动化学报, 2012, 38(3): 491–496.
Xin B, Bai Y Q, Chen J. Two-stage ARMAX parameter identification based on bias-eliminated least squares estimation and durbin's method[J]. Acta Automatica Sinica, 2012, 38(3): 491–496. |
| [8] |
王淑青, 要若天, 高翔, 等.
启发式神经网络在异步电机矢量控制速度估计中的应用[J]. 信阳师范学院学报(自然科学版), 2017, 30(4): 618–622.
Wang S Q, Yao R T, Gao X, et al. Application of heuristic neural network in speed estimation of induction motor[J]. Journal of Xinyang Normal University (Natural Science Edition), 2017, 30(4): 618–622. DOI:10.3969/j.issn.1003-0972.2017.04.023 |
| [9] | Jin L, Li S, Yu J, et al. Robot manipulator control using neural networks:A survey[J]. Neurocomputing, 2018, 285: 23–34. DOI:10.1016/j.neucom.2018.01.002 |
| [10] |
陆营波, 钱晓超, 陈伟, 等.
数据驱动的装备效能评估模型构建方法研究[J]. 系统仿真学报, 2018: 1–8.
Lu Y B, Qian X C, Chen W, et al. Research on data-driven equipment effectiveness evaluation model construction method[J]. Journal of system simulation, 2018: 1–8. |
| [11] | Han H G, Guo Y N, Qiao J F. Nonlinear system modeling using a self-organizing recurrent radial basis function neural network[J]. Applied Soft Computing, 2018, 71: 1105–1116. DOI:10.1016/j.asoc.2017.10.030 |
| [12] |
张礼涛, 曾召霞, 孙文萧.
基于正交最小二乘法的径向基神经网络模型[J]. 信阳师范学院学报(自然科学版), 2013, 26(3): 428–431.
Zhang L T, Zeng Z X, Sun W X, et al. Radial basis function neural network model based on orthogonal least squares[J]. Journal of Xinyang Normal University (Natural Science Edition), 2013, 26(3): 428–431. DOI:10.3969/j.issn.1003-0972.2013.03.030 |
| [13] | Smola A J, Schölkopf B. A tutorial on support vector regression[J]. Statistics and Computing, 2004, 14(3): 199–222. DOI:10.1023/B:STCO.0000035301.49549.88 |
| [14] | Hao P Y. Interval regression analysis using support vector networks[J]. Fuzzy sets and systems, 2009, 160(17): 2466–2485. DOI:10.1016/j.fss.2008.10.012 |
| [15] | Hao P Y. Possibilistic regression analysis by support vector machine[C]//Proceedings of the Fifth IEEE International Conference on Fuzzy Systems. Piscataway, NJ, USA: IEEE, 2011: 889?894. |
| [16] | Ji R, Qu W, Yang Y. An incremental approach to TS fuzzy modeling[J]. IFAC Proceedings Volumes, 2013, 46(13): 365–370. DOI:10.3182/20130708-3-CN-2036.00062 |
| [17] | Qiao J, Wang G, Li W, et al. A deep belief network with PLSR for nonlinear system modeling[J]. Neural Networks, 2018, 104: 68–79. DOI:10.1016/j.neunet.2017.10.006 |
| [18] |
王盈旭, 韩红桂, 郭民.
一种基于改进型深度学习的非线性建模方法[J]. 信息与控制, 2018, 47(6): 680–686.
Wang Y X, Han H G, Guo M. A nonlinear modeling method based on improved deep learning[J]. Information and Control, 2018, 47(6): 680–686. |
| [19] | Qiao J, Wang G, Li X, et al. A self-organizing deep belief network for nonlinear system modeling[J]. Applied Soft Computing, 2018, 65: 170–183. DOI:10.1016/j.asoc.2018.01.019 |
| [20] | Basak D, Pal S, Patranabis D C. Support vector regression[J]. Neural Information Processing-Letters and Reviews, 2007, 11(10): 203–224. |
| [21] | Smola A J, Scholkopf B. A tutorial on support vector regression[J]. Statistics and Computing, 2004, 14(3): 199–222. DOI:10.1023/B:STCO.0000035301.49549.88 |
| [22] | Mohammadi K, Shamshirband S, Anisi M H, et al. Support vector regression based prediction of global solar radiation on a horizontal surface[J]. Energy Conversion and Management, 2015, 91: 433–441. DOI:10.1016/j.enconman.2014.12.015 |
| [23] |
刘小雍, 方华京, 熊中刚, 等.
基于无迹卡尔曼滤波的LSSVR在线多步时间序列预测[J]. 信阳师范学院学报(自然科学版), 2019(2): 1–6.
Liu X Y, Fang H J, Xiong Z G, et al. Multi-step-ahead time series prediction based on LSSVR using UKF with sliding-windows[J]. Journal of Xinyang Normal University (Natural Science Edition), 2019(2): 1–6. |
| [24] | Vapnik V N. An overview of statistical learning theory[J]. IEEE Transactions on Neural Networks, 1999, 10(5): 988–999. DOI:10.1109/72.788640 |
| [25] | Lu Z, Sun J, Butts K. Linear programming SVM-ARMA 2K with application in engine system identification[J]. IEEE Transactions on Automation Science and Engineering, 2011, 8(4): 846–854. DOI:10.1109/TASE.2011.2140105 |
| [26] | Smola A, Scholkopf B, Ratsch G. Linear programs for automatic accuracy control in regression[C]//Proceedings of the ninth International Conference on Artificial Neural Networks. Edinburgh, UK: IET, 1999: 575-580. |
| [27] | Chuang C C. Fuzzy weighted support vector regression with a fuzzy partition[J]. IEEE Transactions on Systems, Man, and Cybernetics, Part B Cybernetics, 2007, 37(3): 630–640. DOI:10.1109/TSMCB.2006.889611 |