



2. 南京财经大学信息工程学院, 江苏 南京 210023;
3. 南京邮电大学先进技术学院, 江苏 南京 210023;
4. 上海大学机电工程与自动化学院, 上海 200072
2. College of Information Engineering, Nanjing University of Finance and Economics, Nanjing 210023, China;
3. Institute of Advanced Technology, Nanjing University of Posts and Telecommunications, Nanjing 210023, China;
4. School of Mechatronics Engineering and Automation, Shanghai University, Shanghai 200072, China
0 引言
聚类分析是机器学习、数据挖掘领域非常重要的一种无监督学习算法.聚类分析经过几十年的发展,取得了丰富的研究成果,涌现了大量的针对不同应用场景的聚类算法[1-6],包括划分聚类、层次聚类、基于密度的聚类、基于网格的聚类以及基于模型的聚类方法. K-means聚类算法是最典型的划分聚类分析方法之一,由于原理简单、执行效率高,在包括数据挖掘、机器学习、空间数据库技术等众多研究领域均已得到了广泛的应用[7].
针对传统硬划分K-means方法在对类簇边界有交叉的数据进行处理时存在的缺陷,如何采用不同的软聚类分析方法对含有不确定性信息的数据进行处理受到了越来越多的关注[8-10].除了早期引入模糊度量的模糊K-means(FKM)算法,学者Lingras等将粗糙集理论上、下近似的概念融入到K-means聚类算法中,提出了粗糙K-means聚类方法[11].该算法的突出特点是将具有不确定性归属关系的数据对象划分到多个类簇的边界区域,但忽视了这些交叉边界区域数据对象关于类簇中心迭代的不同贡献程度,为此,Mitra[12]在RKM算法的基础上引入了模糊度量,根据数据样本与簇心的距离计算样本归属于不同类簇的隶属度,提出了粗糙模糊K-means(RFKM)算法. Maji[13]则认为位于下近似集的数据样本有明确的隶属关系,在RFKM算法的基础上,将类簇下近似集中的数据样本隶属度直接设置为1,主要针对边界区域数据样本的模糊隶属程度进行度量,提出了另外一种粗糙模糊K-means算法. Arabegum进一步在粗糙模糊K-means聚类算法中引入了2型模糊度量,提出了基于2型模糊集的RT2FKM算法[14].
上述文献通过结合粗糙集和模糊集的优势互补,形成了系列较为有效的粗糙模糊K-means聚类算法.但现有RFKM算法更多的是关注数据样本的空间分布,尤其是边界区域不确定性信息的度量,并没有考虑类簇规模的不均衡性.而在实际的工程应用中,针对故障诊断、异常信号检测等特定应用需求的海量不均衡数据越来越普遍,处理不当将会使少数类类簇的中心点向多数类类簇偏移,导致边界区域的多数类类簇样本被错误地划分至少数类类簇.如何更加有效地对类簇规模不均衡的数据进行聚类分析处理已经成为当前的研究热点[15-18].实际上,类簇规模不均衡问题的聚类分析并不是一个新的研究课题,但以往的研究主要是采用数据预处理的方法将不均衡的数据转换为大致均衡的数据之后再进行聚类分析[19-22]. Chawla基于“插值”的思想提出了“smote过采样”算法[19],利用少数类类簇的数据样本不断插值生成新的数据样本,以增加少数类类簇的规模;Barandela等人提出“欠采样”算法[20],通过对多数类类簇样本进行随机挑选,减少部分多数类类簇的样本,以降低类簇规模的不均衡度.采用采样等数据预处理的方法虽然可以有效解决类簇规模的不均衡性问题,但这些方法不可避免地会导致数据的过拟合或信息的丢失[21-22].
针对上述问题,为了能够从算法层面更加有效地对类簇规模不均衡的数据进行聚类分析,首先提出一种类簇规模不均衡度量的方法,将类簇规模不均衡程度的度量融入模糊隶属度的计算,以便区分边界区域的数据样本对于少数类类簇和多数类类簇的隶属度,在此基础上,提出一种基于类簇规模不均衡度量的粗糙模糊K-means聚类算法.最后利用人工数据集和UCI标准数据集对不同算法的执行结果进行对比,验证本文算法的有效性.
1 粗糙模糊K-means聚类算法 1.1 经典粗糙K-means算法Lingras等学者提出的粗糙K-means(RKM)聚类算法[11]将每一个类簇看成一个粗糙集,把能够确定归属于一个类簇的数据样本划分到该类簇相应的下近似集,而将具有不确定归属关系的数据样本划分到两个或以上类簇的边界集.算法的步骤如下:
Step 1 初始化类簇Ci(i=1,2…k)的聚类中心vi、类簇个数k、距离判断阈值ζ、上下近似加权系数ωl和ωb.
Step 2 计算每个数据样本与类簇中心的欧氏距离,并根据距离将每个对象划分至对应类簇的下近似集 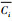
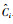
Step 3 据如下公式更新类簇的中心点.
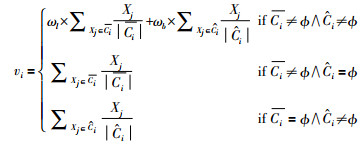
|
(1) |
Step 4 若类簇中心不再发生变化,则算法终止,并输出结果,否则返回Step 2重新进行迭代计算.
1.2 粗糙模糊K-means算法粗糙K-means算法,在处理下近似集和边界集数据时,忽略了同一集合内样本的差异性.学者Mitra将模糊理论引入粗糙K-means算法,提出了粗糙模糊K-means(RFKM)算法[12],利用数据样本与类簇中心的距离计算数据样本归属于不同类簇的隶属度,描述不同的数据样本对于类簇中心迭代计算的不同贡献度.隶属度计算公式如下.
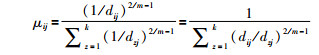
|
(2) |
其中,μij是样本Xj对于第i个类簇的隶属度;dij是样本Xj与簇心vi的欧氏距离;m是模糊系数;k是聚类的类簇个数.
学者Maji认为处于下近似集的样本有明确的隶属关系[13],提出了如下式(3)所示的隶属度量.
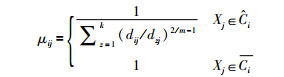
|
(3) |
为了能够更好地描述边界区域数据样本的不确定信息,Arabegum和Devi引入了如下公式(4)所描述的2-型模糊度量,对RFKM算法进行进一步扩展,提出了Rough Type-2 Fuzzy K-means (RT2FKM)算法[14].
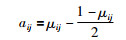
|
(4) |
式中,μij为式(3)计算得到的1-型模糊隶属度.
上述算法均采用如下的式(5)对聚类中心进行迭代计算.
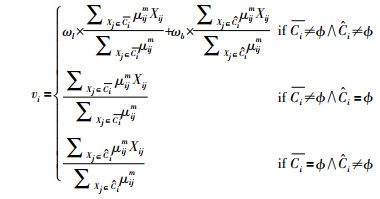
|
(5) |
从隶属度的计算及中心均值的迭代公式可以看出,粗糙模糊K-means算法一方面将具有明确归属关系的数据对象划分到类簇的下近似集,将具有不确定性归属关系的数据对象划分到边界区域,另一方面再通过模糊关系对边界区域的数据对象进一步进行差异性度量,较好地综合了粗糙集和模糊集的优势互补.但从不确定边界区域的划分以及模糊关系的度量也可以看出,传统粗糙模糊K-means主要聚焦于对簇内不确定性信息的描述与处理,而忽略了类簇规模不均衡的影响.
为便于分析,图 1给出了两个规模不均衡的交叉类簇,v1和v2分别是少数类类簇C1和多数类类簇C2的簇心.在边界区域中,蓝色的“o”表示原本应该归属于少数类的数据样本,红色的“□”表示原本应该归属于多数类的数据样本.

|
| 图 1 类簇不均衡示例 Fig.1 Example of imbalanced clusters |
从图 1可以看出,对于边界区域中的绝大多数数据样本来说,与C1类簇中心v1距离d1均要小于与C2类簇中心v2距离d2,即d1 < d2,根据常规的模糊度量,边界区域中的数据样本归属于类簇C1的隶属度要远大于归属于类簇C2的隶属度.另一方面,从类簇的迭代计算式(5)可以看出,类簇中心点的位置取决于下近似均值和上近似均值的加权求和,由于边界区域中包含了一定数量的、原本应该归属于类簇C2的数据样本,而这些数据对象参与类簇C1的中心均值迭代计算的贡献度却更大,使得类簇C1的中心点向类簇C2发生偏移,两个类簇的不均衡程度越大,交叉边界区域的数据对象越多,这种偏移就越严重,最终导致在后续的迭代计算中将更多的原本属于类簇C2的数据样本划分到边界区域,甚至错误地划分到少数类类簇C1的下近似区域,严重影响了聚类分析的精度.
针对上述问题,首先提出一种类簇规模不均衡的度量方法.由于上近似集包含了所有可能归属于该类簇的数据样本,一定程度上描述了类簇的规模大小,对于边界区域的数据对象Xj,可以采用如下的公式对类簇规模的不均衡程度进行度量.
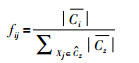
|
(6) |
其中,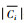
在粗糙模糊K-means算法中,边界区域数据样本对类簇中心迭代计算的贡献大小是通过模糊隶属度量来进行描述的,为了能够在类簇中心点的迭代过程中体现类簇规模的不均衡程度,将式(6)融入隶属度的计算式(3),设计了如式(7)所示的考虑类簇规模不均衡度量的模糊隶属度计算方法.
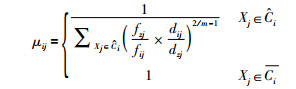
|
(7) |
对比式(7)和式(3),本文的隶属度计算不但考虑了类簇规模不均衡的度量,而且对于边界区域的数据对象Xj,也不再考虑Xj到所有类簇的距离度量,而是通过
下面结合图 1进一步分析考虑类簇规模不均衡程度的模糊隶属度计算方法的合理性和优越性.
若不考虑类簇规模的不均衡度量,则边界区域数据样本Xj对于类簇C1和类簇C2的隶属度分别为μ1j和μ2j.
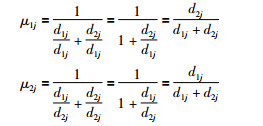
|
其中,μ1j+μ2j=1.
考虑类簇规模的不均衡程度度量,边界区域的数据样本Xj对于类簇C1和C2的隶属度分别为μ′1j和μ′2j.
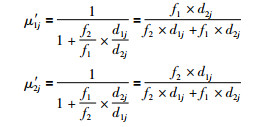
|
显然,μ′1j+μ′2j=1依然满足模糊隶属度量的要求.
比较μ1j和μ′1j可以发现,未考虑类簇规模不均衡度量的μ1j取值大小仅与边界区域的数据样本和类簇中心的距离有关,距离相对越小则隶属度越大,该数据样本在类簇中心点迭代计算中的贡献度也就越大.针对图 1中的示例,由于,d1j < d2j,使得原本归属于类簇C2的数据样本却更大程度上参与类簇C1的中心均值计算,导致类簇C1的中心点向类簇C2进行偏移.而在考虑类簇规模不均衡度量之后,隶属度μ′1j的大小就不再是仅仅由数据样本和类簇中心点的距离决定,还同时综合考虑了不同类簇的规模大小.
从μ′1j的计算公式看出,虽然d1j < d2j,但由于加入了类簇规模的不均衡度量,并且f1j < f2j,使得μ′1j < μ1j,结合式(6)和式(7)可以看出,类簇规模的不均衡程度越大,对边界区域数据样本属于交叉类簇C1和C2的隶属度量调整力度越大,这种调整,较大程度上降低了边界区域含有多数类类簇C2的数据样本对于少数类类簇C1中心点均值计算的贡献度,从而减小了类簇规模的不均衡对类簇C1中心点的不利影响.
2.2 基于类簇规模不均衡度量的改进RFKM算法从类簇中心的迭代计算式(5)可以看出,若类簇规模不均衡程度较严重,对于少数类类簇来说,边界区域数据样本的均值占比相对偏大,而对于多数类类簇来说,边界区域数据样本的均值占比相对偏小.为了减弱中心迭代公式的这种影响,本文采用如式(8)所示的类簇中心均值迭代计算公式.
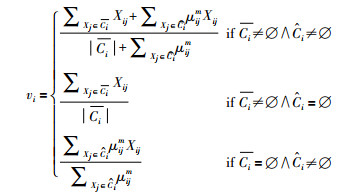
|
(8) |
结合上述类簇规模的不均衡度量以及类簇中心均值的迭代计算公式,进一步给出如下的基于类簇规模不均衡度量的改进粗糙模糊K-means算法,算法的执行步骤如下.
输入:数据集U:U={Xz|z=1,…,N}.
输出:将数据对象集合U划分为k个类簇.
算法执行步骤:
Step 1 类簇个数k;初始化聚类中心vi;距离判断阈值ζ;模糊系数m.
Step 2 对每个对象Xz,计算Xz到各个类簇中心点vi的欧式距离dij.选择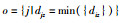
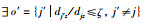
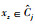
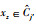
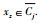
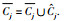
Step 3 计算每个类簇上近似集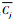
Step 4 若类簇不再发生变化,则算法终止,否则返回Step 2.
上述算法在迭代过程中可以根据数据样本划分到不同类簇的变化对类簇规模进行自适应度量,并对边界区域数据对象参与所属交叉类簇中心点计算的贡献度进行调整,减小了类簇规模不均衡对少数类类簇的不利影响.
另一方面,当类簇规模大致均衡时,比如图 1的示例,当两个类簇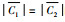
在分析类簇规模不均衡的数据集时,人们往往更加关注少数类类簇的数据.例如,若把电网的异常状态判为正常状态,将可能导致故障蔓延引发大停电事故;若把网络攻击行为判为正常的网络行为,将可能导致重大网络安全事故.因此,保持少数类类簇的原始样本分布,减少少数类类簇信息流失成了判断算法优劣的重要指标.为了更好地展示算法能否最大程度地保留少数类类簇的信息,结合传统模糊聚类的评价指标,本文设计如下5个指标.
OK:位于类簇下近似且聚类正确的样本个数(越大越好).
Err+:多数类类簇样本被错误划分至少数类类簇下近似集的样本个数(越小越好).
Err-:少数类类簇样本被错误划分至多数类类簇下近似集的样本个数(越小越好).
Bd:位于边界区域中样本个数(越小越好).
Bd-:边界区域少数类类簇的样本个数(越小越好).
下面分别用人工数据集和UCI (University of California Irvine Machine Learning Repository)标准数据集对本文的算法进行验证.
3.1 人工数据集为验证本文算法的聚类效果,用随机正态分布的方法创建规模不同的两个类簇,分别包含80和200个样本,类簇不均衡比为1:2.5,如图 2所示.

|
| 图 2 人工数据集分布 Fig.2 Artificial dataset distribution |
用RFKM[12]、Maji改进RFKM[13]和RT2FKM算法[14],进行对比实验.为了保证对比实验的公平,所有对比算法均采用相同的初始聚类中心v0、模糊指数(m=2)、距离判断阈值(ζ=1.4).按照设计的5个聚类效果评判指标,记录所有算法的实验结果,如表 1所示.
| 指标 | RFKM | Maji版RFKM | RT2FKM | 本文算法 |
| OK | 215 | 223 | 246 | 259 |
| Err+ | 28 | 17 | 8 | 3 |
| Err- | 0 | 0 | 0 | 0 |
| Bd | 37 | 40 | 26 | 18 |
| Bd- | 0 | 0 | 0 | 2 |
图 3至图 6分别给出了RFKM、Maji改进的RFKM、RT2FKM和本文算法在人工数据集下的聚类结果.图中,黑色的“☆”代表类簇簇心;蓝色的“o”表示位于少数类类簇下近似集且聚类正确的样本,红色的“o”表示错误地聚类到少数类类簇下近似集的多数类类簇样本;蓝色的“*”表示位于多数类类簇下近似集且聚类正确的样本,红色的“*”表示错误地聚类到多数类类簇的少数类类簇样本;蓝色的“□”表示被位于边界区域的少数类类簇样本;蓝色的“△”表示位于边界区域的多数类类簇样本.

|
| 图 3 RFKM聚类结果 Fig.3 Clustering results of RFKM |

|
| 图 4 Maji改进的RFKM聚类结果 Fig.4 Clustering results of Maji′s improved RFKM |

|
| 图 5 RT2FKM聚类结果 Fig.5 Clustering results of RT2FKM |

|
| 图 6 本文算法的聚类结果 Fig.6 Clustering results of proposed algorithm |
对比图 3至图 6所有算法类簇中心点位置可以发现,相较于其它算法,本文所设计的算法可以保持少数类类簇的中心点在相对较合理的位置,而其它几个算法执行结果的类簇中心点均发生了较为明显的偏移,甚至脱离少数类类簇进入了多数类类簇的范围.由于人工数据集不均衡度较大,大量多数类类簇样本渗透进少数类类簇区域,四种算法的聚类结果都呈现出多数类类簇样本被错误聚类到少数类类簇下近似集、极个别少数类类簇样本被误分到多数类类簇的情况.
为了能够更加直观地展示算法的整体聚类精度以及算法对少数类类簇信息的保留率,本文进一步定义下面2个指标.
OK%:数据集整体的聚类精度(越大越好).
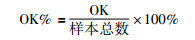
|
PR%:少数类数据信息的综合污染率(越小越好).
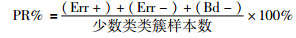
|
根据以上指标,记录本文算法及各比较算法的结果如表 2和图 7所示.
| 指标 | RFKM | Maji版RFKM | RT2FKM | 本文算法 |
| OK% | 76.7% | 79.6% | 87.8% | 92.5% |
| PR% | 35% | 21.3% | 10% | 6.3% |

|
| 图 7 算法聚类的指标结果对比 Fig.7 Comparison of clustering ind icators of each algorithm |
从上述表 2和图 7可以看出,由于本文算法在原有考虑样本空间分布的基础上,加入了对类簇规模不均衡的度量,使得少数类的类簇中心能够保持在合理位置,相较于其它算法,少数类类簇的样本信息综合污染率最低,较好地保留了少数类类簇的样本信息,同时整体聚类精度最高.
3.2 UCI标准数据集选取Credit Approval、Pima Indians Diabetes(PID)、SPECT Heart、Glass、User Knowledge Modeling、Seeds和Breast Cancer七个UCI标准数据集进行对比实验,每一个数据集的详细信息如下.
Credit Approval数据集:含有690个信用卡批准数据样本,其中第一类307个样本作为少数类,第二类383个样本作为多数类,形成不均衡度较低的数据集.
Pima Indians Diabetes(PID)数据集:268个阴性糖尿病数据作为少数类样本,500个阳性糖尿病数据作为多数类样本.
SPECT Heart数据集:包含267个心脏单个质子发射计算机断层显像的样本数据,其中55个不正常的病人数据作为少数类,212个正常的病人数据作为多数类.
Glass数据集:17个采用非浮法制作构成少数类样本;70个使用浮法制作构成多数类样本.
User Knowledge Modeling数据集:包含4类数据,取Very_Low的样本作为少数类样本,Middle和High作为多数类样本.
Seeds数据集:包含3类,每类有70个样本,取第二类种子的20个样本作为少数类,其余作为多数类样本.
Breast Cancer数据集:首先对数据进行清洗,删除有缺省的数据.最终选取恶性肿瘤数据50个,良性肿瘤数据357个,形成不均衡数据集.
按不均衡度由小到大的规则将上述7个数据集进行排序,其基本信息如表 3所示.
| 数据集 | 样本总数 | 少数类样本数 | 多数类样本数 | 不均衡度 |
| Credit | 690 | 307 | 383 | 1:1.2 |
| PID | 768 | 268 | 500 | 1:1.9 |
| SPECT | 267 | 55 | 212 | 1:3.9 |
| Glass | 87 | 17 | 70 | 1:4.1 |
| User | 273 | 49 | 224 | 1:4.6 |
| Seeds | 160 | 20 | 140 | 1:7.0 |
| Breast | 407 | 50 | 357 | 1:7.1 |
结合前面定义的5个聚类效果评价指标,记录UCI标准数据集下各算法的聚类结果和相应的聚类指标,分别如表 4和表 5所示.另外,为了更进一步地进行对比分析,记录表 4中各算法得到聚类结果的计算时间,如表 6所示.
| 数据集 | 指标 | RFKM | Maji改进RFKM | RT2FKM | 本文算法 |
| Credit Approval | OK | 485 | 514 | 507 | 496 |
| Err+ | 29 | 23 | 16 | 22 | |
| Err- | 16 | 12 | 14 | 14 | |
| Bd | 85 | 96 | 88 | 76 | |
| Bd- | 30 | 17 | 28 | 14 | |
| PID | OK | 523 | 617 | 581 | 598 |
| Err+ | 38 | 29 | 21 | 13 | |
| Err- | 14 | 15 | 16 | 11 | |
| Bd | 219 | 198 | 203 | 176 | |
| Bd- | 22 | 16 | 12 | 21 | |
| SPECT Heart | OK | 140 | 196 | 203 | 231 |
| Err+ | 13 | 8 | 7 | 4 | |
| Err- | 2 | 0 | 1 | 0 | |
| Bd | 98 | 91 | 86 | 33 | |
| Bd- | 2 | 1 | 0 | 1 | |
| Glass | OK | 63 | 76 | 74 | 84 |
| Err+ | 0 | 0 | 0 | 0 | |
| Err- | 0 | 0 | 0 | 0 | |
| Bd | 24 | 11 | 13 | 3 | |
| Bd- | 1 | 1 | 2 | 1 | |
| User Knowledge Modeling | OK | 150 | 231 | 224 | 250 |
| Err+ | 26 | 4 | 3 | 1 | |
| Err- | 0 | 0 | 0 | 0 | |
| Bd | 97 | 38 | 46 | 22 | |
| Bd- | 0 | 0 | 0 | 0 | |
| Seeds | OK | 105 | 110 | 108 | 139 |
| Err+ | 33 | 27 | 28 | 4 | |
| Err- | 0 | 0 | 0 | 0 | |
| Bd | 22 | 23 | 24 | 17 | |
| Bd- | 0 | 0 | 0 | 0 | |
| Breast Cancer | OK | 302 | 377 | 375 | 383 |
| Err+ | 38 | 7 | 4 | 3 | |
| Err- | 1 | 5 | 5 | 3 | |
| Bd | 66 | 18 | 23 | 18 | |
| Bd- | 3 | 4 | 4 | 4 |
| 数据集 | 指标 | RFKM | Maji改进RFKM | RT2FKM | 本文算法 |
| Credit Approval | OK% | 70.29% | 74.49% | 73.48% | 71.88% |
| PR% | 23.19% | 17.92% | 15.64% | 16.27% | |
| PID | OK% | 68.10% | 80.34% | 75.65% | 77.86% |
| PR% | 27.61% | 22.39% | 18.28% | 16.79% | |
| SPECT Heart | OK% | 52.43% | 73.41% | 76.03% | 86.52% |
| PR% | 30.91% | 16.36% | 14.55% | 9.10% | |
| Glass | OK% | 72.41% | 87.36% | 85.06% | 96.55% |
| PR% | 5.88% | 5.88% | 11.76% | 5.88% | |
| User Knowledge Modeling | OK% | 54.95% | 84.62% | 82.05% | 91.58% |
| PR% | 53.06% | 8.16% | 6.12% | 2.04% | |
| Seeds | OK% | 65.63% | 68.75% | 67.5% | 86.88% |
| PR% | 165% | 135% | 149% | 20% | |
| Breast Cancer | OK% | 74.2% | 92.63% | 92.14% | 94.1% |
| PR% | 84% | 34% | 26% | 20% |
| 数据集 | 计算时间/s | |||
| RFKM | Maji改进RFKM | RT2FKM | 本文算法 | |
| Credit Approval | 2.055 6 | 1.766 4 | 2.471 1 | 1.897 8 |
| PID | 1.781 7 | 1.543 4 | 2.071 1 | 1.765 8 |
| SPECT Heart | 1.768 4 | 1.489 7 | 1.998 8 | 1.507 9 |
| Glass | 0.473 9 | 0.426 1 | 0.582 5 | 0.445 3 |
| User Knowledge Modeling | 1.472 3 | 1.378 4 | 1.675 3 | 1.487 2 |
| Seeds | 0.832 7 | 0.801 7 | 0.912 3 | 0.825 1 |
| Breast Cancer | 1.376 2 | 1.298 1 | 1.452 6 | 1.307 2 |
从上述表 4和表 5的结果可以看出,当不均衡度较低时,本文算法并没有展现出最理想的改进聚类结果,但是随着UCI数据集不均衡度的增加,本文算法相较于其他算法逐渐呈现出优异的聚类性能.对于Glass数据集,本文算法可以在少数类类簇信息综合污染率最低的基础上,取得96.55%的整体聚类精度;对于其它几个数据集,本文算法在整体聚类精度和保留少数类类簇信息这些指标上均取得了较好的效果.
为了消除实验的偶然误差,表 6中的计算时间都是基于5次重复试验的平均值.由于Maji版RFKM算法只需计算下近似区域样本的模糊隶属度,从而计算时间比经典RFKM算法短. RT2FKM算法将一型模糊隶属度函数扩展为二型模糊隶属度函数,并在运行过程中采用降型法简化计算复杂度,因此它的计算时间比前两种算法长.本文算法在Maji版RFKM算法的基础上将类簇规模不均衡度量融入数据样本归属于不同类簇的隶属度计算,所需计算时间略低于经典RFKM算法,且随着类簇不均衡度的提高,本文算法的聚类性能相较于其他算法显著提高.
人工数据集和UCI数据集的实验结果证明,将类簇规模不均衡度融入数据样本归属于不同类簇的隶属度计算,可以减小类簇规模不均衡对聚类效果的影响,能使小规模类簇的中心点保持在相对合理的位置,最大可能地避免算法将更多的原本归属于多数类类簇的样本错误地聚类到少数类类簇的情况,较好地保留少数类类簇的信息,并且不需要太多的计算时间.
4 结论类簇规模不均衡导致少数类类簇的中心点在迭代计算过程中向多数类类簇偏移,影响聚类精度.针对这一问题,本文在粗糙模糊K-means算法的基础上,设计了一种新的基于类簇规模不均衡度量的隶属度计算方法,将类簇规模不平衡程度作为动态调整权值,融入到隶属度每一次的更新迭代计算中,并在此基础上提出了基于类簇规模不均衡度量的粗糙模糊K-means聚类算法,提高了类簇规模不均衡数据集的聚类精度.
如何针对不同的应用场景,综合考虑不同的影响因素,对类簇规模的不均衡性进一步进行综合有效度量,提高算法的适应性和聚类效果将是下一步研究的重点.
| [1] | Hartigan J.A, Wong M A. Algorithm as 136:A K-means clustering algorithm[J]. Journal of the Royal Statistical Society, 1979, 28(1): 100–108. |
| [2] |
张建朋, 陈福才, 李邵梅, 等.
基于密度与近邻传播的数据流聚类算法[J]. 自动化学报, 2014, 40(2): 277–288.
Zhang J P, Chen F C, Li S M, et al. Data stream clustering algorithm based on density and affinity propagation techniques[J]. Acta Automatica Sinica, 2014, 40(2): 277–288. |
| [3] | Peters G. Rough clustering utilizing the principle of indifference[J]. Information Sciences, 2014, 277(2): 358–374. |
| [4] |
庞宁, 张继福, 秦啸.
一种基于多属性权重的分类数据子空间聚类算法[J]. 自动化学报, 2018, 44(3): 517–532.
Pang N, Zhang J F, Qin X. A subspace clustering algorithm of categorical data using multiple attribute weights[J]. Acta Automatica Sinica, 2018, 44(3): 517–532. |
| [5] | Zhang T, Chen L, Ma F. A modified rough c-means clustering algorithm based on hybrid imbalanced measure of distance and density[J]. International Journal of Approximate Reasoning, 2014, 55(8): 1805–1818. |
| [6] |
张腾飞, 陈龙, 李云.
基于簇内不平衡度量的粗糙K-means聚类算法[J]. 控制与决策, 2013, 28(10): 1479–1484.
Zhang T F, Chen L, Li Y. Rough K-means clustering based on unbalanced degree of cluster[J]. Control and Decision, 2013, 28(10): 1479–1484. |
| [7] | Han J, Kamber M. Data mining, concepts and techniques[M]. 3rd ed. San Francisco, CA, USA: Morgan Kaufmann Publishers, 2011. |
| [8] | Peters G, Crespo F, Lingras P, et al. Soft clustering-fuzzy and rough approaches and their extensions and derivatives[J]. International Journal of Approximate Reasoning, 2013, 54(2): 307–322. |
| [9] |
马福民, 逯瑞强, 张腾飞.
基于边界区域局部模糊增强的πRKM聚类算法[J]. 控制与决策, 2017, 32(11): 1949–1956.
Ma F M, Lu R Q, Zhang T F. Improved πRKM clustering algorithm based on local fuzzy enhancement of boundary region[J]. Control and Decision, 2017, 32(11): 1949–1956. |
| [10] |
逯瑞强, 马福民, 张腾飞.
基于区间2-型模糊度量的粗糙K-means聚类算法[J]. 模式识别与人工智能, 2018, 31(3): 265–274.
Lu R Q, Ma F M, Zhang T F. Interval type-2 fuzzy measure based rough K-means clustering[J]. Pattern Recognition and Artificial Intelligence, 2018, 31(3): 265–274. |
| [11] | Lingas P, West C. Interval set clustering of web users with rough K-means[J]. Journal of Intelligent Information Systems, 2004, 23(1): 5–16. |
| [12] | Mitra S, Banka H, Pedrycz W. Rough fuzzy collaborative clustering[J]. IEEE Transactions on systems Man and Cybernetics, Part B, 2006, 36(4): 795–805. |
| [13] | Maji P, Pal S K. RFCM:A hybrid clustering algorithm using rough and fuzzy sets[J]. Fundamenta Informaticae, 2007, 80(4): 475–496. |
| [14] | Arabegum J P, Mema Devi O. A rough type-2 fuzzy clustering algorithm for MR image segmentation[J]. International Journal of Computer Applications, 2012, 54(4): 4–11. |
| [15] | He H, Garcia E A. Learning from imbalanced data[J]. IEEE Transactions on Knowledge and Data Engineering, 2009, 21(9): 1263–1284. |
| [16] | Liu Y, Hou T, Liu F. Improving fuzzy c-means method for unbalanced dataset[J]. Electronics Letters, 2015, 51(23): 1880–1882. |
| [17] | Aksoylar C, Qian J, Saligrama V. Clustering and community detection with imbalanced clusters[J]. IEEE Transactions on Signal & Information Processing over Networks, 2017, 3(1): 61–76. |
| [18] | Ofek N, Rokach L, Stern R, et al. Fast-CBUS:A fast clustering-based undersampling method for addressing the class imbalance problem[J]. Neurocomputing, 2017, 243: 88–102. |
| [19] | Chawla N V, Bowyer K W, Hall L O, et al. SMOTE:Synthetic minority over-sampling technique[J]. Journal of Artificial Intelligence Research, 2002, 16(1): 321–357. |
| [20] | Barandela R, Valdovinos R M, Sánchez J S, et al. The imbalanced training sample problem:Under or over sampling?[J]. Lecture Notes in Computer Science, 2004. |
| [21] | Douzas G, Bacao F. Self-organizing map oversampling (SOMO) for imbalanced data set learning[J]. Expert Systems with Applications, 2017, 82: 40–52. |
| [22] | Zheng Z, Cai Y, Li Y. Oversampling method for imbalanced classification[J]. Computing & Informatics, 2016, 34(5): 1017–1037. |