



0 引言
自多目标置换流水车间调度问题提出以来,多目标置换流水车间调度问题一直受到各个领域专家学者的关注[1-6].在日常智能制造系统中,多目标置换流水车间调度问题普遍存在,因而,研究多目标置换流水车间调度问题具有较高的理论及实际意义. Ishibuchi等[7]利用遗传算法求解多目标置换流水车间调度问题,并验证了遗传算法求解该类问题的有效性,然而,该算法的精确度较低;Ishibuchi等[8]在此基础上,将遗传算法与Pareto非支配排序方式相结合,用以求解多目标置换流水车间调度问题;Fattahi[9]等提出元启发式算法用以求解3目标置换流水车间调度问题;为寻求新的解决方案,Li等[10]提出一种多目标记忆搜索算法用以求解多目标问题,该算法将NEH模型与扰动因子相结合提高了种群质量及全局收敛性能;徐文婕等[11]通过直觉模糊集相似度值对多目标遗传算法的进化进行引导,该算法在解决规模较大的问题上有良好的表现;Lu等[12]将多目标回溯搜索算法应用于多目标置换流水车间调度领域,通过一系列的标准案例的测试,证明了该算法的有效性.
由以上可知,多目标置换流水车间调度问题是目前国内外学者研究的热点.鉴于启发式算法求解多目标置换流水车间调度问题的成功先例,本文将近年来新提出的萤火虫算法应用于多目标置换流水车间调度问题模型中.萤火虫算法具有编码、算法结构简单,算法易实现等优点,其在函数优化、图像识别、车辆配送等领域[13-15]取得了显著成果,但在多目标置换流水车间调度领域的研究较少.基于此,本文拟在萤火虫算法的基础上引入二元分布估计算法中的概率模型用以记录并更新可行解,并利用概率矩阵挖掘可行解中的优秀可行解片段组合区块用以降低求解复杂度及提高可行解质量;同时,提出一种反复搜索策略在不同的解空间进行搜索,找出被遗漏的关键信息,避免局部最优化.最后,针对标准案例集进行仿真测试,验证了该算法的有效性.
1 建立多目标置换流水车间调度问题数学模型多目标置换流水车间调度问题是许多生产调度问题的简化模型,该问题主要研究了n个工件{J1,J2,…,Jn}在m台机器{M1,M2,…,Mm}上加工,并且每个工件有m道加工工序{n1,n2,…,nm},加工工件的每个工序需要在不同机器上完成,但是所有工件的工序一样且在每道工序的加工机器一样,目标是使得多项生产指标达到最优.相关约束条件为:1)所有工件按照相同顺序加工;2)某一时刻,任一机器只能加工一个工件;3)某一时刻,任一工件只能在一台机器上进行加工;4)任何工件在加工过程中不能中断;5)所有工件在初始时刻都可以加工;6)每道工序的准备时间包含于每道工序的加工时间之中;7)加工机器可以被连续使用.
由于实际生产活动中,最小化完工时间能够使得生产系统效率及利用率实现最大化;流水时间最小化能够为企业加工生产提供一个稳定的生产活动并能将库存最小化;最小化延迟时间能够充分考虑顾客的各种需求.因而在实际生产应用中,完工时间、流水时间及延迟时间是最为普遍、重要的目标.基于此,当前大多数学者在研究多目标置换流水车间调度问题时通常以完成时间(Cmax)、延迟时间(Di(w))及总流程时间(Ei(w))为优化目标,其数学模型可以描述为
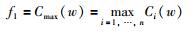
|
(1) |
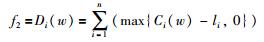
|
(2) |
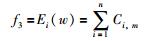
|
(3) |
其中,f1代表工件的最大完工时间,f2代表最大迟到时间,f3代表总流水时间.这3个问题都已被证明为NP-hard难题[16].
针对这3个子目标,故本文的多目标置换流水车间的目标可以表示为
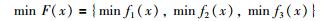
|
(4) |
与求解单目标置换流水车间调度问题不同,多目标置换流水车间调度问题的最优解是一组点的集合,该组点集合被称为Pareto最优解. Pareto最优解概念为:
Pareto最优解(非支配解).如果可行解集合中不存在x′Pareto支配x,则称x是该可行解集合中的非支配解,如果x是多目标置换流水车间调度问题可行解集合中的一个非支配解,则x称之为该问题的Pareto最优解.
2 混合萤火虫算法设计萤火虫算法是Yang受夜间萤火虫活动的影响,提出了萤火虫算法(firefly algorithm,FA),萤火虫算法是一种介于遗传算法和进化规划之间的一种基于群体但不使用进化算子的进化算法,萤火虫算法将每个萤火虫个体看成搜索空间中的一个能够移动搜索的没有体积的微粒.其移动位置由周围其它萤火虫所发出的荧光亮度及光强吸收强度决定.
2.1 编码与初始化为在保证初始种群多样性的同时提高初始种群的质量,本文采取机器编码及NEH启发式编码相结合的方式对初始种群进行编码.
在N个工件中,前N/2个工件,采用机器编码的方式,机器编码的核心思想是能够在保证初始种群多样性的同时可以反映加工机器的约束条件,具体为:
以每个加工工件的工序数为p为例,构造p×N/2的可行解编码矩阵为
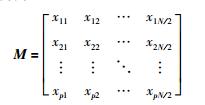
|
该矩阵中的元素xpj由区间(1,Mp+1)产生,这些元素的整数部分代表第j个工件正在负责第p道工序的机器上加工.在该矩阵中,每一列代表每一个工件;同理,每一行都代表每一个负责不同加工工序的机器.有关解码方式跟编码方式相似.本文以工件数及加工机器数均为4的多目标流水车间调度问题为例来说明,如果每个工件在每道加工机器上的加工时间列表为

|
正如该矩阵中显示的,假如4个工件的第1道工序的加工时间不同,在矩阵中第4个工件的加工时间最短,以此类推,加工时间第2短的是工件2,排第3的是工件1,排第4的是工件3,因而,4个工件在第一道工序的加工序列为4,2,1,3,然后再按照相应的加工顺序进行第2道工序的加工,以此类推,直至加工完成.
为进一步提高初始种群的质量,本文将剩余的N/2个工件利用NEH启发式编码方式进行初始化,该方法的基本核心理念就是工件在所有加工机器上的总时间越大,优先级越高.在该编码方式中,首先计算每个工件在所有机器上的加工时间的总和,按照递减顺序对其进行排序,对前两个工件进行排序调度,后面工件依次插入到已完成调度的工件序列中的某个位置,直到所有工件调度完成,得到一个次优调度序列.
2.2 生成外部集合产生初始种群后,按照式(5)~式(7)计算种群各个萤火虫个体的目标函数值得到Pareto多目标解集合,与此同时,计算萤火虫个体的灰熵关联度值.并以灰熵关联度函数作为多目标置换流水车间调度问题的适应度函数,计算可行解的适应度值,同时利用快速选择排序法,将非支配解存放进外部集合(ES)中.
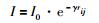
|
(5) |
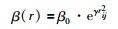
|
(6) |
其中,I0代表萤火虫的最大荧光素亮度值,问题的目标函数值越大,则萤火虫自身的荧光素亮度越大;rij代表了萤火虫之间的笛卡尔距离;γ代表了光强吸收系数. β0代表了萤火虫个体的最大吸引度.
荧光素亮度较低的萤火虫i将会被亮度较高的萤火虫j吸引,其被吸引移动后的位置更新公式为
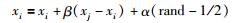
|
(7) |
其中,xi、xj表示为i、j萤火虫个体在空间中所处的位置;α代表萤火虫个体的步长因子,同rand一样为[0~1]区域内的随机数;α(rand-1/2)的作用是为了防止算法在迭代过程中陷入局部最优化而设置的扰动因子.
2.3 位置更新 2.3.1 适应值的分配求解多目标置换流水车间的优化算法中有很多适应度值分配的方式.本文选择灰熵关联度适应值分配方式作为本文适应值的分配方式.
第1步 利用混合萤火虫算法分别对各个子目标进行求解,并将其目标函数的最优值fk(0)(k=1,2,…,M),组合成最优解的目标函数向量Y0=[f1(0),f2(0),…,fM(0)],其中M代表子目标的个数.此外,分别计算出种群中的可行解xi的子目标函数值fk(i)(k=1,2,…,M),组成相应的向量Y1=[f1(i),f2(i),…,fM(i)],其中,i=1,2,…,N.
第2步 对最优解及可行解的目标函数值进行无量纲化的处理:
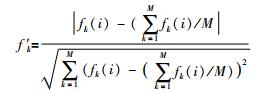
|
(8) |
第3步 灰熵关联系数的求解:
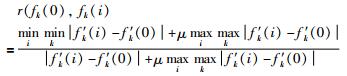
|
(9) |
其中,μ为分辨系数,一般情况下为0.5[17].
第4步 求解各个子目标时的比重:
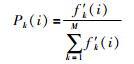
|
(10) |
第5步 求解各个子目标时的信息熵:
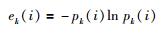
|
(11) |
第6步 求解各个子目标时的熵值权重:
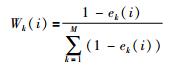
|
(12) |
第7步 可行解的灰熵关联度:
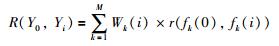
|
(13) |
与其它的分配策略不同,灰熵关联度作为可行解的适应度值能够客观地表示出当前可行解对应的各个子目标的熵值权重.通常情况下,可行解的灰熵关联度适应值越大,说明该可行解越接近最优解,因而,本文将灰熵关联度作为本文的适应度函数.在该混合萤火虫算法每一次的寻优中,按照灰熵关联度适应值排列选择出最优个体,从而更新全局最优个体,引领该算法不断地接近Pareto前沿.
2.3.2 利用萤火虫特性更新位置外部集合生成后,根据式(5)及式(6)分别计算其中1/2萤火虫个体的相对荧光素亮度及吸引度,从而根据萤火虫的相对亮度及吸引度确定萤火虫的移动方向,同时利用式(7)更新萤火虫的位置.
萤火虫在利用荧光素亮度及吸引度更新位置时,邻域的搜索有利于增加萤火虫算法的搜索精度,故本文利用变邻域搜索策略中的Insert及Inverse两种思想模式,同时借鉴模拟退火算法的相关思想提出一种新的邻域搜索方式,具体如图 1所示.

|
| 图 1 Insert及Inverse邻域结构搜索图 Fig.1 Insert and inverse neighborhood structure search diagram |
为增加可行解的质量及提高解的收敛速度,其余1/2的萤火虫个体利用概率矩阵模型记录每个萤火虫及位置间的信息,同时利用区块挖掘、区块竞争使得萤火虫移动到新的位置,从而进行萤火虫位置的更新.本文将外部集合生成后的非分配解的适应值从大到小排序,选择前100个可行解,按照式(14)~式(17)进行位置矩阵及相依矩阵的更新,具体如图 2~图 4所示,具体的更新规则按照式(14)~式(17)更新.
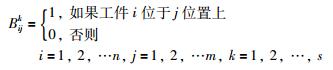
|
(14) |

|
| 图 2 概率矩阵模型更新方式 Fig.2 Updating of probability matrix model |

|
| 图 3 位置矩阵模型更新方式 Fig.3 Updating method of position matrix |

|
| 图 4 相依矩阵模型更新方式 Fig.4 Updating method of dependency matrix |
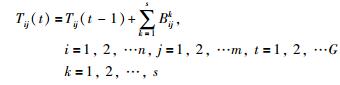
|
(15) |
其中,Bijk代表可行解中工件被加工的位置,k代表可行解的编号,n代表被加工工件的数量,s代表被选择出的用以更新概率矩阵的可行解的数目,t代表目前的迭代数,G代表最大迭代数.
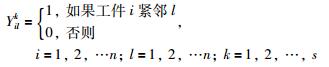
|
(16) |
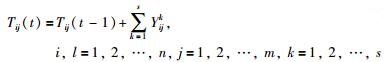
|
(17) |
其中,Yijk代表可行解中各个工件之间的连接关系,k代表被选中的可行解的编码,n代表被加工的工件数量,m代表被选中的用以更新相依矩阵的可行解的数量,t代表当前的迭代次数,G代表最大迭代次数.
2.3.4 构建区块本文通过构建区块来记录算法迭代过程中产生的可行解片段信息,从而降低可行解的复杂度,具体如图 5所示.以单个机器加工15个工件为例,工件{工件1,工件2,…,工件15}为可行解上的单个基因,产生的可行解共有15!种排序组合方式.如果利用区块将有效的可行解片段组合,产生的可行解组合降为7!种,大幅度地降低了可行解的复杂度,本部分将从区块挖掘及区块竞争两个方面来构建区块.

|
| 图 5 种群迭代复杂度比较 Fig.5 The comparison of iterative complexity of population |
1) 区块挖掘
区块挖掘需要依照位置矩阵及相依矩阵中的相关信息进行挖掘,随机产生符合最小长度的空白区块,设区块的最小长度为3,根据位置矩阵及相依矩阵中的概率信息进行挖掘.首先将每个工件在位置矩阵及相依矩阵的概率信息合并为合并概率(combination probability,CP),具体如式(18)所示.然后利用轮盘赌针对合并概率进行选择,其中,区块的起始位置按照概率矩阵的概率信息,以轮盘赌进行选择.在选出第一个工件后,利用合并概率对第2个工件、第3个工件一次筛选.具体选择方式如图 6所示.
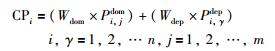
|
(18) |

|
| 图 6 区块挖掘方式图 Fig.6 The diagram of block mining method |
其中,i代表加工工件的顺序编码,γ代表工件i的前一个加工工件的顺序编码,j代表加工工件i的位置,n代表总的加工工件数,CPi代表加工工件i的合并概率,Wdom及Wdep代表在当次种群迭代过程中位置矩阵及相依矩阵所占有的权重,Pi,jdom是工件i在位置j上的概率,Pi,γdep是工件j紧邻工件i前加工的概率.
由于区块的长度是由轮盘赌的方式随机产生的,故随着区块长度的增加,总的概率不断降低,即区块组合错误的概率越来越大.为保证区块质量,本文引用文[18]中阈值设置原则,阈值随着迭代次数的增加由0.24增到0.7.同时,将每代符合阈值的区保存至区块库中,其它区块按照此方式进行挖掘.
为保留优秀的基因片段,本文将挖掘出的区块存入区块库1中,区块库1仅保存该次迭代所产生的所有区块.具体如图 7所示.

|
| 图 7 区块存放至区块库1 Fig.7 Blocks are stored in block library 1 |
2) 区块竞争
本文的区块竞争是将保存在区块库1中的该次迭代产生的区块与保留在区块库2中的迭代以来通过区块竞争保留下的区块进行竞争.本文将区块库1中区块与区块库2中的区块进行工件及位置的对比:(1)若区块间出现重复的位置,利用区块的平均概率进行选择,平均概率较大的区块保留至区块库2中,平均概率较小的区块删除;(2)若区块间出现一个工件重复,则跟位置重复一样,利用平均概率挑选区块,将平均概率较大的区块保留至区块库2中,平均概率较小的区块删除;(3)若区块间出现2个以上的工件重复且工件处的位置一样,则将区块重复的部分保留至区块库2中,其余部分直接删除,否则,将不同部分删除后,再按照平均概率筛选,具体如图 8所示.

|
| 图 8 区块竞争 Fig.8 Block competition |
平均概率的计算方式是区块的第一个工件按照位置矩阵的概率计算,其余工件按照合并概率计算,将区块的各个工件的概率进行加总然后除以区块的总长度,得出该区块的平均概率.区块的平均概率计算方式如式(19)所示:
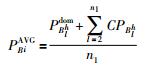
|
(19) |
其中,h是区块的编号,Blh是第i个区块中的第l个工件,j是Blh的所在位置,n1即为目前区块的总长度.
2.3.5 组合人造解为提高可行解的质量,在完成区块构建后,利用区块库2中保留的区块进行组合人造解.该构造方式与区块构建类似,从人造解的最后一个位置开始构建,人造解的最后一个位置依据工件在最后每个位置加工时间的长短,利用轮盘赌的方式进行挖掘,其他的位置以合并概率进行选择,同时已被选择的工件不再进行此次选择.每当选择出一个工件时,将该工件与区块库2中的区块进行对比,如果该工件与区块库2中区块的末端位置及工件相同,则将该区块复制到人造解里,接着从复制后的其实位置继续选择工件,直至完成人造解的构建,具体如图 9所示.

|
| 图 9 人造解组合方式 Fig.9 Solution combination mode |
为增加混合萤火虫算法寻优概率,本文提采用以下方式对可行解进行重组.首先对母体可行解随机切成D个片段,选取最长的可行解片段及最短的可行解片段相组合,然后对该片段进行插入搜寻算子操作,该可行解片段根据合并概率重组,具体如图 10所示.

|
| 图 10 插入搜寻算子重组可行解 Fig.10 Feasible solution of insertion search operator recombination |
本文利用精英选择策略,将母体中适应度函数值较好的个体代替子代适应度函数值较差的个体,从而使得精英个体得以延续.即将新产生的子代可行解与母体放进选择池,从选择池中随机选择两条可行解进行比较,将适应度值较好的可行解放进新的母体中,而适应度值较差的可行解则重新进入选择池继续进行比较,不断进行比较,直至满足新母体解的数量.
2.3.8 反复搜索策略易陷入局部最优是许多智能算法面临的问题,导致算法反复的在同一个解空间进行搜索,从而忽略了其他空间的有效信息,往往这些被忽略的信息是提高可行解质量的关键因素.本文借由反复搜索策略,进行全局性搜索及增加可行解的多样性,反复搜索策略分为保留优势解集及改变搜索范围两部分.
1) 保留优势解
首先,按照适应度函数值将可行解进行排序,设立K指标,本文令K等于10,当母体中的最优解没有更新时,累加K.反之若最优解更新,K指标归零重新累计,当K值超过阀值时,保留母体的前80%的可行解,其余的20%以随机产生的方式填充以增加可行解的多样性及避免陷入局部最优化,具体如图 11所示.

|
| 图 11 保留优势解 Fig.11 Retained dominance solution |
2) 改变搜索范围
在改变搜索范围部分,位置矩阵扮演着重要角色,通过改变位置矩阵的搜索范围,搜寻母体可行解中不同空间的信息,用以增加全局搜索能力,在保留优势解的基础上,更新母体并更新至下一代,此时,清空概率矩阵,改变原来的累计信息范围,搜索母体中不同区域的信息,用以增加全局搜索能力.迭代后期,若持续搜索母体中的不同区域,可能会影响求解方向及收敛的质量.因此,当迭代数达到总迭代数的3%时,将概率矩阵回复到最初的探索范围,使得具有高竞争优势的可行解引领求解方向.
2.4 混合萤火虫算法流程综上所述,本文提出的混合算法的步骤如下:
第1步 初始化算法的基本参数.
第2步 初始化萤火虫的位置,计算每只萤火虫对应的适应度函数值,并利用适应度函数值生成外部档案.
第3步 选取1/2的萤火虫根据式(5)及式(6)计算萤火虫的荧光素值及萤火虫吸引度,更新萤火虫位置,为增加萤火虫算法的局部搜索精度,进行邻域搜索,另外1/2利用工件及位置之间的信息更新概率矩阵并利用概率矩阵中的信息构建区块.
第4步 利用精英保留策略筛选子代中的优势群体.
第5步 为防止陷入局部最优,利用反复搜索策略进行全局性搜索.
第6步 判断全局循环是否已达到最大循环次数,如果cycle < MCN,转第3步;否则结束.
具体混合萤火虫算法流程图如图 12所示.

|
| 图 12 混合萤火虫算法流程图 Fig.12 Flow chart of hybrid firefly algorithm |
本文采用非支配解的数量、均匀性指标和C指标三个指标对混合萤火虫算法求得的Pareto最优解进行评判:
1) 非支配解的数量(number of Pareto solution,NPS)
通过对每个算法所求的Pareto非支配解数量的比较,用以比较不同算法的搜索能力,通常情况下,搜索到的非支配解越多,说明该算法的性能越好.
2) 均匀性指标(spacing metric,SM)
通过计算非支配解集中每个个体与相邻个体之间的距离来描述非支配解记载可行解空间中的分布情况,用以表示均匀性的函数:
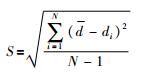
|
式中,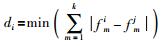
3) C指标
本文采用文[19]中的C指标用以评价.
两种算法产生的A与B两个Pareto最优解集的占优支配情况.具体的计算公式为
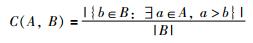
|
式中,C(A,B)代表B解集中的Pareto最优解被A解集中的Pareto最优解占优支配的数量占B解集中Pareto最优解的比率. C(A,B)的取值范围为[0~1],当B解集中的每一个解都被A解集中的一些点占优支配时,C(A,B)=1;当B解集中的每一个解都不被A解集中任何点占优支配时,C(A,B)=0,其中,C(A,B)≠C(B,A),C指标能够反映出可行解的质量以及算法的收敛性.
3.2 实验仿真与比较针对本文提出的混合萤火虫算法(HFA),将该算法与文[20]提出的NSGA-II(non-dominated sorting genetic algorithm II)算法、基本的萤火虫算法(FA)和EDA(estimation of distribution algorithm)针对Reeves案例进行仿真测试,本文利用Visual Studio 2015中的C++编程软件进行仿真测试,仿真测试的相关计算机环境为:计算机的操作系统为Window 8,处理器的主频率是8 G,计算机的CPU是2.71的Intel(R)Celeron(TM)i5-6400.为保证实验的客观性,本文算法的参数设置具体如表 1所示.
| 参数 | 参数值 |
| 构建区块时位置矩阵权重 | 随着迭代次数的增加由0.3增加到0.7 |
| 构建区块时相依矩阵的权重 | 随着迭代次数的增加由0.7降低至0.3 |
| 每次挖掘区块的数量 | 工件数×1 |
| 区块的最小长度 | 3 |
| 区块阈值 | 随着迭代次数的增加阈值由0.24递增到0.7 |
| 母体重组时被切割的可行解片段数量 | 工件数×0.25 |
设初始种群数为200,最大迭代次数为500,算法运行次数为50,获得的最终测试结果如表 2~表 4所示.
| 算例 | 规模 | 非支配解个数 | C指标/% | S均匀性指标 | |||||
| HFA | FA | C(A,B) | C(B,A) | HFA | FA | ||||
| Rec 01 | 20×5 | 19 | 13 | 97 | 6 | 55 | 40 | ||
| Rec 03 | 20×5 | 29 | 22 | 100 | 0 | 96 | 43 | ||
| Rec 05 | 20×5 | 25 | 16 | 90 | 11 | 115 | 50 | ||
| Rec 07 | 20×10 | 22 | 15 | 83 | 7 | 94 | 20 | ||
| Rec 09 | 20×10 | 23 | 12 | 94 | 4 | 70 | 25 | ||
| Rec 11 | 20×10 | 23 | 12 | 89 | 9 | 83 | 49 | ||
| Rec 17 | 20×15 | 19 | 10 | 100 | 0 | 144 | 88 | ||
| Rec 19 | 30×10 | 32 | 20 | 96 | 6 | 221 | 150 | ||
| Rec 21 | 30×10 | 34 | 28 | 87 | 12 | 106 | 87 | ||
| Rec 23 | 30×10 | 27 | 21 | 99 | 4 | 79 | 69 | ||
| 算例 | 规模 | 非支配解个数 | C指标/% | S均匀性指标 | |||||
| HFA | FA | C(A,B) | C(B,A) | HFA | FA | ||||
| Rec 01 | 20×5 | 19 | 10 | 84 | 14 | 55 | 39 | ||
| Rec 03 | 20×5 | 29 | 18 | 91 | 8 | 96 | 50 | ||
| Rec 05 | 20×5 | 25 | 13 | 81 | 17 | 115 | 47 | ||
| Rec 07 | 20×10 | 22 | 11 | 84 | 9 | 94 | 20 | ||
| Rec 09 | 20×10 | 23 | 10 | 94 | 7 | 70 | 46 | ||
| Rec 11 | 20×10 | 23 | 15 | 90 | 7 | 83 | 58 | ||
| Rec 17 | 20×15 | 19 | 9 | 86 | 13 | 144 | 86 | ||
| Rec 19 | 30×10 | 32 | 19 | 100 | 0 | 221 | 143 | ||
| Rec 21 | 30×10 | 34 | 21 | 99 | 5 | 106 | 83 | ||
| Rec 23 | 30×10 | 27 | 13 | 93 | 9 | 79 | 55 | ||
| 算例 | 规模 | 非支配解个数 | C指标/% | S均匀性指标 | |||||
| HFA | NSGA-II | C(A,B) | C(B,A) | HFA | NSGA-II | ||||
| Rec 01 | 20×5 | 19 | 15 | 86 | 15 | 55 | 42 | ||
| Rec 03 | 20×5 | 29 | 26 | 78 | 16 | 96 | 57 | ||
| Rec 05 | 20×5 | 25 | 16 | 100 | 0 | 115 | 56 | ||
| Rec 07 | 20×10 | 22 | 12 | 81 | 5 | 94 | 8 | ||
| Rec 09 | 20×10 | 23 | 13 | 96 | 6 | 70 | 52 | ||
| Rec 11 | 20×10 | 23 | 16 | 100 | 0 | 83 | 66 | ||
| Rec 17 | 20×15 | 19 | 14 | 93 | 4 | 144 | 104 | ||
| Rec 19 | 30×10 | 32 | 22 | 100 | 0 | 221 | 168 | ||
| Rec 21 | 30×10 | 34 | 30 | 99 | 8 | 106 | 99 | ||
| Rec 23 | 30×10 | 27 | 20 | 88 | 7 | 79 | 63 | ||
由表 2~表 4可知,相比于其它3种算法,HFA算法能够获得更多的非支配解,与此同时,HFA算法的C指标值较大以及具有较好的均匀性,表明了,HFA算法具有良好的求解性能.为了更加直观地证明HFA算法的有效性,本文以案例Rec 01、Rec 03、Rec 09、Rec 21为例,分别使用NSGA-II算法和HFA算法对这些案例进行求解,并利用相应的Pareto非支配解图进行直观比较.
图 13~图 16为20×5的多目标置换流水车间调度问题.利用HFA及NSGA-II两种智能算法求解案例Rec 01得到的Pareto解集三维分布图及二维投影图.

|
| 图 13 求解Rec 01案例得到的非支配解分布图 Fig.13 The picture of number of pareto solution distribution for case Rec 01 |

|
| 图 14 f1-f2轴投影图 Fig.14 The picture of f1-f2 axis projection |

|
| 图 15 f1-f3轴投影图 Fig.15 The picture of f1-f3 axis projection |

|
| 图 16 f2-f3轴投影图 Fig.16 The picture of f2-f2 axis projection |
由三维图可知,HFA算法求得的非支配解均在NSGA-II解的左下方.同时在二维图中,由图 14~图 16可知,无论是在最大完工时间方向上、延迟时间方向上还是总流程时间方向上,HFA算法得到的非支配解分布比NSGA-II算法得到的非支配解分布更接近于原点.说明了HFA算法得到的非支配优于NSGA-II算法得到的非支配解.
图 17~图 19为利用HFA及NSGA-II两种智能算法求解案例Rec 03、Rec 09、Rec 21得到的非支配解三维分布图.由图 17~图 19可知,看出HFA算法求得的非支配解均在NSGA-II解的左下方.表明了该混合算法在求解多目标置换流水车间调度问题时具有较好性能.

|
| 图 17 求解Rec 03案例得到的非支配解分布图 Fig.17 The picture of number of pareto solution distribution for Rec 03 case |

|
| 图 18 求解Rec 09案例得到的非支配解分布图 Fig.18 The picture of number of pareto solution distribution for case Rec 09 |

|
| 图 19 求解Rec 21案例得到的非支配解分布图 Fig.19 The picture of number of pareto solution distribution for Rec 21 case |
为进一步验证该算法的有效性,针对Taillard案例,将HFA算法与SEABLL[21](sub-population evolutionary algorithm based on linkage learning,SEABLL)算法进行比较.设初始种群数为100,最大迭代次数为100,算法运行次数为50,具体的比较结果如表 5所示.
| 算例 | 非支配解个数 | S均匀性指标 | |||
| HFA | SEABLL | HFA | SEABLL | ||
| ta 001 | 14 | 12 | 56 | 49 | |
| ta 002 | 5 | 5 | 59 | 54 | |
| ta 003 | 19 | 18 | 52 | 46 | |
| ta 004 | 12 | 8 | 66 | 56 | |
| ta 005 | 20 | 18 | 59 | 43 | |
| ta 006 | 20 | 18 | 63 | 52 | |
| ta 010 | 29 | 25 | 49 | 49 | |
| ta 011 | 20 | 16 | 73 | 52 | |
| ta 012 | 11 | 8 | 143 | 109 | |
| ta 013 | 19 | 15 | 119 | 98 | |
| ta 014 | 21 | 19 | 95 | 61 | |
| ta 015 | 19 | 14 | 121 | 97 | |
| ta 016 | 45 | 39 | 168 | 136 | |
| ta 020 | 52 | 48 | 81 | 65 | |
| ta 030 | 31 | 29 | 69 | 59 | |
由表 5可知,HFA算法求得的非支配解数量要大于SEABLL算法求得的非支配解数量.此外,除了ta 010外,HFA算法的S均匀性指标均大于SEABLL算法的S均匀性指标,故总体而言,相对于其它算法HFA算法具有较好的求解性能.
4 结论本文提出了一种求解多目标置换流水车间调度问题的混合萤火虫算法,首先利用NEH模型及随机生成的方式初始化种群,增加了初始化种群多样性及初始种群质量;利用概率矩阵中的信息组合区块,用以保留优势解片段及提高算法的收敛速度;同时,借由反复搜索策略进行全局性搜索,用以增加可行解的多样性及提高求解质量.最后,针对Taillard案例及Reeves案例进行仿真实验,验证了该混合算法良好的求解性能.
本文只是对多目标置换流水车间调度问题进行相应研究,接下来可以继续研究带准备时间的多目标置换流水车间调度问题、混合置换流水车间调度问题等.
| [1] | Xu J, Wu C C, Yin Y, et al. An iterated local search for the mul-objective permutation flowshop scheduling problem with sequence-dependent setup times[J]. Applied Soft Computing, 2017, 52: 39–47. DOI:10.1016/j.asoc.2016.11.031 |
| [2] | Scaria A, George K, Sebastian J. An artificial bee colony approach for multi-objective job shop scheduling[J]. Procedia Technology, 2016, 25: 1030–1037. DOI:10.1016/j.protcy.2016.08.203 |
| [3] | Laribi I, Yalaoui F, Belkaid F, et al. Heuristics for solving flow shop scheduling problem under resources constraints[J]. IFAC-PapersOnLine, 2016, 49(12): 1478–1483. DOI:10.1016/j.ifacol.2016.07.780 |
| [4] | Zhang R, Chiong R. Solving the energy-efficient job shop scheduling problem: A multi-objective genetic algorithm with enhanced local search for minimizing the total weighted tardiness and total energy consumption[J]. Journal of Cleaner Production, 2016, 112: 3361–3375. DOI:10.1016/j.jclepro.2015.09.097 |
| [5] | Khorasanian D, Moslehi G. Two-machine flow shop scheduling problem with blocking, multi-task flexibility of the first machine, and preemption[J]. Computers & Operations Research, 2017, 79: 94–108. |
| [6] | Sharma N, Sharma H, Sharma A. Beer froth artificial bee colony algorithm for job-shop scheduling problem[J]. Applied Soft Computing, 2018, 68: 507–524. DOI:10.1016/j.asoc.2018.04.001 |
| [7] | Ishibuchi H, Murata T. A multi-objective genetic local search algorithm and its application to flow shop scheduling[J]. IEEE Transactions on Systems, Man and Cybernetics-Part C: Application and Reviews, 1998, 28: 392–403. DOI:10.1109/5326.704576 |
| [8] | Ishibuchi H, Murata T. A multi-objective genetic local search algorithm and its application to flow shop scheduling[J]. IEEE Transactions on Systems, Man and Cybernetics-Part C: Application and Reviews, 1998, 28: 392–403. DOI:10.1109/5326.704576 |
| [9] | Fattahi P. Multi-objective meta-heuristics to solve three-stage assembly flow shop scheduling problem with machine availability constraints[J]. International Journal of Production Research, 2015, 53(3): 944–968. DOI:10.1080/00207543.2014.948575 |
| [10] | Li X, Ma S. Multi-objective memetic search algorithm for multi-objective permutation flow shop scheduling problem[J]. IEEE Access, 2017, 4: 2154–2165. |
| [11] |
徐文婕, 朱光宇.
直觉模糊集相似度遗传算法求解多目标车间调度问题[J]. 控制理论与应用, 2019, 36(7): 1057–1066.
Xu W J, Zhu G Y, et al. Intuitionistic fuzzy set similarity genetic algorithm for solving multi-objective shop scheduling problem[J]. Control Theory and Application, 2019, 36(7): 1057–1066. |
| [12] | Lu C, Gao L, Li X, et al. Energy-efficient permutation flow shop scheduling problem using a hybrid multi-objective backtracking search algorithm[J]. Journal of Cleaner Production, 2017, 144: 228–238. DOI:10.1016/j.jclepro.2017.01.011 |
| [13] |
齐学梅, 王宏涛, 杨洁.
量子萤火虫算法及在无等待流水调度上的应用[J]. 信息与控制, 2016, 45(2): 211–217.
Qi X M, Wang H T, Yang J, et al. Quantum firefly algorithm and its application in waiting free flow scheduling[J]. Information and Control, 2016, 45(2): 211–217. DOI:10.13976/j.cnki.xk.2016.0211 |
| [14] |
张军丽, 周永权.
人工萤火虫与差分进化混合优化算法[J]. 信息与控制, 2011, 40(5): 608–613.
Zhang J L, Zhou Y Q. Hybrid optimization algorithm of artificial firefly and differential evolution[J]. Information and Control, 2011, 40(5): 608–613. |
| [15] |
熊娟, 文桦.
基于萤火虫搜索算法的图像纹理特征提取研究[J]. 计量学报, 2016, 37(3): 255–259.
Xiong J, Wen H. Research on texture feature extraction based on firefly search algorithm[J]. Journal of Metrology, 2016, 37(3): 255–259. |
| [16] | Pinedo M, Hadavi K. Scheduling: Theory, algorithms, and systems[J]. AIIE Transactions, 2016, 28(8): 695–697. |
| [17] |
黄霞, 叶春明, 曹磊.多目标置换流水车间调度的混沌杂草优化算法[J].系统工程理论与实践, 2017, 37(1): 253-262. Huang X, Ye C M, Cool, et al. Chaos weed optimization algorithm for multi-objective displacement flow shop scheduling[J]. System Engineering Theory and Practice, 2017, 37(1): 253-262 CNKI:SUN:XTLL.0.2017-01-022 |
| [18] | Chang P C, Huang W H, Ting C J. Dynamic diversity control in genetic algorithm for mining unsearched solution space in TSP problems[J]. Expert Systems with Applications, 2010, 37(3): 1863–1878. DOI:10.1016/j.eswa.2009.07.066 |
| [19] | Zitzler E. Evolutionary algorithms for multiobjective optimization: Methods and applications[M]. Aachen: Shaker Verlag, 1999. |
| [20] | Deb K, Pratap A, Agarwal S, et al. A fast and elitist multiobjective genetic algorithm: NSGA-II[J]. IEEE Transactions on Evolutionary Computation, 2002, 6(2): 182–197. DOI:10.1109/4235.996017 |
| [21] |
陈慧芬.基于链结学习的子群体进化算法求解多目标调度问题[D].天津: 天津理工大学, 2017. Chen H F. Sub population evolutionary algorithm based on link learning to solve multi-objective scheduling problem[D]. Tianjin: Tianjin University of Technology, 2017. CNKI:CDMD:2.1017.814820 |