



0 引言
如何通过对外在事物的观察和处理,来把握其内在规律,进而实现对未来事物的预测,指导人类活动,是一项非常有价值且难度大的研究课题,多年来一直受到学者们的关注.特别是近几年随着深度学习技术的发展,基于深度学习的各种预测方法层出不穷,在网约车供需缺口短时预测、安全缺陷报告预测、磨矿系统故障诊断、城市交通态势预测、薄板冷轧颤振预报等方面得到较成功应用[1-5].其中,卷积神经网络因其卷积核可以有效地对输入数据如图像、视频等中的局部结构进行学习和处理,通过级联的卷积层逐步提取到输入数据的表层结构与内在的语义信息,由此构成的深度神经网络在处理视觉任务上效果明显[6-7].
与图像相比,因视频多了时间维度,视频不仅具有空域相关性,也存在很强的时域相关性,视频数据量的爆炸式增长使其已经成为网络大数据的主体,思科公司预测,到2022年全球网络视频数据量将占全部网络数据流量的82%[8],视频预测成为人工智能领域的研究热点,不断涌现出大量预测算法[9].现有的主流视频预测方法[10-15],多是基于卷积神经网络与循环神经网络开展的,首先通过卷积神经网络提取图像序列中的空间结构,然后再通过循环神经网络(RNN)或长短时记忆网络(LSTM)来提取这些特征的时序信息,并最后实现预测.其中,Srivastava[10]提出用LSTM处理视频预测任务的基本框架FcLSTM,即采用两个LSTM分别作为编码器和解码器,通过对给定输入视频序列先编码、再解码的方式生成预测序列. Shi等[11-12]在前人研究基础上,提出了ConvLSTM和TrajGRU方法,并将其用于视频预测算法中,形成了视频预测方法的基本框架. Wang等[13-15]针对时空序列预测问题,提出了采用STLSTM的PredRNN,通过分别对序列中的时序记忆和空间记忆进行处理,很好地解决了视频预测问题,并提出PredRNN++与MIM等改进版本.
然而,实际任务中经常面对没有明显局部近邻结构、甚至稀疏的数据.对于这样的数据,卷积神经网络的处理往往难以奏效.这些看似杂乱无序的局部结构对卷积核产生极大干扰,使卷积神经网络失去作用.视频预测任务中,这种情况尤为突出.这类问题被称为无局部结构矩阵序列预测问题,即以一些局部结构丢失的矩阵序列作为输入,来预测未来时刻的矩阵序列.通常情况,这种局部结构的丢失来源于数据观测.大多数情况下,数据的整体结构很难被完整观测,现实中得到的数据往往是原始数据的一种采样.无局部结构矩阵序列数据中广泛存在着全局依赖如图 1所示,局部结构并不明显,如何从这些无局部结构的观测数据学习到其内在变化特征,从而对整体数据进行预测,是一个重要且具有挑战性的问题.
为解决上述问题,本文构建了一种无局部结构矩阵预测网络(Ordinary Matrix Prediction Network,OMPNet),提出一种专门用于处理图像、视频等高维数据的线性运算模块、对偶线性连接(dual linearized connecting,DLC),实现对广泛存在于无结构矩阵序列中的全局依赖和长时依赖(如图 1)进行提取和学习,有效地生成预测结果.

|
| 图 1 无局部结构矩阵序列全局依赖现象 Fig.1 Global dependence phenomenon of ordinary matrix sequence |
视频预测任务即是通过对历史视频序列分析,学习到其中的变化规律,包括空间上图像的变化趋势以及时域上的长时依赖,从而预测出未来时刻的视频序列.通常,一段视频序列由数个视频帧组成,每个视频帧都是一副图像,这些连续的多段图像组成了一段视频.因此对于一段视频序列不仅在每一帧中蕴含着空间结构信息,同时帧与帧之间存在着时序上的关联信息.因此,如何同时提取这些空间特征和时序特征,是视频预测问题的一个难题.
目前主流视频预测算法,是基于ConvLSTM的LSTM类神经网络算法. ConvLSTM相比于传统的RNN和LSTM,其主要特点在于广泛地采用了卷积操作,通过卷积操作捕捉空间特征,实现对视频序列中的空间结构信息进行有效提取.在获得空间信息后,经LSTM处理这些存在时间上关联的时序信息,进而提取给定视频序列中的空间和时序信息,该方法生成的视频预测结果比传统的单一LSTM方法效果有了明显提升[12]. PredRNN、PredRNN++等方法[13-15]是基于ConvLSTM提出的部分改进算法,更有效地解决了视频预测任务,因此成为目前视频预测的基准方法.另外,针对视频序列中帧与帧之间的差值,Villegas等[16]提出了MCNet算法,即对视频序列中帧与帧之间的差值进行计算和学习,认为这些差值之间蕴含的特征为运动特征(motion),而输入序列中最后一帧蕴含内容特征(content),网络对运动特征和内容特征的处理,实现了对未来视频的预测. Qiu等[17]对其进行了改进提出了HPNet算法.
1.2 全局依赖对于矩阵中的某给定位置,与其发生关联的位置并非总在该位置的近邻,这些非局部近邻的像素之间存在着关系和依赖,即为全局依赖.如何有效学习和提取数据中存在的全局依赖一直是计算机视觉研究领域的一个难点问题.目前解决该问题多采用卷积神经网络,其原因在于卷积核对于输入的图像类数据中存在的局部结构能够进行有效地提取和学习.然而,当给定输入数据中存在大量全局依赖或长距离依赖,卷积核难以对其进行有效地学习.为解决上述问题,Simonyan[18]在VGG中给出了解决方案,通过堆叠小型的3×3卷积核,来获得更大的感受野.相比于直接采用11×11等大型卷积核,该方法占用内存少、效果好.为了改善卷积核感受野局限无法处理全局依赖的问题,Yu[19]提出了空洞卷积操作.相比与传统卷积运算,空洞卷积并不对给定像素的局部领域进行计算,而是对一些空洞以外的像素进行加权计算,改善了传统卷积操作感受野过小的问题,对处理数据中的全局依赖有一定改善和帮助.
另外,受到传统计算机视觉中Non-Local Mean的启发,Wang[20]提出了Non-Local算法,设计了专门处理全局依赖的网络结构,可以有效地提取视频序列中的全局依赖和长时长距离依赖,对视频分类等任务十分有效.然而,因Non-Local拥有计算量过大,占用内存多等弊端,还难以应用于视频预测任务.
2 无局部结构矩阵预测网络 2.1 网络总体结构为解决数据中蕴含的全局依赖难以通过卷积操作对其进行学习与提取的难题,本文提出了无局部结构矩阵预测网络OMPNet,其整体框架如图 2所示,该网络通过本文提出的一种新型线性操作、对偶线性连接DLC,实现对无局部结构矩阵序列的预测.

|
| 图 2 OMPNet整体框架图 Fig.2 OMPNet overall frame diagram |
借助对偶线性连接,无局部结构矩阵预测网络可以通过LSTM对给定数据中存在的全局依赖进行有效学习和处理,获得其底层特征,实现对无局部结构矩阵序列的预测.
2.2 对偶线性连接针对图像数据中存在着大量全局依赖和长距离依赖的特点,提出了对偶线性连接,其主要过程表示为
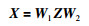
|
(1) |
式(1)中,Z为给定的输入矩阵,X为输入数据经过对偶线性连接操作之后的输出结果,W1、W2为两个可学习的参数矩阵.经过式(1)对偶线性连接计算,输入矩阵中的任一位置,均和矩阵中其余全部位置进行线性运算,即所有像素之间的关系均通过网络计算生成特征图,该特征图包含任一位置与其余全部位置的关系.通过对偶线性连接,网络即可自适应地学习位置与位置之间的全局关系,获得给定输入矩阵的空间特征,即对偶线性连接层输出的空间位置关系编码矩阵.其操作示意图如图 3所示,输入矩阵经过两个参数矩阵W1、W2的编码与特征学习,得到了计算后的特征图.

|
| 图 3 DLC操作示意图 Fig.3 DLC operation diagram |
相比于卷积神经网络,对偶线性连接可以获得输入矩阵中任意位置之间的关系,包括任意近邻关系以及全局依赖;相比于传统的全连接层(fully connected layer),对偶线性连接为线性结构,不仅消耗的计算资源少,而且所占用内存也少,训练时网络更新参数量也相应降低,能够有效地改善全连接层存在的参数量过大、容易出现过拟合问题.
传统的全连接层的运算过程为
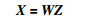
|
(2) |
其中,Z为输入,X为全连接层的输出,W为全连接层的参数矩阵.
采用对偶线性连接,则:
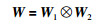
|
(3) |
其中,⊗为Kronecker积,即采用对偶线性连接将传统全连接层中的参数矩阵W分解为两个参数量较小的参数矩阵W1和W2的线性组合,网络通过对两个子参数矩阵W1、W2进行梯度传播与优化,代替了对原始的参数量巨大的参数矩阵W进行学习,减小了梯度反向传播难度,减轻了网络学习时参数矩阵的互相遏制现象.从张量表示的角度可以发现,相比于传统的全连接层,对偶线性连接其实是通过kronecker积,实现了对传统全连接层中参数矩阵的分解,使网络通过梯度传播无需优化更新原有的过冗余参数矩阵,只需更新两个参数矩阵W1和W2,实现了参数量减少、梯度传播难度降低的功能,因此,提出的对偶线性连接减弱了全连接神经网络的梯度消失现象,有利于网络加深,学习到数据中蕴含的更深层次的内在特征.这也是所提出的对偶线性连接优越于传统的线性连接和全连接层的原因所在.
2.3 基于LSTM的预测经过对偶线性连接获得了任意输入帧中每一个位置的全局依赖,即空间位置关系编码矩阵,采用LSTM获得这些空间位置关系之间的时序关系,即帧与帧之间在时域上的联系,得到时序关系,生成预测结果.由于此时得到的空间位置关系编码矩阵同样具有无局部结构的特点,本文采用LSTM对其进行预测. LSTM是RNN的一种特殊形式,由Schmiduber提出,用来解决RNN难以处理长时依赖的问题.区别于一般的RNN,LSTM引入了门控机制与细胞记忆状态,其中,门控机制决定了给定输入和历史信息的通过,从而产生有着不同历史数据记忆的细胞状态.输入进入LSTM的数据,通过由参数矩阵和激活函数组成的门控,得到了有选择的自适应学习.
采用了对偶线性连接的LSTM结构的主要运算过程如下所示:
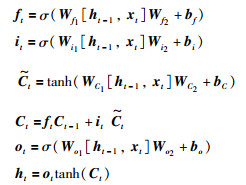
|
(4) |
式(4)中,ft为遗忘门,it为输入门,Ct为细胞状态,ot为输出门.不同的memory和state之间都是通过对偶线性连接进行运算,而不是传统LSTM中的全连接层.
通过LSTM及其门控机制,即可实现对给定数据的处理,对数据中需要遗忘或记忆的信息进行自适应地学习.经过LSTM的学习与运算,即可由空间位置关系编码矩阵得出预测结果.同时,为了得到更好的恢复效果,本方法在LSTM预测模块中采用了PredRNN中提出的时空记忆单元[13],进一步提升了网络的性能和预测的精度.
由此可见,对于输入的无局部结构矩阵序列,首先经过对偶线性连接进行特征提取,提取出其中的空间位置关系,再通过LSTM提取帧与帧之间的时序关系,并生成预测结果,最终由OMPNet得到了对于给定输入序列的预测序列,完成了对无结构矩阵序列的预测.
3 实验及结果分析 3.1 实验设置与数据集本文采用了视频预测经典数据集Moving MNIST和一个真实环境下的城市交通订单数据集,对所提出的OMPNet的预测性能进行评估.实验中OMPNet所用LSTM层数为4层,每层中除了输出门以外的DLC操作的权重矩阵通道数为2,输出门采用了1×1卷积进行降维,使输出的通道数与输入保持一致;每层时序长度为10,输入及输出特征大小均为64×64.所用计算设备为NVIDIA K80显卡,所用深度学习框架为Tensorflow,采用的损失函数为均方误差(mean squared error,MSE)和平均绝对误差(mean absolute error,MAE),其求解公式如下:
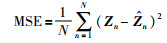
|
(5) |
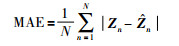
|
(6) |
其中,Zn为目标矩阵的真实值,而ẑn为算法生成的预测值,MSE和MAE的值越小,则说明算法的性能越好.
对采样移动手写数字数据集,为了衡量不同方法预测图像的相似程度,采用结构相似性(structual similarity,SSIM)评价指标,其求解公式为
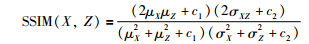
|
(7) |
其中,X和Z分别代表待对比的图像,μX代表图像X中全部像素的平均值,μZ代表图像Z中全部像素的平均值,σX2和σZ2分别为图像X和图像Z中全部像素值的方差,而σXZ代表图像X与Z之间的协方差,c1和c2为常数,实验中c1、c2取值分别为0.01和0.03. SSIM取值在0~1之间,数值越大,说明两个对比图像之间的相似程度越高.
3.2 采样移动手写数字实验移动手写数字数据集(Moving MNIST)是视频预测领域最为常见的数据集.针对无局部结构矩阵预测任务,本文采用了采样移动手写数字数据集(Sampled Moving MNIST)来进行实验.该数据集包含6 000个矩阵序列组成的训练集及3 000个矩阵序列组成的测试集.每个序列包括20帧,记录了两个随机数字的运动过程的随机采样,包括匀速直线运动和完全弹性碰撞,其中每个数字被分配一个速度,其方向与大小在单位圆上均匀随机选择.使用该数据集的原因是其大小是无限的,可以在运行中快速生成.因此训练集与测试集存在明显区别,基于该数据集的实验结果能够证明提出方法泛化的能力[10, 13].与移动手写数字数据集不同的是,采样移动手写数字数据集中的每一帧都是原图像在一定采样率下的随机采样,因此包含了大量的全局依赖,并且图像的局部近邻结构被破坏,难以观察到其中的边、角、轮廓等空间局部结构信息.在实验中,我们对序列中的前10帧进行输入和学习,来预测后10帧,并评价整体的预测结果来判断算法的有效性.测试集上全部测试结果的平均值如表 1所示.
| 方法 | MSE | MAE | SSIM |
| FcLSTM | 141.231 | 288.358 | 0.012 |
| ConvLSTM | 122.511 | 268.779 | 0.508 |
| PredRNN | 101.212 | 228.270 | 0.554 8 |
| OMPNet | 71.311 | 143.810 | 0.705 4 |
由表 1可见,采用OMPNet获得的MSE和MAE明显小于采用了大量卷积层的ConvLSTM和PredRNN的结果,证明OMPNet可以更好地拟合预测图像,采用OMPNet获得的SSIM明显大于ConvLSTM和PredRNN的结果,从结构相似性上进一步证实了OMPNet的预测优越性,即预测结果更相似.与全部为线性层的FcLSTM相比,OMPNet优势更加突出,证明了本文提出的对偶线性连接对无局部结构矩阵预测任务能够取得更好的预测结果.
为了进一步验证算法的性能,图 4和图 5分别给出了采用不同算法对测试集实验的可视化结果对比图,可见:对于包含大量长距离依赖及全局依赖的输入矩阵序列,基于卷积神经网络的ConvLSTM和PredRNN均难以进行很好地处理,因为对输入矩阵序列中的空间结构信息很难通过卷积核进行有效地提取和学习,因此对于Conv LSTM和PredRNN的生成结果,只能维持前几帧的准确程度.而本文提出的OMPNet,可以有效地提取到输入矩阵中的全局依赖及长距离依赖,并且可以通过LSTM学习这些空间结构的时序联系,生成的预测序列较好地展示了数字的大概轮廓和运动轨迹,证实了OMPNet的有效性.

|
| 图 4 数字集1,5可视化对比图 Fig.4 Visual comparison diagrams of digital set 1 and 5 |

|
| 图 5 数字集1,3可视化对比图 Fig.5 Visual comparison diagrams of digital set 1 and 3 |
为了更好地验证提出方法的有效性,本文还采用了一个真实环境下的城市交通订单实验.城市交通订单实验中使用的是网约车订单数据集(ubran traffic dataset),包含了某城市2016年的部分订单数量.由于城市网约车的年累积订单过于庞大,导致在进行订单分析的时候,难以对数以亿计的全部订单量进行整体性分析,只能对全部订单量进行随机采样,进而对采样订单数据集进行分析.该城市交通订单数据集包含400多万条订单,每一条都包含起始的时间、经纬度等信息,以及订单终点的时间、经纬度.
实验时,数据集中每半个小时为一个时刻,每一个时刻的全部交通订单情况按经纬度填入该城市的地图中,形成一个64×64的矩阵.对于任意选定时刻,选取之前相关联的14个时刻的矩阵,组成包含历史信息的矩阵序列,即由包含14个输入帧和一个目标帧构成数据集中的一个序列数据.整个数据集包含7 872个训练数据和900个预测数据.对于不同的算法,均需要输入前14帧进行分析和学习,预测出下一个帧,即之后半个小时的城市整体订单预测结果.
该数据集的主要难点在于,由于数据集中订单情况是该城市全年的整体订单情况的采样,因此生成的矩阵具有稀疏、局部结构缺失等特点,难以用传统算法及卷积神经网络来处理,采用本文提出的OMPNet及对偶线性连接可以有效地对其进行特征提取和预测,采用MSE和MAE评价指标对不同方法的预测结果进行比较,实验结果如表 2所示,由于网约车订单数据集的特殊性,无需对其进行结构相似性的比较,因此表中未计算SSIM.该交通订单数据实验结果可视化对比见图 6所示.
| 方法 | MSE | MAE |
| FcLSTM | 4.233 1 | 0.015 1 |
| ConvLSTM | 3.957 6 | 0.013 8 |
| PredRNN | 4.818 8 | 0.014 3 |
| OMPNet | 3.762 6 | 0.013 2 |

|
| 图 6 交通订单数据可视化对比图 Fig.6 Visual comparison diagrams of traffic order data |
由表 2和图 6可见,采用本文提出的OMPNet预测效果均优于FcLSTM、ConvLSTM和PredRNN三种方法.因为采用了传统线性操作,即全连接层的FcLSTM,难以对数据中存在的大量全局依赖及长距离依赖进行处理,由于过拟合以及梯度消失等问题,使得FcLSTM并不能获得很好的预测结果.而本文提出的OMPNet很好地减弱了梯度传播中梯度消失问题,以及由于参数量过多带来的过拟合问题,获得了更好的预测结果.同时相比于ConvLSTM和PredRNN,对偶线性连接不仅可以处理数据中的局部结构信息,还能有效提取其中的全局依赖,实验证明了OMPNet能够很好地处理网约车订单数据集中存在的稀疏、局部结构缺失,较好解决了梯度传播中梯度消失及全局依赖问题,对真实环境下的城市交通订单实验也能够获得更好地预测结果.
4 结论针对无局部结构矩阵序列预测问题,本文提出了基于深度学习的新型无局部结构矩阵序列预测网络OMPNet,对于数据中存在的大量全局依赖、长距离依赖问题,提出了新型线性操作对偶线性连接,使得整个网络可以自适应地学习给定数据中的全局依赖和局部近邻关系,从而生成较准确的预测结果.相比于传统的基于全连接层的FcLSTM预测网络,网络减少了参数量和内存消耗,降低了梯度传播难度,更好地减轻了过拟合现象.在实验室环境的模拟数据集移动手写数字数据集和真实世界中的城市交通订单数据集上,本文的无局部结构矩阵序列预测网络均取得了较好的实验结果,验证了该方法的有效性,有望在更多无局部结构矩阵预测的任务中推广应用.
| [1] |
谷远利, 李萌, 芮小平.
基于深度学习的网约车供需缺口短时预测研究[J]. 交通运输系统工程与信息, 2019, 19(2): 223–230.
Gu Y L, Li M, Rui X P. Short-term forecasting of supply-demand gap under online car-hailing services based on deep learning[J]. Journal of Transportation Systems Engineering and Information Technology, 2019, 19(2): 223–230. |
| [2] |
郑炜, 陈军正, 吴潇雪.
基于深度学习的安全缺陷报告预测方法实证研究[J]. 软件学报, 2020, 31(5): 1294–1313.
Zheng W, Chen J Z, Wu X X. Empirical studies on deep-learning-based security bug report prediction methods[J]. Journal of Software, 2020, 31(5): 1294–1313. |
| [3] |
曲星宇, 曾鹏, 李俊鹏.
基于RNN-LSTM的磨矿系统故障诊断技术[J]. 信息与控制, 2019, 48(2): 179–186.
QU X Y, Zeng P, Li J P. Fault diagnosis technology of grinding system based on RNN-LSTM[J]. Information and Control, 2019, 48(2): 179–186. |
| [4] |
闫旭, 范晓亮, 郑传潘, 等.
基于图卷积神经网络的城市交通态势预测算法[J]. 浙江大学学报(自然科学版), 2020, 54(6): 1–9.
Yan X, Fan X L, Zheng C P, et al. Urban traffic flow prediction algorithm based on graph convolutional neural networks[J]. Journal of Zhejiang University (Engineering Science), 2020, 54(6): 1–9. |
| [5] |
刘阳, 郜志英, 周晓敏.
工业数据驱动下薄板冷轧颤振的LSTM智能预报[J]. 机械工程学报, 2020, 56(11): 121–131.
Liu Y, Gao Z Y, Zhou X M. Industrial data-driven intelligent forecast for chatter of cold rolling of thin strip with LSTM recurrent neural network[J]. Journal of Mechanical Engineering, 2020, 56(11): 121–131. |
| [6] | Yu T Z, Wang L F, Gu H X. Deep generative video prediction[J]. Pattern Recognition Letters, 2018, 110: 58–65. DOI:10.1016/j.patrec.2018.03.027 |
| [7] | Li H G, Trocan M. Deep neural network based single pixel prediction for unified video coding[J]. Neurocomputing, 2018, 272: 558–570. DOI:10.1016/j.neucom.2017.07.037 |
| [8] | Cisco. Cisco visual networking index: Forecast and trends, 2017-2022[R]. 2018. |
| [9] |
莫凌飞, 蒋红亮, 李煊鹏.
基于深度学习的视频预测研究综述[J]. 智能系统学报, 2018, 13(1): 89–100.
Mo L F, Jang H L, Li X P. A review of video prediction based on deep learning[J]. Journal of Intelligent Systems, 2018, 13(1): 89–100. |
| [10] | Srivastava N, Mansimov E, Salakhutdinov R. Unsupervised learning of video representations using LSTMs[C]//International Conference on Machine Learning. Berlin, Germany: SpringerLink, 2015: 843-852. |
| [11] | Shi X, Gao Z, Lausen L, et al. Deep learning for precipitation nowcasting: A benchmark and a new model[C]//Advances in neural information processing systems. Piscataway, NJ, USA: IEEE, 2017: 5617-5627. |
| [12] | Shi X J, Chen Z R, Wang H, et al. Convolutional LSTM network: A machine learning approach for precipitation nowcasting[C]//Advances in Neural Information Processing Systems. Piscataway, NJ, USA: IEEE, 2015: 802-810. |
| [13] | Wang Y B, Long M S, Wang J M, et al. PredRNN: Recurrent neural networks for predictive learning using spatiotemporal LSTM[C]//Advances in neural information processing systems. Piscataway, NJ, USA: IEEE, 2017: 1-10. |
| [14] | Wang Y B, Gao Z F, Long M S, et al. PredRNN++: Towards a resolution of the deep-in-time dilemma in spatiotemporal predictive learning[C]//International Conference on Machine Learning. Berlin, Germany: SpringerLink, 2018: 5110-5119. |
| [15] | Wang Y B, Zhang J J, Zhu H Y, et al. Memory in memory: A predictive neural network for learning higher-order non-stationarity from spatiotemporal dynamics[C]//Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2019: 9154-9162. |
| [16] | Villegas R, Yang J, Hong S, et al. Decomposing motion and content for natural video sequence prediction[C]//International Conference on Learning Representations. Berlin, Germany: SpringerLink, 2017: 1-12. |
| [17] | Qiu J, Huang G, Lee T, et al. A model cortical network for spatiotemporal sequence learning and prediction[C]//International Conference on Learning Representations. Berlin, Germany: SpringerLink, 2019: 1-17. |
| [18] | Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[C/OL]//International Conference on Learning Representations. (2015-04-10)[2017-01-01]. https://arxiv.org/pdf/1409.1556.pdf. |
| [19] | Yu F, Koltun V. Multi-scale context aggregation by dilated convolutions[C]//International Conference on Learning Representations. Berlin, Germany: SpringerLink, 2016: 1-13. |
| [20] | Wang X, Girshick R, Gupta A, et al. Non-local Neural Networks[C]//Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2018: 7794-7803. |