



0 引言
5G的到来使虚拟现实、无人驾驶和远程医疗等成为现实,同时带来数据的爆发式增长.在互联网信息快速发展的时代,个性化推荐[1]极大地缩短了人们在网络数据海洋中获取目标数据的时间.通过研读大量推荐系统相关文献发现,已有协同过滤算法[2-3]、矩阵分解[4]、朴素贝叶斯[5]、聚类[6]、关联规则[7]和深度学习[8-10]应用于推荐系统[11]中.其中协同过滤算法在推荐系统中最具代表性,然而,随着更加复杂的系统结构的应用及伴随用户扩增而呈指数级增长的海量数据,协同过滤算法技术已经遇到了一系列的挑战,包括冷启动、数据稀疏性和用户兴趣的变化.特别是,数据稀疏性问题显著影响推荐的质量.
在Netflix比赛中兴起的基于矩阵分解的推荐算法,因其较高的预测精度和在数据稀疏时的高性能,引起了大量研究者的关注.矩阵分解变种方法众多,主流的有原始的SVD(singular value matrix)、LFM、加入偏置项后的LFM、SVD++[12]、概率矩阵分解模型[13]等,这些矩阵分解模型核心步骤几乎相同,即将原始评分矩阵R通过随机梯度下降法进行降维处理,得到低秩的特征矩阵P和Q,从而进行预测评分.例如,Bao等[14]提出了一种基于概率矩阵分解的协同过滤模型,利用标签和评级信息来预测用户对项目的兴趣,缓解矩阵分解中的过拟合问题,有效提高预测精度.然而,高度稀疏的评分矩阵将导致矩阵分解中的过拟合问题,虽然正则化可以在一定程度上缓解过拟合的问题,但是当数据高度稀疏时,训练有效的推荐系统模型仍然是一个重大挑战.
网络的发展及社会化标签的兴起和普及,为解决数据稀疏导致的矩阵分解推荐算法的过拟合问题提供了一个新的方向.标签信息不仅可以很好地描述项目特征,而且可以表征用户的偏好,扩充用户—项目的信息.例如,方冰等[15]提出在矩阵分解中融合标签信息,丰富单一数据源,从而提高推荐精度.由于对标签信息分析不充分和忽略用户兴趣的迁移变化,导致这些方法在用户偏好预测中仍存在限制.董力岩等[16]通过遗忘曲线和记忆周期将时间信息融合到用户项目评分矩阵中,以解决兴趣变化的问题;兰艳等[17]提出信息保持期概念,对原始评分数据通过时间函数进行不同程度的加权处理,结合聚类算法提高了预测推荐的准确度,但是该方法的核心还是基于邻域的协同过滤算法,所以不适合具有大规模数据的应用;石鸿瑗等[18]发现,将改进时间权重函数引入矩阵分解模型中,结合类型影响力加强权重优化矩阵分解推荐算法,不仅推荐性能得到提高,而且满足海量数据的需求.
通过分析以上文献,综合考虑矩阵分解推荐算法、基于标签信息的推荐算法和用户兴趣随时间的迁移变化,本文提出了一种融合标签和时间信息的矩阵分解推荐算法TTMF,实验证明本文算法具有较好的推荐效果.
1 融合标签信息和时间权重的矩阵分解推荐算法本文提出的融合标签信息和时间权重的矩阵分解推荐模型TTMF,和传统矩阵分解算法类似.算法分为3个步骤:1)根据评分、标签和时间信息得到用户的标签偏好,构建用户—标签偏好矩阵;2)通过标签的频率和时间信息评估标签和项目之间的关联度,构建项目—标签关联矩阵;3)使用TTMF模型预测用户评分.
1.1 用户标签偏好值推荐系统一般会提供评分时间、评分值和标签等一系列信息,通过用户的这些历史行为可以展现他们的个人偏好,评分可以反映用户对项目的喜好程度,标签可以表征项目特点,但是都不能区分用户对不同标签的喜欢程度.例如,用户B喜欢科幻电影,他对电影《星际穿越》和《黑客帝国》都评分为5,这两部电影都属于科幻类型.用户B不喜欢恐怖类型电影,他对电影《行尸走肉》和电影《釜山行》的评分分别为2和1,评分如此低是因为这两部电影属于恐怖类型. 《异种》是一部含有少许恐怖元素的科幻类型电影,尽管用户B不喜欢恐怖类型的电影,但他还是对这部电影评分为3,因为他喜欢看科幻类型的电影.
因此,可以利用评分记录和标签之间的联系,克服仅仅依赖评分记录的限制,挖掘更多的隐藏信息,从而为用户提供更加精确地推荐.参考以前的研究,可以通过评分记录度量用户对标签的偏好值,一般通过以下步骤来优化表达用户标签偏好.
1.1.1 标签对用户的影响力艾宾浩斯遗忘原理[19]指出,人的记忆在遗忘的过程中是有规律的,即“先快后慢”且通过一定周期的复习记忆信息,人对事物的记忆度会得到增强.例如:当你背诵一篇《致橡树》,1 h就能熟背,如果长时间不回顾,那么对该文章的记忆量就会随时间不断减少;当你定期回顾该文章时,对该文章的记忆就会逐渐增强,之后的记忆几乎不会随时间消减.在电影推荐的场景中,该原理同样适用,如果标记的某类电影标签在之后的观影经历中不再出现,或者次数很少,那么此时该类标签对用户的影响力就会急剧下降;如果该类标签在以后的观影中重复出现,那么用户对该类标签的偏好会得到加强,从而增强了该标签标记电影对用户的影响力.因此,定义标签ti用户u的影响力为
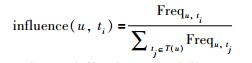
|
(1) |
其中,Frequ,ti表示用户使用标签t的次数,T(u)表示用户u使用的标签集合.
1.1.2 项目的标签权重通常情况下,一个项目可以被多个标签进行标注,并且一个标签标注项目的次数越多,该标签越可以代表项目的特征,因此,本文定义了标签在项目中所占权重的计算方法,它的基本思想就是标签在项目上使用的频率越高,那么该标签的权重就越大,公式定义为
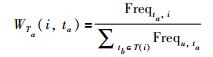
|
(2) |
其中,Frequ,ti表示标签ta在项目i中的标记次数,ti表示项目i中的标签集合.
1.1.3 用户对标签的偏好值定义1 如果一个用户对含有某种标签信息的项目评分越高,那么他对这个标签就越感兴趣.
在定义1的基础上,用户u对t标签的偏好值可以通过用户的项目评分、标签影响力和项目的标签权重进行计算,计算过程为
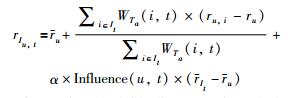
|
(3) |
其中,ru表示用户u的平均评分,ru,i用户u对项目i的评分,It是含有标签t的项目集合,α是一个调节标签影响力在用户标签偏好中的权重,rIt中所有用户的平均评分.
定义2 用户的兴趣会随时间而变化.
考虑用户的兴趣随时间迁移变化,本文提出用户对标签的偏好也是随时间变化的,所以在计算用户的标签偏好值时应该将时间信息考虑在内,本文采用文[20]提出的时间权重函数,其基本思想:用户对近期使用过的标签应该具有较大的偏好值,对早期使用的标签具有较低的偏好值,并且使用标签的时间越早,对该标签的偏好值就越低,即用户对标签使用的时间越早,那么新颖性就越大.因此,用户对标签的偏好值的时间权重为

|
(4) |
其中,lifetimeu,t表示用户u使用标签t的起止时间间隔,为用户u最近使用标签t的时间与第1次使用标签t的时间之差,计算公式为maxTimeu,t-minTimeu,t,如果lifetimeu,t=0,则根据实验数据的特点,lifetimeu,t就被赋值为一个合理的大常数time=10 000 000;τ为条件因子,根据文[20]实验可知,当τ设为0.3时取得最佳效果;maxTimeu为某一特定时间,本文取用户u使用所有标签的最晚时间.
因此,用户对标签t的标签偏好是基于标签影响力和标签时间权重来定义的,最终公式为
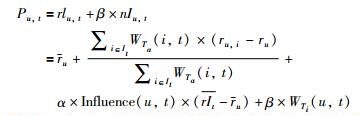
|
(5) |
其中,β表示一个调节用户标签偏好中的时间权重参数.
1.2 项目标签关联度定义3 一个项目上标记某类标签次数越多,那么这个标签越能表达这个项目.
基于定义3,本文认为项目标签关联度除了与项目标签权重有关外,标签和项目之间的关联度也会随着时间而改变.例如:用户一年前用“最强CPU”标记刚上市的游戏笔记本电脑,随着时代进步,科技发展,出现了大批的更加先进的工艺技术,那些当时标记“最强CPU”的电脑,现在成为了“普通处理器”,因此近期的“普通处理器”更加准确地表示该类电脑.所以,为了准确表达项目标签关联度随时间的变化,定义了项目标签的时间权重WTi(i,t),计算方式和用户的标签时间类似,公式为
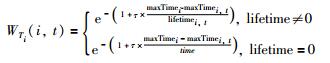
|
(6) |
标签项目关联度可以通过项目的标签权重和项目标签的时间权重进行度量计算,并增加β参数进行修正,β是一个调节标签项目关联度中的时间权重参数.最终计算公式为
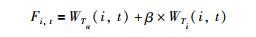
|
(7) |
假设用户集合表示为U={u1,u2,…,um},项目集合表示为I={i1,i2,…,in},标签集合表示为T={t1,t2,…,tk}.用户—项目的评分记录矩阵可标记为R=(ru,i)m×n,u=1,2,…,m,i=1,2,…,n,其中ru,i表示用户u对项目i的评分;根据1.1节定义了用户的标签偏好值,可以计算用户u对标签t的偏好值pu,t故用户—标签的偏好矩阵可用P=(pu,t)m×k,u=1,2,…,m,t=1,2,…,k来表示;1.2节定义了项目—标签关联度,可以计算项目i与标签t的关联度fi,t,所以项目—标签的关联矩阵可用F=(fi,t)n×k,i=1,2,…,n,t=1,2,…,k来表示.根据1.1节和1.2节定义构造用户—标签偏好矩阵P和项目—标签关联矩阵F:

|
可知,R=P·FT,为了得到最优矩阵,开始进行下一步的矩阵分解.
2.2 矩阵分解本文用到的预测公式是Koren的RSVD(regularized singular value matrix)模型,其考虑了用户/项目偏差,通过用户/项目特征向量来进行评级预测.公式为
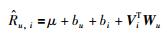
|
(8) |
其中,bu和bi分别代表用户u和项目i的评级偏差,μ是全局平均评级,Vi是项目i的特征向量,Wu是用户u的特征向量. Koren等[12]已经表明,整合用户和项目评级偏置可以提高预测精度.为了解决矩阵分解仅考虑评级信息将导致过拟合问题,所以提出在矩阵分解中融合标签和时间信息来缓解过拟合问题,从而提高推荐质量.
在TTMF模型中,同时使用了标签、时间和评级信息.用户对标签的偏好值,项目和标签之间的关联度及用户对项目的评级都应用于矩阵分解.通过探索挖掘矩阵P中的偏好值、矩阵F中的关联度和矩阵R中的评级,可以做出比基于评级的RSVD方法更加准确地预测R中缺失评级.在经典的SVD模型基础上,进一步考虑评级、用户的标签偏好值、项目标签关联度、用户标签偏置及用户和项目的特征向量:
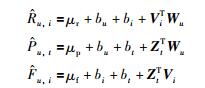
|
(9) |
其中,bt表示标签t的偏好偏差,μr,μp和μf分别是全局平均评级、全局平均偏好和全局平均关联度,Wu是用户u特定向量,Vi是项目i的特定向量,Zt是标签t的特定向量.
为了探索挖掘矩阵R中的评分信息、矩阵P中的偏好值和矩阵F中的关联度中更多的隐藏信息,需要尽量缩小预测值Ȓui与真实值Rui之间的误差,提高预测精度,首要目标就是通过一系列运算求解最优的用户特征矩阵W、项目特征矩阵V和标签特征矩阵T.综合考虑用户项目评级、用户的标签偏好值和项目标签关联度的联系.要最小化的目标函数如式(10)所示:
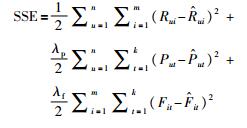
|
(10) |
在计算过程中,还需要加入防止过拟合项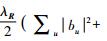
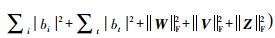
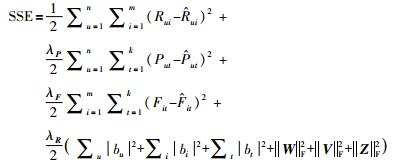
|
(11) |
其中,λP,λF和λR是正则化系数,通过调节这些系数可以防止函数过度拟合;||·||F2是Frobenius范数;Ȓui、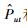
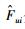
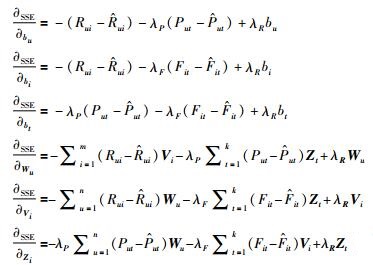
|
(12) |
重复上述过程n次直到目标函数SSE小于预设的某一阈值,说明矩阵分解达到预设优化目标,此时的用户特征矩阵W、项目特征矩阵V和标签特征矩阵Z即为所求最优特征矩阵.
3 实验分析 3.1 实验数据及预处理实验数据来源明尼苏达大学Grouplens小组公开的电影数据集.本文用到的两个数据集是ml-latest-small和ML-10M,如表 1所示且都包含标签、评分和时间戳等信息,每个用户至少评价20部电影,评分范围1~5.
| 数据集 | 用户 | 电影 | 标签记录 | 评分记录 |
| ml-latest-small | 610 | 974 2 | 368 3 | 100 836 |
| ML-10M | 71 567 | 10 681 | 95 580 | 10 000 054 |
数据集ML-10M数据量大,非常适合验证本文算法在实际大数据环境下的推荐性能.在这些原始数据中存在用户和电影编号不连续及无效标记问题,所以实验之前需要进行数据的预处理,包括两个步骤:首先,将对用户和电影编号映射到较低范围内,重新进行编号;然后,删除出现次数少于5次的标签并将该项目的属性作为标签信息来标记电影,处理后的数据如表 2所示.为了保证实验的正确性,避免人为因素影响,将预处理后的数据集随机分成5等份,任意挑选4份作为训练集,剩余的一份为测试集.
| 数据集 | 用户 | 电影 | 标签记录 | 评分记录 | 评分稀疏度 | 标签稀疏度 |
| ml-latest-small | 610 | 974 2 | 332 5 | 100 836 | 0.016 9 | 0.000 56 |
| ML-10M | 71 552 | 10 681 | 92 809 | 10 000 054 | 0.013 1 | 0.000 12 |
表 2中评分稀疏度和标签稀疏度都是度量数据集稀疏性的指标,数据稀疏度计算公式为
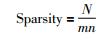
|
(13) |
式中,Sparsity表示数据稀疏度,N表示评分或标签记录的总数,m表示用户数,n表示电影数目.
3.2 实验评价标准在推荐系统领域,评价预测评分准确性的指标有很多,本文实验选择RMSE作为评分预测的评价标准,从RMSE的公式可以看出,它可以放大评分预测误差,可以更加准确地反映推荐算法的预测精度.公式为
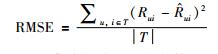
|
(14) |
其中,|T|表示测试集中评分记录的总数.
3.3 实验结果及分析本文选取LFM、RSVD算法作为对比,验证文中提出的TTMF算法的推荐精度,对比算法为:
1) LFM:隐语义模型.
2) RSVD:Koren于2009年提出的RSVD模型.
本文算法涉及了5个参数:为了更好地验证实验的效果,通过调参实验,检验每个参数对实验的影响,调参结果如图 1所示.其中,α,β分别是调节标签影响力权重和时间权重的参数,可以看到当α=1.7时,RMSE最小为0.788 7;当β=0.06时,RMSE最小为0.788 3. λP,λF分别表示用户—标签矩阵和项目—标签矩阵在模型中的权重,当λP=0.001,λF=1.5时,取得最优结果;当λP=0,λF=0时,表示模型与这两个矩阵不相关,此时的模型和RSVD相同.

|
| 图 1 参数对实验的影响 Fig.1 Effect of parameters on the experiment |
通过反复调参实验,对各算法的参数进行最优化,最优化调参结果如表 3所示.
| 算法 | 参数 |
| LFM | 学习率=0.01,正则化系数=0.02 |
| RSVD | 学习率=0.01,正则化系数=0.05 |
| TTMF | α=1.7,β=0.06,λP=0.001,λF=1.5,λR=0.035 |
调参实验后,将LFM算法、RSVD算法和TTMF算法分别在两个数据集中的训练数据集进行训练,测试集数据进行评分预测,每个算法运行5次,求其平均值,得到各算法的结果如图 2和图 3所示.

|
| 图 2 ml-latest-small数据集下RMSE对比 Fig.2 RMSE comparison on the ml-latest-small dataset |

|
| 图 3 ML-10M数据集下RMSE对比 Fig.3 RMSE comparison on the ML-10M dataset |
由图 2的实验结果可知,传统的奇异值矩阵分解推荐算法LFM,其平均RMSE最大,为0.921 1,预测评分准确性最低. Koren提出的RSVD算法通过增加用户和项目偏置信息及用户兴趣随时间迁移变化的时间效应,从而弥补了传统矩阵分解的一些缺陷,评分预测的准确性也有相当大的提升,平均RMSE为0.881 6,相比LFM算法降低了4%左右. TTMF算法利用用户的标签偏好、项目标签关联度和用户兴趣随时间迁移变化优化了RSVD算法,其平均RMSE在这3种算法中最小,为0.855 3,相比LFM算法降低了6.8%左右,取得了更好的推荐准确性,说明了本文提出的利用标签和时间信息来提高推荐质量的可行性,可以方便地应用到利用矩阵分解系统过滤算法的推荐系统中.
由图 3可以看出,本文提出的TTMF算法的平均RMSE依然是最小的,为0.757 2,说明了在更大规模的数据集上,TTMF算法同样具有一定的优越性.
4 结束语矩阵分解算法具有较好的可扩展性和较高的精确度,而社会化标签能够更直接更好地表示用户的偏好和资源的内容特征,本文在矩阵分解模型的基础上,分别引入全局偏置、用户标签偏好、项目标签关联度及时间效应对基础模型进行了优化,实验证明无论是在小数据集ml-latest-small,还是在大数据集ML-10M上,本文算法的预测精度都得到提高,为解决此类推荐问题提供了新的方法工具.后续的研究可以将推荐算法进行分布式部署,利用Spark大数据平台基于内存的数据流计算优势,以此来增加推荐系统的实时推荐能力.
| [1] |
项亮.
推荐系统实践[M]. 北京: 人民邮电出版社, 2012: 1-195.
Xiang L. Recommendation system practice[M]. Beijing: People's Posts and Telecommunications Press, 2012: 1-195. |
| [2] |
黄震华, 张佳雯, 田春岐, 等.
基于排序学习的推荐算法研究综述[J]. 软件学报, 2016, 27(3): 691–713.
Huang Z H, Zhang J W, Tian C Q, et al. Review of research on recommendation algorithms based on ranking learning[J]. Journal of Software, 2016, 27(3): 691–713. |
| [3] |
冷亚军, 陆青, 梁昌勇.
协同过滤推荐技术综述[J]. 模式识别与人工智能, 2014, 27(8): 720–734.
Leng Y J, Lu Q, Liang C Y. Overview of collaborative filtering recommendation technology[J]. Pattern Recognition and Artificial Intelligence, 2014, 27(8): 720–734. |
| [4] | Wang R Q, Cheng H K, Jiang Y L, et al. A novel matrix factorization model for recommendation with LOD-based semantic similarity measure[J]. Expert Systems with Applications, 2019, 123: 70–81. DOI:10.1016/j.eswa.2019.01.036 |
| [5] |
刘鹏, 赵慧含, 滕家雨, 等.
面向大规模中文文本分类的朴素贝叶斯并行Spark算法[J]. 中南大学学报(英文版), 2019, 26(1): 1–12.
Liu P, Zhao H H, Teng J Y, et al. Naive Bayesian parallel spark algorithm for large-scale chinese text classification[J]. Journal of Central South University (English Edition), 2019, 26(1): 1–12. |
| [6] |
刘丹, 段建民, 王昶人.
一种基于聚类分组的快速联合兼容SLAM数据关联算法[J]. 机器人, 2018, 40(2): 158–168, 177.
Liu D, Duan J M, Wang Y R, et al. A fast joint compatible SLAM data association algorithm based on clustering grouping[J]. Robot, 2018, 40(2): 158–168, 177. |
| [7] |
杨阳, 丁家满, 李海滨, 等.
一种基于Spark的不确定数据集频繁模式挖掘算法[J]. 信息与控制, 2019, 48(3): 257–264.
Yang Y, Duan J M, Li H B, et al. A frequent pattern mining algorithm for uncertain data sets based on Spark[J]. Information and Control, 2019, 48(3): 257–264. |
| [8] |
黄立威, 江碧涛, 吕守业, 等.
基于深度学习的推荐系统研究综述[J]. 计算机学报, 2018, 41(7): 1619–1647.
Huang L W, Jiang B T, Lu S Y, et al. Review of research on recommendation systems based on deep learning[J]. Chinese Journal of Computers, 2018, 41(7): 1619–1647. |
| [9] |
张荣, 李伟平, 莫同.
深度学习研究综述[J]. 信息与控制, 2018, 47(4): 385–397, 410.
Zhang R, Li W P, Mo T, et al. Review of deep learning research[J]. Information and Control, 2018, 47(4): 385–397, 410. |
| [10] |
赵洋, 李国良, 田国会, 等.
基于深度学习的视觉SLAM综述[J]. 机器人, 2017, 39(6): 889–896.
Zhao Y, Li G L, Tian G L, et al. Overview of visual SLAM based on deep learning[J]. Robot, 2017, 39(6): 889–896. |
| [11] | Lyu L, Medo M, Yeung C H, et al. Recommender systems[J]. Physics Reports, 2012, 519(1): 1–49. DOI:10.1016/j.physrep.2012.02.006 |
| [12] | Koren Y, Bell R M, Volinsky C. Matrix factorization techniqures for recommender systems[J]. IEE Computer, 2009, 42(8): 30–37. DOI:10.1109/MC.2009.263 |
| [13] | Tan F, Li L, Zhang Z, et al. A multi-attribute probabilistic matrix factorization model for personalized recommendation[J]. Pattern Analysis and Applications, 2016, 19(3): 857–866. DOI:10.1007/s10044-015-0510-2 |
| [14] | Bao T, Ge Y, Chen E, et al. Collaborative filtering with user ratings and tags[C]//1st International Workshop on Context Discovery and Data Mining. New York, NJ, USA: ACM, 2012: 1-5. 10.1145/2346604.2346606 |
| [15] |
方冰, 牛晓婷.
基于标签的矩阵分解推荐算法[J]. 计算机应用研究, 2017, 34(4): 1022–1025, 1031.
Fang B, Niu X T. Matrix decomposition recommendation algorithm based on labels[J]. Computer Application Research, 2017, 34(4): 1022–1025, 1031. |
| [16] |
董立岩, 王越群, 贺嘉楠, 等.
基于时间衰减的协同过滤推荐算法[J]. 吉林大学学报(工学版), 2017, 47(4): 1268–1272.
Dong L Y, Wang Y Q, He J N, et al. Collaborative filtering recommendation algorithm based on time decay[J]. Journal of Jilin University(Engineering and Technology Edition), 2017, 47(4): 1268–1272. |
| [17] |
兰艳, 曹芳芳.
面向电影推荐的时间加权协同过滤算法的研究[J]. 计算机科学, 2017(4): 302–308, 329.
Lan Y, Cao F F. Research on time-weighted collaborative filtering algorithm for movie recommendation[J]. Computer Science, 2017(4): 302–308, 329. |
| [18] |
石鸿瑗, 孙天昊, 李双庆, 等.
融合时间和类型特征加权的矩阵分解推荐算法[J]. 重庆大学学报, 2019, 42(1): 83–91.
Shi H Y, Sun T H, Li S Q, et al. Matrix decomposition recommendation algorithm combining weights of time and type features[J]. Journal of Chongqing University, 2019, 42(1): 83–91. |
| [19] | Niu Y Y, Cheng G Z, Qi C, e tc. Measurement method of user influence timeliness based on forgetting curve[J]. Computer Application, 2017, 37(S1): 18–22. |
| [20] |
郭娣, 赵海燕.
融合标签流行度和时间权重的矩阵分解推荐算法[J]. 小型微型计算机系统, 2016, 37(2): 293–297.
Guo D, Zhao H Y. Matrix decomposition recommendation algorithm combining tag popularity and time weighting[J]. Small Micro Computer System, 2016, 37(2): 293–297. |